[논문리뷰] An Image is Worth One Word: Personalizing Text-to-Image Generation using Textual Inversion
arXiv 2022. [Paper] [Page] [Github]
Rinon Gal, Yuval Alaluf, Yuval Atzmon, Or Patashnik, Amit H. Bermano, Gal Chechik, Daniel Cohen-Or
Tel Aviv University | NVIDIA
2 Aug 2022

Introduction
최근에 대규모 text-to-image 모델은 자연어 설명을 추론하는 전례 없는 능력을 보여주었다. 이를 통해 사용자는 처음 보는 구성으로 새로운 장면을 합성하고 다양한 스타일로 생생한 사진을 생성할 수 있다. 이러한 도구는 예술적 창조, 영감의 원천, 심지어 새롭고 물리적인 제품을 디자인하는 데 사용되었다. 그러나 이들의 사용은 텍스트를 통해 원하는 대상을 설명하는 사용자의 능력에 의해 제한된다.
대규모 모델에 새로운 개념을 도입하는 것은 어려운 경우가 많다. 각각의 새로운 개념에 대해 확장된 데이터셋으로 모델을 재학습하는 것은 엄청나게 비용이 많이 들고 몇 가지 예에 대한 fine-tuning은 일반적으로 치명적인 망각으로 이어진다. 보다 나은 접근 방식은 모델을 고정하고 변환 모듈을 학습하여 새로운 개념에 직면했을 때 출력을 조정한다. 그러나 이러한 접근 방식은 여전히 이전 지식을 잊어버리거나 새로 학습한 개념과 동시에 접근하는 데 어려움이 있다.
본 논문은 사전 학습된 text-to-image 모델의 텍스트 임베딩 space에서 새로운 단어를 찾아 이러한 문제를 극복할 것을 제안한다. 저자들은 텍스트 인코딩 프로세스의 첫 번째 단계를 고려하였다. 여기서 입력 문자열은 먼저 토큰 집합으로 변환된다. 각 토큰은 자체 임베딩 벡터로 대체되며 이러한 벡터는 다운스트림 모델을 통해 공급된다. 본 논문의 목표는 새롭고 구체적인 개념을 나타내는 새로운 임베딩 벡터를 찾는 것이다.
본 논문은 $S_\ast$로 표시하는 새로운 pseudo-word로 새로운 임베딩 벡터를 나타낸다. 그런 다음 이 pseudo-word는 다른 단어처럼 취급되며 생성 모델에 대한 새로운 텍스트 쿼리를 작성하는 데 사용할 수 있다.
“해변의 $S_\ast$ 사진”
“벽에 걸려 있는 $S_\ast$의 유화”
“$S_\ast^1$ 스타일의 $S_\ast^2$ 그림”
중요한 것은 이 프로세스가 생성 모델을 그대로 유지한다는 것이다. 그렇게 함으로써 새로운 task에 대한 비전 및 언어 모델을 fine-tuning할 때 일반적으로 손실되는 풍부한 텍스트 이해 능력과 일반화 능력을 유지한다.
이러한 pseudo-word를 찾기 위해 task를 inversion 중 하나로 구성한다. 사전 학습된 고정된 text-to-image 모델과 개념을 묘사하는 작은 (3-5) 이미지 세트가 제공된다. “A photo of $S_\ast$” 형식의 문장이 작은 세트에서 이미지의 재구성으로 이어질 수 있도록 단일 단어 임베딩을 찾는 것을 목표로 한다. 이 임베딩은 Textual Inversion이라고 하는 최적화 프로세스를 통해 발견된다.
GAN inversion에 일반적으로 사용되는 도구를 기반으로 일련의 확장을 추가로 조사한다. 저자들의 분석에 따르면 일부 핵심 원칙은 남아 있지만 순진한 방식으로 선행 기술을 적용하는 것은 도움이 되지 않거나 매우 해롭다.
저자들은 광범위한 개념과 프롬프트에 대한 본 논문의 접근 방식의 효과를 입증하여 고유한 개체를 새로운 장면에 주입하고 다양한 스타일로 변환하고 포즈를 전환하고 편견을 줄이고 심지어 새로운 제품을 상상할 수 있음을 보여주었다.
