[논문리뷰] TokenVerse: Versatile Multi-concept Personalization in Token Modulation Space
SIGGRAPH 2025 (Best Paper). [Paper] [Page]
Daniel Garibi, Shahar Yadin, Roni Paiss, Omer Tov, Shiran Zada, Ariel Ephrat, Tomer Michaeli, Inbar Mosseri, Tali Dekel
Google DeepMind | Tel Aviv University | Technion | Weizmann Institute
21 Jan 2025
Introduction
본 논문의 목표는 다양한 개념이 하나의 이미지에서 추출되고 다른 구성으로 결합될 수 있는 다재다능하고 유연한 개념 개인화를 가능하게 하는 것이다. 본 논문의 프레임워크는 사전 학습된 text-to-image diffusion transformer (DiT) 모델을 기반으로 하며, 여기서 입력 텍스트는 두 경로로 처리된다.
- 텍스트 토큰이 이미지 토큰과 함께 처리되는 transformer block을 통해
- 각 transformer block 내의 토큰 채널을 modulation하는 modulation 경로를 통해
의미적 이미지 조작을 위해 GAN에서 modulation space를 성공적으로 사용한 데 영감을 받아, 본 논문은 DiT에서 modulation space $\mathcal{M}$을 사용하는 방법을 탐구하였다. 저자들은 $\mathcal{M}$ 내의 방향이 GAN과 유사하게 생성된 이미지에 대한 의미적 수정에 해당한다는 것을 관찰하였다. 그러나 이러한 조작은 종종 개인화된 콘텐츠 생성에 적합하지 않으며, 단일 텍스트 토큰에 대한 modulation 벡터를 수정하면 이 토큰과 관련된 개념에만 의미적 수정이 발생할 수 있음을 발견했다. Per-token modulation space를 $\mathcal{M}^{+}$로 표시한다.
본 논문은 시각적 개념의 분리된 개인화 및 개념 합성을 위해 $\mathcal{M}^{+}$를 활용한다. 이미지와 캡션이 주어졌을 때, 각 텍스트 토큰에 대한 modulation 벡터를 최적화하면 설명하는 시각적 요소를 개인화하기에 충분하다. 이미지에서 시각적 개념의 분리는 모델이 텍스트 토큰과 해당 이미지 부분을 본질적으로 연관시키는 특성에 의해 자연스럽게 촉진된다. 모든 텍스트 토큰의 modulation 벡터는 공동으로 최적화되지만, 각 최적화된 벡터는 modulation하는 텍스트 토큰에 연결된 시각적 요소를 개인화한다. 따라서 캡션에서 개념 합성을 설명하고 학습된 벡터를 텍스트 토큰에 연결하기만 하면 여러 학습된 요소를 새로운 설정에서 함께 생성할 수 있다.
본 논문의 방법인 TokenVerse는 모델의 가중치를 조정하지 않고도 복잡한 개념을 표현할 만큼 충분히 표현력이 뛰어나며, 따라서 prior를 보존한다. 또한 시각적 요소가 시각적 단서(ex. segmentation mask)가 아닌 semantic 텍스트 토큰으로 정의되므로, 최적화 중에 캡션에 간단히 설명함으로써 겹치는 물체와 물체가 아닌 개념(ex. 포즈, 조명, 재료)의 개인화를 지원한다. 마지막으로, 이 TokenVerse는 매우 모듈화되어 여러 이미지에서 추출한 개념을 원활하게 결합할 수 있다.
Method
1. Preliminaries: The Modulation mechanism in DiTs
Modulation은 각 채널에 하나의 scale factor를 곱하고 하나의 bias 스칼라로 shift하는 채널별로 신경망의 activation을 수정하는 것을 말한다. 생성 모델의 맥락에서 modulation 메커니즘은 StyleGAN에서 사용된 후 상당한 인기를 얻었다. StyleGAN에서는 modulation 파라미터를 약간 수정하면 생성된 이미지에 부드럽고 semantic하게 의미 있는 perturbation이 발생하는 것으로 나타났으며, 이 속성은 이미지 편집 및 조작에 광범위하게 활용되었다.
