[논문리뷰] TextureDreamer: Image-guided Texture Synthesis through Geometry-aware Diffusion
CVPR 2024. [Paper] [Page]
Yu-Ying Yeh, Jia-Bin Huang, Changil Kim, Lei Xiao, Thu Nguyen-Phuoc, Numair Khan, Cheng Zhang, Manmohan Chandraker, Carl S Marshall, Zhao Dong, Zhengqin Li
University of California, San Diego | University of Maryland, College Park | Meta
17 Jan 2024

Introduction
최근 몇 년 동안 3D reconstruction과 생성 모델의 발전으로 인해 3D 콘텐츠 제작에 있어 놀라운 진전이 이루어졌지만, 고품질 텍스처를 만드는 것은 상대적으로 연구가 부족하며, 사실적인 텍스처를 제작하는 것은 굉장히 어렵고 전문가의 노력이 필요했다.
본 논문은 몇 개의 이미지에서 고품질의 텍스처를 생성하는 새로운 프레임워크인 TextureDreamer를 소개한다. 물체의 무작위로 샘플링된 3~5개의 뷰가 주어지면, 다른 카테고리의 타겟 메쉬로 텍스처를 전송할 수 있다. 반면, 이전의 텍스처 생성 방법은 일반적으로 정렬된 형상이 있는 많은 뷰가 필요하거나 같은 카테고리에만 작동할 수 있었다.
TextureDreamer는 사전 학습된 text-to-image diffusion model을 사용한다. 이전 연구들에서는 2D diffusion model을 텍스트 기반 3D 콘텐츠 생성에 적용했지만, 텍스트 전용 입력이 복잡하고 자세한 패턴을 설명하기에 충분히 표현력이 없다는 한계점이 있었다. 텍스트 기반 방법과 달리, TextureDreamer는 고유한 텍스트 토큰으로 사전 학습된 diffusion model을 fine-tuning하여 작은 입력 이미지 세트에서 텍스처 정보를 효과적으로 추출한다. 이를 통해 복잡한 텍스처를 정확하게 설명하는 과제를 해결하였다.
Score Distillation Sampling (SDS)은 사전 학습된 2D diffusion model에서 정의한 분포와 렌더링된 이미지의 분포 간의 불일치를 최소화하여 3D 콘텐츠를 생성하고 편집하는 데 널리 사용된다. 하지만, 두 가지 잘 알려진 한계점으로 인해 고품질 텍스처를 생성하는 데 방해가 된다. 첫째, 이 방법은 수렴하는 데 필요한 비정상적으로 높은 classifier-free guidance (CFG)로 인해 지나치게 매끄럽고 채도가 높은 외형을 만드는 경향이 있다. 둘째, 3D와 일관된 모양을 생성하는 지식이 부족하여 종종 Janus problem 및 텍스처와 형상 간의 불일치가 발생한다.
저자들은 이러한 과제를 해결하기 위해 두 가지 핵심적인 디자인 선택을 제안하였다. SDS를 사용하는 대신 최적화 접근 방식에서 Variational Score Distillation (VSD)을 기반으로 하여 훨씬 더 사실적이고 다양한 텍스처를 생성할 수 있다. VSD는 수렴하는 데 큰 CFG 가중치가 필요하지 않으며, 이는 사실적이고 다양한 모양을 만드는 데 필수적이다. 그러나 단순하게 VSD 업데이트를 적용하는 것만으로는 고품질 텍스처를 생성하는 데 충분하지 않다. 저자들은 작은 수정을 통해 계산 비용을 약간 줄이는 동시에 텍스처 품질을 개선하였다.
또한 VSD loss만으로는 3D 일관성 문제를 완전히 해결할 수 없다. 적은 입력 이미지에 대한 fine-tuning은 수렴을 더 어렵게 만든다. 따라서 ControlNet 아키텍처를 통해 fine-tuning된 diffusion model에 렌더링된 normal map을 주입하여 주어진 메쉬에서 추출된 형상 정보에 따라 텍스처 생성 프로세스를 명시적으로 컨디셔닝한다.
본 논문의 프레임워크인 personalized geometry aware score distillation (PGSD)는 semantic하게 의미 있고 시각적으로 매력적인 방식으로 매우 자세한 텍스처를 다양한 형상으로 효과적으로 전송할 수 있다.
Method
1. Preliminaries
Score Distillation Sampling (SDS)
Score Distillation Sampling (SDS)은 3D 콘텐츠 생성을 위해 사전 학습된 2D diffusion model을 사용하는 수많은 방법의 핵심 요소이다. 렌더링된 이미지를 사전 학습된 diffusion model로 모델링된 고차원 manifold로 밀어 3D 표현을 최적화한다. $\theta$가 3D 표현이고 \(\epsilon_\psi\)가 사전 학습된 diffusion model이라 할 때, 파라미터 $\theta$로 역전파된 gradient는 다음과 같다.
