[논문리뷰] Text Embedding is Not All You Need: Attention Control for Text-to-Image Semantic Alignment with Text Self-Attention Maps
CVPR 2025. [Paper]
Jeeyung Kim, Erfan Esmaeili, Qiang Qiu
Purdue University
21 Nov 2024
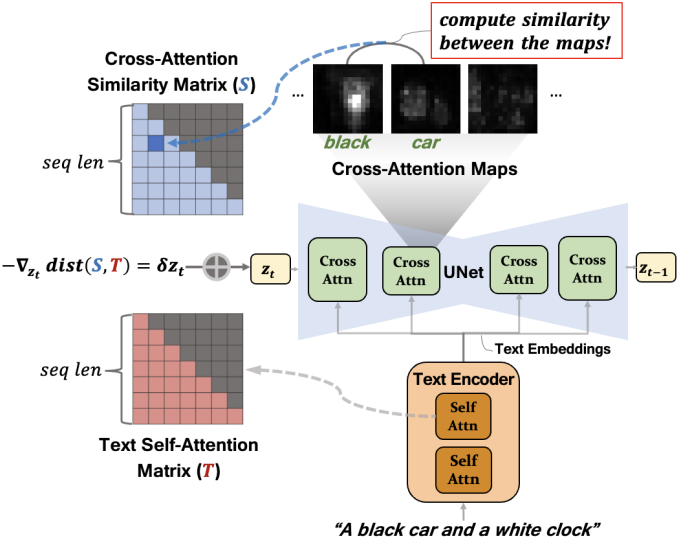
Introduction
Text-to-image (T2I) diffusion model에서 각 토큰의 cross-attention map은 이미지에서 attention이 집중된 영역을 강조하고 토큰에 해당하는 요소의 공간적 배치에 대한 단서를 제공한다. 특히, 관련 단어 간 cross-attention map의 공간적 정렬이 텍스트 프롬프트에 대한 이미지의 충실도에 영향을 미친다.
예를 들어, a black car and a white clock이라는 프롬프트에서 car와 clock에 대한 cross-attention map이 과도하게 겹치면 고유한 토큰 기여도가 희석되어 하나의 물체가 누락될 수 있다. 반대로, black과 car, 또는 white와 clock에 대한 cross-attention map이 너무 많이 갈라지면 속성 오결합이 발생할 수 있다. 이는 구문적으로 관련된 단어가 이상적으로 공간적으로 정렬된 cross-attention map을 가져야 함을 의미한다. 그러나 cross-attention map 간의 이러한 공간적 정렬을 결정하는 요인은 아직 밝혀지지 않았다.
본 논문에서는 먼저 서로 다른 토큰 간 cross-attention map의 공간적 정렬에 기여하는 요인들을 조사했다. 조사 결과, cross-attention 모듈의 key 역할을 하는 텍스트 임베딩은 이러한 cross-attention map의 유사성을 결정하는 데 중추적인 역할을 한다. 구체적으로, 서로 다른 단어에 대한 텍스트 임베딩이 더 유사해질수록 해당 cross-attention map의 코사인 유사도가 증가한다. 이러한 효과는 초기 denoising step에서 두드러진다.
Cross-attention map이 단어 간의 구문적 관계를 포착해야 하고, cross-attention map의 공간적 정렬은 텍스트 임베딩의 영향을 받는다는 점을 고려할 때, 저자들은 텍스트 임베딩이 텍스트 프롬프트의 언어적 구조를 정확하게 포착하는지 의문을 제기하였다. 본 논문의 결과는 그렇지 않다는 것을 시사한다. 프롬프트에서 구문적으로 관련된 단어 (ex. 검은색-자동차 및 하얀색-시계)는 반드시 유사한 텍스트 임베딩을 생성하지 않는다. 결과적으로, 텍스트 임베딩에서 파생된 cross-attention map은 구문적 관계를 충실하게 반영하지 못할 가능성이 높다. 결국, T2I diffusion model은 프롬프트를 부정확하게 표현하는 이미지를 생성하는 경우가 많다.
위의 문제를 해결하기 위해 기존 연구들은 텍스트 프롬프트 내의 구문 정보를 얻기 위해 외부 소스를 활용하고, 이러한 관계를 통합하기 위해 cross-attention map을 정규화했다. 그러나 이러한 방법은 텍스트 파서나 인간의 개입이 필요하며 외부 입력에 의존한다는 한계가 있다.
놀랍게도 T2I diffusion model은 텍스트 인코더의 self-attention map을 통해 프롬프트 내 구문 관계를 본질적으로 포착한다. 인코더의 self-attention 모듈에서 각 토큰은 구문적으로 관련 단어에 더 높은 attention score를 출력해 전체 문장을 효과적으로 인코딩한다. 그러나 이 정보는 텍스트 인코더 출력, 즉 텍스트 임베딩에 약하게 인코딩되어 있다. 이는 텍스트 attention 모듈이 <bos> 토큰에 집중하여 다른 토큰의 영향을 최소화하기 때문이다. 이를 attention sink라고 부른다.
