[논문리뷰] Text2Room: Extracting Textured 3D Meshes from 2D Text-to-Image Models
ICCV 2023 (Oral). [Paper] [Page] [Github]
Lukas Höllein, Ang Cao, Andrew Owens, Justin Johnson, Matthias Nießner
The University of Hong Kong | Tencent AI Lab | Fudan University | Shanghai AI Laboratory
21 Mar 2023
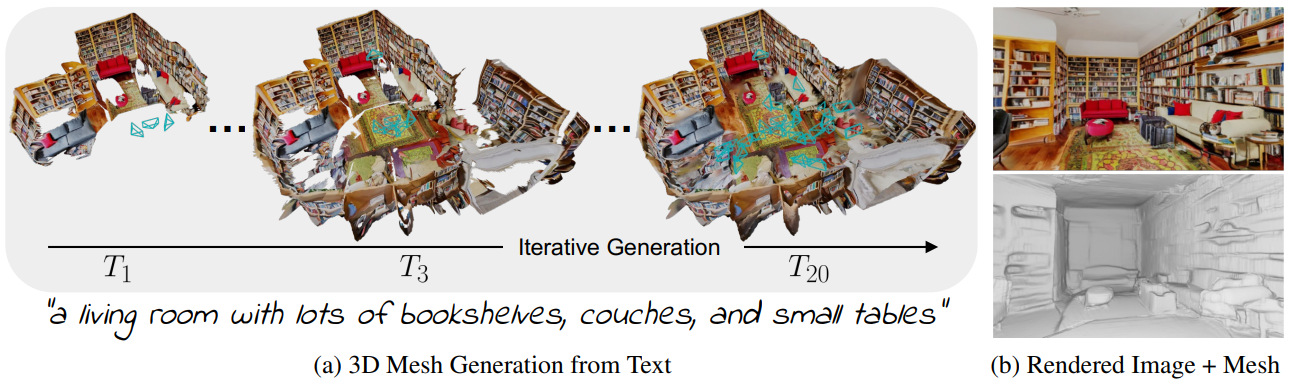
Introduction
3D 장면의 메쉬 표현은 AR/VR 에셋 생성부터 컴퓨터 그래픽에 이르기까지 많은 애플리케이션에서 중요한 구성 요소이지만 이러한 3D 에셋을 생성하는 것은 상당한 전문 지식이 필요한 힘든 과정으로 남아 있다. 2D 도메인에서 최근 연구에서는 diffusion model과 같은 생성 모델을 사용하여 텍스트로부터 고품질 이미지를 성공적으로 생성했다. 이러한 방법은 사용자가 원하는 콘텐츠가 포함된 이미지 생성에 대한 장벽을 크게 줄여 콘텐츠 생성의 민주화에 효과적으로 도움을 주었다. 다양한 연구들에서 유사한 방법을 적용하여 텍스트에서 3D 모델을 생성하려고 노력했지만 기존 접근 방식에는 여러 가지 중요한 제한 사항이 있으며 2D text-to-image 모델의 일반성이 부족하다.
3D 모델 생성의 핵심 과제 중 하나는 사용 가능한 3D 학습 데이터 부족에 대처하는 것이다. 3D 데이터셋은 2D 이미지 데이터셋보다 훨씬 작기 때문이다. 예를 들어 3D supervision을 직접 사용하는 방법은 ShapeNet과 같은 단순한 모양의 데이터셋으로 제한되는 경우가 많다. 이러한 데이터 제한을 해결하기 위해 최근 방법들에서는 3D 생성을 이미지 도메인의 반복 최적화 문제로 공식화하여 2D text-to-image 이미지 모델의 표현력을 3D로 끌어올린다. 이를 통해 radiance field 표현에 저장된 3D 객체를 생성할 수 있으며, 텍스트에서 임의의 모양을 생성하는 능력을 보여준다. 그러나 이러한 방법은 룸 스케일의 3D 구조와 텍스처를 생성하기 위해 쉽게 확장될 수 없다. 대규모 장면을 생성할 때 어려운 점은 생성된 출력이 외부를 향한 관점에서 조밀하고 일관성이 있는지 확인하고 이러한 뷰에 벽, 바닥, 가구 등 필요한 모든 구조가 포함되어 있는지 확인하는 것이다. 또한 메쉬는 상용 하드웨어 렌더링과 같은 많은 작업에 대해 원하는 표현으로 남아 있다.