최신 text-to-image DiT에서 modulation 메커니즘은 diffusion timestep과 텍스트 프롬프트의 임베딩과 같은 컨디셔닝 신호를 통합하는 데 사용된다. 특히 Stable Diffusion 3과 Flux는 MLP를 통해 diffusion timestep $t$와 텍스트 프롬프트 $p$의 임베딩을 처리하여 벡터를 출력하였다.
\[\begin{equation} y = \textrm{MLP}(t, \textrm{CLIP} (p)) \end{equation}\]그런 다음 이 벡터는 추가로 처리되어 채널별 scale 및 shift 파라미터로 분할되며, 이는 diffusion model의 각 블록 내에서 텍스트 토큰과 이미지 토큰을 modulation하는 데 사용된다. 중요한 점은 모든 토큰에 동일한 scale 및 shift 파라미터가 사용된다는 것이다.
2. The $\mathcal{M}^{+}$ space

StyleGAN에서 편집을 위해 modulation space를 사용하는 데 영감을 받아, 저자들은 DiT의 modulation space를 탐색하여 $\mathcal{M}$이라는 이름을 붙였다. Modulation 경로에 주입된 텍스트 임베딩에 간단한 조작을 사용하면 입력 텍스트를 그대로 유지하면서 modulation 벡터를 수정할 수 있다. 이를 통해 의미적으로 풍부한 수정을 할 수 있지만 생성된 이미지를 전체적으로 변경하는 경우가 많다.
따라서, 본 논문은 특정 텍스트 토큰에 영향을 미치는 modulation 벡터만 수정하는 프레임워크를 도입하였다. 이러한 모든 수정의 공간을 $\mathcal{M}^{+}$라고 한다.
The modulation space $\mathcal{M}$
Modulation space에서 방향을 얻기 위한 단순한 접근 방식은 특정 속성이 있는 텍스트 프롬프트와 없는 텍스트 프롬프트를 사용하는 것이다.
\[\begin{equation} \Delta_\textrm{attribute} = \textrm{MLP} (t, e_\textrm{attribute}) - \textrm{MLP} (t, e_\textrm{neutral}) \end{equation}\]여기서 \(e_\textrm{neutral}\)은 이미지를 생성하는 데 사용된 텍스트 프롬프트의 임베딩이고, \(e_\textrm{attribute}\)는 동일한 프롬프트의 임베딩이지만 관심있는 물체에 일부 속성이 추가된 것이다 (ex. “dog” 대신 “Poodle dog”). 이러한 방향을 얻었으면 일부 scale factor $w$와 함께 modulation 벡터 $y$에 추가하여 업데이트된 modulation 벡터 \(y + w \Delta_\textrm{attribute}\)를 얻을 수 있다.
위 그림의 (a)에서 볼 수 있듯이, 관심 대상은 실제로 원하는 속성을 소유하도록 수정된다. 그러나 수정은 localize되지 않는다. 즉, 각 방향은 이미지의 관련 없는 속성도 수정한다.
The Per-token modulation space $\mathcal{M}^{+}$
Localization의 부족을 극복하기 위해, 저자들은 개별 텍스트 토큰을 다르게 modulation하는 것을 제안하였다. 모든 텍스트 토큰별 modulation 벡터에 해당하는 공간을 $\mathcal{M}^{+}$라 하자. 구체적으로, 모든 토큰을 modulation하는 데 동일한 벡터 $y$를 사용하는 대신, 영향을 미치고자 하는 개념에 해당하는 텍스트 토큰에 대해서만 modulation 벡터를 수정한다. 하나의 텍스트 토큰에 대한 modulation 벡터를 수정하면 attention layer를 통해 해당 이미지 토큰에 영향을 미치고, 이는 해당 토큰과 연관된 이미지 영역에서 보다 로컬한 효과로 변환된다.