\[\begin{equation} \nabla_\theta \mathcal{L}_\textrm{SDS} (\theta) = \mathbb{E}_{t, \epsilon} \bigg[ w(t) (\epsilon_\psi (x_t, y, t) - \epsilon) \frac{\partial g (\theta, c)}{\partial \theta} \bigg] \end{equation}\]($w(t)$는 가중치 계수, $y$는 텍스트 입력, $t$는 timestep, $c$는 카메라 포즈, $g$는 미분 가능한 렌더러, $x_t$는 $x = g(\theta, c)$에 noise를 추가한 이미지)
SDS는 널리 사용되지만 수렴하려면 일반적인 classifier-free guidance (CFG)보다 훨씬 더 높은 가중치가 필요하여 지나치게 부드럽고 채도가 높은 외형을 가진다.
Variational Score Distillation (VSD)
이 문제를 극복하기 위해 일반적인 CFG를 사용해도 수렴할 수 있는 Variational Score Distillation (VSD)이 제안되었다. VSD는 전체 3D 표현 $\theta$를 random variable로 취급하고 $\theta$와 사전 학습된 diffusion model에서 정의한 분포 사이의 KL divergence를 최소화한다. 여기에는 3D 표현 $\theta$에서 생성된 noisy한 이미지르 denoise하기 위해 LoRA 네트워크 \(\epsilon_\phi\)와 카메라 포즈 $c$를 임베딩하는 카메라 인코더 $\rho$를 fine-tuning하는 작업이 포함된다.
\[\begin{equation} \min_\phi \mathbb{E}_{t, \epsilon, c} [\| \epsilon_\phi (x_t, y, t, c) - \epsilon \|_2^2] \end{equation}\]3D 표현 $\theta$에 대한 gradient는 다음과 같이 계산된다.
\[\begin{equation} \nabla_\theta \mathcal{L}_\textrm{VSD} (\theta) = \mathbb{E}_{t, \epsilon, c} \bigg[ w(t) (\epsilon_\psi (x_t, y, t) - \epsilon_\phi (x_t, y, t, c)) \frac{\partial g (\theta, c)}{\partial \theta} \bigg] \end{equation}\]VSD는 생성된 3D 콘텐츠의 시각적 품질과 다양성을 크게 개선하지만, 3D 지식의 본질적인 부족으로 인해 3D 일관성 문제를 해결할 수 없어 Janus problem 및 형상과 텍스처 간의 불일치가 발생한다. 본 논문은 형상 정보를 명시적으로 주입하여 diffusion model가 형상을 인식하도록 함으로써 이 문제를 해결하였다.
2. Personalized Geometry-aware Score Distillation (PGSD)
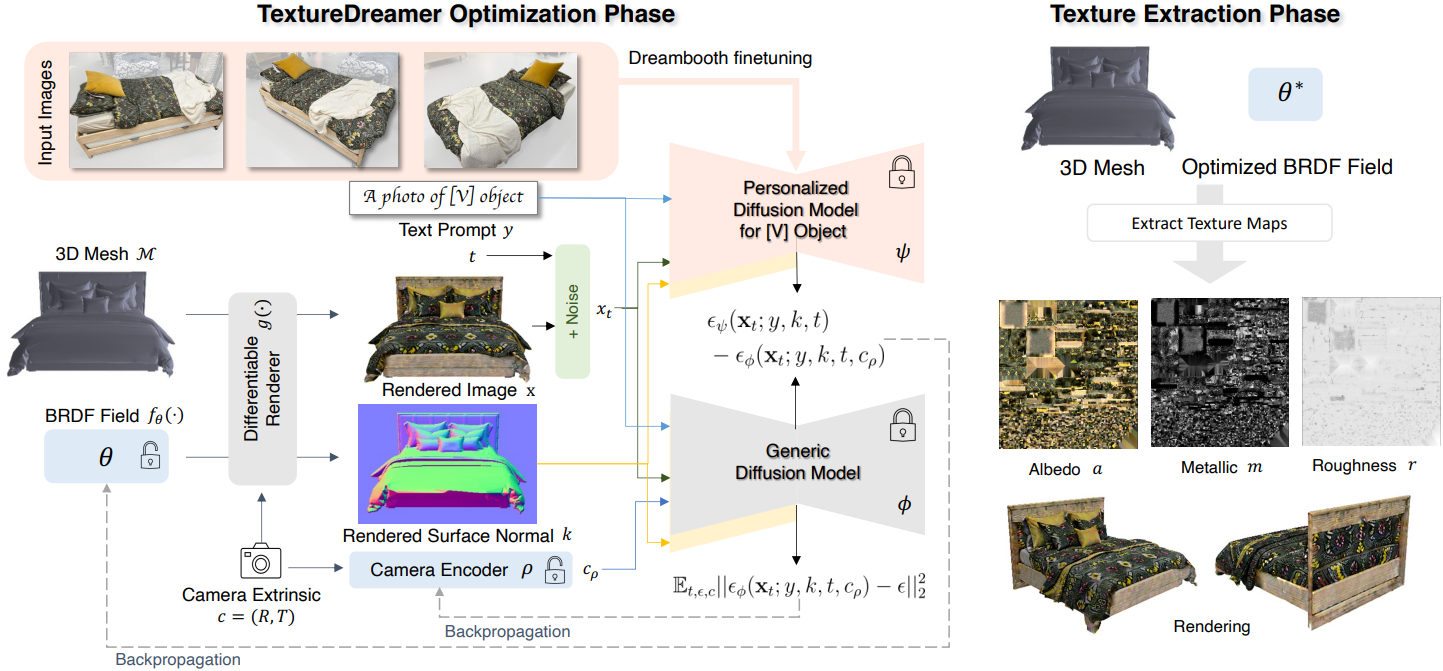
Problem setup
- 입력: 다양한 시점에서 촬영한 3~5개의 이미지 \(\{I\}_{k=1}^K\)와 3D 메쉬 $\mathcal{M}$
- 출력: \(\{I\}_{k=1}^K\)에서 $\mathcal{M}$으로 전송된 텍스처
텍스처는 albedo $a$, roughness $r$, metallic $m$으로 parameterize되며 (표준 microfacet BRDF), neural BRDF field
\[\begin{equation} f_\theta (v) : v \in \mathbb{R}^3 \rightarrow a, r, m \in \mathbb{R}^5 \end{equation}\]로 표현된다 ($v$는 $\mathcal{M}$에서 샘플링한 포인트). $f_\theta$는 multi-scale hash encoding과 MLP로 구성되어 있다.
개인화된 텍스처 정보 추출
Dreambooth는 몇 개의 입력 이미지로 사전 학습된 text-to-image diffusion model을 fine-tuning하여 개인화된 이미지를 생성한다. 본 논문에서는 Dreambooth로 이미지들에서 텍스처 정보를 추출한다.
구체적으로, 텍스트 프롬프트 $y$ = “A photo of [V] object”와 입력 이미지들로 diffusion model을 fine-tuning한다. 여기서 “[V]”는 입력 물체를 설명하는 고유 식별자이다. 먼저 대상 물체의 배경을 흰색으로 마스킹하여 제거한다. Reconstruction loss의 경우 입력 이미지의 짧은 모서리를 512로 resize하고 512$\times$512로 random crop하여 학습시킨다. Dreambooth fine-tuning 모델이 다른 카테고리로 일반화될 수 있기를 바라기 때문에 클래스별 prior preservation loss는 적용하지 않는다.
