[논문리뷰] TextDiffuser: Diffusion Models as Text Painters
NeurIPS 2023. [Paper] [Github]
Jingye Chen, Yupan Huang, Tengchao Lv, Lei Cui, Qifeng Chen, Furu Wei
HKUST | Sun Yat-sen University | Microsoft Research
18 May 2023
Introduction
이미지 생성 분야는 diffusion model의 출현과 대규모 이미지-텍스트 쌍 데이터셋의 가용성으로 엄청난 발전을 보였다. 그러나 기존 diffusion model은 이미지에 시각적으로 만족스러운 텍스트를 생성하는 데 여전히 어려움을 겪고 있으며 현재 이 목적을 위한 전문화된 대규모 데이터셋이 없다. 다양한 형태의 텍스트 이미지가 광범위하게 사용되고 일반적으로 전문적인 기술이 필요한 고품질 텍스트 이미지를 생성하는 데 어려움이 있는 점을 고려할 때 AI 모델이 이미지에 정확하고 일관된 텍스트를 생성하는 능력은 매우 중요하다.
텍스트 이미지를 만드는 기존 솔루션에는 Photoshop과 같은 이미지 처리 도구를 사용하여 이미지에 텍스트를 직접 추가하는 것이 포함된다. 그러나 배경의 복잡한 텍스처나 조명 변화로 인해 종종 부자연스러운 아티팩트가 발생한다. 최근에는 전통적인 방법의 한계를 극복하고 텍스트 렌더링 품질을 향상시키기 위해 diffusion model을 사용했다. 예를 들어 Imagen, eDiff-I, DeepFloyd은 diffusion model이 CLIP 텍스트 인코더보다 T5 시리즈 텍스트 인코더로 텍스트를 더 잘 생성함을 보여주었다. 일부 성공에도 불구하고 이러한 모델은 생성 프로세스에 대한 제어가 부족한 텍스트 인코더에만 초점을 맞춘다.
본 논문에서는 diffusion model 기반의 유연하고 제어 가능한 프레임워크인 TextDiffuser를 제안한다. 프레임워크는 두 단계로 구성된다. 첫 번째 단계에서는 Layout Transformer를 사용하여 텍스트 프롬프트에서 각 키워드의 좌표를 찾고 문자 레벨 segmentation mask를 얻는다. 두 번째 단계에서는 생성된 segmentation mask를 텍스트 프롬프트와 함께 diffusion process의 조건으로 활용하여 latent diffusion model을 fine-tuning한다. 생성된 텍스트 영역의 품질을 더욱 향상시키기 위해 latent space에서 character-aware loss을 도입한다.

위 그림은 텍스트 프롬프트를 단독으로 사용하거나 텍스트 템플릿 이미지와 함께 사용하여 정확하고 일관된 텍스트 이미지를 생성하는 TextDiffuser의 적용을 보여준다. 또한 TextDiffuser는 텍스트로 불완전한 이미지를 재구성하기 위해 텍스트 인페인팅을 수행할 수 있다. 모델을 학습하기 위해 OCR 도구와 디자인 필터링 전략을 사용하여 OCR 주석이 있는 천만 개의 고품질 이미지-텍스트 쌍인 MARIO-10M을 얻는다. 여기서 OCR 주석은 각각 인식, 감지, 문자 레벨 segmentation 주석으로 구성된다. 저자들은 광범위한 실험과 user study를 통해 MARIO-Eval에서 기존 방법보다 제안된 TextDiffuser의 우수성을 입증하였다.