Method
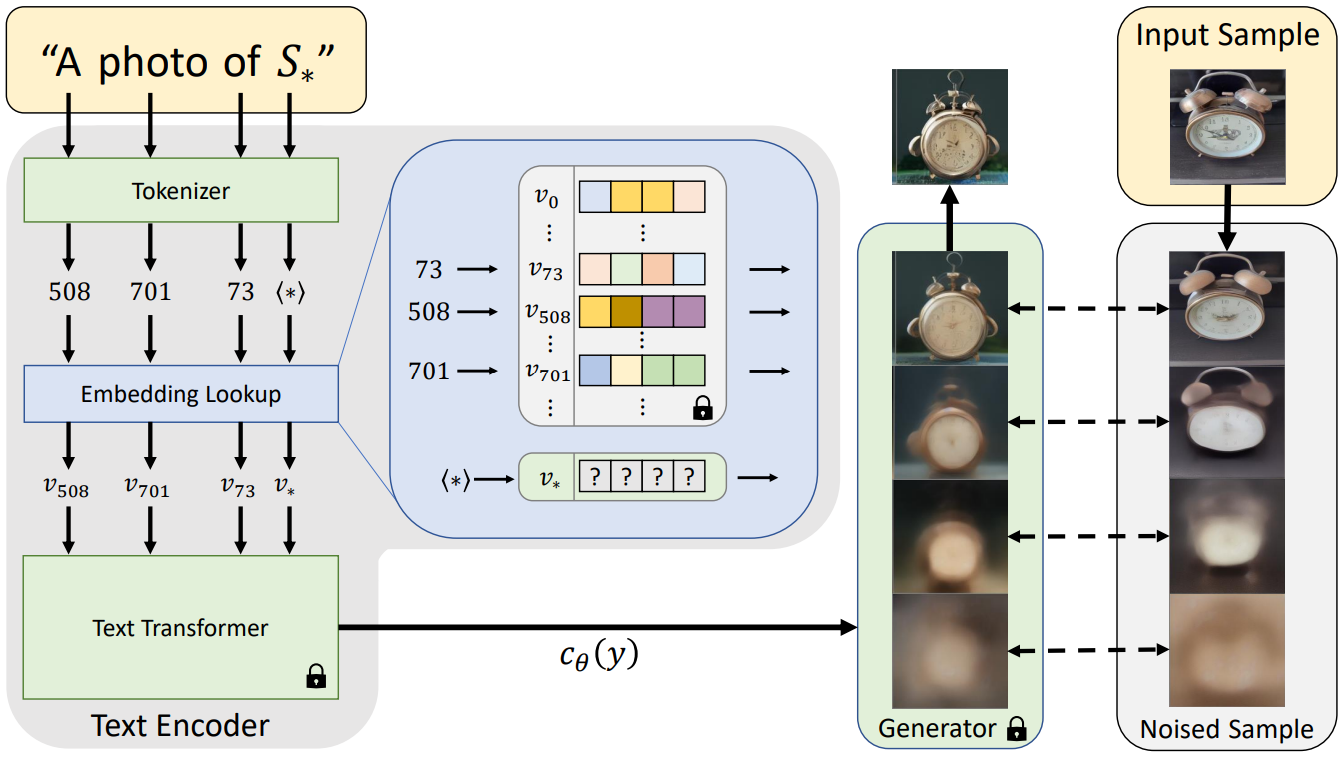
본 논문의 목표는 새로운 사용자 지정 개념의 언어로 가이드된 생성을 가능하게 하는 것이다. 그렇게 하기 위해 이러한 개념을 사전 학습된 text-to-image 모델의 중간 표현으로 인코딩하는 것을 목표로 한다. 이상적으로는 이러한 모델에 의해 표현되는 풍부한 semantic과 시각적 prior를 활용하고 개념의 직관적인 시각적 변환을 가이드하는 데 사용할 수 있는 방식으로 수행되어야 한다.
일반적으로 text-to-image 모델에서 사용하는 텍스트 인코더의 단어 삽입 단계에서 이러한 표현에 대한 후보를 검색하는 것은 자연스러운 일이다. 여기에서 이산적인 입력 텍스트는 먼저 직접 최적화가 가능한 연속 벡터 표현으로 변환된다.
