[논문리뷰] Improved Masked Image Generation with Token-Critic
ECCV 2022. [Paper]
José Lezama, Huiwen Chang, Lu Jiang, Irfan Essa
Google Research
9 Sep 2022

Introduction
클래스 조건부 이미지 합성은 현실적인 디테일과 시각적 아티팩트가 거의 없거나 전혀 없는 다양하고 의미론적으로 유의미한 이미지를 생성해야 하는 까다로운 task이다. 이 분야는 크게 GAN, diffusion model, vector-quantized (VQ) latent space를 사용하는 transformer 기반 모델이 인상적인 발전을 보였다. 이러한 각 기술은 모델 크기, 샘플링 계산 비용, 이미지 품질 및 다양성을 절충하는 서로 다른 이점을 제공한다.
자연어 생성 task를 위한 transformer를 기반으로 하는 ViT는 인상적인 이미지 생성 성능을 달성했다. 초기 연구들에서는 VQ latent space에 autoregressive transformer를 적용했지만 최근에는 BERT와 non-autoregressive 샘플링에서 영감을 받은 mask-and-predict 학습을 사용하는 MaskGIT라는 새 모델로 더욱 발전했다.
Inference 중에 MaskGIT는 모든 토큰이 가려진 빈 캔버스에서 시작한다. 각 step에서 모든 토큰을 병렬로 예측하지만 예측 점수가 가장 높은 토큰만 유지한다. 나머지 토큰은 마스킹되고 몇 번의 iteration으로 모든 토큰이 생성될 때까지 다음 iteration에서 다시 리샘플링된다. MaskGIT의 non-autoregressive 특성은 수십 배 더 빠른 샘플링을 허용하여 autoregressive transformer와 diffusion model의 수백 step과 달리 일반적으로 8~16 step으로 이미지를 생성한다.
반복적인 non-autoregressive 생성의 핵심 과제 중 하나는 유지해야 할 토큰 수와 각 샘플링 step에서 리샘플링할 토큰을 아는 것이다. 예를 들어 MaskGIT는 미리 정의된 masking schedule을 사용하고 모델의 예측이 더 확실한 예측 토큰을 유지한다. 그러나 이 절차에는 세 가지 중요한 단점이 있다.
- 리샘플링할 토큰을 선택하기 위해 모델링 오차에 민감할 수 있는 generator의 예측 신뢰도에 의존한다.
- 거부 또는 수락 결정은 각 토큰에 대해 독립적으로 이루어지므로 토큰 간의 풍부한 상관 관계를 캡처하는 데 방해가 된다.
- 샘플링 절차는 greedy하고 “후회할 수 없는” 것이므로 최신 컨텍스트에서 가능성이 낮아진 토큰이더라도 이전에 샘플링된 토큰을 수정할 수 없다.
본 논문에서는 generator의 출력을 입력으로 사용하는 두 번째 transformer인 Token-Critic을 제안한다. 직관적으로, Token-Critic은 실제 분포 하에 있을 가능성이 있는 토큰의 구성과 generator에서 샘플링된 구성을 인식하도록 학습된다. 반복 샘플링 프로세스 중에 Token-Critic에서 예측한 점수는 유지되는 토큰 예측과 다음 iteration에서 마스킹 및 리샘플링되는 토큰 예측을 선택하는 데 사용된다.
Token-Critic을 사용하여 앞서 언급한 세 가지 제한 사항을 해결한다.
- 토큰의 마스킹은 실제 분포에서 가능성이 없는 토큰을 구별하도록 학습된 Token-Critic 모델에 위임된다.
- Token-Critic은 전체 샘플링된 토큰 집합을 집합적으로 살펴보므로 토큰 간의 상관 관계를 캡처할 수 있다.
- 제안된 샘플링 절차는 반복 디코딩 중에 이전에 샘플링된 토큰을 수정할 수 있도록 한다.
Token-Critic을 사용할 때 MaskGIT는 ImageNet 256$\times$256과 512$\times$512 클래스 조건부 생성에서 성능을 크게 향상시키면서 이미지 품질과 다양성 사이에서 더 나은 trade-off를 달성한다. 또한 Token-Critic을 사용하여 얻은 이득은 거부 샘플링을 위해 사전 학습된 ResNet classifier로 얻은 이득을 보완한다. Classifier 기반 거부 샘플링과 결합된 경우 Token-Critic은 이미지 합성 품질에서 classifier guidance를 통해 SOTA 연속 diffusion model과 유사하거나 능가하는 동시에 inference 중에 이미지 생성 속도가 2배 더 빠르다.
