[논문리뷰] Text-to-LoRA: Instant Transformer Adaption
ICML 2025. [Paper] [Github]
Rujikorn Charakorn, Edoardo Cetin, Yujin Tang, Robert Tjarko Lange
Sakana AI
6 Jun 2025
Introduction
최근 LLM은 다양한 능력과 지식을 보여주지만, 특정 task에 특화된 능력을 추가할 때는 여전히 경직되어 있다. 이러한 경우, 실무자들은 Low-Rank Adaptation (LoRA)와 같은 parameter-efficient fine-tuning 테크닉을 사용하여 모델의 일부를 재학습하는 방법을 사용한다. 일반적으로 LoRA 어댑터는 각 다운스트림 task에 맞게 최적화되어야 하며, task별 데이터셋과 hyperparameter 설정이 필요하다. 이러한 fine-tuning 방식은 task 간 지식 전달 가능성을 크게 제한하고 엔지니어링 오버헤드를 유발한다.
최근에는 구조적 제약을 유도함으로써 LoRA 어댑터가 학습한 low-rank 행렬들을 더욱 압축할 수 있다는 것이 관찰되었다. 또한, inference 시점에 여러 LoRA를 결합하여 새로운 task를 수행할 수 있다. 이러한 접근 방식의 핵심은 기존 LoRA의 압축률 향상 및 온라인 구성을 위해 분해 또는 차원 축소 기법을 명시적으로 사용하는 것이다. 이는 다음과 같은 질문을 제기한다.
여러 개의 사전 학습된 LoRA들을 압축하기 위해 신경망을 end-to-end로 학습시킬 수 있을까?
이전에 본 적 없는 task에 대해, test-time에 자연어 instruction만으로 해당 task에 특화된 LoRA 어댑터를 생성해낼 수 있을까?
저자들은 서로 다른 LoRA 어댑터가 동일한 기본 적응 메커니즘을 공유하고 이를 결합하기 위한 명시적인 구조나 레시피 없이도 동시에 최적화될 수 있다고 가설을 세웠다. 이 가설을 검증하기 위해, task별 LoRA를 압축하고 inference 시점에 새로운 LoRA 어댑터를 zero-shot으로 생성하는 hypernetwork인 T2L을 제안하였다. T2L은 Super Natural Instructions (SNI) 데이터셋의 다양한 task 분포에서 LoRA를 압축하도록 학습되었다. 중요한 점은 T2L이 타겟 task에 대한 자연어 설명을 입력으로 사용하여 처음 보는 task에 대하여 LoRA를 zero-shot으로 생성한다는 것이다.
T2L은 사전 학습된 어댑터를 reconstruction하거나 다운스트림 task 분포에서 supervised fine-tuning을 통해 효과적으로 학습될 수 있다. 학습 후, T2L은 다양한 벤치마크 task에서 multi-task LoRA 모델과 SOTA zero-shot LoRA 라우팅 방법인 Arrow Routing보다 우수한 성능을 보였다.
Method
본 논문에서는 hypernetwork를 활용하여 task별 적응을 위한 LoRA 어댑터를 생성한다. 각 타겟 모듈 $m$과 레이어 인덱스 $l$에 대해, hypernetwork는 task $t^i$의 task 설명 $z^i \in Z^i$를 기반으로 다음과 같이 두 개의 low-rank 행렬 $A$, $B$를 생성한다.
\[\begin{aligned} \Delta W_{m,l}^i = h_\theta (\phi_{m,l}^i), \quad \textrm{with} \quad \phi_{m,l}^i = \textrm{concat} [f(z^i), E[m], E[l]] \end{aligned}\]여기서 $f$는 텍스트 설명의 벡터 표현을 제공하며, 일반적으로 양방향 transformer 모델의 CLS 토큰 또는 LLM의 마지막 토큰 activation이다. $E$는 $m$ 또는 $l$로 인덱싱되는 학습 가능한 임베딩 사전이다.
$m$과 $l$의 값은 일괄 처리가 가능하므로 T2L은 한 번의 forward pass 내에서 모든 모듈과 레이어 인덱스에 대한 $\Delta W$를 효율적으로 생성할 수 있다.
