[논문리뷰] An Image is Worth 32 Tokens for Reconstruction and Generation
NeurIPS 2024. [Paper] [Page] [Github]
Qihang Yu, Mark Weber, Xueqing Deng, Xiaohui Shen, Daniel Cremers, Liang-Chieh Chen
ByteDance | Technical University Munich
11 Jun 2024

Introduction
많은 이미지 생성 모델의 아키텍처는 표준 이미지 tokenizer와 de-tokenizer를 통합하였다. 이러한 모델들은 tokenize된 이미지 표현을 활용하여 픽셀을 latent space로 변환한다. Latent space는 원래 이미지 space보다 훨씬 더 컴팩트하며, 압축적이면서도 표현력이 풍부한 표현을 제공하므로 생성 모델의 효율적인 학습과 inference를 용이하게 할 뿐만 아니라 모델 크기를 확장할 수 있는 길을 열어준다.
이미지 tokenizer는 latent 토큰과 이미지 패치 사이의 위치에 대한 직접 매핑을 유지하기 위해 latent space가 2D 구조를 유지해야 한다는 가정에 기반한다. 이는 tokenizer가 이미지에 내재된 중복성을 효과적으로 활용하여 더 압축된 latent space를 만드는 능력을 제한한다.
이미지 tokenization에 2D 구조가 필요한가?
이 질문에 답하기 위해, 저자들은 모델 예측이 입력 이미지에서 추출한 높은 수준의 정보에만 기반하는 여러 이미지 이해 task에서 영감을 얻었다. 이러한 task들에는 출력이 일반적으로 이미지가 아닌 특정 구조로 나타나기 때문에 de-tokenization이 필요하지 않다. 즉, 모든 task 관련 정보를 여전히 캡처할 수 있는 상위 수준의 1D 시퀀스를 출력 형식으로 사용한다. 이러한 방법의 성공은 이미지 재구성 및 생성의 맥락에서 이미지 latent 표현으로서 보다 컴팩트한 1D 시퀀스를 조사하도록 동기를 부여한다. 고품질 이미지를 생성하기 위해 높은 수준의 정보와 낮은 차원의 정보를 모두 통합하는 것이 중요하며, 이는 극도로 압축된 latent 표현에서는 도전 과제가 된다.
본 논문에서는 이미지를 discrete한 1차원 시퀀스로 tokenize하도록 설계된 transformer 기반 프레임워크를 소개한다. 이 시퀀스는 나중에 de-tokenizer를 통해 이미지 space로 다시 디코딩될 수 있다. 구체적으로, ViT 인코더, ViT 디코더, VQ-VAE의 모델 디자인을 따르는 vector quantizer로 구성된 transformer 기반 1D tokenizer인 TiTok을 제시하였다. Tokenization 단계에서 이미지는 일련의 패치로 분할되고 flatten되며, 그 다음에 latent 토큰의 1D 시퀀스와 concat된다. ViT 인코더의 feature 인코딩 프로세스 후, 이러한 latent 토큰들은 이미지의 latent 표현을 구축한다. Vector quantization (VQ) 단계 이후, ViT 디코더는 마스킹된 토큰 시퀀스에서 입력 이미지를 재구성하는 데 활용된다.
Method
1. TiTok: From 2D to 1D Tokenization
기존 VQ 모델은 상당한 성과를 보여주었지만 latent 표현 \(\textbf{Z}_\textrm{2D}\)는 종종 정적인 2D 그리드로 간주된다. 이러한 구성은 본질적으로 latent 그리드와 원본 이미지 패치 간의 엄격한 일대일 매핑을 가정한다. 이 가정은 VQ 모델이 인접 패치 간의 유사성과 같은 이미지에 존재하는 중복성을 완전히 활용하는 능력을 제한한다. 또한 이 접근 방식은 latent 크기 선택의 유연성을 제한하는데, 가장 널리 사용되는 구성은 $f = 4$, $f = 8$, $f = 16$으로, 256$\times$256$\times$3 크기의 이미지에 대해 각각 4096, 1024, 256개의 토큰이 생성된다.