이전 연구들에서는 이 임베딩 space가 기본 이미지 semantic을 캡처하기에 충분히 표현력이 있음을 보여주었다. 그러나 이러한 접근 방식은 contrastive 또는 language-completion 목적 함수를 활용했으며 둘 다 이미지에 대한 심층적인 시각적 이해를 필요로 하지 않다. 이러한 방법은 개념의 모양을 정확하게 캡처하지 못하고 합성에 사용하려고 시도하면 상당한 시각적 손상이 발생한다. 본 논문의 목표는 생성을 가이드할 수 있는 pseudo-word를 찾는 것인데, 이는 비전 task이다. 따라서 시각적 재구성 목적 함수를 통해 찾을 것을 제안한다.
Latent Diffusion Models
오토인코더의 latent space에서 작동하는 Latent Diffusion Model (LDM)을 통해 방법을 구현한다.
LDM은 두 가지 핵심 구성 요소로 구성된다. 첫째, 오토인코더는 대량의 이미지 모음에 대해 사전 학습된다. 인코더 $\mathcal{E}$는 이미지 \(x \in \mathcal{D}_x\)를 KL-divergence loss 또는 vector quantization을 통해 정규화된 공간적 latent code $z = \mathcal{E}(x)$로 매핑하는 방법을 학습한다. 디코더 $D$는 $D(\mathcal{E}(x)) \approx x$와 같이 이러한 latent를 이미지에 다시 매핑하는 방법을 학습한다.
두 번째 구성 요소인 diffusion model은 학습된 latent space 내에서 코드를 생성하도록 학습된다. 이 diffusion model은 클래스 레이블, segmentation mask, 공동으로 학습된 텍스트 임베딩 모델의 출력 등으로 컨디셔닝될 수 있다. $c_\theta (y)$를 컨디셔닝 입력 $y$를 컨디셔닝 벡터로 매핑하는 모델이라고 하자. LDM loss는 다음과 같이 계산된다.
\[\begin{equation} L_\textrm{LDM} := \mathbb{E}_{z \sim \mathcal{E} (x), y, \epsilon \sim \mathcal{N}(0,I), t} [\| \epsilon - \epsilon_\theta (z_t, t, c_\theta (y)) \|_2^2] \end{equation}\]여기서 $t$는 timestep, $z_t$는 시간 $t$까지 noise된 latent, $\epsilon$은 스케일링되지 않은 noise 샘플, $\epsilon_\theta$는 denoising network이다. 직관적으로 여기의 목적 함수는 이미지의 latent 표현에 추가된 noise를 올바르게 제거하는 것이다. 학습하는 동안 $c_\theta$와 $\epsilon_\theta$는 공동으로 최적화되어 LDM loss를 최소화한다. inference 시 무작위 noise 텐서가 샘플링되고 반복적으로 denoise되어 새로운 latent 이미지 $z_0$을 생성한다. 마지막으로 이 latent code는 사전 학습된 디코더 $x’ = D(z_0)$를 통해 이미지로 변환된다.
본 논문은 LAION-400M 데이터셋에서 사전 학습된 14억 파라미터의 text-to-image 모델을 사용한다. 여기서 $c_\theta$는 BERT 텍스트 인코더를 통해 구현되며 $y$는 텍스트 프롬프트이다.
Text embeddings
BERT와 같은 일반적인 텍스트 인코더 모델은 텍스트 처리 단계로 시작한다. 첫째, 입력 문자열의 각 단어 또는 하위 단어는 일부 미리 정의된 사전(dictionary)의 인덱스인 토큰으로 변환된다. 그런 다음 각 토큰은 인덱스 기반 조회를 통해 검색할 수 있는 고유한 임베딩 벡터에 연결된다. 이러한 임베딩 벡터는 일반적으로 텍스트 인코더 $c_\theta$의 일부로 학습된다.
본 논문에서는 이 임베딩 space를 inversion 대상으로 선택하였다. 구체적으로, 배우고자 하는 새로운 개념을 나타내기 위해 placeholder 문자열 $S_\ast$를 지정한다. 임베딩 프로세스에 개입하고 토큰화된 문자열과 관련된 벡터를 새롭고 학습된 임베딩 $v_\ast$로 교체하여 본질적으로 개념을 어휘에 주입한다. 그렇게 함으로써 다른 단어와 마찬가지로 개념을 포함하는 새로운 문장을 작성할 수 있다.