이러한 단점을 해결하기 위해 본 논문은 기존 2D text-to-image 모델에서 장면 스케일의 3D 메쉬를 추출하는 방법인 Text2Room을 제안한다. Text2Room은 인페인팅과 단안 깊이 추정을 통해 반복적으로 장면을 생성한다. 텍스트로부터 이미지를 생성하여 초기 메쉬를 생성하고 깊이 추정 모델을 사용하여 이를 3D로 역투영한다. 그런 다음 새로운 시점에서 메쉬를 반복적으로 렌더링한다. 각각의 이미지에서 인페인팅을 통해 렌더링된 이미지의 구멍을 채운 다음 생성된 콘텐츠를 메쉬에 융합한다.
반복 생성 방식에는 두 가지 중요한 디자인 고려 사항이 있다. 즉, 시점 선택 방법과 생성된 장면 콘텐츠를 기존 메쉬와 병합하는 방법이다. 먼저 대량의 장면 콘텐츠를 포함하는 미리 정의된 궤적에서 시점을 선택한 다음 나머지 구멍을 닫는 시점을 적응적으로 선택한다. 생성된 콘텐츠를 메쉬와 병합할 때 두 개의 깊이 맵을 정렬하여 부드러운 전환을 만들고 왜곡된 텍스처가 포함된 메쉬 부분을 제거한다. 이러한 결정을 통해 광범위한 공간을 표현할 수 있는 강력한 텍스처와 일관된 형상을 갖춘 대규모 장면 스케일 3D 메쉬가 생성된다.
Method

Text2Room의 방법은 텍스트 입력을 통해 전체 장면의 텍스가 있는 3D 메쉬를 생성한다. 이를 위해 다양한 포즈의 2D text-to-image 모델에서 생성된 프레임을 공동 3D 메쉬로 지속적으로 융합하여 시간이 지남에 따라 장면을 만든다. 접근 방식의 핵심 아이디어는 먼저 장면 레이아웃과 개체를 생성한 다음 3D 형상의 나머지 구멍을 닫는 2단계 맞춤형 시점 선택이다. 두 단계의 각 포즈에 대해 반복적인 장면 생성 체계를 적용하여 메쉬를 업데이트한다. 먼저 깊이 정렬 전략을 사용하여 각 프레임을 기존 형상에 정렬한다. 그런 다음 새로운 콘텐츠를 삼각측량하고 필터링하여 메쉬에 병합한다.
1. Iterative 3D Scene Generation
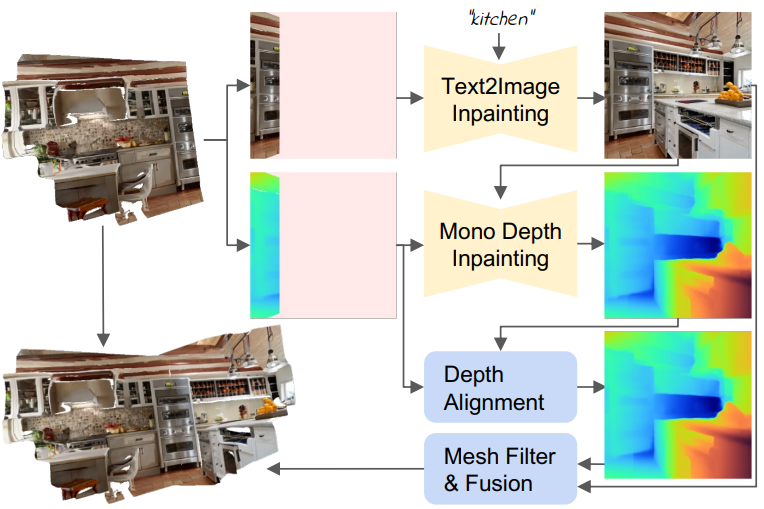
장면은 메쉬 $\mathcal{M} = (\mathcal{V}, \mathcal{C}, \mathcal{S})$로 표현되며, 여기서 정점 $\mathcal{V} \in \mathbb{R}^{N \times 3}$, 정점 색상 $\mathcal{C} \in \mathbb{R}^{N \times 3}$, 면 집합 $S \in \mathbb{N}_0^{M \times 3}$이 시간이 지남에 따라 생성된다. 두 단계 모두에서 입력은 선택한 포즈 \(\{E_t\}_{t=1}^T \in \mathbb{R}^{3 \times 4}\)에 해당하는 임의의 텍스트 프롬프트 집합 \(\{P_t\}_{t=1}^T\)이다. InfiniteNature-Zero에서 영감을 받아 render-refine-repeat 패턴을 따라 장면을 반복적으로 구축한다. 이 반복적인 장면 생성 프로세스를 위 그림에 요약되어 있다. 공식적으로, 생성의 각 step $t$에 대해 먼저 새로운 시점에서 현재 장면을 렌더링한다.