본 논문은 2D tokenization 대신, latent 표현과 이미지 패치 간의 고정된 대응 관계가 없는 1D 시퀀스를 이미지 재구성 및 생성을 위한 효율적이고 효과적인 latent 표현으로 제안하였다.
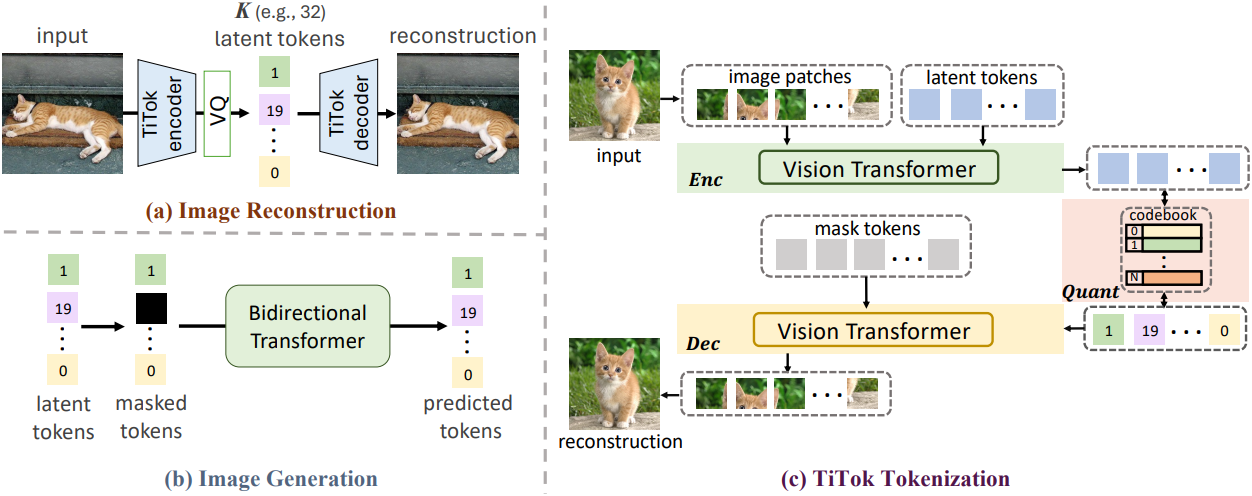
Image Reconstruction with TiTok
저자들은 Transformer-based 1-Dimensional Tokenizer (TiTok)라는 새로운 프레임워크를 확립하고, ViT를 활용하여 이미지를 1D latent 토큰으로 tokenize한 다음 이러한 1D latent 이미지에서 원본 이미지를 재구성한다. TiTok은 tokenization 및 de-tokenization 프로세스 모두에 표준 ViT를 사용한다. 즉, 인코더 $\textrm{Enc}$와 디코더 $\textrm{Dec}$는 모두 ViT이다.
Tokenize하는 동안 이미지를 패치 $\textbf{P} \in \mathbb{R}^{\frac{H}{f} \times \frac{W}{f} \times D}$로 patchify하고 이를 $K$개의 latent 토큰 $\textbf{L} \in \mathbb{R}^{K \times D}$와 concat한다. 그런 다음 이들은 ViT 인코더로 입력된다. 인코더 출력에서 이미지의 latent 표현으로 latent 토큰만 유지하여 길이가 $K$인 컴팩트한 1D 시퀀스 \(\textbf{Z}_\textrm{1D}\)를 얻는다. 이 조정은 latent 크기를 이미지의 해상도에서 분리하고 디자인 선택에 더 많은 유연성을 허용한다.