Textual inversion
이러한 새로운 임베딩을 찾기 위해 다양한 배경이나 포즈와 같은 여러 설정에서 대상 개념을 묘사하는 작은 이미지 세트(일반적으로 3-5개)를 사용한다. 작은 세트에서 샘플링된 이미지에 대한 LDM loss를 최소화하여 직접 최적화를 통해 $v_\ast$를 찾는다. 생성 조건을 지정하기 위해 CLIP ImageNet 템플릿에서 파생된 중립 컨텍스트 텍스트를 무작위로 샘플링한다. 여기에는 “A photo of $S_\ast$”, “A rendition of $S_\ast$” 등의 형식 프롬프트가 포함된다.
최적화 목적 함수는 다음과 같이 정의할 수 있다.
\[\begin{equation} v_\ast = \underset{v}{\arg \min} \mathbb{E}_{z \sim \mathcal{E} (x), y, \epsilon \sim \mathcal{N} (0,I), t} [\| \epsilon - \epsilon_\theta (z_t, t, c_\theta (y)) \|_2^2] \end{equation}\]$c_\theta$와 $\epsilon_\theta$를 모두 고정한 상태에서 원본 LDM 모델과 동일한 학습 체계를 재사용하여 실현된다. 특히 이것은 재구성 task이다. 따라서 학습된 임베딩이 개념에 고유한 미세한 시각적 디테일을 캡처하도록 동기를 부여할 것으로 기대한다.
Qualitative comparisons and applications
1. Image variations
다음은 본 논문의 방법, DALLE-2의 CLIP 기반 재구성, 사람이 작성한 다양한 길이의 캡션으로 생성된 개체의 변형들이다.