Method
Token-Critic의 목표는 non-autoregressive transformer 기반 generator의 반복 샘플링 프로세스를 가이드하는 것이다. Generator에 의해 출력된 토큰화된 이미지가 주어지면 Token-Critic은 각 토큰에 대한 점수를 제공하는 두 번째 transformer로 설계되어 토큰이 주어진 상황에서 실제 분포 아래에 있는지 여부를 나타낸다.
1. Training the Token-Critic
Token-Critic의 학습 절차는 간단하다. 마스킹된 이미지와 생성적 non-autoregressive transformer에 의한 완성된 이미지가 주어지면 Token-Critic은 결과 이미지의 어떤 토큰이 원래 마스킹되었는지 구별하도록 학습된다.
실제 VQ 이미지를 $x_0$, 랜덤 이진 마스크를 $m_t$, 결과 마스크 이미지를 $x_t = x_0 \odot m_t$라 하자. 인덱스 $t$는 마스킹 비율을 나타낸다. 먼저, $\theta$로 parameterize된 transformer $G_\theta$는 마스킹된 토큰을 예측하는 데 사용된다. 즉, 클래스 인덱스 $c$를 조건으로 \(p_\theta (\hat{x}_0 \vert x_t, c)\)에서 \(\tilde{x}_0\)를 샘플링한다. 여기서 flatten된 시각적 토큰 집합에 클래스 토큰을 추가한다. $x_t$의 마스킹되지 않은 토큰은 \(\hat{x}_0 = \tilde{x}_0 \odot (1 − m_t) + x_0 \odot m_t\) 형식으로 출력에 복사된다.
$\phi$로 parameterize된 Token-Critic transformer는 \(\hat{x}_0\)를 입력으로 받아 $m_t$에 대해 예측된 이진 마스크를 출력한다. 학습 중에 파라미터 $\phi$는 다음 목적 함수를 최소화하도록 최적화된다.
\[\begin{equation} \mathcal{L}_i = \mathbb{E}_{q(x_0, c), q(t), q(m_t \vert t), p_\theta (\hat{x}_0 \vert m_t \odot x_0, c)} [\sum_{j=1}^N \textrm{BCE} (m_t^{(j)}, p_\phi (m_t^{(j)} \vert \hat{x}_0, c))] \end{equation}\]여기서 $q(x_0, c)$는 마스킹되지 않은 실제 이미지의 분포, $q(t)$는 timestep의 분포, $q(m_t \vert t)$는 이진 마스크의 분포이다. BCE는 binary cross-entropy loss를 나타낸다. Generator $G_\theta$에 의해 유도된 샘플링 분포 \(p_\theta (\hat{x}_0 \vert m_t \odot x_0)\)는 Token-Critic 모델의 학습 중에 고정된다.

학습 알고리즘은 Algorithm 1에서 요약된다. $\gamma(t) \in (0, 1)$은 코사인 마스크 스케줄링 함수이다. $q(t) = \mathcal{U}(0, 1)$에서 샘플링된 균일한 난수 $t$가 주어지면 $m_t$의 마스킹된 토큰 수는 $r = \lceil N \cdot \gamma (t) \rceil$로 계산된다. 여기서 $N$은 이미지 내의 총 토큰 수이다.
2. Sampling with Token-Critic
Inference하는 동안 마스킹된 토큰을 vocabulary의 실제 코드로 점진적으로 대체하는 데 관심이 있다. 완전히 마스킹된 이미지 $x_T$와 클래스 조건 $c$에서 시작하여 다음과 같이 근사할 수 있는 $p(x_{t-1} \vert x_t, c)$에서 반복적으로 샘플링한다.