여기서 $r$은 음영이 없는 전통적인 래스터화(rasterization) 함수, $I_t$는 렌더링된 이미지, $d_t$는 렌더링된 깊이, $m_t$는 콘텐츠가 관찰되지 않은 픽셀을 마킹하는 이미지 공간 마스크이다. 그런 다음 고정된 text-to-image 모델 \(\mathcal{F}_{\textrm{t2i}}\)를 사용하여 텍스트 프롬프트에 따라 관찰되지 않은 픽셀을 인페인팅한다.
\[\begin{equation} \hat{I}_t = \mathcal{F}_\textrm{t2i} (I_t, m_t, P_t) \end{equation}\]다음으로, 깊이 정렬에 단안 깊이 추정기 \(\mathcal{F}_d\)를 적용하여 관찰되지 않은 깊이를 다시 칠한다.
\[\begin{equation} \hat{d}_t = \textrm{predict-and-align} (\mathcal{F}_d, I_t, d_t, m_t) \end{equation}\]마지막으로 본 논문의 융합 방식을 통해 새로운 콘텐츠 \(\{\hat{I}_t, \hat{d}_t, m_t\}\)를 기존 메쉬와 결합한다.
2. Depth Alignment Step
2D 이미지 $I$를 3D로 끌어올리기 위해 픽셀당 깊이를 예측한다. 이전 콘텐츠와 새 콘텐츠를 올바르게 결합하려면 두 콘텐츠가 서로 일치해야 한다. 즉, 벽이나 가구와 같은 장면의 유사한 영역은 비슷한 깊이에 배치되어야 한다. 그러나 역투영(backprojection)에 대해 예측된 깊이를 직접 사용하면 깊이가 시점 간의 스케일에 따라 일관되지 않기 때문에 3D 형상에서 불연속성이 발생한다.
이를 위해 2단계로 깊이 정렬을 수행한다. 먼저, 이미지의 알려진 부분에 대한 ground-truth 깊이 $d$를 입력으로 사용하고 그에 대한 예측을 정렬하는 최첨단 깊이 인페인팅 네트워크를 사용한다.
\[\begin{equation} \hat{d}_p = \mathcal{F}_d (I, d) \end{equation}\]그런 다음 scale 및 shift 파라미터 $\gamma, \beta in \mathbb{R}$을 최적화하고 예측과 렌더링된 불일치를 정렬하여 결과를 개선한다.
\[\begin{equation} \min_{\gamma, \beta} \bigg\| m \odot \bigg( \frac{\gamma}{\hat{d}_p} + \beta - \frac{1}{d} \bigg) \bigg\|^2 \end{equation}\]$m$을 통해 관찰되지 않은 픽셀을 마스킹 처리한다. 그런 다음 정렬된 깊이를
\[\begin{equation} \hat{d} = \bigg(\frac{\gamma}{\hat{d}_p} + \beta \bigg)^{-1} \end{equation}\]로 추출할 수 있다. 마지막으로 마스크 가장자리에 5$\times$5 Gaussian kernel을 적용하여 $\hat{d}$를 매끄럽게 만든다.
3. Mesh Fusion Step
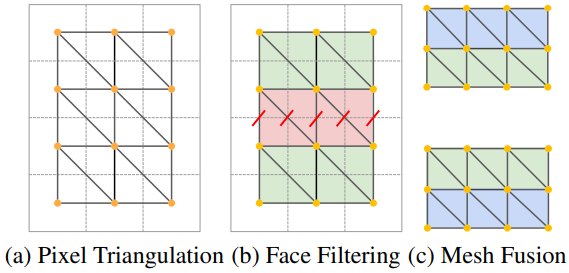
각 step에서 새로운 콘텐츠 \(\{\hat{I}_t, \hat{d}_t, m_t\}\)를 장면에 삽입한다. 이를 위해 먼저 이미지 공간의 픽셀을 3D 공간의 포인트 클라우드로 역투영한다.
