[논문리뷰] TextMesh: Generation of Realistic 3D Meshes From Text Prompts
arXiv 2023. [Paper] [Page]
Christina Tsalicoglou, Fabian Manhardt, Alessio Tonioni, Michael Niemeyer, Federico Tombari
ETH Zurich | Google | Technical University of Munich
24 Apr 2023

Introduction
간단한 텍스트 프롬프트에서 사실적인 2D 이미지를 생성하는 분야는 빠르게 성장하는 분야이다. Diffusion model과 텍스트-이미지 쌍이 포함된 엄청난 양의 학습 데이터 덕분에 현재 모델은 매우 높은 품질의 이미지를 생성할 수 있다. 당연히 3D 모델링에서도 동일한 고품질 생성 능력을 얻을 수 있는지에 대한 의문이 생긴다. 불행히도 출력 공간이 훨씬 더 크고 3D 일관성이 필요하며 텍스트와 3D 모델에 대한 많은 양의 학습 데이터 쌍이 부족하기 때문에 훨씬 더 어려운 분야이다.
초기 방법은 주로 CLIP 목적 함수를 사용하여 구와 같은 템플릿 모양을 변형하려고 시도했다. 그러나 3D 형상은 외형뿐 아니라 형상 면에서도 여전히 매우 만족스럽지 못했다. 이 한계를 극복하기 위해 DreamFusion은 최근 앞서 언급한 text-to-image diffusion model (ex. Imagen)의 능력을 활용하여 텍스트 프롬프트에서 3D 모델링을 supervise할 것을 제안했다. 이를 위해 새로운 Score Distillation Sampling (SDS) 기울기와 함께 view-dependent 프롬프트를 사용하여 Neural Radiance Field (NeRF)를 학습시킬 것을 제안하였다.
제안된 방법이 인상적인 결과를 생성할 수 있음에도 불구하고 여전히 몇 가지 단점이 있다. 첫째, 이 방법은 모델을 수렴시키는 데 필요한 강력한 guidance로 인해 과포화된 색상으로 개체를 생성하는 경향이 있다. 예를 들어 프롬프트에 “A DSLR photo of”라는 접두어를 붙인 프롬프트 엔지니어링을 통해 이 문제를 어느 정도 완화할 수 있지만 실제 현실감에 관한 결과는 여전히 만족스럽지 않다. 둘째, 표준 컴퓨터 그래픽 파이프라인 내에서 사용하기에는 비실용적인 접근 방식을 렌더링하는 NeRF 형식의 3D 장면을 나타낸다. 실제로 NeRF에서 mesh를 추출하는 것은 가능하지만 밀도 기반 표현을 고려할 때 간단한 프로세스가 아니다.
본 논문에서는 앞서 언급한 한계, 즉 표준 3D mesh 형태로 사실적인 3D 콘텐츠를 생성하는 것을 목표로 텍스트 프롬프트에서 3D 모양을 생성하는 새로운 방법인 TextMesh를 제시한다.

위 그림에서 볼 수 있듯이, 생성된 3D mesh는 현실감을 크게 향상시키고 AR 또는 VR의 표준 컴퓨터 그래픽 파이프라인 및 애플리케이션 내에서 직접 활용할 수 있다. 이를 위해 DreamFusion을 SDF (signed distance function)의 형태로 모델링하도록 수정하여 획득한 볼륨의 0-level set로 표면을 쉽게 추출할 수 있도록 한다. 또한 mesh 품질을 향상시키기 위해 mesh의 색상과 깊이에 따라 다른 diffusion model을 활용하여 출력을 다시 텍스처링한다. 이를 위해 여러 시점에서 개체를 렌더링하고 diffusion을 사용하여 텍스처 최적화를 가이드하여 현실감과 디테일을 향상시킨다. 그럼에도 불구하고 개별 view를 독립적으로 처리할 때 정제된 텍스처는 심각한 불일치를 나타낸다. 따라서 대신 diffusion model을 통해 여러 view를 동시에 실행한다. 최종 텍스처를 얻기 위해 생성된 출력 view를 Score Distillation Sampling과 함께 학습시켜 원활한 전환을 보장한다.