1. Text-to-LoRA Architectures
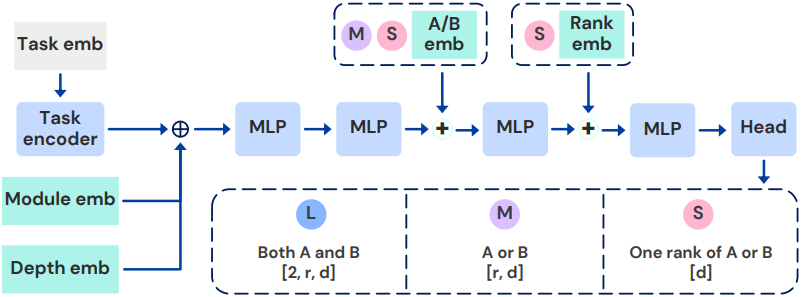
대부분의 hypernetwork 파라미터는 타겟 가중치의 크기에 따라 선형적으로 확장되는 출력 레이어에서 나온다. 저자들은 복잡도-성능 trade-off를 탐구하기 위해 T2L의 세 가지 버전인 L, M, S를 제안하였다. 다른 inductive bias와 파라미터 수를 나타내는 hypernetwork에 다른 출력 공간을 부과한다. 모든 버전이 동일한 backbone 아키텍처를 사용하고 출력 head와 학습 가능한 임베딩만 다르다.
- L: 최종 linear layer가 low-rank 행렬 $A$와 $B$를 동시에 출력하는 가장 큰 모델. \(\vert \theta_\textrm{head} \vert = d_\textrm{out} \times 2 \times r \times d\)
- M: Low-rank 행렬 $A$와 $B$ 사이에 공유 출력 레이어가 있는 중간 크기의 모델. 즉, head는 학습 가능한 임베딩에 따라 $A$ 또는 $B$ 중 하나를 출력. \(\vert \theta_\textrm{head} \vert = d_\textrm{out} \times r \times d\)
- S: 한 번에 low-rank 행렬의 한 rank만 출력하는 가장 inductive bias가 강한 가장 작은 모델. \(\vert \theta_\textrm{head} \vert = d_\textrm{emb} \times d\)
LoRA 어댑터는 $r \times d \times 2 \times L \times \vert M \vert$개의 학습 가능한 파라미터를 가지며, 여기서 $L$은 레이어 수이고 $\vert M \vert$은 타겟 모듈 수이다. 모든 아키텍처는 모든 입력 임베딩을 batch로 만들어 한 번의 forward pass로 모든 low-rank 행렬 $A$와 $B$를 생성할 수 있다.
2. Training Text-to-LoRA via LoRA Reconstruction
T2L을 학습시키는 가장 간단한 방법은 사전 학습된 task별 LoRA를 reconstruction하는 것이다. 이 설정을 통해 공개적으로 사용 가능한 LoRA 라이브러리를 활용할 수 있다. 또는, LoRA 라이브러리를 먼저 사전 학습시킨 다음 T2L을 학습시켜 reconstruction하는 2단계 절차를 사용할 수도 있다.
One-hot 벡터 또는 학습 가능한 벡터를 task 임베딩으로 사용하여 T2L을 학습시킬 수 있다. 그러나 이러한 임베딩은 처음 보는 task에 적용할 수 없다. Zero-shot LoRA 생성을 가능하게 하기 위해, 자연어 task 설명의 임베딩으로 T2L을 추가로 컨디셔닝한다. 이를 통해 T2L은 해당 task 설명을 기반으로 처음 보는 task를 포함한 다양한 task에 대한 LoRA 어댑터를 생성할 수 있다. 적절한 LoRA 어댑터 라이브러리 $\Omega$가 주어졌을 때, T2L의 reconstruction loss는 다음과 같다.
\[\begin{equation} \mathcal{L} (\Omega, \theta) = \mathbb{E}_{\Delta W^i \sim \Omega} \vert \Delta W^i - h_\theta (\phi^i) \vert \end{equation}\]3. Training Text-to-LoRA via Supervised Fine-Tuning
또는, T2L을 fine-tuning 데이터셋에서 직접 최적화할 수 있다. Supervised fine-tuning (SFT)으로 T2L을 학습시키면 타겟 LoRA 어댑터가 필요 없고 end-to-end 학습이 가능하다. 이 학습 방식은 기존에 학습된 LoRA가 기능이나 다운스트림 task에 의해 자연스럽게 클러스터링되지 않은 경우에 더 좋다.
예를 들어, task $t^1$과 $t^2$이 유사한 LLM 능력이 필요할 수 있지만 $\Delta W^1$과 $\Delta W^2$는 다를 수 있다. 따라서 reconstruction을 통해 학습된 T2L은 다른 $\Delta W^1$과 $\Delta W^2$를 압축해야 하므로 일반화 가능성이 낮다. 실제로 reconstruction을 통해 학습된 T2L은 처음 보는 task로 일반화하지 못한다. 반면, SFT로 학습된 T2L은 task를 클러스터링하는 것을 암시적으로 학습할 수 있으며, 이는 zero-shot LoRA 라우팅 성능을 향상시킨다.
