[논문리뷰] Text2LIVE: Text-Driven Layered Image and Video Editing
ECCV 2022. [Paper] [Page] [Github]
Omer Bar-Tal, Dolev Ofri-Amar, Rafail Fridman, Yoni Kasten, Tali Dekel
Weizmann Institute of Science | NVIDIA Research
5 Apr 2022

Introduction
자연 이미지와 동영상에서 개체의 모양과 스타일을 조작하는 계산 방법은 엄청난 발전을 보여 사용자가 다양한 편집 효과를 쉽게 얻을 수 있다. 그럼에도 불구하고 이 분야의 연구는 주로 레퍼런스 이미지에 의해 대상 외형이 주어지고 원본 이미지가 글로벌하게 편집되는 Style-Transfer에 집중되어 있다. 편집의 localization을 제어하려면 일반적으로 분할 마스크와 같은 추가 입력 guidance가 필요하다. 따라서 외형 transfer는 대부분 글로벌 예술적 stylization 또는 특정 이미지 도메인 또는 스타일로 제한되었다. 본 논문에서는 이러한 요구 사항을 제거하고 실제 이미지 및 동영상의 보다 유연하고 창의적인 의미론적 외형 조작을 가능하게 하고자 한다.
최신 Vision-Language model의 전례 없는 성능에 영감을 받아 간단한 텍스트 프롬프트를 사용하여 대상 편집을 표현한다. 이를 통해 사용자는 쉽고 직관적으로 대상의 모습과 편집 대상 개체/영역을 지정할 수 있다. 구체적으로, 주어진 대상 텍스트 프롬프트를 만족시키는 로컬한 의미론적 편집을 가능하게 한다. 예를 들어 케이크 이미지와 대상 텍스트 “oreo cake”가 주어지면 자동으로 케이크 영역을 찾고 원래 이미지인 크림과 자연스럽게 결합되는 사실적이고 고품질 텍스처를 합성한다. 필링과 쿠키 부스러기가 전체 케이크와 슬라이스 조각을 semantically-aware 방식으로 색칠한다.
본 논문의 프레임워크는 4억 개의 텍스트-이미지 예제에 대해 사전 학습된 CLIP 모델에서 학습한 표현을 활용한다. CLIP이 차지하는 방대한 시각적 및 텍스트 공간의 풍부함은 다양한 최근 이미지 편집 방법에서 입증되었다. 그러나 임의의 실제 이미지에서 기존 개체를 편집하는 작업은 여전히 어렵다. 대부분의 기존 방법은 CLIP과 함께 사전 학습된 generator(ex. GAN 또는 Diffusion model)를 결합한다. GAN을 사용하면 이미지 도메인이 제한되며 입력 이미지를 GAN의 latent space로 invert해야 한다. 이는 그 자체로 어려운 작업이다. Diffusion model은 이러한 한계를 극복하지만 목표 편집을 만족시키는 것과 원본 콘텐츠에 대한 충실도를 유지하는 것 사이에 내재된 trade-off에 직면한다. 또한 동영상으로 확장하는 것은 간단하지 않다. 본 논문에서는 다른 방법으로 단일 입력 이미지 또는 동영상 및 텍스트 프롬프트에서 generator를 학습할 것을 제안한다.
본 논문은 두 가지 주요 구성 요소를 통해 외부 생성 사전이 사용되지 않는 경우에 생성을 의미 있는 고품질 편집으로 이끈다.
- 새로운 텍스트 기반 레이어 편집을 제안한다. 즉, 편집된 이미지를 직접 생성하는 대신 입력에 합성되는 RGBA 레이어(색상 및 불투명도)를 통해 편집을 나타낸다. 이를 통해 편집 레이어에 직접 적용되는 텍스트 기반 loss를 포함하여 새로운 목적 함수를 통해 생성된 편집의 콘텐츠 및 localization을 guide할 수 있다.
- 입력 이미지와 텍스트에 다양한 augmentation을 적용하여 다양한 이미지-텍스트 학습 예제의 내부 데이터셋에서 generator를 학습시킨다. 내부 학습 접근 방식이 강력한 정규화 역할을 하여 복잡한 텍스처와 반투명 효과의 고품질 생성을 가능하게 한다.