Methodology
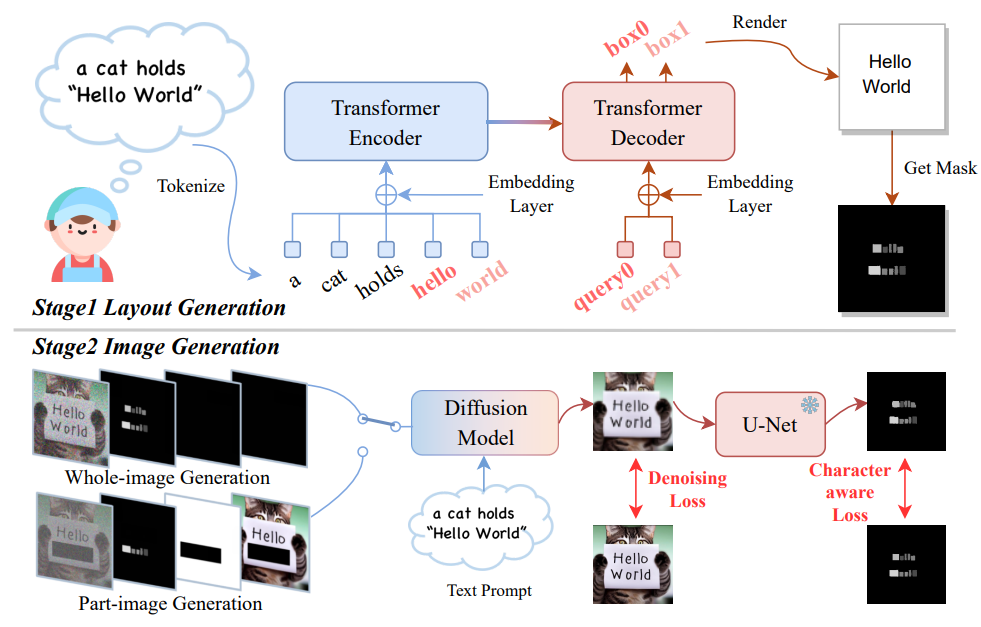
위 그림과 같이 TextDiffuser는 레이아웃 생성과 이미지 생성의 두 단계로 구성된다.
1. Stage1: Layout Generation
이 단계에서 목표는 bounding box를 활용하여 키워드의 레이아웃을 결정하는 것이다 (사용자 프롬프트에서 지정한 따옴표로 묶음). Layout Transformer에서 영감을 받아 Transformer 아키텍처를 활용하여 키워드 레이아웃을 얻는다.
토큰화된 프롬프트를 $\mathcal{P} = (p_0, p_1, \ldots, p_{L−1})$로 표시하자. 여기서 $L$은 토큰의 최대 길이를 의미한다. LDM을 따라 CLIP과 2개의 linear layer를 사용하여 시퀀스를 $\textrm{CLIP}(\mathcal{P}) \in \mathbb{R}^{L \times d}$로 인코딩한다. 여기서 $d$는 latent space의 차원이다. 키워드를 다른 키워드와 구별하기 위해 두 개의 entry (즉, keyword와 non-keyword)로 키워드 임베딩 $\textrm{Key}(\mathcal{P}) \in \mathbb{R}^{L \times d}$를 설계한다. 또한 임베딩 레이어 $\textrm{Width}(\mathcal{P}) \in \mathbb{R}^{L \times d}$로 키워드의 너비를 인코딩한다. 학습 가능한 위치 임베딩 $\textrm{Pos}(\mathcal{P}) \in \mathbb{R}^{L \times d}$와 함께 다음과 같이 전체 임베딩을 구성한다.
\[\begin{equation} \textrm{Embedding} (\mathcal{P}) = \textrm{CLIP} (\mathcal{P}) + \textrm{Pos} (\mathcal{P}) + \textrm{Key} (\mathcal{P}) + \textrm{Width} (\mathcal{P}) \end{equation}\]임베딩은 $K$ 개의 키워드의 bounding box $B \in \mathbb{R}^{K \times 4}$를 autoregressive하게 얻기 위해 Transformer 기반 $l$-layer 인코더 $\Phi_E$와 디코더 $\Phi_D$로 추가로 처리된다.