\[\begin{aligned} p (x_{t-1} \vert x_t, c) &= \sum_{x_0} p_\phi (x_{t-1} \vert x_0, c) p_\theta (x_0 \vert x_t, c) \\ &= \mathbb{E}_{x_0 \sim p_\theta (x_0 \vert x_t, c)} [p_\phi (x_{t-1} \vert x_0, c)] \\ &\approx p_\phi (x_{t-1} \vert \hat{x}_0, c), \quad \hat{x}_0 \sim p_\theta (x_0 \vert x_t, c) \end{aligned}\]MaskGIT의 마스크 계산은 예측 점수 $p_\theta (x_0 \vert x_t, c)$에만 의존하며 예측 점수가 가장 낮은 토큰이 마스킹된다. 마스크 샘플링은 각 토큰에 대해 독립적이며 이전에 마스킹되지 않은 토큰이 영원히 마스킹되지 않은 상태로 유지된다 (greedy). 대조적으로 제안된 마스크 샘플링은 토큰 간의 상관 관계를 고려하여 결합 분포에서 샘플링을 근사화하기 위해 Token-Critic 모델 $\phi$에 의해 학습된다. 이것은 특히 더 나은 생성 품질로 이어지는 샘플링을 향상시킨다. 또한 Token-Critic은 가장 최근 생성을 기반으로 이전 결정을 취소할 수 있도록 한다.

샘플링 프로세스는 Algorithm 2에서 제공된다. 각 step의 마스킹 비율은 스케줄링 함수 $\gamma (t)$에 의해 제공된다 ($t = T-1, \ldots, 0$). 여기서 높은 값의 $t$는 더 많은 마스킹에 해당한다. 각 단계에서 $m_t$를 예측한 후 가장 낮은 Token-Critic 점수를 가진 $R = \lceil \gamma (t/T) \cdot N \rceil$개의 토큰을 마스킹한다. 다음으로, 첫 번째 step에서 무작위성을 도입하기 위해 순위를 매기기 전에 Token-Critic 점수에 작은 “선택 노이즈” $n(t)$를 추가한다. 이 선택 noise는 $n(t) = K \cdot u \cdot (t/T)$에 따라 어닐링되며, 여기서 $K$는 hyperparameter이고 $u \in [-0.5, 0.5]^N$이다. 또한 각 토큰의 샘플링 temperature는 linear schedule $T(t) = a \cdot (t/T) + b$에 따라 어닐링된다.
샘플링 식에서 주어진 $x_0$에 대해 $x_{t−1}$이 $x_t$와 독립적으로 만들어진다는 가정을 사용한다. 이 가정은 이전 마스크 $m_t$를 \(\hat{x}_0\)에 concat하여 Token-Critic의 입력을 간단히 조정함으로써 삭제할 수 있다. 그러나 실제로는 이것이 더 나은 결과를 가져오지 않는다. 실제로 Token-Critic은 이전 마스크를 무시함으로써 더 이상 최신 컨텍스트에 맞지 않을 가능성이 있는 이전에 샘플링된 토큰을 수정할 수 있는 능력이 있다. 이는 MaskGIT 모델의 greedy한 마스크 선택을 해결한다.
3. Relation to Discrete Diffusion Processes
Token-Critic의 역할은 마스킹에 의해 점차적으로 정보를 파괴하는 확률적 과정이 존재한다고 가정하는 discrete diffusion process의 관점에서도 이해할 수 있다. 이 설정에서 reverse process는 마스킹된 토큰을 실제 분포에 따라 VQ 코드북의 요소로 점진적으로 대체하는 것을 목표로 한다. 본 논문의 경우 이것은 샘플링 절차의 각 step에서 generator $G_\theta$가 하는 일이다. 이상적으로 각 중간 결과는 $G_\theta$를 학습하는 데 사용되는 분포이므로 부분적으로 마스킹된 실제 이미지의 분포 내에 있어야 한다. Token-Critic의 역할은 중간 샘플을 이러한 영역으로 가이드하는 것이다.