본 논문은 프레임워크를 텍스트 기반 동영상 편집 영역으로 가져간다. 현실 세계 동영상은 장면에 대한 풍부한 정보를 제공하는 복잡한 개체와 카메라 모션으로 구성되는 경우가 많다. 그럼에도 불구하고 일관된 동영상 편집을 달성하는 것은 어렵고 순전히 달성할 수 없다. 따라서 저자들은 Layered Neural Atlases를 사용하여 동영상을 2D atlas의 집합으로 분해할 것을 제안한다. 각 atlas는 동영상 전체에서 전경 개체 또는 배경을 나타내는 통합된 2D 이미지로 취급될 수 있다. 이 표현은 동영상 편집 작업을 크게 단순화한다. 단일 2D atlas에 적용된 편집 내용은 일관된 방식으로 전체 동영상에 자동으로 다시 매핑된다. 동영상에서 쉽게 사용할 수 있는 풍부한 정보를 활용하면서 atlas space에서 편집을 수행하도록 프레임워크를 확장한다.
Text-Guided Layered Image and Video Editing
간단한 텍스트 프롬프트로 표현되는 의미론적이고 localize된 편집에 중점을 둔다. 이러한 편집에는 개체의 텍스처를 변경하거나 복잡한 반투명 효과로 장면을 의미론적으로 보강하는 작업이 포함된다. 이를 위해 사전 학습된 CLIP 모델을 활용하면서 단일 입력 이미지 또는 동영상에서 generator를 학습할 수 있는 잠재력을 활용한다. CLIP 모델은 고정된 상태로 유지되고 loss를 설정하는 데 사용된다. CLIP에 따르면 대상 텍스트를 만족시킬 수 있는 수많은 편집이 있을 수 있으며 그 중 일부는 noisy하거나 바람직하지 않은 솔루션을 포함한다. 따라서 편집의 localization을 제어하고 원본 콘텐츠를 보존하는 것은 모두 고품질 편집 결과를 얻기 위한 핵심 구성 요소이다. 다음과 같은 주요 구성 요소를 통해 이러한 문제를 해결한다.
- Layered editing: Generator는 입력 이미지에 합성된 RGBA 레이어를 출력한다. 이를 통해 편집 레이어에 직접 적용되는 전용 loss를 통해 편집 내용과 공간 범위를 제어할 수 있다.
- Explicit content preservation and localization losses: 원본 콘텐츠를 보존하고 편집 내용의 localization을 guide한다.
- Internal generative prior: 입력 이미지/동영상과 텍스트에 augmentation을 적용하여 예제의 내부 데이터셋을 구성한다. 이러한 augment된 예제는 더 크고 다양한 예제 셋에서 텍스트 기반 편집을 수행하는 generator를 학습시키는 데 사용된다.
1. Text to Image Edit Layer

위 그림에서 볼 수 있듯이 본 논문의 프레임워크는 소스 이미지 $I_s$를 입력으로 취하고 컬러 이미지 $C$와 불투명도 맵 $\alpha$로 구성된 편집 레이어 \(\mathcal{E} = \{C, \alpha\}\)를 합성하는 generator $G_\theta$로 구성된다. 최종 편집된 이미지 $I_o$는 $I_s$ 위에 편집 레이어를 합성하여 제공된다.
주요 목표는 $I_o$가 대상 텍스트 프롬프트 $T$를 준수하도록 $\mathcal{E}$를 생성하는 것이다. 또한 RGBA 레이어를 생성하면 텍스트를 사용하여 생성된 콘텐츠 및 localization을 추가로 guide할 수 있다. 이를 위해 2가지 보조 텍스트 프롬프트를 고려한다.
- $T_\textrm{screen}$: 대상 편집 레이어를 표현
- $T_\textrm{ROI}$: 소스 이미지에서 관심 영역(ROI)을 지정하고 localization을 초기화하는 데 사용
Objective function
본 논문의 새로운 목적 함수는 CLIP의 feature space에서 정의된 3가지 loss 항을 통합하였다.
