[논문리뷰] Token Merging: Your ViT But Faster
ICLR 2023 (Oral). [Paper] [Github]
Daniel Bolya, Cheng-Yang Fu, Xiaoliang Dai, Peizhao Zhang, Christoph Feichtenhofer, Judy Hoffman
Georgia Tech | Meta AI
17 Oct 2022
Introduction
대규모 ViT 모델을 실행하는 것은 번거로울 수 있으며, 더 빠른 아키텍처로 일반 ViT의 결과를 재현하는 것은 어려운 일이다. 최근 transformer의 입력 독립적 특성을 활용하여 런타임에 토큰을 제거(pruning)하여 더 빠른 모델을 구현하는 방법들이 등장했다. 그러나 토큰 제거에는 몇 가지 단점이 있다. 토큰 제거로 인한 정보 손실로 인해 합리적으로 줄일 수 있는 토큰 수가 제한되고, 효과를 보려면 모델을 재학습해야 하며 (일부는 추가 파라미터 필요), 대부분의 방법은 학습 속도를 높이는 데 적용할 수 없다. 또한, 입력에 따라 제거되는 토큰 개수가 다르기 때문에 batch로 inference 하는 것이 불가능하다.
본 논문에서는 토큰을 제거하는 대신 결합하는 Token Merging (ToMe) 기법을 제시하였다. 맞춤형 매칭 알고리즘을 사용했기 때문에, ToMe는 pruning 기법만큼 빠르면서도 정확도는 더 높다. 또한, 학습 여부와 관계없이 적용 가능하므로, 정확도 저하를 최소화하면서 대규모 모델에서도 활용 가능하다. 학습 과정에서 ToMe를 적용하면 학습 속도가 실제로 향상되는 것을 확인할 수 있으며, 경우에 따라 전체 학습 시간을 절반으로 단축하기도 한다. 또한, 저자들은 이미지, 동영상, 오디오에 아무런 수정 없이 ToMe를 적용했으며, 모든 경우에서 SOTA와 경쟁력을 갖춘 것으로 나타났다.
Method
본 논문의 목표는 기존 ViT에 토큰 병합 모듈을 삽입하는 것이다. 중복 토큰을 병합함으로써, 학습을 별도로 수행하지 않고도 처리량을 높일 수 있기를 기대한다.
전략
Transformer의 각 block에서 토큰을 병합하여 layer당 $r$만큼 줄인다. $r$은 비율이 아니라 토큰의 양이다. 즉, 네트워크의 $L$개 블록에 걸쳐 $rL$개의 토큰을 점진적으로 병합한다. $r$을 변경하면 속도와 정확도 사이에 trade-off가 발생한다. 토큰이 적을수록 정확도는 떨어지지만 처리량은 증가하기 때문이다. 입력 이미지에 관계없이 $rL$개의 토큰을 줄이기 때문에 batch로 inference하거나 학습할 수 있어 실용적이다.
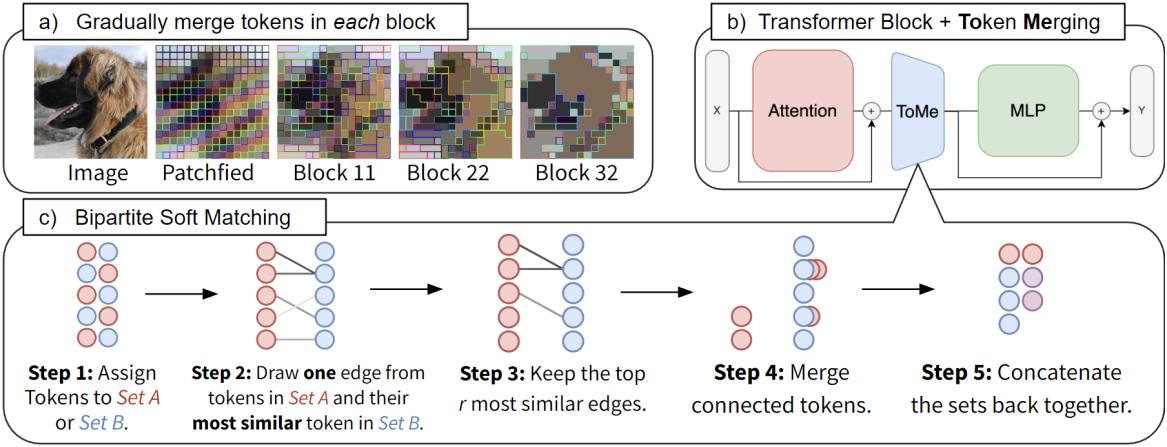
위 그림에서 볼 수 있듯이, 각 transformer block의 attention과 MLP branch 사이에 토큰 병합 단계를 적용한다. 이러한 배치를 통해 병합될 토큰에서 정보를 전파하고, attention 내의 feature를 사용하여 병합할 대상을 결정할 수 있게 되었으며, 이 두 가지 모두 정확도를 향상시킨다.