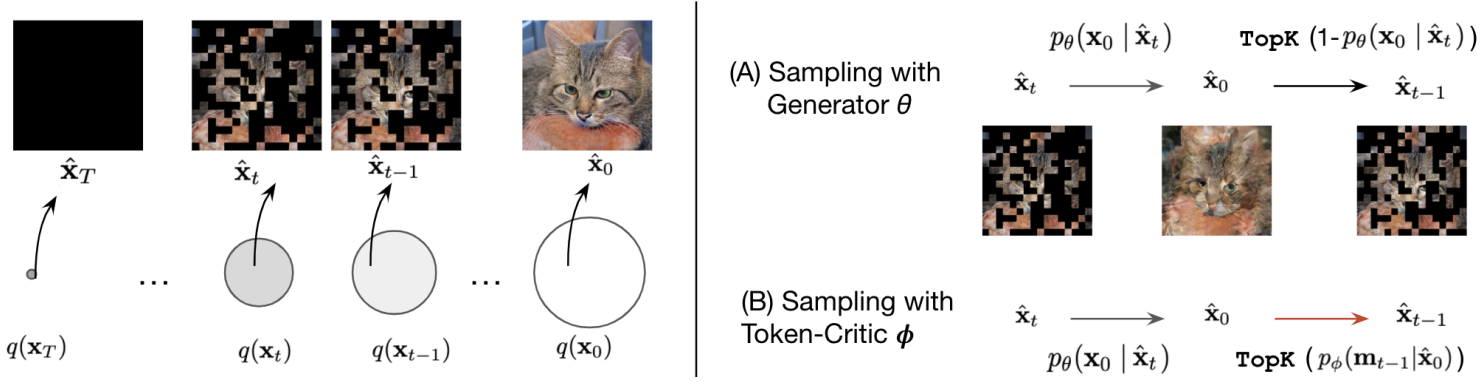
위 그림은 reverse process의 개략도를 나타낸다. 마스킹된 이미지 \(\hat{x}_t\)의 현재 추정치가 주어지면 generator를 사용하여 깨끗한 이미지의 추정치 \(\hat{x}_0\)를 생성한다. 앞서 언급한 모델링 한계로 인해 이 추정치는 일반적으로 실제 이미지의 분포와는 거리가 멀다. 그런 다음 Token-Critic을 사용하여 \(\hat{x}_0\)에서 덜 손상된 이미지 \(\hat{x}_{t-1}\)을 예측한다. 호환되지 않는 토큰을 구별하도록 학습되었기 때문에 가장 “그럴듯해 보이는” 토큰을 마스킹하여 향상된 예측을 달성한다.
Diffusion process 논문에서 깨끗한 이미지의 추정치에 의존하는 유사한 샘플링 전략이 연속적인 경우와 불연속적인 경우에 사용되었다. 접근 방식의 차이점은 사전에 얻은 고정 모델 (ex. Gaussian prior) 대신 학습된 forward model을 암시적으로 사용한다는 것이다. 반면에 이미지 생성을 위한 이전의 discrete diffusion model은 일반적으로 각 토큰에 대해 독립적인 확률적 프로세스를 가정하고 각 토큰이 마스킹되거나 랜덤으로 변환되거나 동일하게 유지될 확률을 정의하는 고정 형식 Markov chain을 제공한다. 독립 가정 하에서도 토큰 카테고리의 수가 많으면 posterior를 얻기 위해 필요한 $n$-step Markov transition matrix의 계산이 비실용적일 수 있다. 이러한 디자인 차이는 부분적으로 고해상도 이미지를 합성할 때 diffusion model의 낮은 효율성을 설명한다. 대신, Token-Critic은 이러한 가정의 수치적 해석 가능성과 취급 용이성을 절충하여 보다 효율적이고 학습된 forward process \(p_\phi (x_t \vert \hat{x}_0)\)를 제공한다.
Experiments
- 데이터셋: ImageNet 256$\times$256, 512$\times$512
- 구현 디테일
- MaskGIT의 VQ 인코더-디코더를 채택
- 코드북 크기: 1024
- ImageNet 256$\times$256로 학습
- 이미지를 16배 압축 (ex. 256$\times$256 이미지는 16$\times$16 정수 그리드로 압축)
- Transformer
- 레이어 수: generator는 24개, Token-Critic은 20개
- head 수: generator는 16개, Token-Critic은 12개
- 임베딩 차원: 768
- hidden 차원: 3,072
- 학습 가능한 positional embedding, LayerNorm, truncated normal initialization (stddev=0.02) 사용
- dropout: 0.1
- optimizer: Adam ($\beta_1$ = 0.9, $beta_2$ = 0.96)
- data augmentation: RandomResizeAndCrop
- batch size: 256
- epoch: 600
- MaskGIT과 동일한 코사인 마스킹 비율 사용
- Token-Critic 샘플링 step: 18
- MaskGIT의 VQ 인코더-디코더를 채택
1. Class-Conditional Image Synthesis
Quantitative Results
다음은 외부 classifier를 활용하지 않는 방법들을 비교한 표이다.