Method
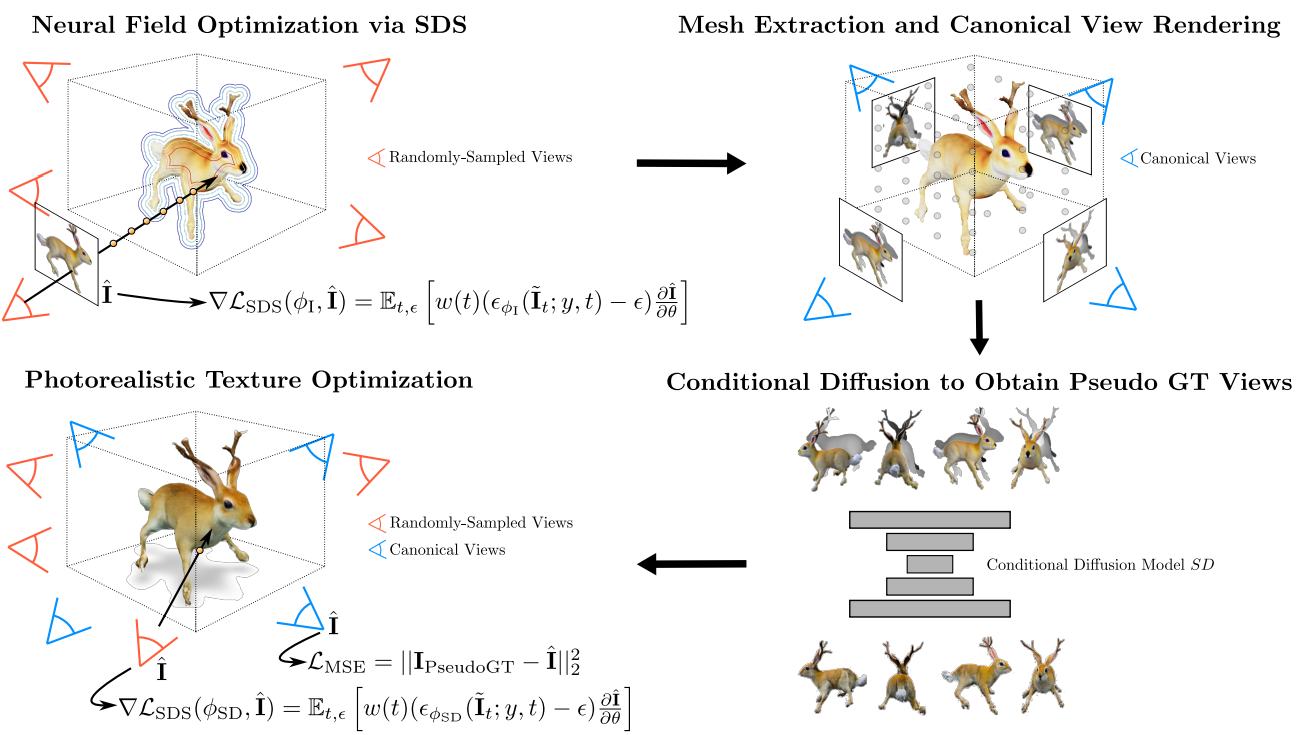
본 논문의 목표는 텍스트 프롬프트에서 사실적인 텍스처로 고품질 3D mesh 표현을 생성하는 방법을 개발하는 것이다. 위 그림은 TextMesh의 전체 개요를 보여준다.
1. Initial Scene Representation
Neural Radiance Field (NeRF)
Radiance field $f$는 3D 위치 $x \in \mathbb{R}^3$과 광선 관찰 방향 $d \in \mathbb{S}^2$에서 RGB 색상 $c \in [0, 1]^3$와 볼륨 밀도 $\sigma \in \mathbb{R}^{+}$로의 연속 매핑이다. Neural radiance field (NeRF)에서 이 필드 $f_\theta$는 파라미터 $\theta$가 있는 신경망으로 parameterize된다. 픽셀을 렌더링하기 위해 $d \in \mathbb{R}^2$ 방향의 광선이 카메라 중심에서 project되고 $M$개의 등거리 지점 $p_i$가 광선을 따라 샘플링된다. 주어진 카메라 포즈 $\xi \in \mathbb{R}^{3 \times 4}$에 대해 연산자 $\pi$는 고전적인 볼륨 렌더링을 사용하여 픽셀 $u \in \mathbb{R}^2$를 색상 $\hat{I} \in [0, 1]^3$에 매핑한다.