토큰 유사도
유사한 토큰을 병합하기 전에 먼저 유사함의 의미를 정의해야 한다. 두 토큰의 feature 간 거리가 짧다면 두 토큰을 유사하다고 부르고 싶을 수 있지만, 이는 반드시 최적의 방법은 아니다. 최신 transformer의 중간 feature space는 overparameterize되어 있다. 예를 들어, ViT-B/16은 각 토큰의 RGB 픽셀 값을 완전히 인코딩할 수 있는 충분한 feature를 가지고 있다. 즉, 중간 feature에는 유사도 계산을 방해할 만큼 노이즈가 포함될 가능성이 있다.
다행히도 transformer는 QKV self-attention을 통해 이 문제를 기본적으로 해결한다. 구체적으로, key는 내적 유사도에 사용하기 위해 각 토큰에 포함된 정보를 이미 요약하고 있다. 따라서 각 토큰의 key 간의 cosine similarity를 사용하여 어떤 토큰이 유사한 정보를 포함하는지 확인할 수 있다.
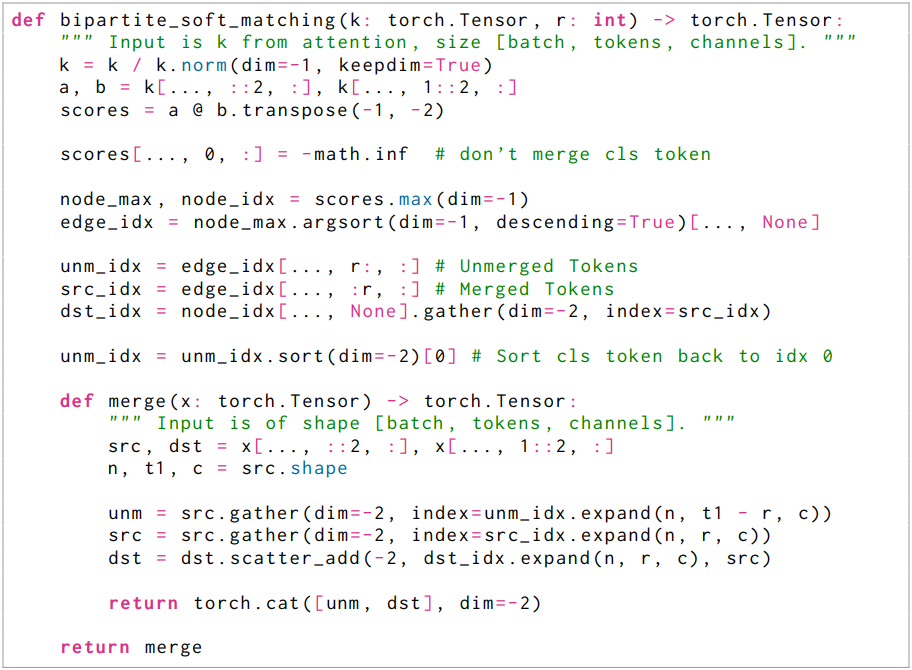
Bipartite Soft Matching
토큰 유사도가 정의되었으므로, 총 토큰 수를 $r$만큼 줄이기 위해 어떤 토큰을 매칭할지 빠르게 판단하는 방법이 필요하다. 네트워크 내에서 잠재적으로 수천 개의 토큰에 대해 $L$번 매칭을 수행해야 하므로, 실행 시간은 절대적으로 무시할 수 있어야 한다. 대부분의 반복적인 클러스터링 알고리즘은 실행 시간이 오래 걸린다.
따라서 병렬화할 수 없는 반복적인 것들을 피하고, 병합으로 인한 변화가 점진적으로 이루어지는 것이 중요하다. 클러스터링은 하나의 그룹으로 병합할 수 있는 토큰 수에 제한을 두지 않기 때문에 변화가 점진적으로 이루어지지 않는다. 반면 매칭은 대부분의 토큰을 병합하지 않은 상태로 둔다.