\[\begin{equation} \textbf{Z}_\textrm{1D} = \textrm{Enc} (\textbf{P} \oplus \textbf{L}) \end{equation}\]($\oplus$는 concatenation, 인코더 출력에서 latent 토큰만 보관)
De-tokenization 단계에서는 하나의 마스크 토큰를 $\frac{H}{f} \times \frac{W}{f}$번 복제하여 얻은 마스크 토큰 시퀀스 \(\textbf{M} \in \mathbb{R}^{\frac{H}{f} \times \frac{W}{f} \times D}\)를 quantize된 latent 토큰 \(\textbf{Z}_\textrm{1D}\)에 통합한다. 그런 다음 이미지는 다음과 같이 ViT 디코더를 통해 재구성된다.
\[\begin{equation} \hat{\textbf{I}} = \textrm{Dec} (\textrm{Quant} (\textbf{Z}_\textrm{1D}) \oplus \textbf{M}) \end{equation}\]2D 그리드 latent 이미지를 1D 시퀀스로 flatten할 수 있지만, 암시적인 2D 그리드 매핑 제약 조건이 여전히 지속되기 때문에 제안된 1D tokenizer와는 상당히 다르다.
Image Generation with TiTok
저자들은 단순성과 효과성 때문에 MaskGIT을 생성 프레임워크로 채택하였으며, 단순히 VQGAN tokenizer를 TiTok으로 대체함으로써 MaskGIT 모델을 학습시킬 수 있다.
이미지는 discrete한 1D 토큰으로 미리 tokenize된다. 각 학습 step에서 랜덤한 비율의 latent 토큰이 마스크 토큰으로 대체된다. 그런 다음 bidirectional transformer가 마스킹된 토큰 시퀀스를 입력으로 사용하여 마스킹된 토큰의 discrete한 토큰 ID를 예측한다. Inference 프로세스는 여러 샘플링 step으로 구성되며, 각 step에서 마스크된 토큰에 대한 transformer의 예측은 예측 신뢰도에 따라 샘플링되고, 이를 사용하여 마스킹된 이미지를 업데이트한다. 이런 방식으로 이미지는 마스크 토큰으로 가득 찬 시퀀스에서 이미지로 점진적으로 생성되며, 나중에 de-tokenize하여 픽셀 공간으로 다시 되돌릴 수 있다.
2. Two-Stage Training of TiTok with Proxy Codes
VQ 모델을 위한 기존 학습 전략
대부분의 VQ 모델은 간단한 공식을 따르지만, 학습 프로세스는 현저히 민감하며, 모델의 성능은 학습 패러다임의 채택에 크게 영향을 받는다. 예를 들어, VQGAN은 DALL-E의 dVAE와 비교했을 때 ImageNet validation set에서 reconstruction FID (rFID)가 상당히 향상되었다. 이러한 향상은 perceptual loss와 adversarial loss의 발전에 기인한다. 게다가 MaskGIT의 VQGAN의 최신 구현은 성능을 더욱 높이기 위해 구조적 개선 없이 정제된 학습 기술을 활용한다.
주목할 점은 이러한 개선 사항의 대부분은 보조 loss를 통해서만 적용되고 모델의 효능에 상당한 영향을 미친다는 것이다. Loss function의 복잡성, 관련된 hyperparameter의 광범위한 튜닝, 공개적으로 사용 가능한 코드 베이스가 없다는 점을 감안할 때, TiTok에 대한 최적의 실험 설정을 확립하는 것은 상당한 과제이며, 특히 거의 연구되지 않은 컴팩트한 1D tokenization인 경우 더욱 그렇다.
2단계 학습
일반적인 VQGAN 설정으로 TiTok을 학습시키는 것이 가능하지만, 저자들은 개선된 성능을 위해 2단계 학습 패러다임을 도입하였다. 2단계 학습 전략에는 “warm-up”과 “디코더 fine-tuning” 단계가 포함된다.