본 논문은 텍스트 인코더의 self-attention map을 재사용하고 구문 정보를 diffusion model에 직접 전달하였다. 먼저, cross-attention map 쌍 간의 유사도를 나타내는 값을 갖는 유사도 행렬을 정의한다. 그런 다음, inference 과정에서 cross-attention 유사도 행렬과 텍스트 self-attention 행렬 간의 거리를 최소화하기 위해 diffusion model의 latent noise를 업데이트한다. 이를 통해 구문 관계를 diffusion process에 원활하게 통합할 수 있다. Cross-attention 모듈이 맥락적 관계를 더 잘 포착하도록 유도함으로써, 본 접근법은 궁극적으로 프롬프트의 의도된 의미를 정확하게 반영하는 이미지를 생성한다.
본 논문의 방법은 T2I 모델에 이미 내장된 간과된 정보를 활용하여 두 가지 주요 이점을 제공한다.
- 텍스트 파서나 수동 토큰 인덱스와 같은 외부 입력이 필요하지 않다.
- 다양한 문장 구조에서 효과적이다.
Preliminaries
텍스트 인코더
텍스트 인코더의 layer $\ell$에서 key를 $e_i^{(\ell)} \in \mathbb{R}^{H_e D_e}$라 하자 ($i = 1, \cdots, s$). 여기서 $s$는 key 시퀀스 길이, $D_e$는 head당 임베딩 차원, $H_e$는 텍스트 인코더의 head 수이다. 이 때, self-attention 행렬 $T^{(\ell, h)} \in \mathbb{R}^{s \times s}$는 다음과 같다.
\[\begin{equation} T_{ij}^{(\ell, h)} = \frac{\exp (\omega_{ij})}{\sum_k \exp (\omega_{ik})}, \quad \omega_{ij} = e_i^{(\ell) \top} W_\textrm{en}^{(\ell, h)} e_j^{(\ell)} \end{equation}\]본 논문에서는 layer와 head에 대해 평균화된 self-attention 행렬을 사용한다.
\[\begin{equation} T^\prime = \frac{1}{L_e H_e} \sum_{\ell = 1}^{L_e} \sum_{h=1}^{H_e} T^{(\ell, h)} \end{equation}\]<bos> 토큰과 <eos> 토큰에 할당된 높은 attention 확률로 인해 해당 값을 제거하고 각 행을 다음과 같이 재정규화한다.
텍스트 인코더의 최종 출력 $k_i \in \mathbb{R}^{H_e D_e}$ ($i = 1, \cdots, s$)는 T2I diffusion model 모델의 조건 입력으로 사용된다. $k_i$를 텍스트 임베딩이라고 부른다.
Cross-attention 모듈
Cross-attention layer $\ell$에서, query를 \(q_a^{(\ell)} \in \mathbb{R}^{H_c D_c}\)로 정의하자 ($a = 1, \cdots, N_c$). 여기서 $N_c$는 query 시퀀스 길이, $D_c$는 head당 hidden dimension, $H_c$는 cross-attention layer의 head 수이다. Head $h$에서 cross-attention map \(A^{(\ell, h)} \in \mathbb{R}^{N_c \times s}\)는 다음과 같이 정의된다.
\[\begin{equation} A_{ai}^{(\ell, h)} = \frac{\exp (\Omega_{ai})}{\sum_{j=1}^s \exp (\Omega_{aj})}, \; \Omega_{ai} = q_a^{(\ell) \top} W_c^{(\ell, h)} k_i^{(\ell)} \end{equation}\]Cross-attention 유사도 행렬
본 논문에서는 $N_c = M$인 모든 layer와 head에 대해 평균화된 cross-attention map을 사용한다.
\[\begin{equation} A = \frac{1}{L_M H_c} \sum_{\ell = 1}^{L_M} \sum_{h=1}^{H_c} A^{(\ell, h)} \end{equation}\]($L_M$은 $N_c = M$인 cross-attention layer의 수)
위의 평균 cross-attention map을 기반으로 유사도 행렬 $S \in \mathbb{R}^{s \times s}$를 다음과 같이 정의한다.