2. Text-guided synthesis
다음은 텍스트로 가이드된 개인화된 생성 결과이다.
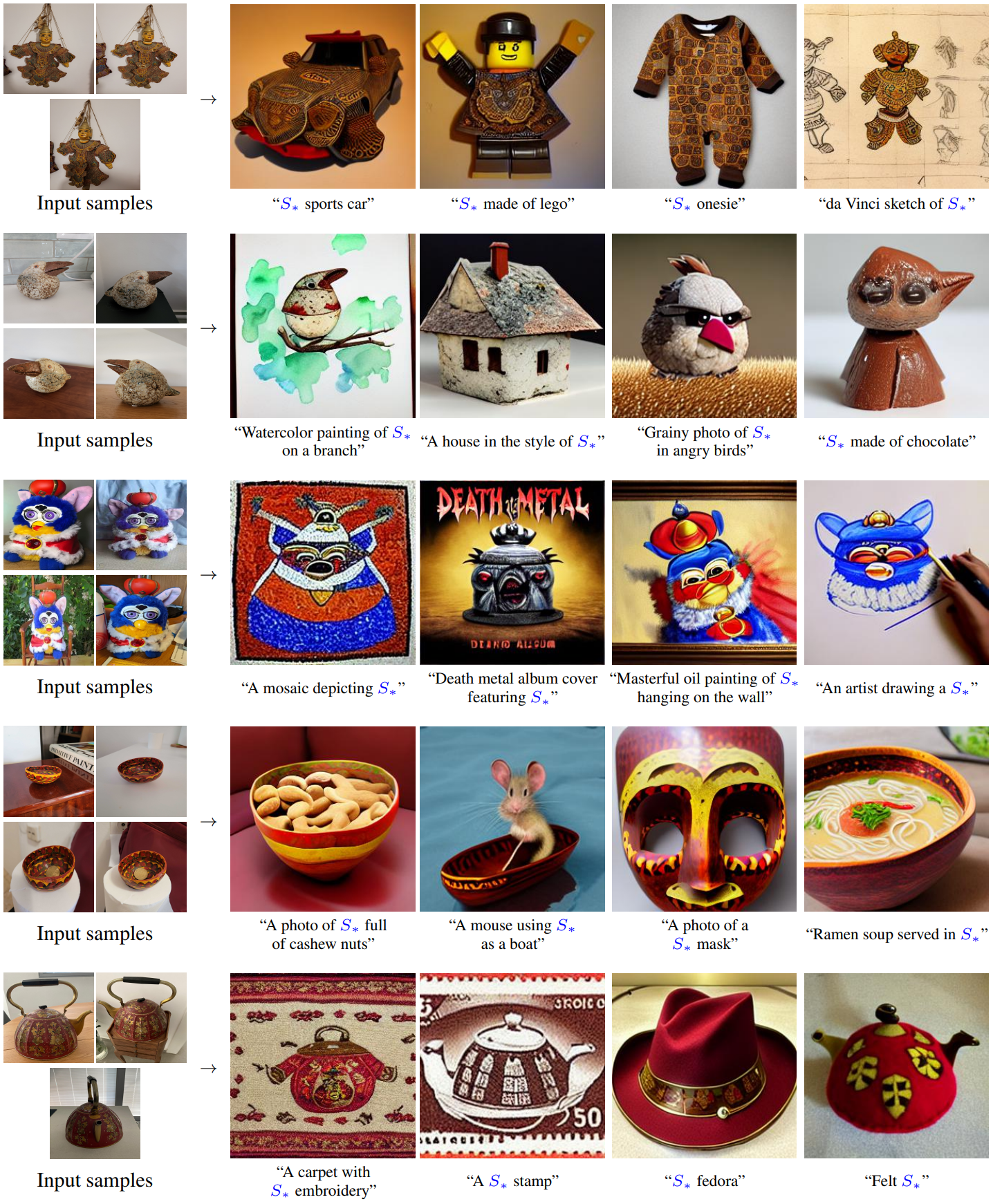
다음은 다른 개인화된 생성 접근 방식과 비교한 결과이다.

2. Style transfer
모델은 알 수 없는 특정 스타일을 나타내는 유사어를 찾을 수 있다. 이러한 pseudo-word를 찾기 위해 모델에 공유 스타일이 있는 작은 이미지 세트를 제공하고 학습 텍스트를 “A painting in the style of $S_\ast$” 형식의 프롬프트로 대체한다. 그 결과는 아래와 같다.

개념을 캡처하는 능력이 단순한 객체 재구성을 넘어 더 추상적인 아이디어로 확장된다.
3. Concept compositions
다음은 2개의 pseudo-word를 사용한 생성 결과이다.

4. Bias reduction
Text-to-image 모델의 일반적인 한계는 모델을 학습하는 데 사용되는 인터넷 규모 데이터에서 발견된 편향을 상속한다는 것이다. 이러한 편향은 생성된 샘플에서 나타난다.

위 그림에서는 “의사”라는 단어에 인코딩된 편향을 강조하고 작고 더 다양한 세트에서 새로운 임베딩을 학습하여 이 편향을 줄일 수 있음을 보여준다. 즉, 성별과 인종의 다양성을 증가시킨다.
5. Downstream applications
다음은 pseudo-word를 LDM 위에 구축된 하위 모델과 함께 사용한 예시이다.

Quantitative analysis
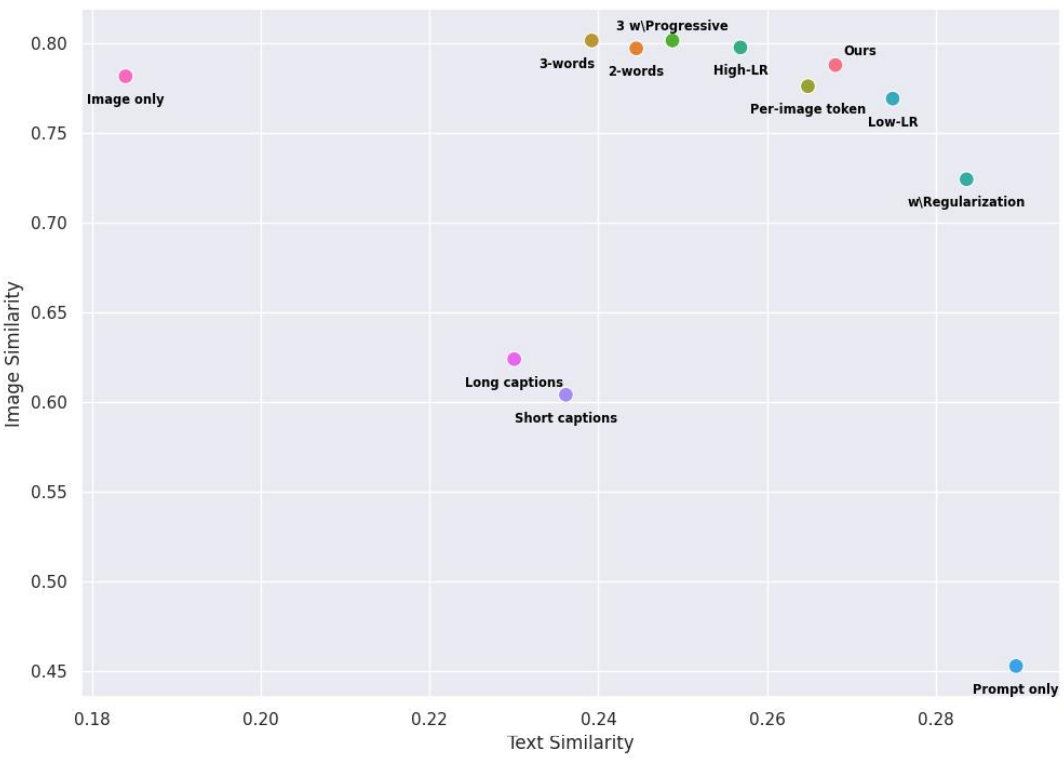
다음은 CLIP 기반의 정량적 평가 결과이다.