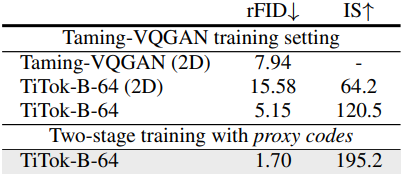
첫 번째 “warm-up” 단계에서는 RGB 값을 직접 회귀하고 다양한 loss function을 사용하는 대신, proxy code라고 하는 기존 MaskGIT-VQGAN 모델에서 생성된 discrete code로 1D VQ 모델을 학습시킨다. 이 접근 방식을 사용하면 복잡한 loss function과 GAN 아키텍처를 우회하여 1D tokenization 설정을 최적화하는 데 집중할 수 있다. 이 수정은 TiTok 내의 tokenizer와 quantizer의 능력에 해를 끼치지 않으며, tokenizer와 quantizer는 여전히 이미지 tokenization과 de-tokenization을 위해 완벽하게 작동할 수 있다.
주요 수정은 단순히 TiTok의 de-tokenizer 출력을 처리하는 것과 관련이 있다. 구체적으로, proxy code 집합으로 구성된 이 출력은 이후 동일한 VQGAN 디코더에 공급되어 최종 RGB 출력을 생성한다. Proxy code의 도입은 단순 distillation과는 다르다.
Proxy code를 사용한 첫 번째 학습 단계 후에 선택적으로 두 번째 “디코더 fine-tuning” 단계를 통해 재구성 품질을 개선한다. 구체적으로, 인코더와 quantizer를 고정하고, 일반적인 VQGAN 학습 레시피를 사용하여 디코더만 픽셀 공간으로 학습시킨다. 이러한 2단계 학습 전략은 학습 안정성과 재구성된 이미지 품질을 크게 개선한다.
Experiments
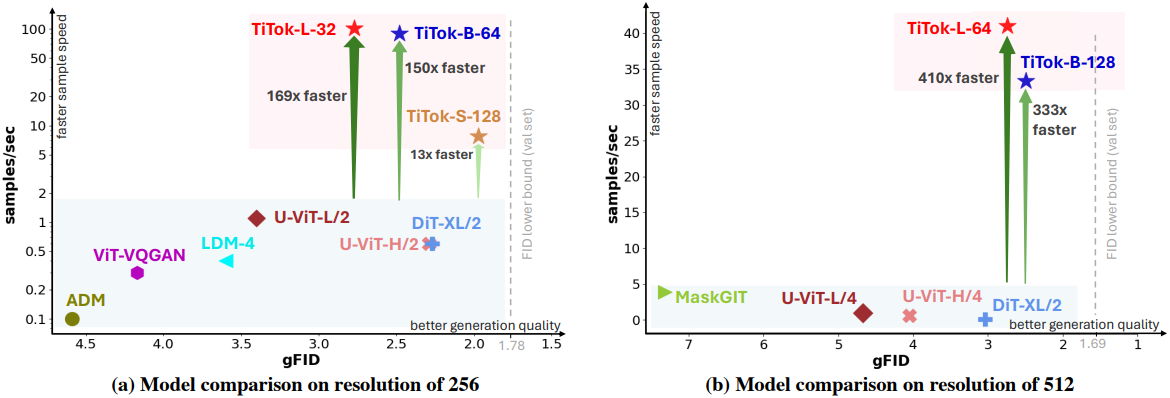
1. Preliminary Experiments of 1D Tokenization
다음은 ImageNet-1K에서의 (a) 재구성, (b) linear probing, (c) 생성, (d) 샘플링 속도를 비교한 그래프이다.