예를 들어, 개를 변경하는 경우 modulation 벡터 \(y + w \Delta_\textrm{Poodle}\)을 “dog” 텍스트 토큰에만 적용하고 나머지 토큰에는 수정되지 않은 $y$를 사용한다. 위 그림의 (b)에서 볼 수 있듯이, 이러한 방향은 매우 로컬한 변경으로 이어지며 주로 조작된 토큰에 해당하는 물체에 영향을 미친다. 이 접근 방식은 물체에 국한되지 않으며 포즈와 같은 추상적인 개념에도 적용할 수 있다.
3. Disentangled concept learning
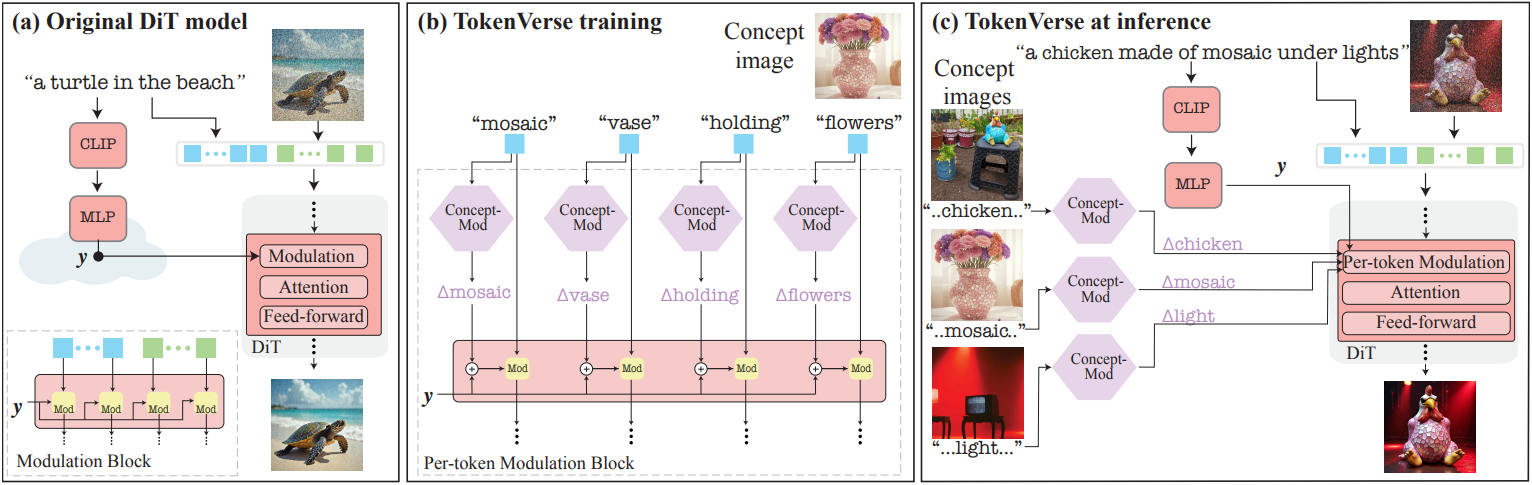
이제 $\mathcal{M}^{+}$ 내에서 원하는 방향을 찾아야 한다. 구체적으로, 여러 가지 원하는 개념을 묘사하는 예시 이미지(“개념 이미지”)와 이를 설명하는 캡션이 주어졌을 때, 목표는 캡션에 언급된 각 시각적 개념에 대한 서로 분리된 표현을 학습하는 것이다. 중요한 점은 물체 마스크에 의존하지 않고 unsupervised 방식으로 이를 달성하는 것이다.