저자들의 알고리즘은 다음과 같다.
- 토큰을 크기가 거의 같은 두 개의 집합 $\mathbb{A}$와 $\mathbb{B}$로 나눈다.
- $\mathbb{A}$의 각 토큰에서 $\mathbb{B}$의 가장 유사한 토큰으로 가는 edge를 하나씩 그린다.
- 가장 유사한 edge $r$개를 유지한다.
- 여전히 연결된 토큰을 병합한다 (ex. 각 토큰의 feature를 평균화).
- 두 집합을 다시 concat한다.
이렇게 하면 bipartite graph가 생성되고 $\mathbb{A}$의 각 토큰은 edge가 하나만 있으므로 4번에서 연결 요소(connected component)를 찾는 것은 간단하다. 또한, 모든 토큰 쌍 간의 유사도를 계산할 필요가 없다. $\mathbb{A}$와 $\mathbb{B}$를 신중하게 선택하면 정확도에 문제가 되지 않는다. 실제로 이 bipartite soft matching은 토큰을 무작위로 제거하는 것만큼 빠르며, 구현하는 데 몇 줄의 코드만 필요하다.
토큰 크기 추적
토큰이 병합되면 더 이상 하나의 입력 패치를 나타내지 않는다. 이는 softmax attention의 결과를 바꿀 수 있다. 동일한 key를 가진 두 토큰을 병합하면 해당 key가 softmax 항에 미치는 영향이 줄어든다. 이 문제는 proportional attention이라는 간단한 변경을 통해 해결할 수 있다.
\[\begin{equation} \textbf{A} = \textrm{softmax} \left( \frac{\textbf{Q} \textbf{K}^\top}{\sqrt{d}} + \log \textbf{s} \right) \end{equation}\]여기서 $s$는 각 토큰의 크기, 즉 토큰이 나타내는 패치 수를 나타내는 행 벡터이다. 이는 key의 사본 $s$개를 가지고 있는 것과 동일한 연산을 수행한다. 또한 토큰을 병합할 때처럼 토큰을 집계할 때마다 $s$만큼 가중치를 적용해야 한다.
병합과 함께 학습
앞서 설명한 부분들은 이미 학습된 ViT 모델에 token merging을 추가할 수 있도록 설계되었다. ToMe를 사용한 학습은 필수는 아니지만, 정확도 저하를 줄이거나 학습 속도를 높이기 위해 바람직할 수 있다. 학습을 위해 토큰 병합을 pooling 연산으로 처리하고, 마치 average pooling을 사용하는 것처럼 병합된 토큰을 통해 backprop한다. Token pruning에서처럼 Gumbel softmax와 같은 기법을 사용할 필요는 없다. 실제로 저자들은 일반 ViT 학습에 사용된 것과 동일한 설정이 여기에서도 최적임을 확인했다. 따라서 ToMe는 학습 속도를 높이기 위한 간편한 대체 수단이다.
Image Experiments
1. Design Choices
다음은 ablation study 결과이다.
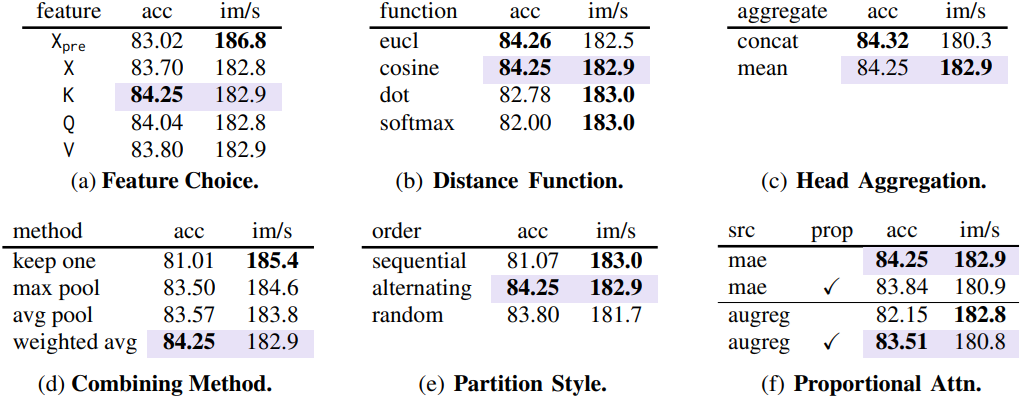
다음은 매칭 알고리즘에 대한 비교 결과이다.