Geometry-aware score distillation
Dreambooth로 텍스처 정보 추출을 마치면 fine-tuning된 Dreambooth 모델을 VSD를 위한 denoising network $\epsilon_\psi$로 채택하여 메쉬 $\mathcal{M}$으로 정보를 전송한다. 매우 사실적이고 다양한 외형을 생성하는 뛰어난 능력 때문에 SDS 대신 VSD를 사용한다. 이미지 $x$를 렌더링하기 위해 Fantasia3D를 따라 고정된 HDR environment map $E$를 조명으로 미리 선택하고 Nvdiffrast를 미분 가능한 렌더러로 사용한다. Dreambooth 학습을 위해 입력 이미지와 일치하도록 배경을 흰색으로 설정한다. 이렇게 하면 랜덤 색상이나 중립적 배경에 비해 더 나은 색상 충실도를 얻는 데 도움이 된다.
그러나 단순히 SDS를 VSD로 대체하는 것만으로는 2D diffusion model에서 3D 지식이 부족하다는 한계를 해결할 수 없다. 따라서 메쉬 $\mathcal{M}$에서 렌더링된 normal map $k$로 컨디셔닝된 사전 학습된 ControlNet을 통해 개인화된 diffusion model $\epsilon_\psi$에 형상 정보를 주입하는 geometry-aware score distillation를 사용한다. 이 augmentation은 생성된 텍스처의 3D 일관성을 크게 향상시킨다.
$x = g(\theta, c)$를 카메라 포즈 $c$에서 추출된 BRDF 맵 $a_\theta$, $r_\theta$, $m_\theta$를 갖는 고정된 환경 맵에서 렌더링된 이미지라고 하자. BRDF field의 MLP 파라미터 $\theta$를 최적화하기 위해 제안된 Personalized Geometry-aware Score Distillation (PGSD)의 gradient는 다음과 같다.
\[\begin{equation} \nabla_\theta \mathcal{L}_\textrm{PGSD} (\theta) = \mathbb{E}_{t, \epsilon, c} \bigg[ w(t) (\epsilon_\psi (x_t; y, k, t) - \epsilon_\phi (x_t; y, k, t, c_\rho)) \frac{\partial x}{\partial \theta} \bigg] \\ \textrm{where} \; x_t = \alpha_t x + \sigma_t \epsilon, \; \epsilon \sim \mathcal{N}(0,I) \end{equation}\]$c_\rho$는 카메라 인코더 $\rho$로 임베딩된 카메라 extrinsic이고, $\epsilon_\phi$는 사전 학습된 diffusion model, $\epsilon_\psi$는 fine-tuning된 개인화된 diffusion model이다. Normal map $k$는 ControlNet을 사용하여 두 diffusion model에 컨디셔닝된다.
저자들은 이 방법이 CFG에서 이점을 얻지 못한다는 것을 발견했다. 아마도 개인화된 모델 $\epsilon_\psi$가 적은 수의 이미지에서 fine-tuning되었기 때문일 것이다. 본 논문의 목표는 입력 외형을 타겟 형상으로 충실하게 전송하는 것이므로 다양성을 높이기 위해 CFG가 필요하지 않다.
또한 저자들은 광범위한 실험을 통해 몇 가지 중요한 디자인 선택을 식별했다.
- Dreambooth 가중치가 텍스처 디테일을 제거하는 동안 $\epsilon_\phi$를 원래 사전 학습된 diffusion model 가중치로 초기화하는 것이 중요하다. 그렇지 않으면 Dreambooth의 fine-tuning 프로세스가 diffusion model을 작은 학습 세트에 overfitting시킬 수 있다.
- LoRA 가중치를 제거하면 텍스처 충실도가 크게 향상될 수 있다.
따라서 $\epsilon_\phi$에서 LoRA 구조를 제거하고 카메라 임베딩만 유지하여 \(\mathcal{L}_\textrm{PGSD}\)를 구현한다.
Experiment
- 데이터셋: 4개의 카테고리에서 각각 8개의 물체를 선택하고 물체 주위의 3~5개의 뷰를 선택
- 카테고리: sofa, bed, mug/bowl, plush toy
- 구현 디테일
- CFG 가중치: 1.0 (즉, $\omega = 0$)
- 카메라 인코더: hash-grid positional encoding + MLP
- MLP: 2 layer
- 임베딩 차원: 1,280
- learning rate
- 인코딩: 0.01
- MLP: 0.001
- 카메라 인코더: 0.0001
1. Image-guided texture transfer
다음은 같은 카테고리의 물체로 텍스처를 전송한 예시들이다.