예를 들어, “a person dancing at dawn”이라는 캡션의 경우, “person”, “dancing”, “dawn”이라는 단어를 각각 이미지의 identity, 포즈, lighting을 포착하는 $\mathcal{M}^{+}$의 방향과 연관시켜야 한다. 개념 이미지에서 이러한 방향을 추출하면 해당 텍스트 토큰에 방향을 추가하기만 하면 학습된 개념들을 새 이미지를 생성하는 데 사용할 수 있다. 중요한 점은 이 접근 방식이 모듈식이기 때문에, 공동 학습 없이 여러 개념 이미지에서 서로 다른 방향을 별도로 추출할 수 있다.
목표는 프롬프트 $p$의 여러 토큰에 각각 대응하는 방향 집합 \(\{\Delta_i\}_{i=1}^{\textrm{len}(p)}\)를 결정하는 것이다. 이를 위해, $p$의 모든 토큰에 대해 $\mathcal{M}^{+}$의 방향을 예측하는 작은 MLP인 Concept-Mod를 학습시킨다.
\[\begin{equation} (\Delta_1, \ldots, \Delta_{\textrm{len}(p)}) = \textrm{Concept-Mod} (p) \end{equation}\]각 \(\Delta_i\)가 $i$번째 토큰 (ex. 일반적인 사람을 나타내는 “사람”)과 해당 토큰의 커스텀된 버전 (ex. 이미지에 나타나는 특정 사람) 사이의 $\mathcal{M}^{+}$ 방향을 나타내야 한다. 저자들은 원래 text-to-image 모델이 학습된 것과 동일한 diffusion loss를 사용하여 개념 이미지와 연관된 프롬프트에 대해 Concept-Mod를 학습시켰다. Inference 시, 학습된 개념은 적절한 텍스트 토큰에 학습된 offset을 추가하여 새로 생성된 이미지에 통합될 수 있다.
Per-block optimization
두 단계로 방향을 학습시킨다. 첫 번째 단계에서는 개념의 대략적인 측면을 학습하는 것을 목표로 한다. 이는 diffusion loss 최적화에서 높은 noise level의 선택을 우선시하여 수행된다. 두 번째 단계에서는 낮은 noise level에 더 집중하여 방향을 정제한다. 이 단계에서는 transformer block별 벡터를 출력하는 추가 MLP도 학습된다. 이 block별 MLP의 출력은 Concept-Mod MLP의 출력에 더해져 각 토큰과 block마다 방향이 생성된다.
Concept isolation loss
TokenVerse는 캡션의 각 토큰에 대해 $\mathcal{M}^{+}$에서 별도의 방향을 학습한다. 이 공간은 비교적 얽힘이 없기 때문에 동일한 이미지에서 학습한 방향은 일반적으로 잘 분리된다. 그러나 다른 이미지에서 학습한 물체를 결합할 때 최적화된 방향이 서로 간섭하여 개념 충실도가 떨어질 수 있다.
이러한 경우를 피하기 위해 학습 iteration의 50%에 추가로 concept isolation loss를 통합한다. 이 loss는 최적화된 방향이 개념 이미지에 나타나지 않는 개념에 영향을 미치지 않도록 최적화를 조정하도록 설계되었다.
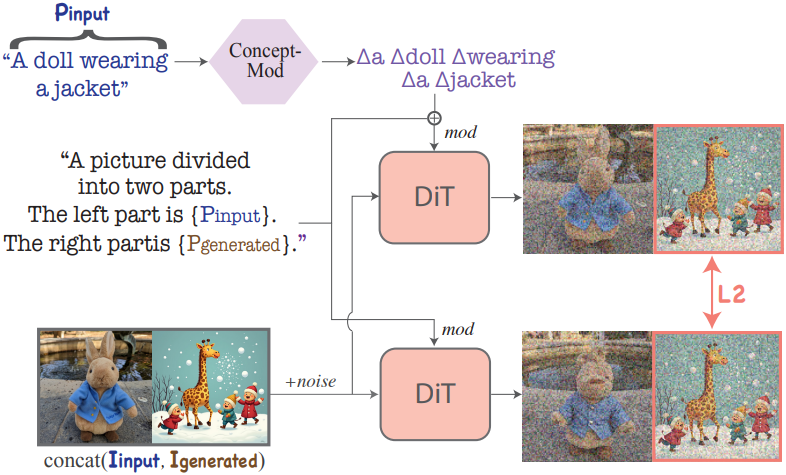
위 그림에서 볼 수 있듯이, 입력 이미지를 무작위로 생성된 이미지와 결합하고 캡션을 병합하여 연결된 이미지의 두 부분을 모두 설명하는 하나의 문장으로 만든다. 실제로는 다음과 같이 loss를 계산한다.