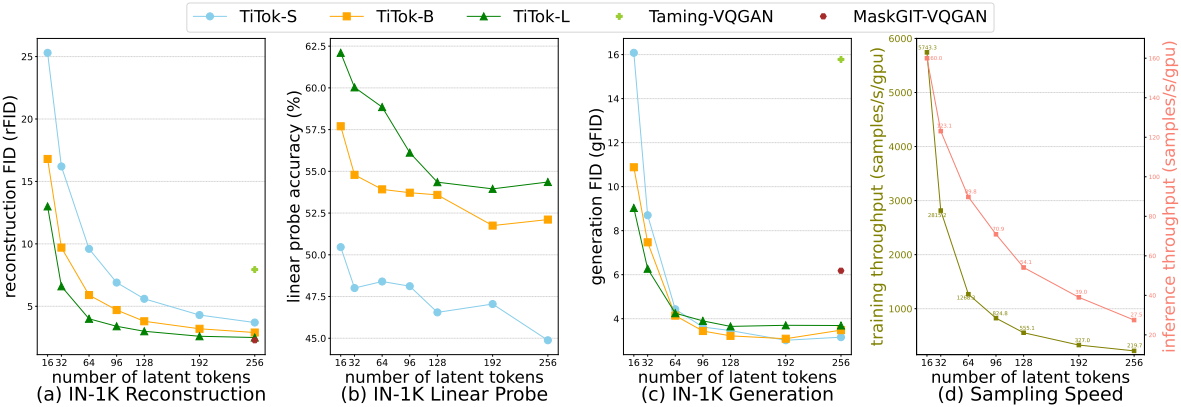
2. Main Experiments
다음은 ImageNet-1K에서의 (위) 256$\times$256과 (아래) 512$\times$512 생성 결과이다. (P는 generator의 파라미터 수, S는 샘플링 step 수, T는 A100에서 초당 생성할 수 있는 샘플 수)
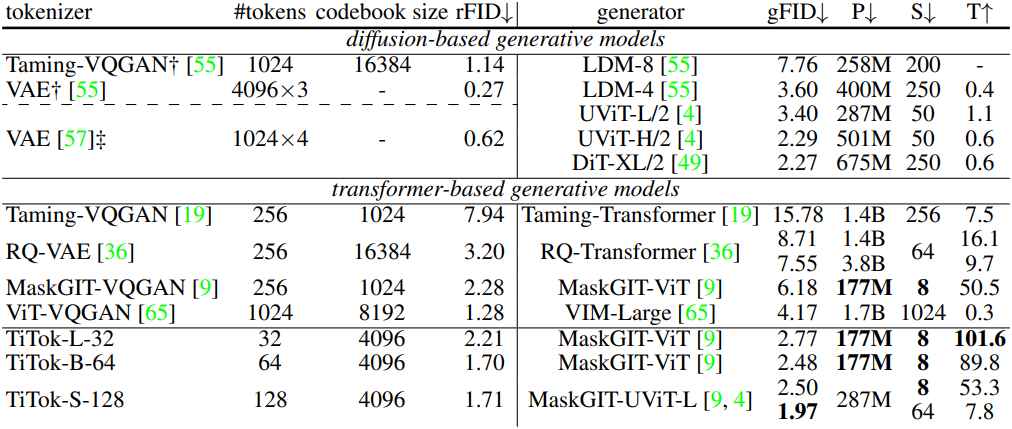
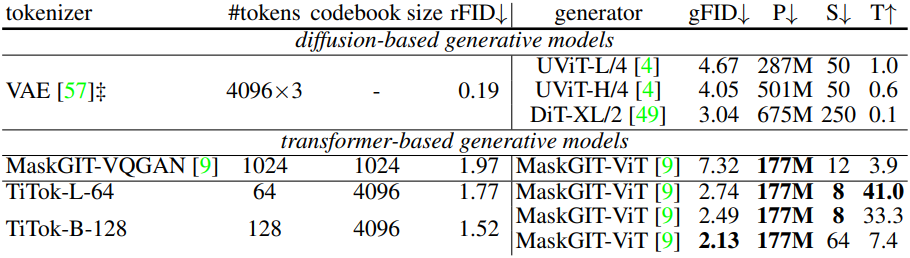
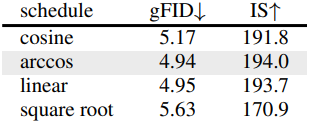
3. Ablation Studies
다음은 구성 요소, 마스킹 schedule, proxy code에 대한 ablation 결과이다.