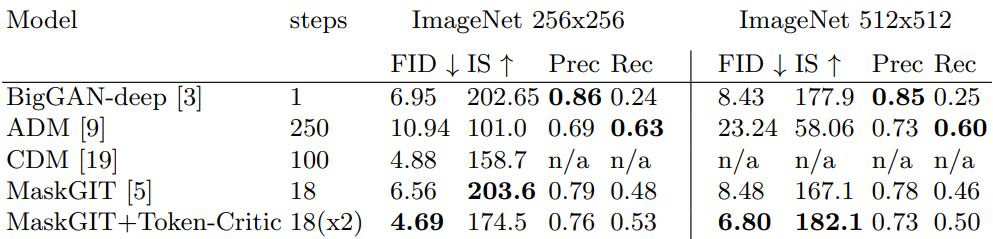
다음은 외부 classifier를 활용하지 않는 방법들의 FID-vs-IS 곡선을 나타낸 그래프이다.
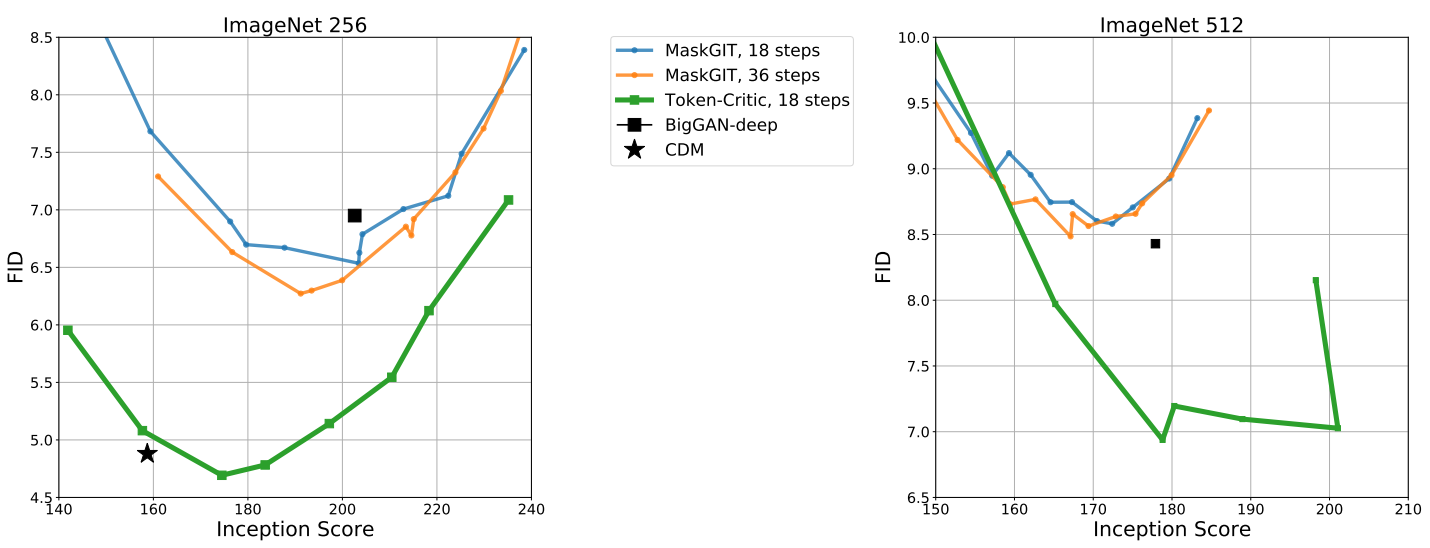
Leveraging an External Classifier
다음은 학습 중이나 샘플링 중에 외부 classifier를 사용하는 방법들을 비교한 표이다.
