[논문리뷰] TEXTure: Text-Guided Texturing of 3D Shapes
SIGGRAPH 2023. [Paper] [Page] [Github]
Elad Richardson, Gal Metzer, Yuval Alaluf, Raja Giryes, Daniel Cohen-Or
Tel Aviv University
3 Feb 2023
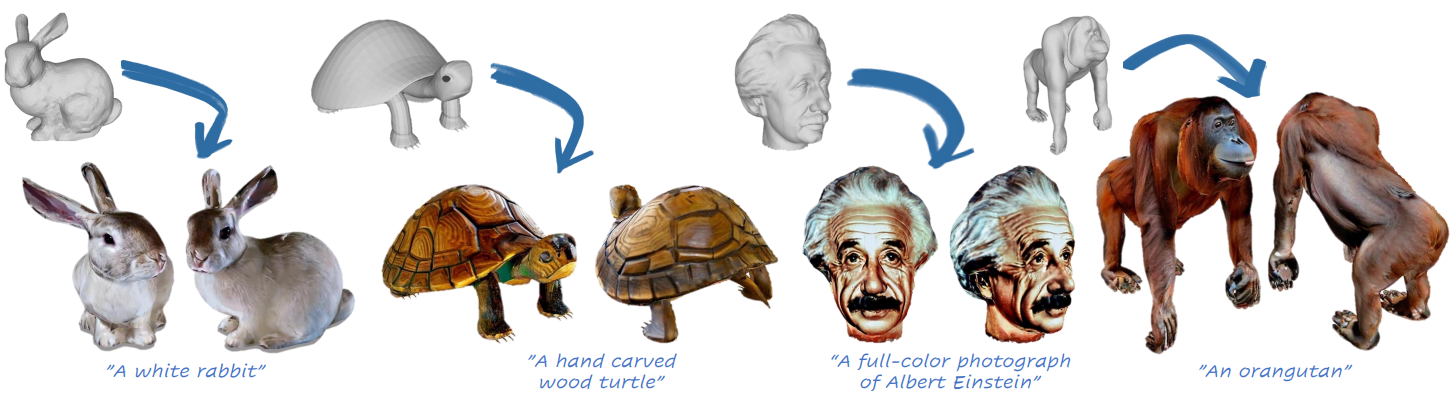
Introduction
단어로 그림을 그리는 능력은 최근 text-to-image 모델의 발전으로 우리 모두에게 현실이 되었다. 텍스트 설명이 주어지면 이러한 새 모델은 입력 텍스트의 본질과 의도를 캡처하는 매우 상세한 이미지를 생성할 수 있다. Text-to-image 생성의 급속한 발전에도 불구하고 3D 개체를 색칠하는 것은 색칠되는 표면의 특정 모양을 고려해야 하기 때문에 여전히 중요한 과제로 남아 있다. 최근 연구들은 언어-이미지 모델을 guidance로 사용하여 3D 객체 페인팅 및 텍스처링에서 상당한 진전을 이루기 시작했다. 그러나 이러한 방법은 2D 방법에 비해 품질 면에서 여전히 부족하다.
본 논문에서는 3D 개체 텍스처링에 중점을 두고 diffusion model을 활용하여 주어진 3D 입력 mesh를 매끄럽게 색칠하는 기술인 TEXTure를 제시한다. Stable Diffusion을 텍스처링 prior로 간접적으로 활용하기 위해 score distillation를 적용하는 이전의 텍스처링 접근 방식과 달리 깊이 조건부 diffusion model을 사용하여 렌더링된 이미지에 전체 denoising process를 직접 적용하도록 선택한다.

핵심적으로 본 논문의 방법은 여러 시점에서 개체를 반복적으로 렌더링하고 깊이 기반 페인팅 체계를 적용한 다음 mesh 꼭지점 또는 아틀라스에 다시 투영한다. TEXTure는 실행 시간과 생성 품질 모두에서 상당한 향상을 가져올 수 있다. 그러나 이 프로세스를 단순하게 적용하면 생성 프로세스의 확률론적 특성으로 인해 위 그림의 (A)와 같이 눈에 띄는 이음새가 있는 매우 일관성 없는 텍스처가 생성된다.