- \(\mathcal{L}_\textrm{comp}\): $I_o$가 $T$를 잘 따르도록 만드는 loss
- \(\mathcal{L}_\textrm{screen}\): 편집 레이어의 직접적인 supervision 역할을 하는 loss
- \(\mathcal{L}_\textrm{structure}\): 구조 보존 loss
여기에 추가로 정규화 항 \(\mathcal{L}_\textrm{reg}\)를 사용하여 alpha matte $\alpha$를 통해 편집 범위를 제어한다.
\[\begin{equation} \mathcal{L}_\textrm{Text2LIVE} = \mathcal{L}_\textrm{comp} + \lambda_g \mathcal{L}_\textrm{screen} + \lambda_s \mathcal{L}_\textrm{structure} + \lambda_r \mathcal{L}_\textrm{reg} \end{equation}\]Composition loss
\(\mathcal{L}_\textrm{comp}\)는 대상 텍스트 프롬프트와 일치하는 이미지를 생성하는 주요 목표를 반영하며 코사인 거리 loss와 방향 loss의 조합으로 구성된다.
\[\begin{aligned} \mathcal{L}_\textrm{comp} &= \mathcal{L}_\textrm{cos} (I_o, T) + \mathcal{L}_\textrm{dir} (I_s, I_o, T_\textrm{ROI}, T) \\ \mathcal{L}_\textrm{cos} &= \mathcal{D}_\textrm{cos} (E_\textrm{im} (I_o), E_\textrm{txt} (T)) \\ \mathcal{L}_\textrm{dir} &= \mathcal{D}_\textrm{cos} (E_\textrm{im} (I_o) - E_\textrm{im} (I_s), E_\textrm{txt} (T) - E_\textrm{txt} (T_\textrm{ROI})) \\ \end{aligned}\]여기서 \(E_\textrm{im}\)과 \(E_\textrm{txt}\)는 각각 CLIP의 이미지 인코더와 텍스트 인코더이다.
대부분의 CLIP 기반 편집 방법과 비슷하게 먼저 각 이미지를 augment하여 여러 다양한 view를 얻고 각 view에 대한 CLIP loss를 따로 계산한다.
Screen loss
\(\mathcal{L}_\textrm{screen}\)은 생성된 편집 레이어 $\mathcal{E}$에 대한 직접적인 텍스트 supervision 역할을 한다. 단색 배경(종종 녹색)이 후처리 시에 이미지로 대체되는 chroma keying에서 영감을 얻었다. Chroma keying은 이미지 및 동영상 후반 작업에서 광범위하게 사용되며 녹색 배경 위에 다양한 시각적 요소를 묘사한다. 따라서 녹색 배경 $I_\textrm{green}$ 위에 편집 레이어를 합성하고 텍스트 템플릿 \(T_\textrm{screen} := "\{ \} \textrm{ over a green screen}"\)과 일치하도록 한다.
\[\begin{equation} \mathcal{L}_\textrm{screen} = \mathcal{L}_\textrm{cos} (I_\textrm{screen}, T_\textrm{screen}) \\ I_\textrm{screen} = \alpha \cdot C + (1- \alpha) \cdot I_\textrm{green} \end{equation}\]이 loss의 좋은 속성은 원하는 효과에 대한 직관적인 supervision이 가능하다는 것이다. 모든 실험에서 화면 텍스트 템플릿에 $T$를 연결한다. Composition loss와 유사하게 CLIP에 공급하기 전에 먼저 이미지에 augmentation을 적용한다.
Structure loss
개체의 원래 공간 레이아웃, 모양 및 인식된 의미를 유지하면서 상당한 텍스처 및 모양 변경이 가능해야 한다. Style transfer의 맥락에서 다양한 perceptual content loss들이 제안되었지만 대부분은 사전 학습된 VGG 모델에서 추출된 feature를 사용한다. 대신 CLIP feature space에서 loss를 정의한다. 이를 통해 $I_o$의 내부 CLIP 표현에 추가 제약을 부과할 수 있다. 저자들은 최근 연구들에서 영감을 받아 self-similarity 측정을 채택하였다. 특히 CLIP의 ViT 인코더에 이미지를 공급하고 가장 깊은 계층에서 $K$개의 공간적 토큰들을 추출한다. $S(I) \in \mathbb{R}^{K \times K}$로 표시되는 self-similarity 행렬이 구조 표현으로 사용된다. 각 행렬 요소 $S(I)_{ij}$는 다음과 같이 정의된다.
\[\begin{equation} S(I)_{ij} = 1 - \mathcal{D}_\textrm{cos} (t^i (I), t^j (I)) \end{equation}\]여기서 $t^i (I) \in \mathbb{R}^{768}$은 이미지 $I$의 $i$번째 토큰이다.