- Base model을 사용하여 고정된 25개 이미지를 생성하고 이 이미지들에서 항상 하나의 이미지를 무작위로 선택한다.
- 결합된 이미지와 결합된 캡션에서 모델을 실행하여 입력 프롬프트의 토큰에만 최적화된 방향을 적용한다.
- 개념 이미지에 concat된 이미지에 해당하는 부분에만 모델의 출력과 base model의 출력 사이에 L2 loss를 적용한다.
이를 통해 학습된 방향이 텍스트와 일치하는 개념 이미지의 부분에만 영향을 미치도록 한다.
Experiments
1. Qualitative results
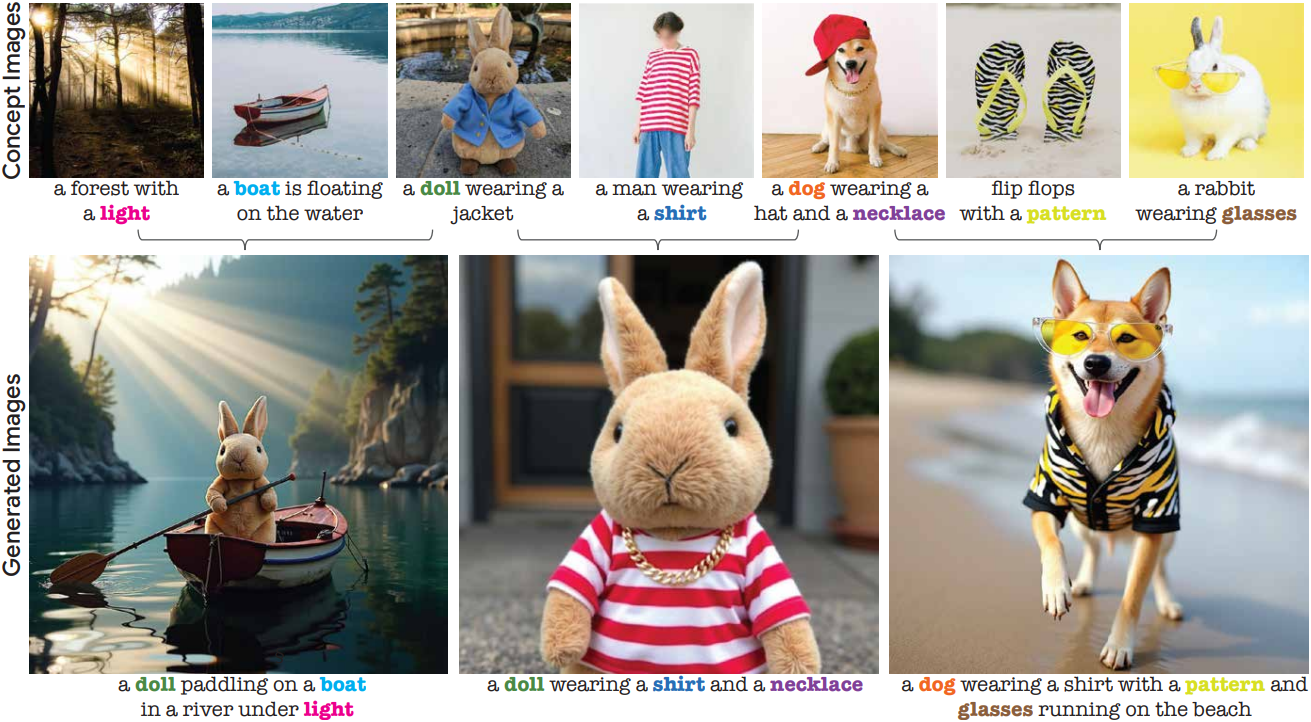
다음은 4개의 개념을 적절히 합성한 예시들이다.