\[\begin{equation} B = \Phi_D (\Phi_E (\textrm{Embedding} (\mathcal{P}))) = (b_0, b_1, \ldots, b_{K-1}) \end{equation}\]특히 위치 임베딩을 Transformer 디코더 $\Phi_D$에 대한 query로 사용하여 $n$번째 query가 프롬프트의 $n$번째 키워드에 해당하는지 확인한다. 이 모델은 $\vert B_\textrm{GT} - B \vert$로도 표시되는 $l1$ loss로 최적화된다. 여기서 $B_\textrm{GT}$는 ground-truth이다. 또한 Pillow와 같은 일부 Python 패키지를 활용하여 텍스트를 렌더링하고 $\vert \mathcal{A} \vert$개의 채널로 문자 레벨 segmentation mask $C$를 얻을 수 있다. 여기서 $\vert \mathcal{A} \vert$는 알파벳 $\mathcal{A}$의 크기를 나타낸다.
2. Stage2: Image Generation
이 단계에서는 첫 번째 단계에서 생성된 segmentation mask $C$에 의해 가이드되는 이미지를 생성하는 것을 목표로 한다. VAE를 사용하여 모양이 $H \times W$인 원본 이미지를 4차원 latent space feature $F \in \mathbb{R}^{4 \times H’ \times W’}$로 인코딩한다. 그런 다음 timestep $T \sim \textrm{Uniform}(0, T_\textrm{max})$를 샘플링하고 Gaussian noise $\epsilon \sim \mathbb{R}^{4 \times H’ \times W’}$를 샘플링하여 원래 feature를 손상시키고
\[\begin{equation} \hat{F} = \sqrt{\vphantom{1} \bar{\alpha}_T} F + \sqrt{1 - \bar{\alpha}_T} \epsilon \end{equation}\]를 생성한다. 여기서 \(\bar{\alpha}_T\)는 DDPM에서 도입된 diffusion process의 계수이다. 또한 3개의 convolution layer로 문자 레벨 segmentation mask $C$를 다운샘플링하여 8차원 $C’ \in \mathbb{R}^{8 \times H’ \times W’}$를 생성한다. 또한 1차원 feature mask $M’ \in \mathbb{R}^{1 \times H’ \times W’}$와 4차원 마스킹된 feature \(\hat{F}_M \in \mathbb{R}^{4 \times H' \times W'}\)라는 두 가지 추가 feature를 도입한다. 전체 이미지 생성 과정에서 $\hat{M}$은 feature의 모든 영역을 커버하도록 설정되고 \(\hat{F}_M\)은 완전히 마스크된 이미지의 feature이다. 부분 이미지 생성 (텍스트 인페인팅) 과정에서 feature mask $\hat{M}$은 사용자가 생성하려는 영역을 나타내고 마스킹된 특징 \(\hat{F}_M\)은 사용자가 보존하려는 영역을 나타낸다. 두 가지를 동시에 학습하기 위해 샘플이 $\sigma$의 확률로 완전히 가려지고 $1 - \sigma$의 확률로 부분적으로 가려지는 마스킹 전략을 사용한다. Feature 채널에서 \(\hat{F}, \hat{C}, \hat{M}, \hat{F}_M\)을 17차원 입력으로 concat하고 샘플링된 noise $\epsilon$과 예측된 noise $\epsilon_\theta$ 사이의 denoising loss를 사용한다.
\[\begin{equation} l_\textrm{denoising} = \| \epsilon - \epsilon_\theta (\hat{F}, \hat{C}, \hat{M}, \hat{F}_M, \mathcal{P}, \mathcal{T}) \|_2^2 \end{equation}\]또한 모델이 텍스트 영역에 더 집중할 수 있도록 character-aware loss를 제안한다. 세부적으로 latent feature를 문자 레벨 segmentation mask에 매핑할 수 있는 U-Net을 사전 학습한다. 학습하는 동안 파라미터를 수정하고 가중치 $\lambda_\textrm{char}$가 있는 cross-entropy loss $l_\textrm{char}$를 사용하여 guidance를 제공하는 데만 사용한다. 전반적으로 모델은
\[\begin{equation} l = l_\textrm{denoising} + \lambda_\textrm{char} l_\textrm{char} \end{equation}\]로 최적화된다.