이러한 불일치를 완화하기 위해 각 diffusion process 전에 추정되는 “keep”, “refine”, “generate” 영역의 trimap에 렌더링된 뷰의 동적 분할을 도입한다. “generate” 영역은 렌더링된 view에서 처음 보고 칠해야 하는 영역이다. “refine” 영역은 이전 iteration에서 이미 칠해진 영역이지만 이제 더 나은 결과를 볼 수 있으므로 다시 칠해야 한다. 마지막으로 “keep” 영역은 현재 다시 그려서는 안 되는 영역이다.
그런 다음 trimap 분할을 고려한 수정된 diffusion process를 사용한다. Diffusion process 동안 “keep” 영역을 고정함으로써 보다 일관된 출력을 얻을 수 있지만 새로 생성된 영역은 여전히 글로벌 일관성이 부족하다 (위 그림의 (B) 참조). “generate” 영역에서 더 나은 글로벌 일관성을 장려하기 위해 depth-guided diffusion model과 mask-guided diffusion model을 샘플링 프로세스에 통합한다 (위 그림의 (C) 참조). 마지막으로, “refine” 영역의 경우 이러한 영역을 다시 칠하지만 기존 텍스처를 고려하는 새로운 프로세스를 설계한다. 이러한 기술을 함께 사용하면 단 몇 분 만에 매우 사실적인 결과를 생성할 수 있다 (위 그림의 (D) 참조).
또한, TEXTure는 텍스트 프롬프트에 의해 가이드되는 텍스처 mesh뿐만 아니라 다른 색상의 mesh 또는 작은 이미지셋의 기존 텍스처를 기반으로 사용될 수 있다. TEXTure는 표면 대 표면 매핑이나 중간 재구성 단계가 필요하지 않다. 대신 Textual Inversion과 DreamBooth를 기반으로 특정 텍스처를 나타내는 semantic 토큰을 학습하고 깊이로 컨디셔닝된 모델로 확장하고 학습된 시점 토큰을 도입한다. 정렬되지 않은 몇 개의 이미지에서도 텍스처의 본질을 성공적으로 캡처할 수 있고 semantic 텍스처를 기반으로 3D mesh를 칠하는 데 사용할 수 있다.