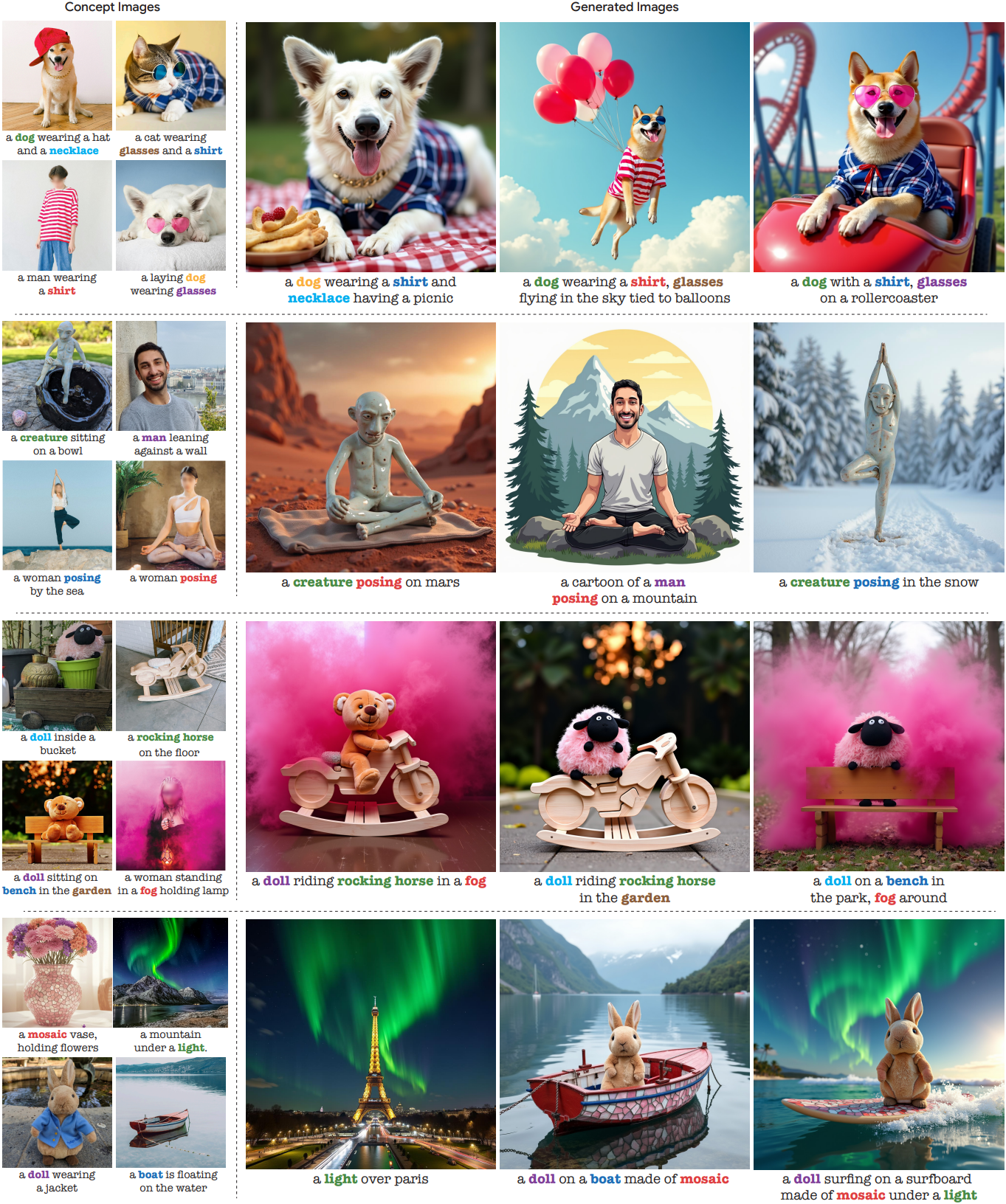
다음은 9개의 개념을 한 번에 합성한 예시이다.