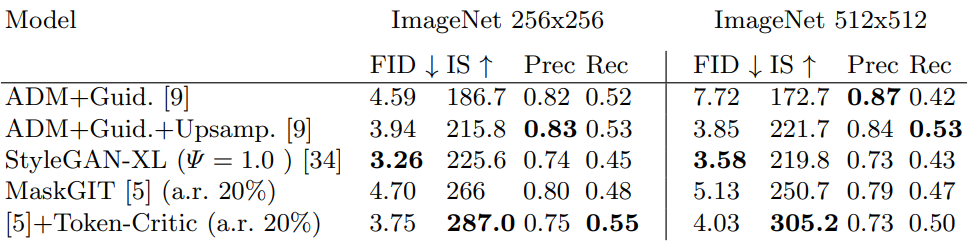
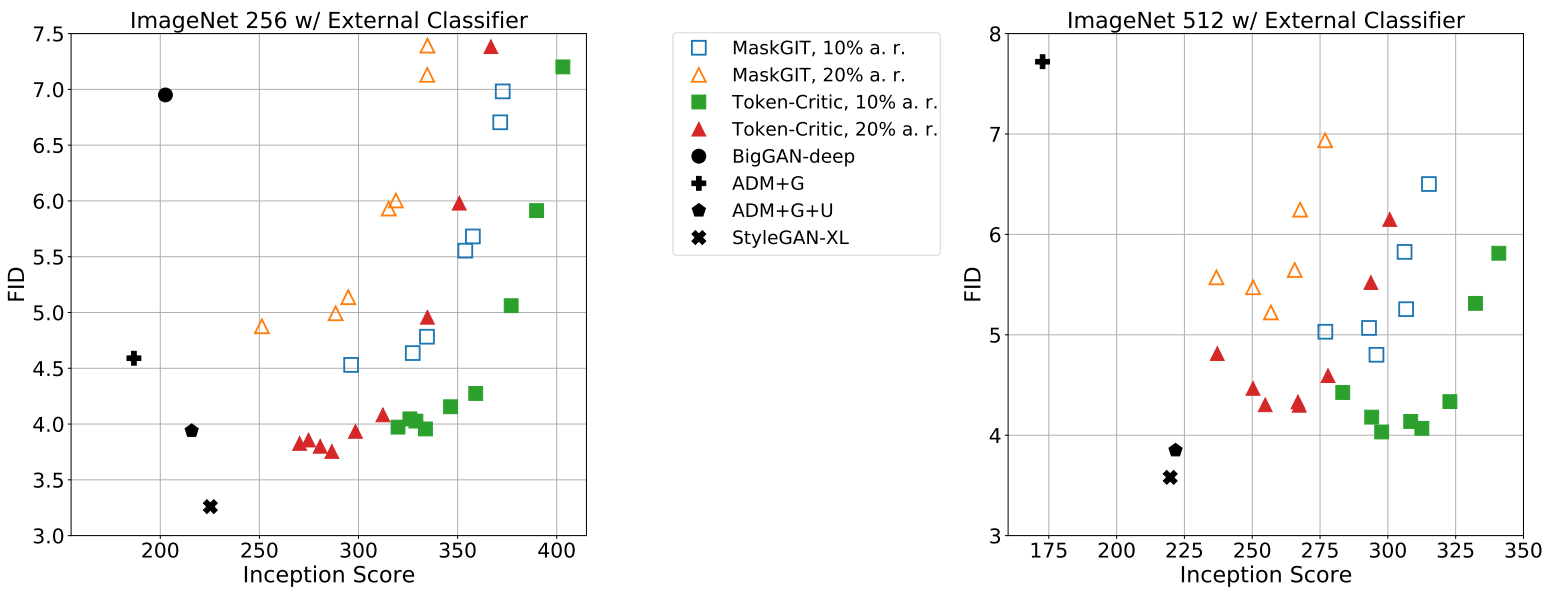
다음은 외부 classifier를 활용한 방법들의 FID-vs-IS 곡선을 나타낸 그래프이다.
Qualitative Results
다음은 ImageNet 512$\times$512 모델의 샘플들을 비교한 것이다.

2. VQ Image Refinement
다음은 이전에 생성된 VQ 이미지들을 Token-Critic으로 개선한 결과이다. 상단은 원본 샘플들 (FID/IS 8.48/167)이고 하단은 60%의 토큰을 Token-Critic 점수로 정제한 후의 샘플들 (FID/IS 7.64/182.4)이다.