여기서 $K \in \mathbb{R}^{3 \times 3}$은 카메라 내장 함수(camera intrinsics)이고 $W$, $H$는 각각 이미지 너비와 높이이다. 그런 다음 간단한 삼각측량 방식을 사용한다. 여기서 각 4개의 이웃 픽셀 \(\{(u, v), (u+1, v), (u, v+1), (u+1, v+1)\}\)은 이미지에서는 두 개의 삼각형을 형성한다. 추정된 깊이에는 잡음이 많기 때문에 이 삼각측량 방식은 늘어난 3D 형상을 생성한다. 이 문제를 완화하기 위해 저자들은 늘어난 면을 제거하는 두 가지 필터를 제안하였다.
- 모서리 길이를 기준으로 면을 필터링한다. 면 모서리의 유클리드 거리가 임계값 \(\delta_\textrm{edge}\)보다 큰 경우 면을 제거한다.
- 표면 법선과 보는 방향 사이의 각도를 기준으로 면을 필터링한다.
여기서 $\mathcal{S}$는 면 집합이고, $(i_0, i_1, i_2)$는 삼각형의 정점 인덱스, \(\delta_\textrm{sn}\)은 임계값, $n \in \mathbb{R}^3$은 정규화된 면 법선, $v \in \mathbb{R}^3$은 카메라 중심에서 삼각형이 시작된 평균 픽셀 위치를 향하는 3D 공간에서의 정규화된 뷰 방향이다. 이렇게 하면 이미지의 비교적 적은 수의 픽셀에서 메쉬의 넓은 영역에 대한 텍스처가 생성되는 것을 방지할 수 있다.
마지막으로 새로 생성된 메쉬 패치와 기존 형상을 융합한다. 인페인팅 마스크 $m_t$에 속하는 픽셀에서 역투영된 모든 면은 이미 메쉬의 일부인 인접 면과 함께 연결된다. 정확하게는 $m_t$의 모든 가장자리에서 삼각측량 방식을 계속 사용하지만 $M_t$의 기존 꼭지점 위치를 사용하여 해당 면을 만든다.
4. Two-Stage Viewpoint Selection
Text2Room의 핵심 부분은 장면이 합성되는 텍스트 프롬프트와 카메라 포즈를 선택하는 것이다. 사용자는 원칙적으로 이러한 입력을 임의로 선택하여 원하는 실내 장면을 만들 수 있다. 그러나 포즈를 부주의하게 선택하면 생성된 장면이 변형되고 늘어짐 및 구멍 아티팩트가 포함될 수 있다. 이를 위해 저자들은 최적의 위치에서 각 다음 카메라 포즈를 샘플링하고 이후에 빈 영역을 개선하는 2단계 시점 선택 전략을 제안하였다.
Generation Stage
첫 번째 단계에서는 일반 레이아웃과 가구를 포함하여 장면의 주요 부분을 만든다. 이어서 결국 방 전체를 덮는 미리 정의된 궤적을 다양한 방향으로 렌더링한다. 저자들은 각 궤적이 대부분 관찰되지 않은 영역이 있는 시점에서 시작하는 경우 생성이 가장 잘 작동한다는 것을 발견했다. 이는 장면의 나머지 부분과 계속 연결되어 있는 동안 다음 청크의 윤곽선을 생성한다. 그런 다음 궤적이 끝날 때까지 계속해서 이동하고 회전하여 해당 청크의 3D 구조를 완성한다.
또한 각 포즈에 대한 최적의 관찰 거리를 보장한다. 시선 방향 $L \in \mathbb{R}^3$을 따라 카메라 위치 $T_0 \in \mathbb{R}^3$을 균일하게 변환한다.
\[\begin{equation} T_{i+1} = T_i - 0.3L \end{equation}\]평균 렌더링 깊이가 0.1보다 크면 중지하거나 10 step 후에 카메라를 폐기한다. 이렇게 하면 기존 형상에 너무 가까운 뷰를 방지할 수 있다.