마지막으로 diffusion 기반 이미지 편집의 정신으로 텍스처를 더욱 다듬고 편집할 수 있다. 본 논문은 두 가지 편집 기법을 제안한다.
- 새 텍스트의 semantic과 더 잘 일치하도록 가이드 프롬프트를 사용하여 기존 텍스처 맵을 수정하는 텍스트 전용 개선
- 사용자가 텍스처 맵에 편집 내용을 직접 적용할 수 있는 방법
Method
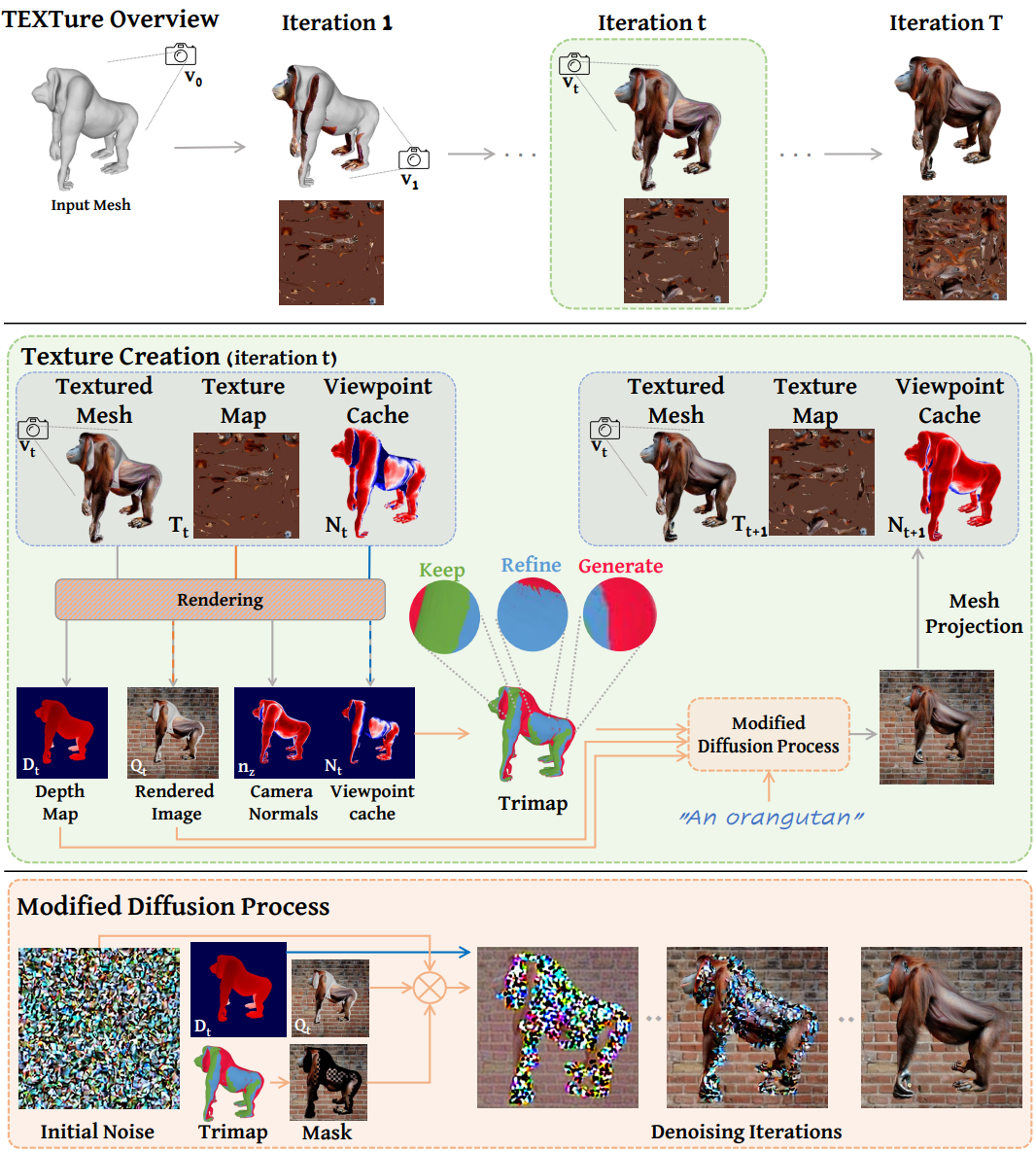
먼저 위 그림에 나와 있는 text-guided mesh texturing 체계의 기반을 마련한다. TEXTure는 주어진 3D mesh의 증분 텍스처링 (incremental texturing)을 수행하며, 각 iteration에서 단일 시점에서 본 mesh의 현재 보이는 영역을 색칠한다. 로컬 및 글로벌 일관성을 모두 장려하기 위해 mesh를 “keep”, “refine”, “generate” 영역의 trimap으로 분할한다. 이 정보를 denoising step에 통합하기 위해 수정된 depth-to-image diffusion process가 제공된다.
본 논문은 TEXTure의 두 가지 확장을 제안한다.
- 주어진 텍스쳐를 표현하는 커스텀 개념을 학습하여 주어진 mesh의 텍스쳐를 새로운 mesh로 옮기는 텍스쳐 전달 방식
- 가이드 텍스트 프롬프트 또는 사용자 제공 낙서를 통해 사용자가 주어진 텍스처 맵을 편집할 수 있는 텍스처 편집 기술
1. Text-Guided Texture Synthesis
본 논문의 텍스처 생성 방법은 Stable Diffusion과 공유 latent space를 기반으로 사전 학습된 depth-to-image diffusion model \(\mathcal{M}_\textrm{depth}\)와 사전 학습된 인페인팅 diffusion model \(\mathcal{M}_\textrm{paint}\)에 의존한다. 생성 과정에서 텍스처는 XAtlas를 사용하여 계산되는 UV 매핑을 통해 아틀라스로 표현된다.