T2L의 SFT loss는 다음과 같다.
\[\begin{equation} \theta = \underset{\theta}{\arg \min} \mathbb{E}_{\mathcal{D}^i \sim \mathcal{D}, z^i \sim Z^i} \mathcal{L}_\textrm{SFT} (\mathcal{D}^i, \Psi, h_\theta (\phi^i)) \end{equation}\]Experiments
- 구현 디테일
- Base LLM model: Mistral-7B-Instruct
- 텍스트 임베딩 모델: gte-large-en-v1.5
- LoRA rank: $r = 8$
- LoRA는 모든 attention block의 query/value projection 모듈에만 적용
- 학습 가능한 파라미터 수: L은 55M, M은 34M, S는 5M
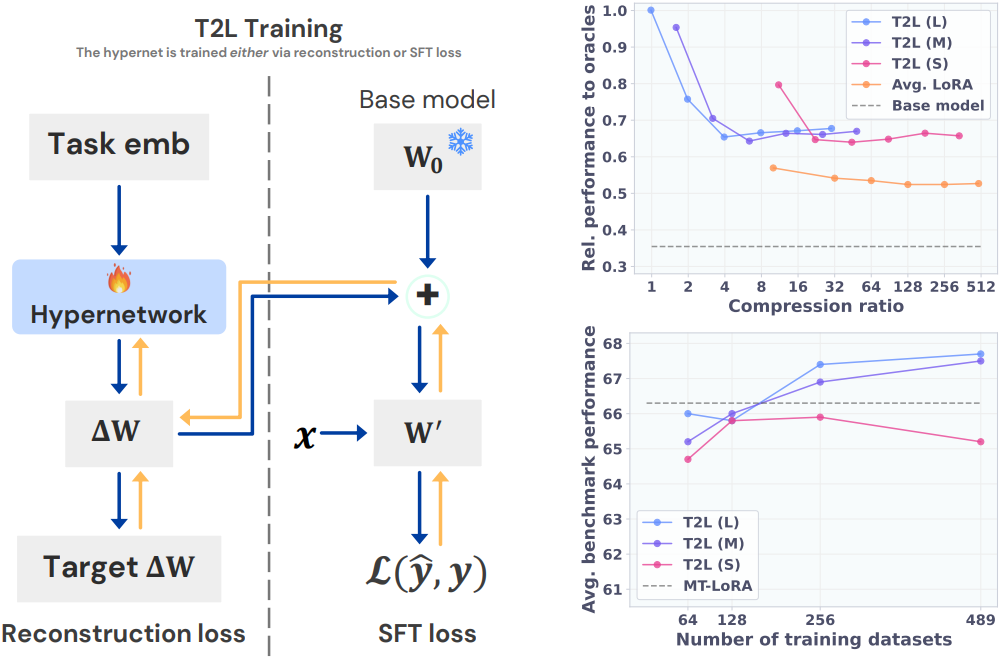
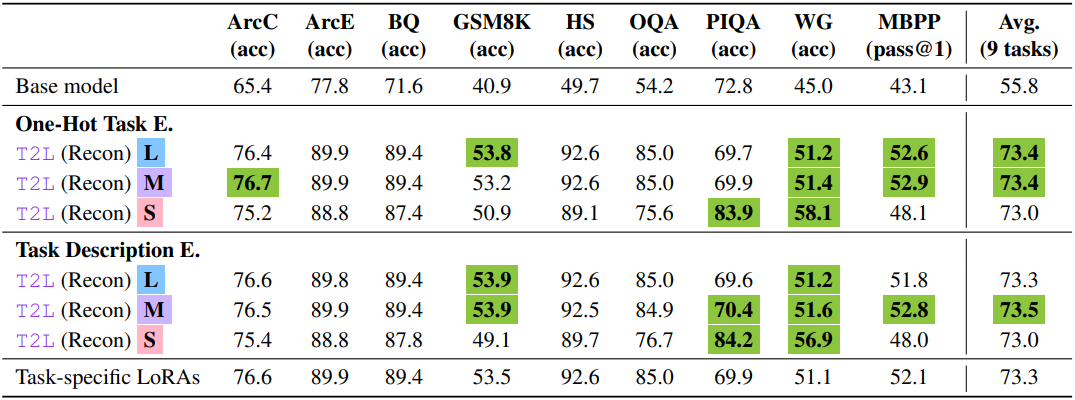
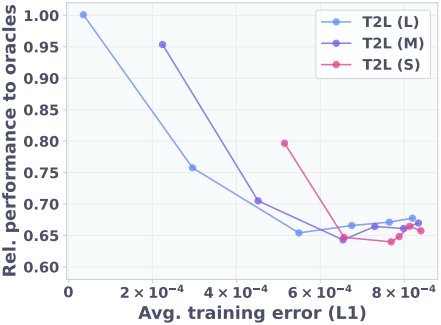
1. LoRA Compression
다음은 reconstruction을 통해 학습된 T2L에 대한 성능을 비교한 결과이다.