\[\begin{equation} \pi : (\xi, u) \rightarrow \hat{I}_u, \quad \hat{I}_u = \sum_{m=1}^M \alpha_m c_m \\ \alpha_m = T_m (1 - \exp (- \sigma_m \delta_m)) \\ T_m = \exp \bigg( - \sum_{m' = 1}^m \sigma_{m'} \delta_{m'} \bigg) \\ (\sigma_i, c_i) = f_\theta (p_i, d), \quad \delta_i = \| p_i - p_j \|_2 \end{equation}\]Signed Distance Field
NeRF는 인상적인 view 합성 결과를 달성하지만 밀도 기반 표현은 3D 형상을 추출하고 mesh를 얻는 데 적합하지 않다. 이 제한을 극복하기 위해 대신 SDF 기반 표현을 채택한다.
\[\begin{equation} f_\theta (p_i, d) = (s_i, c_i) \end{equation}\]여기서 $s_i \in \mathbb{R}$은 위치 $p_i$에서 표면으로부터의 부호가 있는 거리이다. 볼륨 렌더링으로 학습을 가능하게 하기 위해 SDF를 밀도 변환 $t$로 채택한다.
\[\begin{equation} t_\sigma (s)= \alpha \Psi_\beta (-s) \\ \Psi_\beta (s) = \begin{cases} \frac{1}{2} \exp \bigg( \frac{s}{\beta} \bigg) & \quad \textrm{if } s \le 0 \\ 1 - \frac{1}{2} \exp \bigg( -\frac{s}{\beta} \bigg) & \quad \textrm{if } s > 0 \end{cases} \end{equation}\]$\alpha, \beta \in \mathbb{R}$은 학습 가능한 파라미터이다. 이 변환을 사용하여 SDF 기반 neural field 표현을 동일한 볼륨 렌더링 기술로 이미지 평면에 렌더링할 수 있다.
2. Text-to-3D via Score-based Distillation
Score distillation sampling (SDS) 방식을 사용하여 neural distance field를 학습시켜 초기 3D 모델을 생성한다. 이를 위해 임의로 샘플링된 카메라 포즈 $\xi$가 주어지면 이미지 평면의 모든 픽셀 $u_i$에서 볼륨 렌더링 연산자 $\pi$를 사용하여 각각의 렌더링된 이미지 $\hat{I}$를 얻는다. 그런 다음 임의의 일반 noise와 timestep $t$를 샘플링하고 두 가중치 $\alpha_t$와 $\sigma_t$를 사용하여 렌더링된 이미지에 추가한다.
\[\begin{equation} \tilde{I}_t = \alpha_t \hat{I}_t + \sigma_t \epsilon, \quad \textrm{where} \quad \epsilon \sim \mathcal{N}(0, I) \end{equation}\]$\sigma_t$는 \(\tilde{I}_t\)가 diffusion process 시작 시 데이터 밀도에 가깝도록 선택된다. Noisy한 있는 이미지 $\tilde{I}$, diffusion step $t$, 텍스트 임베딩 $y$가 주어지면 $\epsilon_{\phi_I} (\tilde{I}, y, t)$로 noise를 예측하려고 시도하는 diffusion model $\phi_I$ (Imagen)에 $\tilde{I}$를 공급한다. 이 예측으로부터 제공된 텍스트 프롬프트에 대해 렌더링된 이미지를 높은 확률 밀도 영역으로 미는 기울기 방향을 도출할 수 있다.
\[\begin{equation} \nabla \mathcal{L}_\textrm{SDS} (\phi_I, \hat{I}) = \mathbb{E}_{t, \epsilon} \bigg[ w(t) (\epsilon_{\phi_I} (\tilde{I}_t; y, t) - \epsilon) \frac{\partial \hat{I}}{\partial \theta} \bigg] \end{equation}\]여기서 $w(t)$는 가중치 함수이고 $y$는 조건부 텍스트 임베딩이다. 그런 다음 이 기울기는 수렴될 때까지 signed distance field를 최적화하는 데 사용된다. Classifier-free guidance를 사용하여 텍스트 조건의 강도를 제어한다. 이 프로세스에는 MLP 기반 NeRF 볼륨 렌더링과 픽셀 레벨 diffusion model 실행이 포함되므로 메모리 제약으로 인해 저해상도에서만 수행할 수 있다. 이러한 이유로 64$\times$64로 렌더링된 이미지에서 \(\mathcal{L}_\textrm{SDS}\)를 계산한다 (즉, Imagen의 저해상도 분기만 사용). 음영 및 배경 모델링을 포함하여 렌더링에 대한 정확한 디테일은 DreamFusion의 디테일과 일치한다. 그러나 DreamFusion과 달리 모델 하단에서 아티팩트가 번지는 것을 방지하기 위해 카메라의 전체 고도 범위를 샘플링한다.