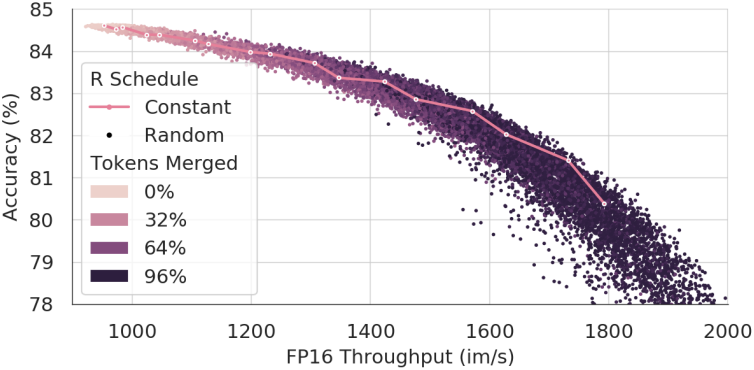
다음은 병합 스케줄에 대한 비교 결과이다.
2. Model Sweep
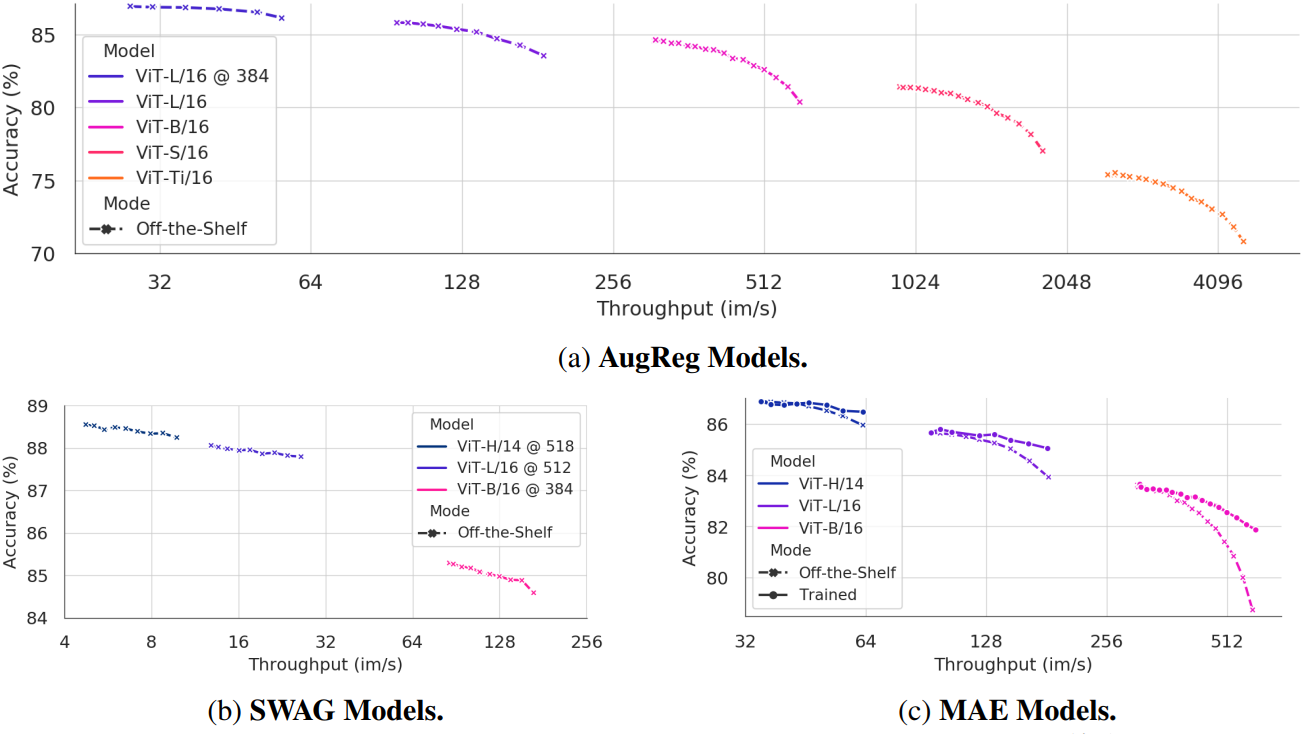
다음은 AugReg (supervised), SWAG (weakly supervised), MAE (self-supervised)에 대하여 학습 없이 ToMe를 적용한 결과이다.