2. Zero-Shot LoRA Generation
다음은 처음 보는 task에 대한 zero-shot 성능을 비교한 결과이다.
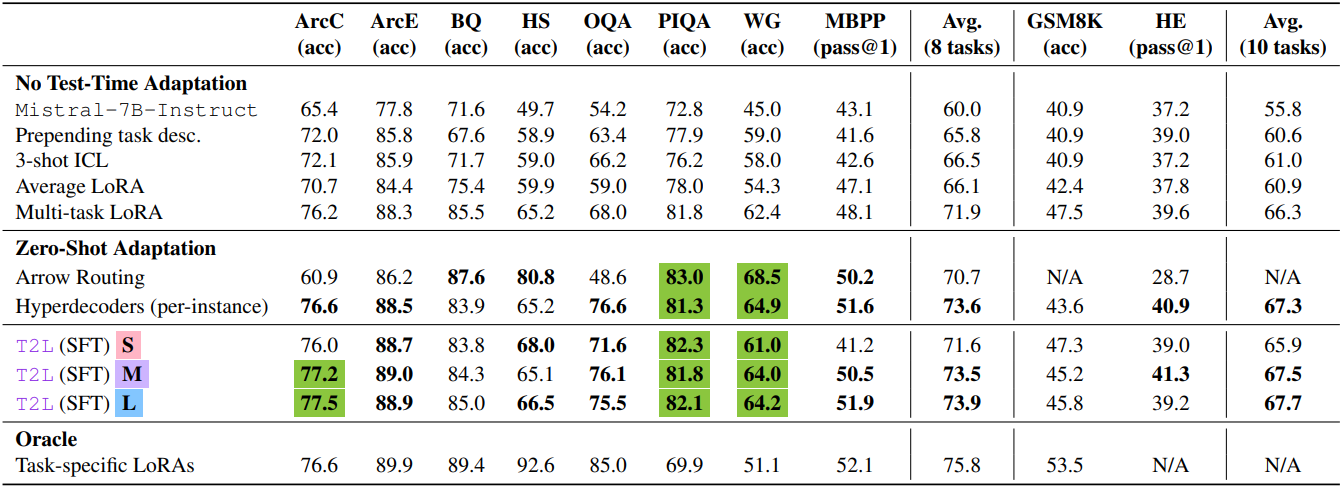
3. Ablations and Analyses
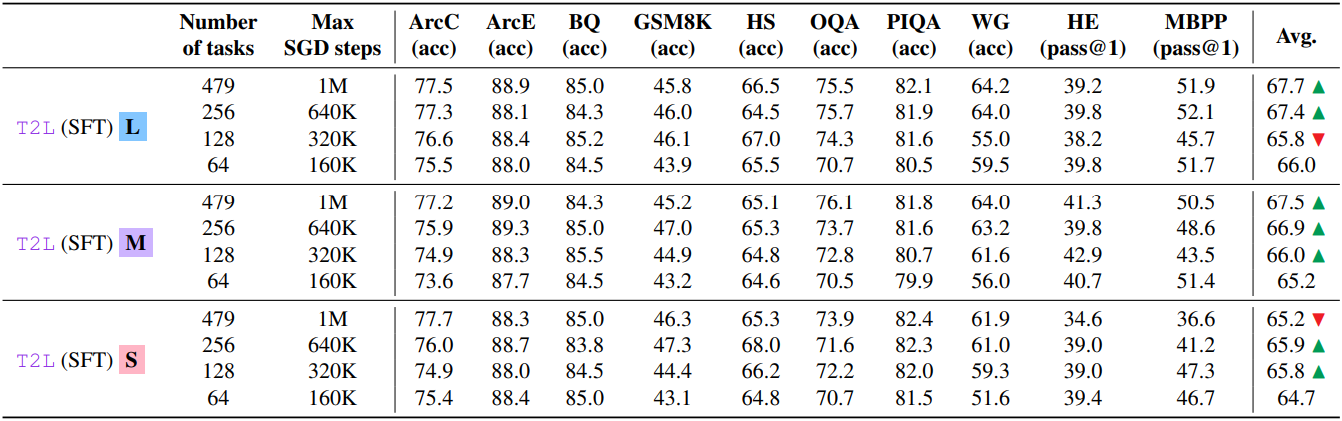
다음은 학습한 task 수에 대한 성능을 비교한 결과이다.