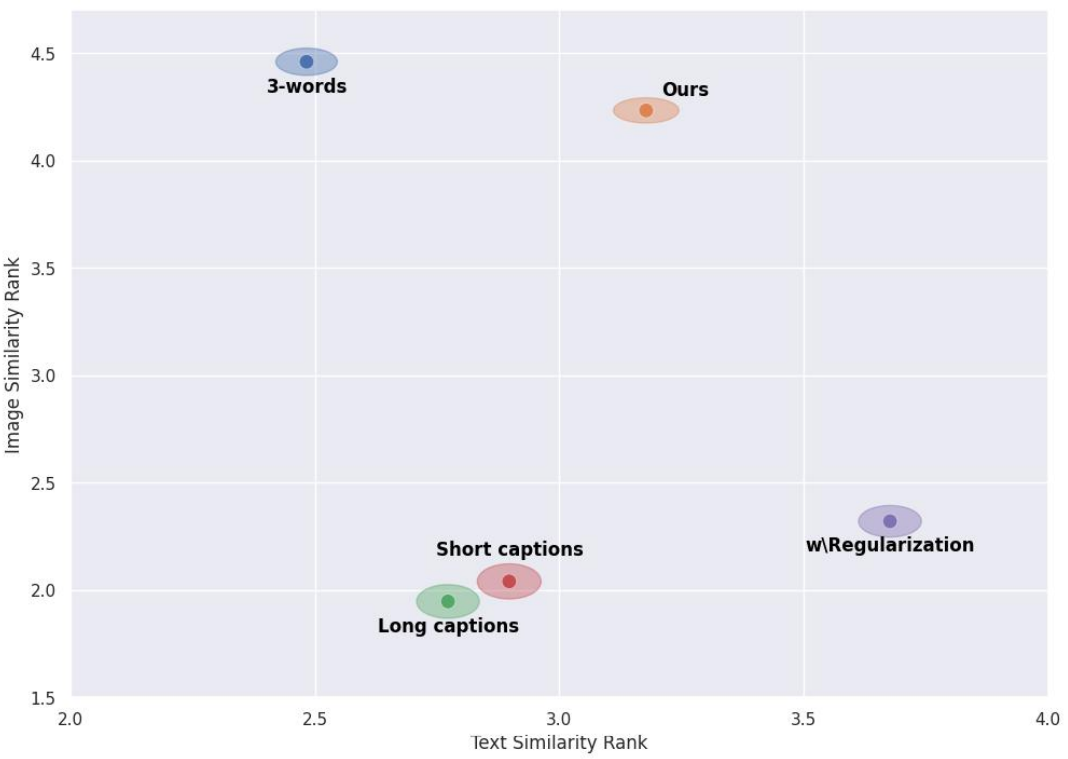
다음은 user study 결과이다.
Limitations
- 개념의 의미론적 본질을 통합하는 대신 정확한 모양을 학습하는 데 여전히 어려움을 겪을 수 있다.
- 최적화 시간이 길다. 단일 개념을 학습하는 데 약 2시간이 걸린다.