임의의 초기 시점 $v_0 = (r = 1.25, \phi_0 = 0, \theta = 60)$에서 시작한다. 여기서 $r$은 카메라 반경, $\phi$는 카메라 방위각, $\theta$는 카메라 고도이다. 그런 다음 \(\mathcal{M}_\textrm{depth}\)를 사용하여 렌더링된 깊이 맵 \(\mathcal{D}_0\)에 따라 $v_0$에서 볼 때 mesh의 초기 컬러 이미지 $I_0$를 생성한다. 그런 다음 생성된 이미지 $I_0$는 텍스처 아틀라스 \(\mathcal{T}_0\)에 다시 투영되어 $v_0$에서 모양의 보이는 부분을 색칠한다.
이 초기화 단계에 이어 고정된 시점 집합을 반복하는 incremental colorization 프로세스를 시작한다. 각 시점에 대해 렌더러 $\mathcal{R}$을 사용하여 mesh를 렌더링하여 \(\mathcal{D}_t\)와 $Q_t$를 얻는다. 여기서 $Q_t$는 모든 이전 colorization step을 고려하는 시점 $v_t$에서 본 mesh의 렌더링이다. 마지막으로 다음 이미지 $I_t$를 생성하고 $Q_t$를 고려하면서 $I_t$를 업데이트된 텍스처 아틀라스 \(\mathcal{T}_t\)에 다시 투영한다.
단일 view가 그려지면 생성된 텍스처를 따라 로컬 일관성과 글로벌 일관성이 필요하기 때문에 생성 task가 더욱 어려워진다. 아래에서 incremental painting 프로세스의 단일 iteration $t$를 고려하고 이러한 문제를 처리하기 위해 제안된 기술에 대해 자세히 설명한다.
Trimap Creation
시점 $v_t$가 주어지면 먼저 렌더링된 이미지를 “keep”, “refine”, “generate”의 세 영역으로 분할한다. “generate” 영역은 처음으로 표시되고 이전에 그린 영역과 일치하도록 칠해야 하는 렌더링된 영역이다. “keep” 영역과 “refine” 영역의 구분은 약간 더 미묘한 차이가 있으며 비스듬한 각도에서 mesh를 색칠하면 높은 왜곡이 발생할 수 있다는 사실을 기반으로 한다. 이는 화면이 있는 삼각형의 단면이 낮아 mesh 텍스처 이미지 \(\mathcal{T}_t\)에 대한 저해상도 업데이트가 발생하기 때문이다. 특히 카메라 좌표계에서 면 법선 $n_z$의 $z$ 성분으로 삼각형의 단면을 측정한다.
이상적으로는 현재 view가 이전에 그린 일부 영역에 대해 더 나은 colorization 각도를 제공하는 경우 기존 텍스처를 “refine”하고 싶다. 그렇지 않으면 원본 텍스처를 “keep”하고 이전 view와의 일관성을 유지하기 위해 수정하지 않아야 한다. 보이는 영역과 이전에 색상이 지정된 단면을 추적하기 위해 모든 iteration에서 업데이트되는 추가 메타 텍스처 맵 $\mathcal{N}$을 사용한다. 이 추가 맵은 각 iteration에서 텍스처 맵과 함께 효율적으로 렌더링될 수 있으며 현재 trimap 분할을 정의하는 데 사용된다.
Masked Generation
전체 이미지를 생성하도록 depth-to-image diffusion process를 학습했기 때문에 이미지의 일부를 고정된 상태로 “keep”하도록 샘플링 프로세스를 수정해야 한다. Blended Diffusion을 따라, 각 denoising step에서 “keep” 영역에 있는 $Q_t$의 noised 버전, 즉 $z_{Q_t}$를 diffusion process에 명시적으로 주입하여 이러한 영역이 최종 생성된 결과에 매끄럽게 혼합되도록 한다. 특히, 현재 샘플링 timestep $i$에서의 latent는 다음과 같이 계산된다.
\[\begin{equation} z_i \leftarrow z_i \odot m_\textrm{blended} + z_{Q_t} \odot (1 - m_\textrm{blended}) \end{equation}\]즉, “keep” 영역의 경우 원래 값에 따라 고정된 $z_i$를 설정하기만 하면 된다.