마지막으로 출력 feature는 VAE 디코더에 입력되어 이미지를 얻는다.
3. Inference Stage
TextDiffuser는 다음과 같은 방식으로 inference는 중에 높은 수준의 제어 가능성과 유연성을 제공한다.
- 사용자 프롬프트에서 이미지를 생성한다. 특히 사용자는 생성된 레이아웃을 수정하거나 개인화된 요구 사항에 맞게 텍스트를 편집할 수 있다.
- 사용자는 템플릿 이미지 (ex. 장면 이미지, 필기 이미지, 인쇄 이미지)를 제공하여 두 번째 단계부터 직접 시작할 수 있으며, segmentation model은 문자 레벨의 segmentation mask를 얻기 위해 사전 학습된다.
- 사용자는 텍스트 인페인팅을 사용하여 주어진 이미지의 텍스트 영역을 수정할 수 있다. 또한 이 작업은 여러 번 수행할 수 있다.
MARIO Dataset and Benchmark
텍스트 렌더링을 위해 특별히 설계된 대규모 데이터셋이 없기 때문에 저자들은 이 문제를 완화하기 위해 OCR 주석이 있는 1천만 개의 이미지-텍스트 쌍을 수집하여 MARIO-10M 데이터셋을 구성하였다. 또한 MARIO-10M 테스트셋의 부분 집합과 기타 기존 소스에서 MARIO-Eval Benchmark를 수집하여 텍스트 렌더링 품질을 평가하기 위한 포괄적인 도구 역할을 한다.
1. MARIO-10M Dataset
MARIO-10M은 자연 이미지, 포스터, 책 표지 등 다양한 데이터 소스에서 가져온 약 1천만 개의 고품질의 다양한 이미지-텍스트 쌍 모음이다.

위 그림은 데이터셋의 몇 가지 예를 보여준다. 저자들은 주석을 구성하고 노이즈 데이터를 정리하기 위해 자동 체계와 엄격한 필터링 규칙을 설계하였다. 데이터셋에는 텍스트 감지, 인식, 문자 레벨 segmentation 주석을 포함하여 각 이미지에 대한 포괄적인 OCR 주석이 포함되어 있다. 구체적으로 탐지를 위해 DB를 사용하고 인식을 위해 PARSeq를 사용하며 segmentation을 위해 U-Net을 수동으로 학습한다. MARIO-10M의 총 크기는 10,061,720이며, 이 중에서 학습 세트로 1천만 개의 샘플을 무작위로 선택하고 테스트셋으로 61,720개의 샘플을 선택한다. MARIO-10M은 세 가지 데이터 소스에서 수집된다.
MARIO-LAION은 대규모 데이터셋 LAION-400M에서 파생되었다. 저자들은 필터링 후 9,194,613개의 고품질 텍스트 이미지를 해당 캡션과 함께 얻었다. 이 데이터셋은 광고, 메모, 포스터, 표지, 밈, 로고 등을 포함한 광범위한 텍스트 이미지로 구성된다.
MARIO-TMDB는 고품질 포스터가 포함된 영화 및 TV 프로그램용 커뮤니티 구축 데이터베이스인 The Movie Database (TMDB)에서 파생되었다. 저자들은 수집된 759,859개의 샘플 중 TMDB API를 사용하여 343,423개의 영어 포스터를 필터링하였다. 각 이미지에는 캡션이 없기 때문에 프롬프트 템플릿을 사용하여 영화 제목에 따라 캡션을 구성하였다.
MARIO-OpenLibrary는 출판된 각 책에 대한 웹 페이지를 생성하는 편집 가능한 개방형 라이브러리 카탈로그인 Open Library에서 파생되었다. 저자들은 먼저 6,352,989개의 원본 크기 Open Library 표지를 대량으로 수집한 다음 필터링 후 523,684개의 고품질 이미지를 얻었다. MARIO-TMDB와 마찬가지로 캡션이 없기 때문에 제목을 사용하여 수동으로 캡션을 구성하였다.