3. Comparison to Other Works
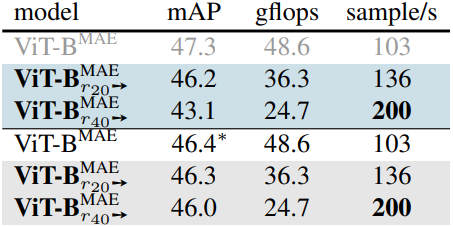
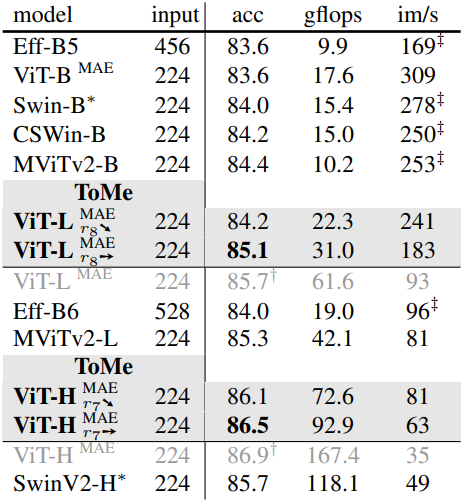
다음은 ImageNet-1k에서 SOTA 모델과 비교한 결과이다. ($r_x$➙는 매 layer마다 $x$개의 토큰을 병합, $r_x$➘는 첫 번째 layer에서 $2x$개, 마지막 layer에서 0개를 병합하는 점진적 감소 방식)
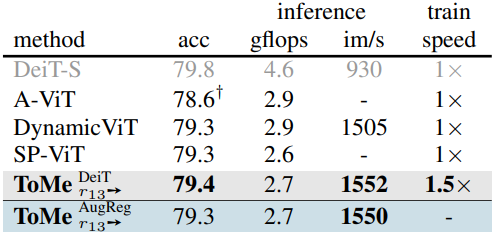
다음은 token pruning 방법과의 비교 결과이다.
4. Visualizations
다음은 병합된 토큰들을 시각화한 결과들이다.

Video & Audio Experiments
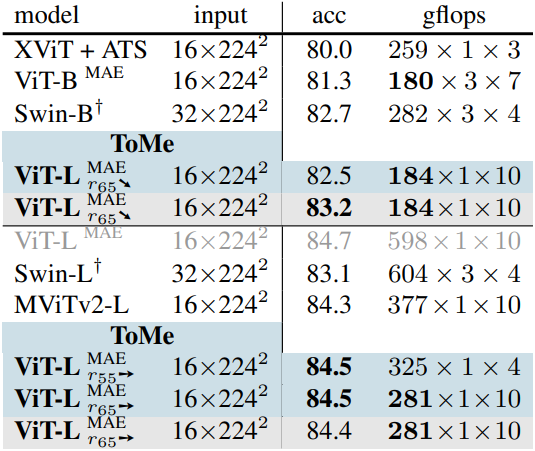
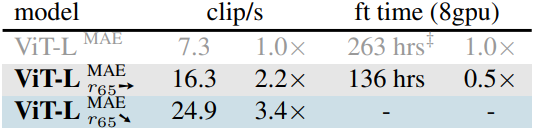
다음은 (왼쪽) Kinetics-400에서 SOTA 모델들과 비교한 성능과 (오른쪽) inference 속도 및 fine-tuning 시간을 비교한 결과이다. (파란색은 학습 없이, 회색은 MAE fine-tuning 적용)
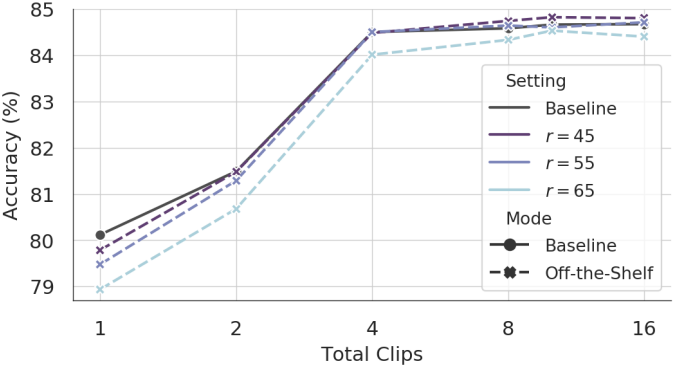
다음은 전체 클립 수에 대한 정확도를 비교한 결과이다.
다음은 AudioSet-2M에서의 성능을 비교한 결과이다.