Consistent Texture Generation
“keep” 영역을 diffusion process에 주입하면 “generate” 영역과 더 잘 혼합된다. 그러나 “keep” 경계에서 벗어나 “generate” 영역으로 더 깊이 이동하면 생성된 출력이 대부분 샘플링된 noise에 의해 제어되며 이전에 페인트한 영역과 일치하지 않는다.
먼저 각 시점에서 동일한 샘플링된 noise를 사용하도록 선택한다. 이는 때때로 일관성을 향상시키지만 여전히 시점의 변화에 매우 민감하다. 마스킹된 영역을 완성하기 위해 직접 학습된 인페인팅 diffusion model \(\mathcal{M}_\textrm{paint}\)를 적용하면 더 일관되게 생성된다. 그러나 이것은 컨디셔닝 깊이 \(\mathcal{D}_t\)에서 벗어나 새로운 형상을 생성할 수 있다. 두 모델의 장점을 모두 활용하기 위해 초기 샘플링 단계에서 두 모델을 번갈아 가며 사용하는 인터리브 프로세스를 도입한다. 구체적으로, 샘플링 중에 다음 노이즈 잠재 $z_{i-1}$은 다음과 같이 계산된다.
\[\begin{equation} z_{i-1} = \begin{cases} \mathcal{M}_\textrm{depth} (z_i, \mathcal{D}_t) & \quad 0 \le i < 10 \\ \mathcal{M}_\textrm{paint} (z_i, \textrm{“generate"}) & \quad 10 \le i < 20 \\ \mathcal{M}_\textrm{depth} (z_i, \mathcal{D}_t) & \quad 20 \le i < 50 \end{cases} \end{equation}\]\(\mathcal{M}_\textrm{depth}\)를 적용할 때 noised latent는 현재 깊이 \(\mathcal{D}_t\)에 의해 가이드되는 반면 \(\mathcal{M}_\textrm{paint}\)를 적용할 때 샘플링 프로세스는 글로벌하게 일관된 방식으로 “generate” 영역을 완료하는 작업을 수행한다.
Refining Regions
“refine” 영역을 처리하기 위해 이전 값을 고려하면서 새로운 텍스처를 생성하는 diffusion process에 대한 또 다른 새로운 수정을 사용한다. 저자들의 주요 관찰은 샘플링 프로세스의 첫 번째 step에서 번갈아 바둑판 모양의 마스크를 사용하여 noise를 이전 완료와 로컬로 정렬되는 값으로 가이드할 수 있다는 것이다.
이 프로세스의 세분성은 바둑판 마스크의 해상도와 제한된 step 수를 변경하여 제어할 수 있다. 실제로 처음 25개의 샘플링 step에 마스크를 적용한다. 즉, 마스킹된 $m_\textrm{blended}$는 다음과 같이 설정된다.
\[\begin{equation} m_\textrm{blended} = \begin{cases} 0 & \quad \textrm{“keep"} \\ \textrm{checkboard} & \quad \textrm{“refine"} \wedge i \le 25 \\ 1 & \quad \textrm{“refine"} \wedge i > 25 \\ 1 & \quad \textrm{“generate"} \end{cases} \end{equation}\]여기서 1은 이 영역을 페인트하고 그렇지 않은 경우 유지해야 함을 나타낸다.