대략 원점을 중심으로 원형 동작으로 다음 청크를 생성하는 궤적을 선택하여 이 원칙에 따라 닫힌 방 레이아웃을 만든다. 그에 따라 텍스트 프롬프트를 엔지니어링함으로써 text-to-image 모델이 원치 않는 영역에 가구를 생성하는 것을 막는 것이 도움이 된다. 예를 들어 바닥이나 천장을 바라보는 포즈의 경우 각각 “바닥” 또는 “천장”이라는 단어만 포함하는 텍스트 프롬프트를 선택한다.
Completion Stage
첫 번째 step 후에 장면 레이아웃과 가구가 정의된다. 그러나 선험적으로 충분한 포즈를 선택하는 것은 불가능하다. 장면은 즉시 생성되므로 메쉬에는 어떤 카메라에서도 관찰되지 않은 구멍이 포함되어 있다. 그 구멍을 보면서 사후에 추가 포즈를 샘플링하여 장면을 완성한다.
장면을 조밀하고 균일한 셀로 복셀화(voxelize)한다. 각 셀에서 랜덤 포즈를 샘플링하고 기존 형상에 너무 가까운 포즈는 삭제한다. 가장 관찰되지 않은 픽셀을 보는 셀당 하나의 포즈를 선택한다.
다음으로 선택한 모든 카메라 포즈의 장면을 앞서 설명한 방법으로 인페인팅한다. Text-to-image 모델이 연결된 큰 영역에 대해 더 나은 결과를 생성할 수 있기 때문에 인페인팅 마스크를 지우는 것이 중요하다. 따라서 먼저 고전적인 인페인팅 알고리즘을 사용하여 작은 구멍을 인페인팅하고 나머지 구멍을 확장한다. 확장된 영역에 속하고 렌더링된 깊이에 가까운 모든 면을 추가로 제거한다.
마지막으로 장면 메쉬에서 Poisson surface reconstruction을 실행한다. 이렇게 하면 완료 후 남은 구멍이 닫히고 불연속성이 완화된다. 그 결과 생성된 장면의 빈틈없는 메쉬가 생성되며, 이는 고전적인 래스터화(rasterization)를 통해 렌더링할 수 있다.
Results
- 구현 디테일
- \(\mathcal{F}_{t2i}\): Stable Diffusion
- \(\mathcal{F}_d\): IronDepth
- \(\delta_\textrm{edge} = 0.1\), \(\delta_\textrm{sn} = 0.1\)
- 생성하는 동안 각각의 시작 포즈와 끝 포즈 사이에 각각 샘플링된 10개의 프레임이 있는 20개의 서로 다른 궤적을 사용
- 하나의 장면을 만드는데 RTX 3090 GPU에서 50분 소요
1. Qualitative Results
다음은 다른 방법들과 결과를 비교한 것이다.

다음은 3D 장면 생성 결과이다.

2. Quantitative Results & Ablations
다음은 다른 방법들과 정량적으로 비교한 표이다.
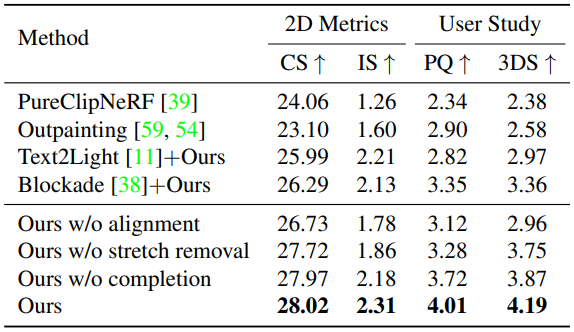
다음은 Text2Room의 주요 구성 요소에 대한 ablation study 결과이다.

4. Spatially Varying Scene Generation
다음은 여러 텍스트 프롬프트를 결합하여 공간적으로 다양한 장면을 생성한 결과이다.

다음은 레이아웃 guidance로 장면을 생성한 결과이다.

Limitations
- Text2Room의 임계값 방식은 확장된 영역을 모두 감지하지 못할 수 있으며, 이로 인해 왜곡이 남아 있을 수 있다.
- 일부 구멍은 두 번째 단계 후에도 완전히 완료되지 않을 수 있으며, 이로 인해 포아송 재구성을 적용한 후 영역이 지나치게 평활해진다.
- 장면 표현이 그림자나 조명과 물질들을 분리하지 않는다.