결국 Marching Cubes (MC)를 사용하여 zero-level set의 표면으로써 signed distance field에서 mesh가 추출된다. Floater (즉, 예상되는 물체 표면에서 signed distance 값이 0에 가까운 영역)가 때때로 볼륨 내에 남아 있을 수 있기 때문에, 추가로 항상 볼륨 중앙에 더 가까운 가장 큰 mesh 성분을 추가로 선택하여 mesh를 만들고 다음 단계에 사용할 수 있다.
3. Photorealistic Texturing Using Multi-View Consistent Diffusion
학습된 distance field에서 3D mesh $\mathcal{M}$을 추출하면 이미 모델에 적합한 형상이 있다. 반면에 텍스처에는 여전히 두 가지 주요 단점이 있다.
- 최적화가 저해상도에서만 수행되기 때문에 고주파수 디테일이 누락된다
- 큰 guidance 가중치를 사용한 결과 과포화된 (만화 같은) 색상이 표시된다.
이 두 가지 제한 사항을 해결하기 위해 색상과 깊이로 컨디셔닝된 Stable Diffusion 모델 $\textrm{SD}$의 표준 파이프라인을 사용하여 초기 텍스처를 개선한다. 이를 위해 획득한 mesh를 가져와 형상을 고정하고 differentiable render $R$ (NVdiffrast)을 사용하여 4개의 표준 시점 $\mathcal{P}$ (즉, 전면, 후면, 양쪽)에서 색상과 깊이를 렌더링한다. 4개의 view를 깊이로 컨디셔닝된 diffusion model에 독립적으로 공급하는 것은 객체의 매우 사실적인 이미지를 얻는 간단한 방법이며, 이는 re-texturing을 가이드하는 역할을 할 수 있다. 그러나 독립적으로 처리될 때 결과 이미지는 몇 가지 3D 불일치를 나타내어 시점에 따라 객체에 다른 identity를 부여한다.
이 한계를 극복하기 위해 2$\times$2 격자의 4개의 표준 RGB와 깊이 예측을 단일 RGB 이미지 \(\hat{I}_\textrm{tiled}\)와 깊이 맵 $D_\textrm{tiled}$에 타일링하고 단일 diffusion 연산에서 공동으로 처리한다.
\[\begin{equation} I_\textrm{tiled} = \textrm{SD} (\hat{I}_\textrm{tiled}, D_\textrm{tiled}) \end{equation}\]이는 타일 이미지가 diffuse되는 동안 diffusion model이 일관된 view를 생성하도록 한다 (아래 그림 참조).
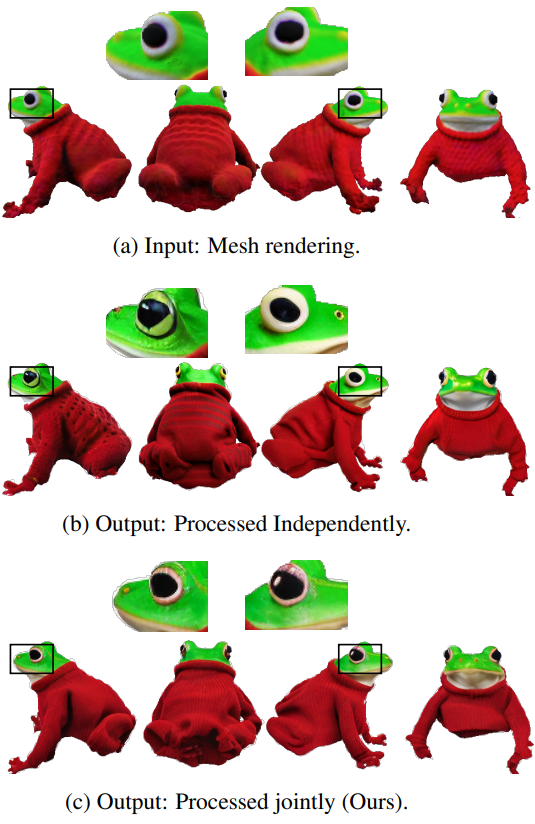
개별 pseudo ground truth view \(\{I_{\textrm{PseudoGT}, i}\}_{i=1}^4\)는 이미지 \(\hat{I}_\textrm{tiled}\)에서 추출된 다음, mesh 형상에 새 텍스처를 적용할 수 있도록 하는 pseudo ground truth로 사용된다. 최적화하는 loss는 다음과 같다.