\[\begin{equation} S_{ij} = \frac{C_{ij}}{\sum_{k=1}^s C_{ik}}, \; C_{ij} = \frac{\sum_{a=1}^{N_c} A_{ai} A_{aj}}{(\sum_{a=1}^{N_c} A_{ai}^2)^{\frac{1}{2}} (\sum_{a=1}^{N_c} A_{aj}^2 )^{\frac{1}{2}}} \end{equation}\]Method
1. Why Do Generated Images Misrepresent Text?
정확한 T2I 생성을 위해서는 cross-attention map이 단어 간의 구문적 관계를 포착해야 한다. 텍스트 임베딩 $k_i$의 유사도는 cross-attention 유사도 행렬 $C$와 강력하게 상관관계가 있지만, 텍스트 프롬프트의 구문적 결합을 충분히 반영하지 못한다. 즉, 텍스트 임베딩의 유사도는 정확한 이미지 생성에 필요한 구문 정보가 부족하다. 텍스트 self-attention map $T$는 구문 정보를 효과적으로 포착하지만, 텍스트 임베딩에 충분히 인코딩되지 않는다. 텍스트 임베딩에 정보가 없는 것은 attention 모듈의 attention sink, 즉 attention 가중치가 <bos> 토큰에 편향되기 때문일 수 있다.
저자들은 분석을 위해 다음 세 가지 카테고리로 구성된 프롬프트를 포함하는 프롬프트 세트를 사용하였다.
- [attribute₁][object₁] and [attribute₂][object₂]
- [object₁(animal)] with [object₂]
- [object₁(animal)] and [attribute₂][object₂]
위 형식의 프롬프트 세트를 통해 텍스트와 이미지의 의미적 불일치의 두 가지 주요 사례, 즉 누락된 물체와 속성의 잘못된 연결에 집중할 수 있다.

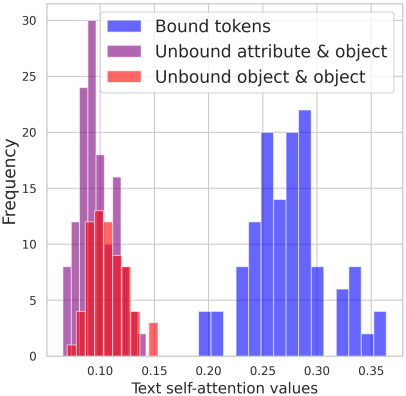
Cross-attention map에서는 공간적 중첩이나 분리가 매우 중요하다. 위 그림은 이러한 효과를 보여준다. 구문적으로 연결되지 않은 단어에 대한 attention map의 중첩은 물체를 누락시키는 반면, 구문적으로 연결된 단어에 대한 중첩이 더 커지면 속성 결합이 강화된다. 이는 구문적 연관성이 cross-attention map에 반영되어야 함을 시사한다.
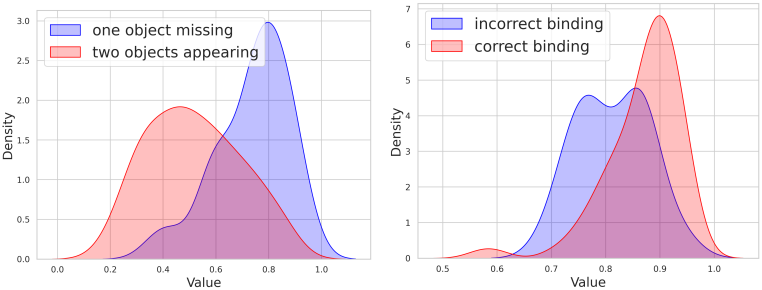
저자들은 cross-attention map의 영향을 통계적으로 평가하기 위해, 프롬프트 세트의 카테고리 2와 3을 분석하였다. 공간적 중첩은 코사인 유사도 행렬 $C$로 측정 가능하다고 가정하고, 누락된 물체의 경우 object₁과 object₂의 attention map에 대해, 그리고 속성 결합의 경우 attribute₂와 object₂의 attention map에 대해 코사인 유사도를 계산한다. 그런 다음, 두 경우 모두에서 올바른 이미지와 잘못된 이미지의 코사인 유사도 분포를 비교한다. 위 그림에서 볼 수 있듯이, 코사인 유사도가 낮을수록 물체 존재와 상관관계가 있는 반면, 유사도가 높을수록 더 정확한 결합을 지원하는 경향이 있다.
이러한 관찰은 토큰 간 cross-attention map의 유사성에 기여하는 요인을 조사하는 데 동기를 부여하였다.
발견 1: 텍스트 임베딩의 코사인 유사도는 cross-attention 유사도 행렬 $C$와 높은 상관관계를 보인다.
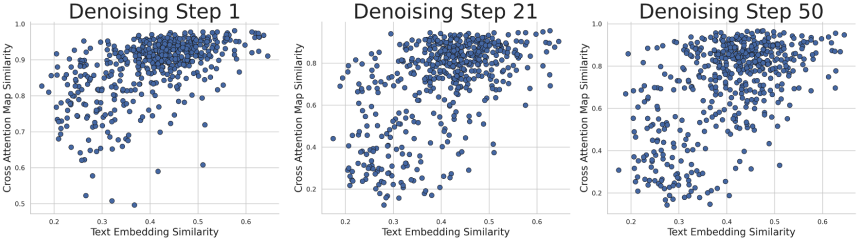
위 그림은 텍스트 임베딩의 코사인 유사도와 $C$ 사이에 상관관계가 있으며, 최종 denoising step 전체에서 지속됨을 보여준다. 이는 유사한 텍스트 임베딩으로 인해 cross-attention map이 겹칠 수 있음을 시사한다.