Texture Projection
텍스처 아틀라스 \(\mathcal{T}_t\)로 다시 투영하기 위해 differential renderer $\mathcal{R}$을 통해 렌더링될 때 \(\mathcal{T}_t\) 값에 대해 \(\mathcal{L}_t\)에 대한 기울기 기반 최적화를 적용한다.
\[\begin{equation} \nabla_{\mathcal{T}_t} \mathcal{L}_t = [(\mathcal{R} (\textrm{mesh}, \mathcal{T}_t, v_t) - I_t) \odot m_s] \frac{\partial \mathcal{R} \odot m_s}{\partial \mathcal{T}_t} \end{equation}\]서로 다른 view에서 projection의 매끄러운 텍스처 이음새를 얻기 위해 “refine” 영역과 “generate” 영역의 경계에 soft mask $m_s$가 적용된다.
\[\begin{aligned} m_s &= m_h \ast g \\ m_h &= \begin{cases} 0 & \quad \textrm{“keep"} \\ 1 & \quad \textrm{“refine"} \cup \textrm{“generate"} \\ \end{cases} \end{aligned}\]여기서 $g$는 2D Gaussian blur kernel이다.
Additional Details
텍스처는 렌더링 해상도가 1200$\times$1200인 1024$\times$1024 아틀라스로 표현된다. Diffusion process를 위해 내부 영역을 분할하고 512$\times$512로 크기를 조정하고 사실적인 배경에 매트를 적용한다. 모든 모양은 객체 주변의 8개 시점과 2개의 추가 상단/하단 view로 렌더링된다. 시점 순서도 최종 결과에 영향을 미칠 수 있다.
2. Texture Transfer
주어진 3D mesh에서 새 텍스처를 성공적으로 생성했으므로 이제 주어진 텍스처를 텍스처가 없는 새 타겟 mesh로 전송하는 방법을 설명한다. 이는 색칠된 mesh 또는 작은 입력 이미지 세트에서 텍스처를 캡처하는 방법을 보여준다. 텍스처 전송 접근 방식은 사전 학습된 diffusion model을 fine-tuning하고 생성된 텍스처를 나타내는 pseudo-token을 학습하는 Textual Inversion과 DreamBooth를 기반으로 한다. 그런 다음 fine-tuning된 모델은 새 형상을 텍스처링하는 데 사용된다. Fine-tuning된 모델의 일반화를 새로운 형상으로 개선하기 위해 새로운 spectral augmentation 기술을 제안한다. 그런 다음 mesh 또는 이미지에서 개념 학습 체계에 대해 논의한다.
Spectral Augmentations
원래 입력 형상 자체가 아니라 입력 텍스처를 나타내는 토큰을 학습하는 데 관심이 있으므로 이상적으로는 입력 텍스처를 포함하는 형상 범위에 대한 공통 토큰을 학습해야 한다. 이렇게 하면 특정 형상에서 텍스처가 분리되고 fine-tuning된 diffusion model의 일반화가 향상된다. 본 논문은 surface caricaturization의 개념에서 영감을 받아 새로운 spectral augmentation 기술을 제안한다. 본 논문의 경우, mesh Laplacian의 스펙트럼에 의해 정규화된 텍스처 소스 mesh에 대한 임의의 저주파 형상 변형을 제안한다.
Spectral eigenbasis에 대한 랜덤 변형을 변조하면 입력 모양의 무결성을 유지하는 부드러운 변형이 발생한다. 경험적으로 무작위로 선택한 eigenfunction에 비례하는 크기로 mesh에 랜덤 팽창 또는 수축을 적용하도록 선택한다.
Texture Learning
Spectral augmentation 기술을 적용하여 입력 모양의 해당 깊이 맵을 사용하여 대규모 이미지셋을 생성한다. 여러 시점 (왼쪽, 오른쪽, 위, 아래, 앞, 뒤)에서 이미지를 렌더링하고 렌더링된 개체를 임의의 색상 배경에 붙여넣는다.
렌더링된 이미지 세트가 주어지면 “a $\langle D_v \rangle$ photo of a \(\langle \mathcal{S}_\textrm{texture} \rangle\)” 형식의 프롬프트를 사용하여 텍스처를 나타내는 임베딩 벡터를 따르고 최적화한다. 여기서 $\langle D_v \rangle$는 렌더링된 이미지의 view 방향을 나타내는 학습된 토큰이고 \(\langle \mathcal{S}_\textrm{texture} \rangle\)는 텍스처를 나타내는 토큰이다. 동일한 view의 이미지 내에서 공유되는 6개의 학습된 방향 토큰 $D_v$와 모든 이미지에서 공유되는 텍스처를 나타내는 단일 토큰 \(\mathcal{S}_\textrm{texture}\)가 있다. 또한 입력 텍스처를 더 잘 캡처하기 위해 diffusion model 자체도 fine-tuning한다.