2. MARIO-Eval Benchmark
MARIO-Eval benchmark는 MARIO-10M 테스트셋과 기타 소스의 부분 집합에서 수집된 텍스트 렌더링 품질을 평가하기 위한 포괄적인 도구 역할을 한다. DrawBenchText의 21개 프롬프트, DrawTextCreative의 175개 프롬프트, ChineseDrawText의 218개 프롬프트, MARIO-10M 테스트셋의 부분 집합에서 5,000개의 이미지-텍스트 쌍을 포함하여 총 5,414개의 프롬프트로 구성된다. 5,000개의 이미지-텍스트 쌍은 4,000, 500, 500 쌍의 3개의 세트로 나뉘며 각각의 데이터 소스를 기반으로 LAIONEval4000, TMDBEval500, OpenLibraryEval500으로 명명된다.
MARIO-Eval로 텍스트 렌더링 품질을 다음 네 가지 측면에서 평가한다.
- Fréchet Inception Distance (FID): 생성된 이미지의 분포와 실제 이미지의 분포를 비교한다.
- CLIPScore는 CLIP의 이미지와 텍스트 표현 간의 코사인 유사도를 계산한다.
- OCR 평가: 기존 OCR 도구를 활용하여 생성된 이미지에서 텍스트 영역을 감지하고 인식한다. Accuracy, Precision, Recall, F-measure는 키워드가 생성된 이미지에 나타나는지 여부를 평가하는 메트릭으로 사용된다. 4. 인간 평가: 인간 평가자를 초청하여 설문지를 사용하여 생성된 이미지의 텍스트 렌더링 품질을 평가하는 방식으로 수행된다.
Experiments
- 구현 디테일
- Stage 1
- 사전 학습된 CLIP을 활용하여 주어진 프롬프트의 임베딩을 얻음
- Transformer layer의 수 $l = 2$이고 latent space의 차원 $d = 512$
- CLIP을 따라 토큰의 최대 길이 $L = 77$
- Arial 폰트를 활용하고 폰트 크기를 24로 설정하여 너비 임베딩을 얻고 렌더링에도 이 글꼴을 사용
- 알파벳 $\mathcal{A}$는 26개의 대문자, 26개의 소문자, 10개의 숫자, 32개의 구두점, 공백 문자를 포함하여 95자로 구성
- 토큰화 후 단어에 대한 하위 토큰이 여러 개일 경우 첫 번째 하위 토큰만 키워드로 표시
- Stage 2
- Hugging Face Diffusers를 사용하여 diffusion process 구현하고 체크포인트 “runwayml/stable-diffusion-v1-5”를 사용
- 입력 convolution layer의 입력 차원(4 $\rightarrow$ 17)만 수정
- 입력 이미지와 출력 이미지의 높이 $H$와 너비 $W$는 512
- Diffusion process의 경우 입력은 $H’ = W’ = 64$
- Batch size = 768
- 8개의 Tesla V100 GPU 32GB로 4일 동안 2 epochs 학습
- Optimizer: AdamW (learning rate = $10^{-5}$)
- 계산 효율성을 위해 기울기 체크포인트와 xformers를 활용
- $T_\textrm{max}$ = 1000
- Classifier-free guidance를 위해 캡션이 10% 확률로 삭제됨
- 부분 이미지 생성을 학습할 때 감지된 텍스트 상자는 50%의 확률로 마스킹됨
- Inference하는 동안 50개의 샘플링 step을 사용하고 scale 7.5의 classifier-free guidance를 사용
- Stage 1
1. Ablation Studies
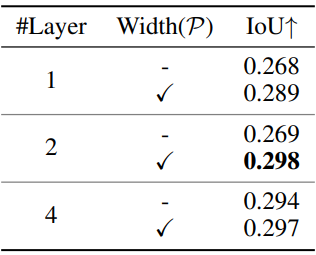
다음은 Layout Transformer에 대한 ablation 결과이다.
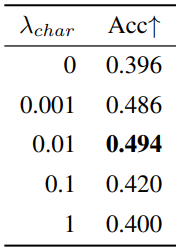
다음은 character-aware loss의 가중치에 대한 ablation 결과이다.