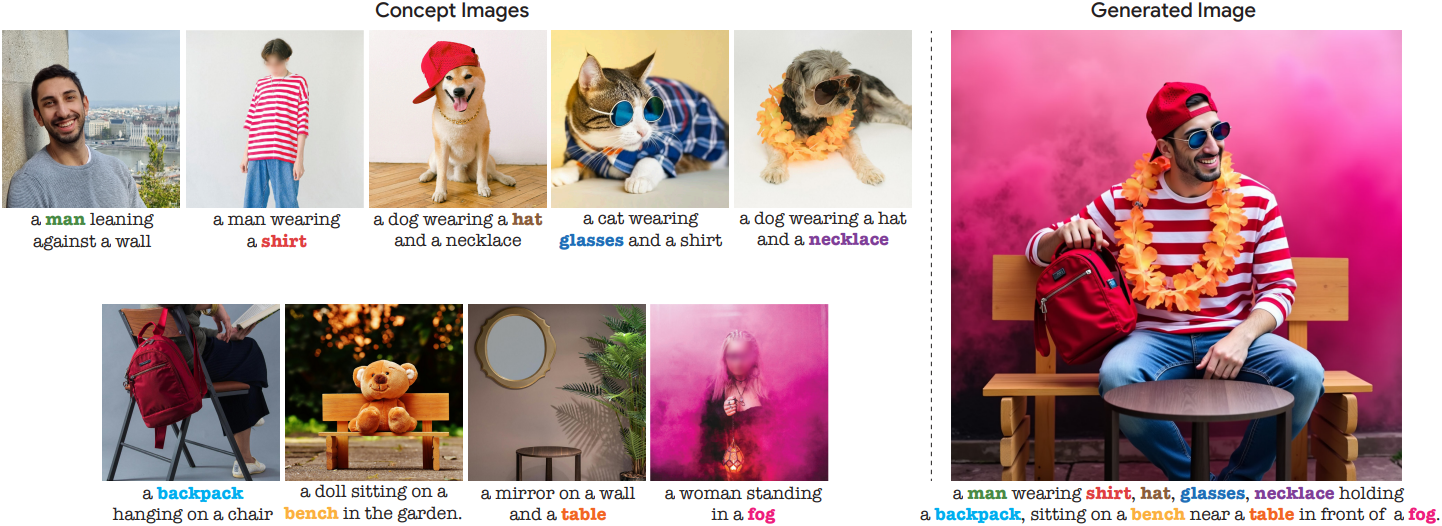
다음은 물체가 아닌 개념에 대한 합성 결과들이다.

2. Comparisons
다음은 동일한 개념 이미지들에 대한 합성 결과를 비교한 것이다.

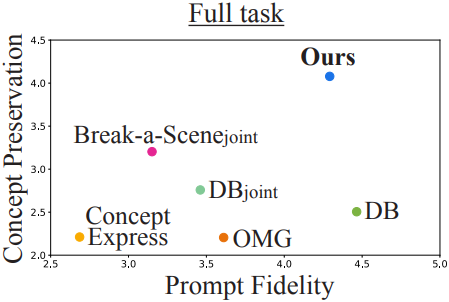
다음은 DreamBench++를 이용하여 정량적으로 비교한 결과이다.

다음은 user study 결과이다.
3. Ablation study
다음은 ablation 결과이다.

Limitations

- Modulation 벡터들이 각 개념 이미지로부터 독립적으로 학습되기 때문에 두 벡터가 비슷할 수 있다.
- 같은 이름을 가진 개념들을 합성하는 데 어려움을 겪는다.
- 호환되지 않은 합성의 경우 합성에 실패한다.