\(\mathcal{L}_\textrm{structure}\)는 $I_s$와 $I_o$의 self-similarity 행렬 사이의 Frobenius norm distance로 정의된다.
\[\begin{equation} \mathcal{L}_\textrm{structure} = \| S(I_s) - S(I_o) \|_F \end{equation}\]Sparsity regularization
편집의 공간적 범위를 제어하기 위해 출력 불투명도 맵을 sparse하게 만드는 것이 좋다. Sparsity loss 항을 $L_1$- 및 $L_0$-근사 정규화 항의 조합으로 정의한다.
\[\begin{equation} \mathcal{L}_\textrm{reg} = \gamma \|\alpha\|_1 + \Psi_0 (\alpha) \end{equation}\]여기서 $\Psi_0(x) = 2 \textrm{Sigmoid} (5x) - 1$는 0이 아닌 요소에 페널티를 부과하는 부드러운 $L_0$ 근사이다.
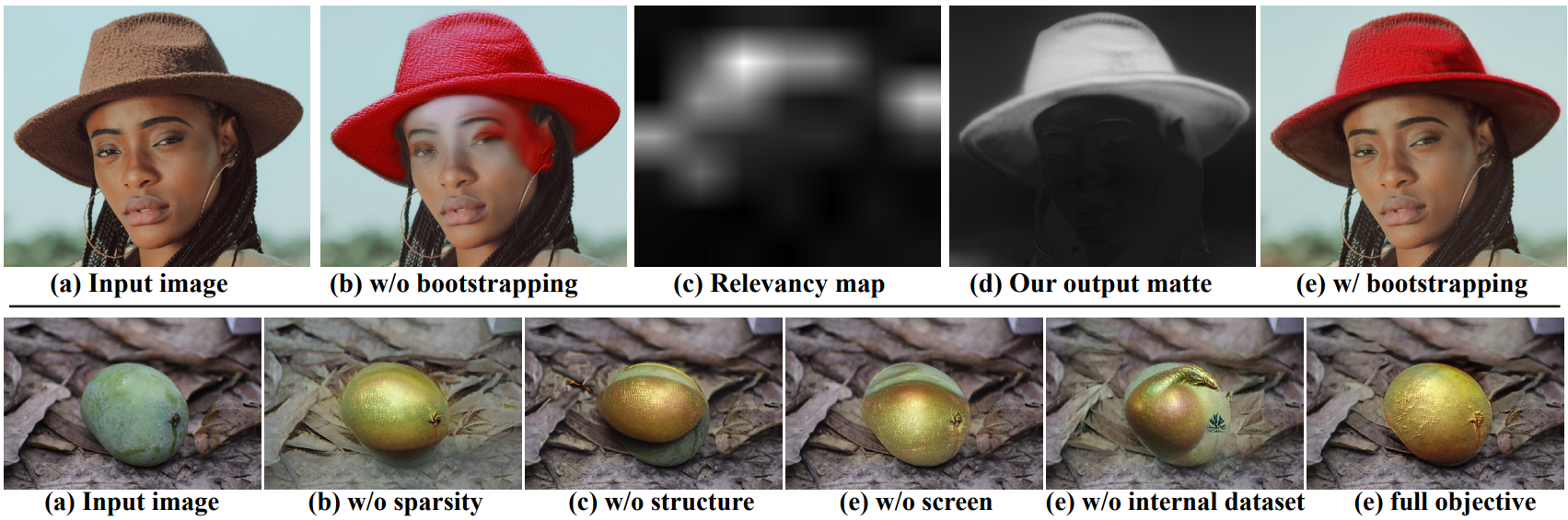
Bootstrapping
사용자가 제공한 편집 마스크 없이 정확한 localize된 효과를 얻기 위해 텍스트 기반 relevancy loss를 적용하여 불투명도 맵을 초기화한다. 주어진 텍스트 $T_\textrm{ROI}$와 가장 관련성이 높은 이미지 영역을 대략적으로 강조 표시하는 relevancy map $R(I_s) \in [0, 1]^{224 \times 224}$를 자동으로 추정한다. Relevancy map을 사용하여 다음을 최소화하여 $\alpha$를 초기화한다.