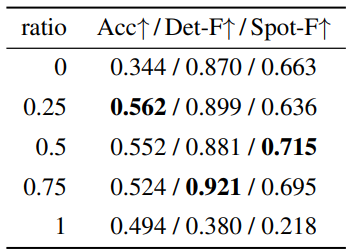
다음은 학습 비율 $\sigma$에 대한 ablation 결과이다.
2. Experimental Results
Quantitative Results
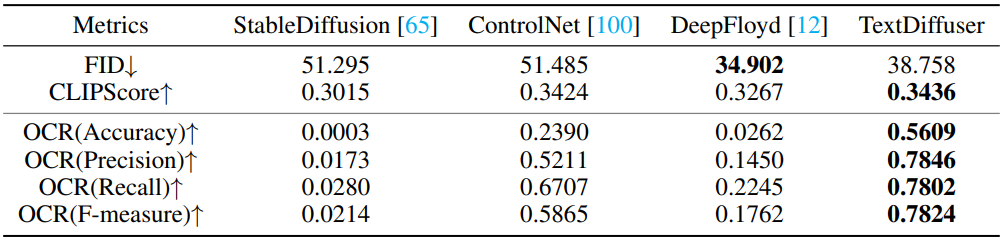
다음은 기존 방법들과 text-to-image의 성능을 비교한 표이다.