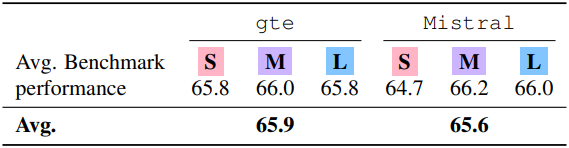
다음은 텍스트 임베딩 모델에 따른 성능을 비교한 결과이다.
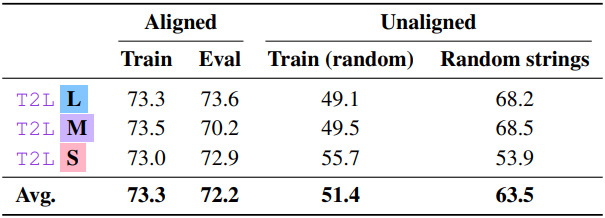
다음은 task 설명에 따른 성능을 비교한 결과이다.
- Train: 해당 task에 대한 학습 설명
- Eval: 해당 task에 대한 처음 보는 설명
- Random strings: 무작위의 문자열
- Train (random): 다른 task에 대하여 랜덤하게 샘플링한 학습 설명
다음은 T2L이 생성한 LoRA를 적용한 예시들이다.

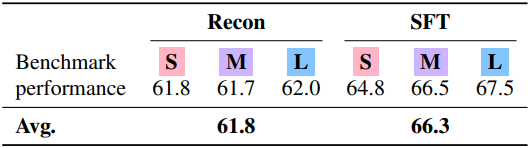
다음은 reconstruction 방식과 SFT 방식을 비교한 결과이다.
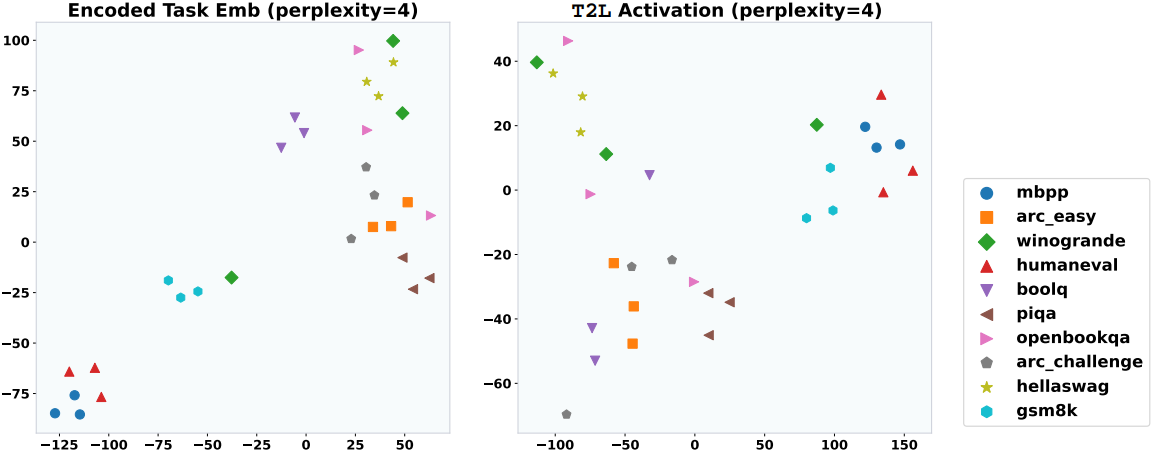
다음은 (왼쪽) task 인코더의 activation과 (오른쪽) 마지막 MLP block의 activation에 대한 2D t-SNE projection이다.
Limitations
- LoRA를 hypernetwork의 출력 공간으로만 고려하였다.
- T2L이 달성한 압축은 잘 설계된 inductive bias를 사용하여 더욱 최적화될 수 있다.
- T2L은 여전히 task-specific LoRA의 벤치마크 성능에 도달하지 못한다.