\[\begin{equation} \mathcal{L}_\textrm{init} = \textrm{MSE} (R(I_s), \alpha) \end{equation}\]Relevancy map은 noise가 많고 관심 영역에 대한 대략적인 추정만 제공한다. 따라서 학습 중에 이 loss를 annealing한다. 나머지 loss와 함께 다양한 내부 예제에 대한 학습을 통해 프레임워크는 이 대략적인 초기화를 극적으로 개선하고 정확하고 깨끗한 불투명도를 생성한다.
Training data
Generator는 입력에서 파생된 다양한 이미지-텍스트 학습 예제 내부 데이터셋 \(\{(I_s^i, T^i)\}_{i=1}^N\)을 사용하여 각 입력 $(I_s, T)$에 대해 처음부터 학습된다. 구체적으로, 각 학습 예제 $(I_s^i, T^i)$는 $I_s$와 $T$에 임의로 augmentation들을 적용하여 생성된다. 이미지 augmentation에는 global crop, color jittering, flip이 포함되며 텍스트 augmentation에는 미리 정의된 텍스트 템플릿에서 랜덤하게 샘플링된다. 이러한 augmentation 사이의 모든 조합의 광대한 space는 학습을 위한 풍부하고 다양한 데이터셋을 제공한다. 이제 해야할 것은 전체 데이터셋에 대해 하나의 매핑 함수 $G_\theta$를 학습하는 것이며, 이는 강력한 정규화를 제공한다. 특히, 각각의 개별 예제에 대해 $G_\theta$는 합성 이미지가 $T^i$에 의해 잘 설명되도록 $I_s^i$에서 그럴듯한 편집 레이어 $\mathcal{E}^i$를 생성해야 한다.
2. Text to Video Edit Layer
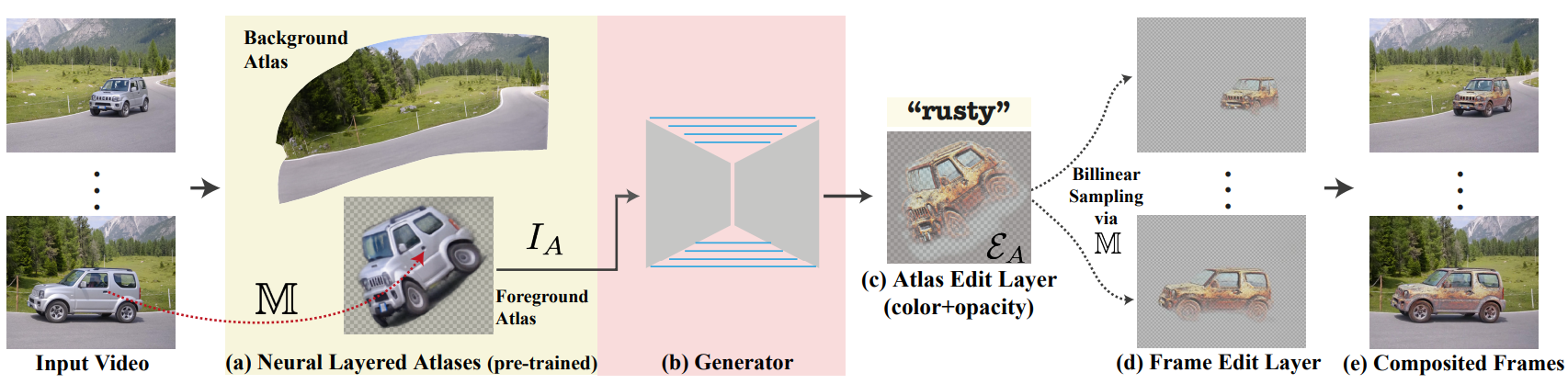
자연스러운 질문은 앞서 설명한 이미지 프레임워크를 동영상에 적용할 수 있는지 여부이다. 주요 추가 과제는 시간적으로 일관된 결과를 달성하는 것이다. 이미지 프레임워크를 각 프레임에 독립적으로 적용하는 것은 만족스럽지 못한 불안한 결과를 낳는다. 시간적 일관성을 강화하기 위해 위 그림의 (a)와 같이 Neural Layered Atlases (NLA) 방법을 사용한다.