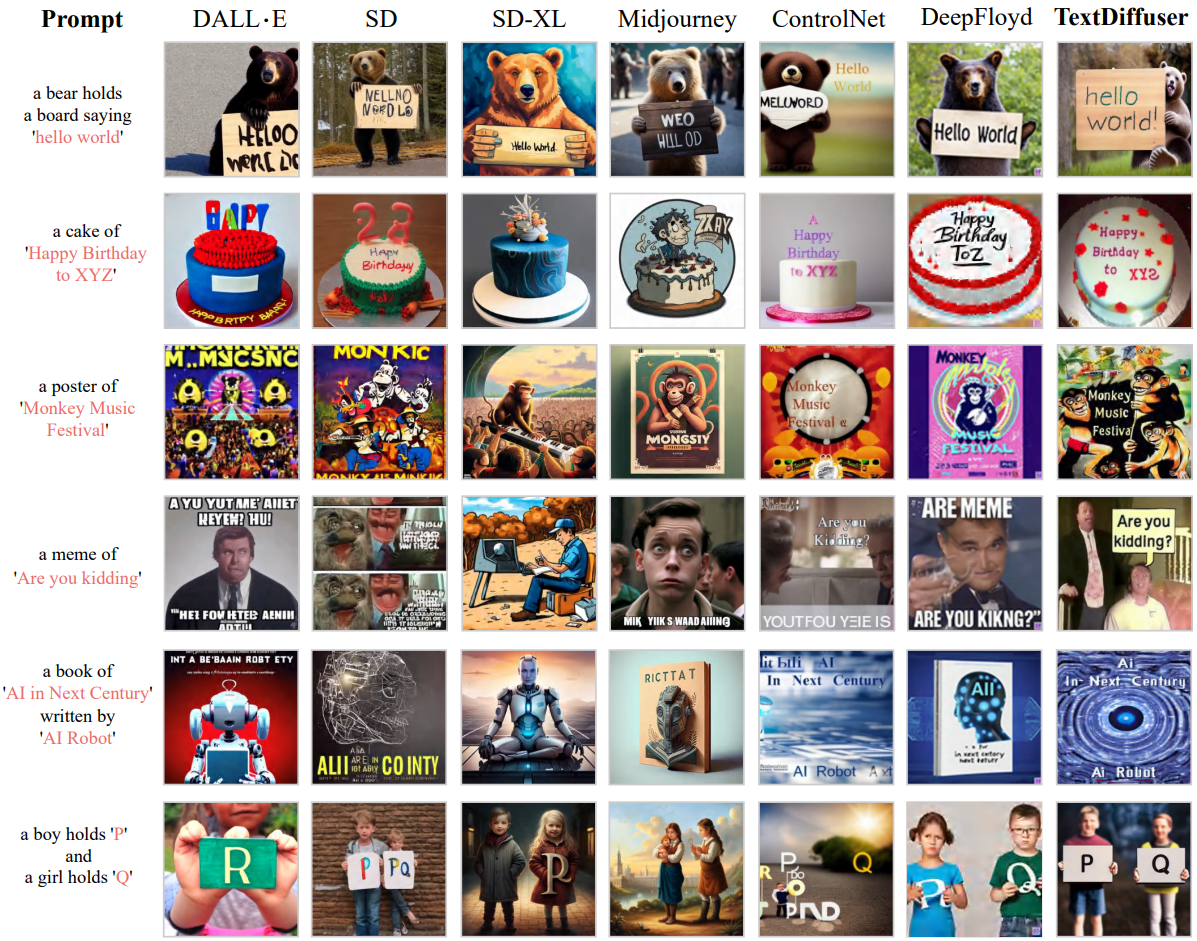
Qualitative Results
다음은 전체 이미지 생성 결과를 비교한 것이다.
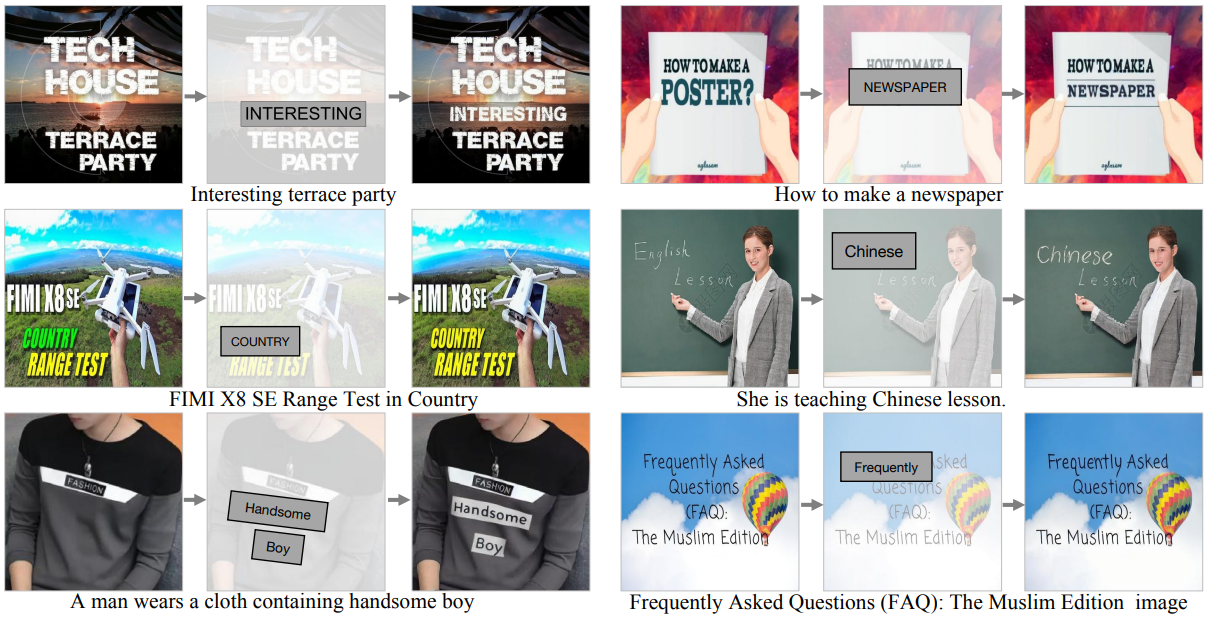
다음은 부분 이미지 생성 (인페인팅) 결과를 비교한 것이다.
User Studies
다음은 전체 이미지 생성 (왼쪽)과 부분 이미지 생성 (오른쪽)에 대한 user study 결과이다.