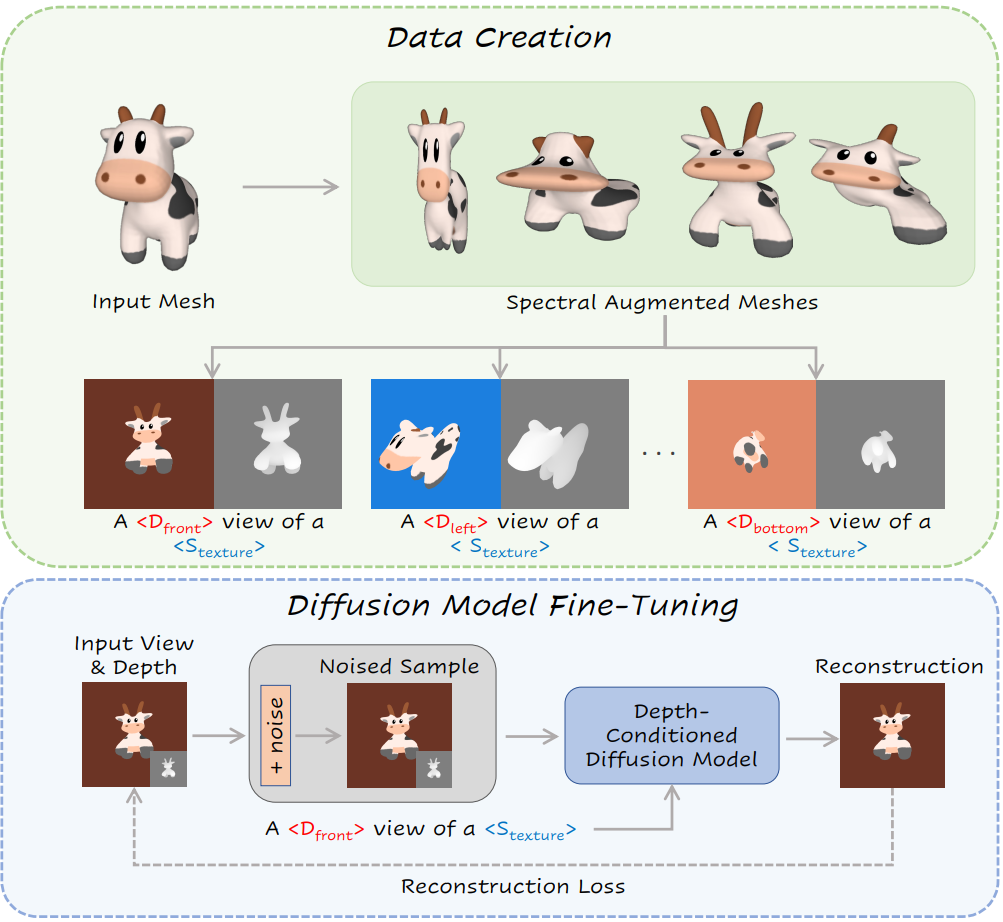
텍스처 학습 체계는 위 그림에 설명되어 있다. 학습 후 TEXTure를 사용하여 타겟 모양에 색상을 지정하고 원래의 Stable Diffusion 모델을 fine-tuning된 모델로 교체한다.
Texture from Images
다음으로 작은 샘플 이미지 세트를 기반으로 텍스처를 생성하는 더 어려운 task를 살펴보자. 몇 개의 이미지만으로 동일한 품질을 기대할 수는 없지만 서로 다른 텍스처를 나타내는 개념을 잠재적으로 학습할 수 있다. 표준 textual inversion 기술과 달리 TEXTure가 학습한 개념은 깊이로 컨디셔닝된 모델에서 학습되기 때문에 구조가 아닌 대부분 텍스처를 나타낸다. 이것은 잠재적으로 다른 3D 모양을 텍스처링하는 데 더 적합하다.