Preliminary: Neural Layered Atlases
NLA는 동영상의 통합된 2D parameterization을 제공한다. 동영상은 2D atlas의 집합으로 분해되며, 각각은 2D 이미지로 취급될 수 있으며 전체 동영상에서 하나의 전경 개체 또는 배경을 나타낸다. 전경 및 배경 atlas의 예는 위 그림에 나와 있다. 각 동영상 위치 $p = (x, y, t)$에 대해 NLA는 각 atlas에서 해당 2D 위치(UV)와 전경 불투명도 값을 계산한다. 이를 통해 설정된 atlas에서 원본 동영상을 재구성할 수 있다. NLA는 atlas, 픽셀에서 atlas로의 매핑, 불투명도를 나타내는 여러 MLP로 구성된다. 보다 구체적으로, 각 동영상 위치 $p$는 먼저 두 개의 매핑 네트워크인 $M_b$ 및 $M_f$에 공급된다.
\[\begin{equation} M_b (p) = (u_b^p, v_b^p), \quad M_f (p) = (u_f^p, v_f^p) \end{equation}\]여기서 $(u_\ast^p, v_\ast^p)$는 베경/전경 atlas space에서 2D 좌표이다. 각 픽셀은 또한 각 위치에서 전경의 불투명도 값을 예측하는 MLP에 공급된다. 예측된 UV 좌표는 각 위치에서 RGB 색상을 출력하는 atlas 네트워크 $A$로 공급된다. 따라서 $p$의 원래 RGB 값은 $p$를 atlas에 매핑하고 해당 atlas 색상을 추출한 다음 예측된 불투명도에 따라 혼합하여 재구성할 수 있다.
중요한 것은 NLA를 사용하면 일관된 동영상 편집이 가능하다는 것이다. 연속 atlas(전경/배경)가 먼저 고정 해상도 이미지로 discretize된다. 사용자는 이미지 편집 도구(ex. Photoshop)를 사용하여 분할된 atlas를 직접 편집할 수 있다. 그런 다음 atlas 편집은 동영상에 다시 매핑되고 예측된 UV 매핑과 전경 불투명도를 사용하여 원본 프레임과 혼합된다. 본 논문은 텍스트만으로 guide되는 완전 자동 방식의 atlas 편집을 생성하는 데 관심이 있다.
Text to Atlas Edit Layer
동영상 프레임워크는 위 그림과와 같이 NLA를 “동영상 렌더러”로 활용한다. 특히 동영상에 대해 사전 학습되고 고정된 NLA 모델이 주어지면, 동영상에 다시 매핑될 때 렌더링된 각 프레임이 대상 텍스트를 준수하도록 전경 또는 배경에 대해 2D atlas 편집 레이어를 생성하는 것이 목표이다.
이미지 프레임워크와 마찬가지로 2D atlas를 입력으로 사용하고 atlas 편집 레이어 \(\mathcal{E}_A = \{C_A, \alpha_A\}\)를 생성하는 generator $G_\theta$를 학습시킨다. $G_\theta$는 CNN이므로 discretize된 atlas $I_A$로 작업한다. 사전 학습된 UV 매핑은 $\mathcal{E}_A$를 bilinear하게 샘플링하여 각 프레임에 매핑하는 데 사용된다.
\[\begin{equation} \mathcal{E}_t = \textrm{Sampler}(\mathcal{E}_A, \mathcal{S}) \end{equation}\]여기서 \(\mathcal{S} = \{M(p) \; \vert \; p = (\cdot, \cdot, t)\}\)는 프레임 $t$에 해당하는 UV 좌표들의 집합이다. 최종 편집된 동영상은 $\mathcal{E}_t$를 원본 프레임과 혼합하여 얻을 수 있다.
Training
$G_\theta$ 학습을 위한 간단한 접근 방식은 $I_A$를 이미지로 취급하여 이미지 프레임워크에 연결하는 것이다. 이 접근 방식은 시간적으로 일관된 결과를 가져오지만 두 가지 주요 단점이 있다.