View를 타일링하면 3D 개체 일관성이 크게 향상되지만 view는 여전히 교차점과 관찰되지 않는 개체 부분에서 약간의 오정렬을 나타낼 수 있다. 원활한 전환과 완전한 3D mesh를 보장하기 위해 image-to-image Stable Diffusion 모델 $\phi_\textrm{SD}$를 사용하여 photometric loss를 작은 SDS 성분과 결합하는 두 번째 최적화 단계를 수행한다. 이 단계에 대한 새로운 pseudo ground truth \(\{I'_{\textrm{PseudoGT},i}\}_i\)는 포즈 \(\mathcal{P}'\)에서 수렴된 텍스처를 렌더링하여 얻는다. 이 단계에서 다음을 최적화한다.
\[\begin{equation} \nabla \mathcal{L}_\textrm{textrue} (\mathcal{R}, \mathcal{M}, P, i) = \nabla \mathcal{L}_\textrm{MSE} + \lambda_\textrm{SDS} \nabla \mathcal{L}_\textrm{SDS} \\ \textrm{with} \quad \mathcal{L}_\textrm{MSE} = \| I'_{\textrm{PseudoGT}, i} - \hat{I} \|_2^2 \\ \textrm{and} \quad \hat{I} = \mathcal{R} (\mathcal{M}, P) \quad \textrm{for} \; P \in \mathcal{P}' \end{equation}\]여기서 $i$는 카메라 포즈 $P \in \mathcal{P}’$에 대한 시점을 설명하고 \(\lambda_\textrm{SDS}\)는 텍스처 최적화에 대한 기여도를 제어하는 SDS 가중치이다. 이 단계에서는 guidance 가중치를 높이면 색상이 포화되는 경우가 많으며 텍스처에 작은 변화만 주기를 원하기 때문에 이전의 SDS-supervised 연구들에 비해 7.5라는 매우 작은 guidance 가중치를 사용한다. 또한, 최적화를 \(I'_{\textrm{PseudoGT}, i}\)에 고정하면 결과 텍스처가 원본에서 너무 많이 벗어나지 않도록 강제하여 SDS 기울기가 높은 영역만 변경하도록 권장한다.
Evaluation
1. Comparison with state-of-the-art
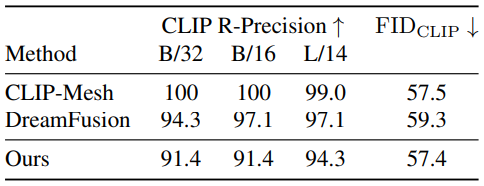
다음은 SOTA와 정량적으로 비교한 표이다.
다음은 정성적 결과를 비교한 표이다.

2. Ablation Study
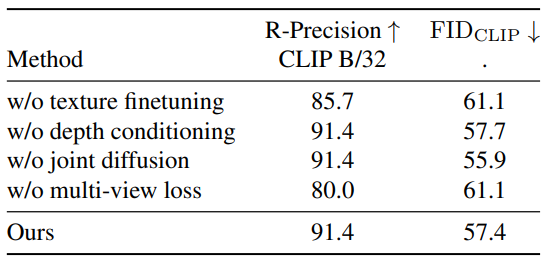
다음은 TextMesh의 다양한 구성 요소에 대한 ablation 결과이다.
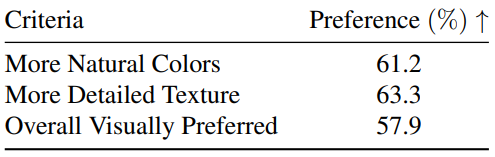
다음은 user study 결과이다.
3. Mesh Quality
다음은 3D mesh 형상을 DreamFusion과 비교한 것이다.

다음은 3D 일관성을 확인하기 위하여 여러 view를 나타낸 것이다.