이 task를 위해 사전 학습된 saliency network를 사용하여 이미지에서 눈에 띄는 개체를 분할하고 표준 scale 및 crop augmentation를 적용하고 결과를 랜덤하게 색상이 지정된 배경에 붙여넣는다. 본 논문의 결과는 이미지에서 semantic 개념을 성공적으로 학습하고 중간에 명시적인 재구성 단계 없이 3D 모양에 적용할 수 있음을 보여준다. 이는 실제 물체에서 영감을 얻은 매혹적인 텍스처를 만들 수 있는 새로운 기회를 만든다.
3. Texture-Editing
Trimap 기반 TEXTuring을 사용하여 2D 편집 기술을 전체 mesh로 쉽게 확장할 수 있음을 보여준다. 텍스트 기반 편집의 경우 텍스트 프롬프트로 가이드되는 기존 텍스처 맵을 변경하려고 한다. 이를 위해 전체 텍스처 맵을 “refine” 영역으로 정의하고 TEXTuring 프로세스를 적용하여 새 텍스트 프롬프트에 맞게 텍스처를 수정한다. 추가로 사용자가 주어진 텍스처 맵을 직접 편집할 수 있는 낙서 기반 편집을 제공한다 (ex. 원하는 영역에 대한 새로운 색상 구성표 정의). 이를 허용하기 위해 TEXTuring 프로세스 중에 변경된 영역을 “refine” 영역으로 정의하고 나머지 텍스처를 고정된 상태로 “keep”한다.
Experiments
1. Text-Guided Texturing
Qualitative Results
다음은 TEXTure를 사용한 텍스처링 결과이다.



Qualitative Comparisons
다음은 텍스트 기반 텍스처 생성 방법들과 비교한 것이다.


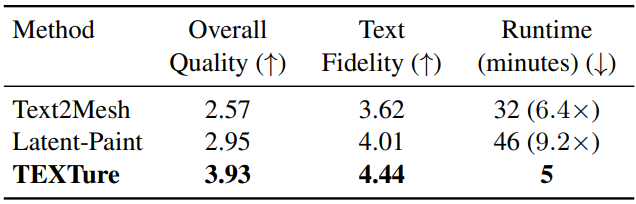
User Study
다음은 user study 결과이다. (1점 ~ 5점)
다음은 추가적인 user study 결과이다. (순위)

Ablation Study
다음은 각 단계에 대한 ablation 결과이다.
- (A): 전체 시점을 색칠하는 순진한 색칠 방법
- (B): “keep” 영역을 고려
- (C): “generate” 영역에 대한 인페인팅 기반 방법
- (D): “refine” 영역을 사용한 최종 방법

2. Texture Capturing
Texture From Mesh
다음은 mesh로부터의 토큰 기반 텍스처 전송 결과이다.

Texture From Image
다음은 이미지로부터의 토큰 기반 텍스처 전송 결과이다.


3. Editing
다음은 Texture Editing 결과이다. 상단은 로컬한 낙서 기반 편집 결과이고 하단은 글로벌한 텍스트 기반 편집 결과이다.

Limitations

TEXTure는 공간적으로 일관되도록 설계되었지만 때때로 다른 view에서 가려진 정보로 인해 글로벌 스케일에서 불일치가 발생할 수 있다. 위 그림을 보면 다른 시점에서 다른 모양의 눈이 추가되었다. 또 다른 주의 사항은 시점 선택이다. TEXTure는 객체 주변에 8개의 고정된 시점을 사용하는데, 이는 적대적인 형상을 완전히 포함하지 않을 수 있다. 또한 depth-guided 모델은 때때로 입력 깊이에서 벗어나 형상 구조와 일치하지 않는 이미지를 생성할 수 있다. 결과적으로 mesh에 충돌하는 투영이 발생할 수 있으며, 이는 이후 iteration에서 수정할 수 없다.