다음은 다른 카테고리의 물체로 텍스처를 전송한 예시들이다.

다음은 relighting한 예시들이다.

다음은 다른 방법들과 비교한 결과이다.



다음은 합성된 텍스처의 다양성을 보여주는 예시이다.

2. Ablation Studies
다음은 ablation 결과이다.

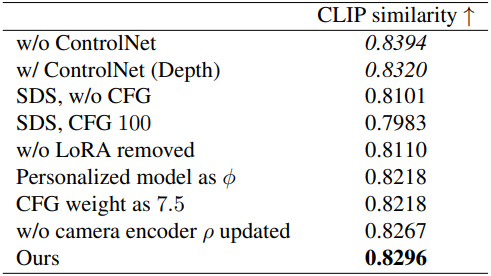
ControlNet을 사용하지 않거나 ControlNet로 depth를 주입하면 CLIP similarity가 더 높지만, 전송 결과는 타겟 모양을 무시하고 형상을 추론하지 않고 텍스처를 직접 그리는 경향이 있다.
Limitations

- 특수하고 반복되지 않는 텍스처를 전송할 수 없다.
- 입력 이미지에 강한 specular highlight가 있는 경우 텍스처에 조명을 베이킹하는 경향이 있다.
- 입력 이미지의 시점이 전체 물체를 덮지 않는 경우 Janus problem이 나타날 수 있다.