- Atlas는 종종 원본 구조를 불균일하게 왜곡하여 낮은 품질의 편집으로 이어질 수 있다.
- 동영상 프레임을 무시하고 atlas를 사용하면 generator에 augmentation 역할을 할 수 있는 다양한 view나 고정되지 않은 개체 변형과 같이 동영상에서 사용할 수 있는 풍부하고 다양한 정보를 무시한다.
저자들은 atlas 편집을 동영상에 다시 매핑하고 편집된 결과 프레임에 loss를 적용하여 이러한 단점을 극복하였다. 이미지의 경우와 유사하게 동일한 목적 함수를 사용하고 학습을 위해 atlas에서 직접 내부 데이터셋을 구성한다.
보다 구체적으로, 학습 예제는 먼저 $I_A$에서 crop을 추출하여 구성된다. 유익한 atlas 영역을 샘플링하기 위해 먼저 공간과 시간 모두에서 동영상 세그먼트를 랜덤하게 자른 다음 $M$을 사용하여 해당 atlas crop $I_{Ac}$에 매핑한다. 그런 다음 $I_{Ac}$에 추가 augmentation을 적용하고 generator에 입력하여 편집 레이어 \(\mathcal{E}_{Ac} = G_\theta (I_{Ac})\)가 된다. 그런 다음 \(\mathcal{E}_{Ac}\)와 $I_{Ac}$를 동영상에 다시 매핑하여 프레임 편집 레이어 $\mathcal{E}_t$와 재구성된 전경/배경 crop $I_t$를 생성한다. 이는
\[\begin{equation} \mathcal{E}_t = \textrm{Sampler}(\mathcal{E}_{Ac}, \mathcal{S}) \end{equation}\]를 사용하여 \(\mathcal{E}_{Ac}\)와 $I_{Ac}$를 bilinear하게 샘플링하여 수행된다. $S$는 프레임 crop에 해당하는 UV 좌표 집합이다. 마지막으로 $I_s = I_t$와 $\mathcal{E} = \mathcal{E}_t$로 \(\mathcal{L}_\textrm{Text2LIVE}\)를 적용한다.
Results
1. Qualitative evaluation
다음은 입력 이미지(상단)에 Text2LIVE가 생성한 편집 레이어(중간)를 더해하여 만든 최종 이미지(하단)이다.

다음은 Text2LIVE의 이미지 편집 결과들이다.

다음은 Text2LIVE의 동영상 편집 결과들이다.

2. Comparison to Prior Work
다음은 Text2LIVE(상단)를 baseline(하단)과 비교한 것이다.

3. Quantitative evaluation
다음은 AMT (Amazon Mechanical Turk) survey 평가 결과이며, 각 baseline의 결과보다 Text2LIVE의 결과를 선호하는 비율을 나타낸 것이다.

4. Ablation Study
다음은 ablation study 결과이다.
5. Limitations

일부 편집의 경우 CLIP이 특정 솔루션에 대해 매우 강한 편향을 나타낸다. 예를 들어, 위 그림에서 볼 수 있듯이 케이크 이미지가 주어지면 “생일 케이크”라는 텍스트는 양초와 강하게 연관된다. 본 논문의 방법은 입력 이미지 레이아웃에서 크게 벗어나 새로운 객체를 생성하도록 설계되지 않았으며 비현실적인 양초를 생성한다. 그럼에도 불구하고 보다 구체적인 텍스트를 사용하면 원하는 편집을 수행할 수 있다. 예를 들어, “moon”이라는 텍스트는 초승달을 생성하도록 guide한다. “a bright full moon”이라는 텍스트를 사용함으로써 보름달을 생성하도록 guide할 수 있다. 마지막으로, 유사한 개념을 설명하는 텍스트 프롬프트가 약간 다를 경우 편집 내용이 약간 다를 수 있다.
동영상 측면에서 본 논문의 방법은 사전 학습된 NLA 모델이 원본 동영상을 정확하게 표현한다고 가정한다. 따라서 atlas 표현의 아티팩트가 편집된 동영상으로 전파될 수 있으므로 NLA가 잘 작동하는 예시로 제한된다.