발견 2-1: 단어의 구문적 결합과 텍스트 임베딩 유사성 간에는 유의미한 상관관계가 없다.
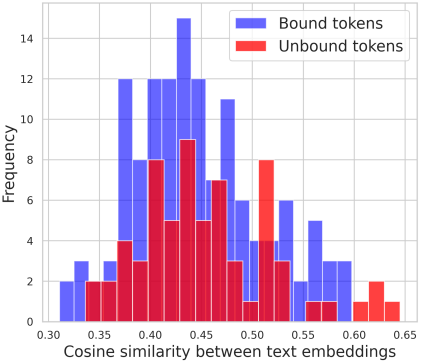
Stable Diffusion에 사용되는 CLIP 임베딩은 단어 관계를 무시하는 Bag-of-Words 모델처럼 동작한다. 또한 위 그림에서 볼 수 있듯이, CLIP 텍스트 임베딩의 유사성이 구문적 결합과 상관관계가 없다. 구문적으로 결합된 토큰의 경우 가까운 임베딩을, 결합되지 않은 토큰의 경우 먼 임베딩을 예상했지만, 분포가 분리되지 않았다.
발견 2-2: 텍스트 self-attention map에는 구문 정보가 있다.
위 그림과 같이 텍스트 임베딩을 생성하는 텍스트 인코더의 self-attention map은 구문 관계를 포착한다. Self-attention map은 구문적으로 바인딩된 토큰 간의 유사도가 높고, 바인딩되지 않은 토큰 간의 유사도가 낮음을 보여준다.
발견 2-3: Attention sink는 텍스트 임베딩에 구문 정보가 부족한 이유에 기여할 수 있다.
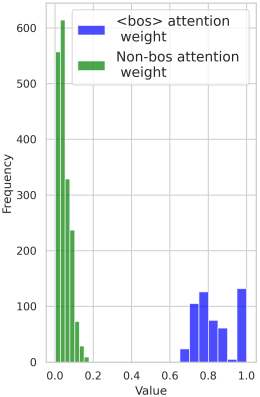
텍스트 임베딩이 여러 self-attention 모듈에서 파생되었음에도 불구하고 관계 정보가 부족한 이유는 attention score가 소수의 토큰에 집중되는 attention sink 때문이다. 위 그림에서 볼 수 있듯이, CLIP의 텍스트 인코더에서 attention은 주로 <bos> 토큰에 집중된다. <bos> 토큰에 초점을 맞추면 self-attention map $T$에서 텍스트 임베딩으로의 관계적 정보 전송이 제한될 수 있다. 다른 토큰에 대한 attention score는 훨씬 작아서 각 self-attention layer에서 영향이 최소화되기 때문이다.
잠재적으로 cross-attention map에 영향을 미칠 수 있는 토큰 벡터 간의 코사인 유사도가 <bos> 토큰의 attention sink로 인해 텍스트 self-attention layer 전반에서 거의 변하지 않는다. 즉, attention sink는 self-attention map을 임베딩에 정확하게 인코딩하는 데 방해가 될 수 있다.
텍스트 임베딩만으로는 의미적으로 정렬된 이미지를 생성하는 데 충분하지 않다. 반면, 텍스트 self-attention map에서 간과되었던 구문 정보를 cross-attention map으로 전달하여 T2I 의미적 정렬을 향상시킬 수 있는 잠재력이 있다.
2. Text Self-Attention Maps (T-SAM) Guidance
본 논문에서는 텍스트 인코더 내의 self-attention map을 활용하여 cross-attention map을 향상시키는 방안을 제안하였다. Cross-attention map의 유사도 행렬과 텍스트 self-attention 행렬 간의 거리를 최소화함으로써, 임베딩된 구문 관계가 cross-attention로 효과적으로 전달되도록 보장한다.
Inference 과정에서 cross-attention map을 최적화하고, 유사도 행렬을 조정하여 텍스트 self-attention 행렬 $T$에 맞춘다. 정규화된 코사인 유사도 행렬 $S$가 cross-attention 유사도 행렬로 사용된다. Loss function은 다음과 같다.
\[\begin{equation} \mathcal{L}(z_t) = \sum_{i=1, j \le i}^s \frac{i}{s} \vert T_{ij}^\gamma - S_{ij} (z_t) \vert \end{equation}\]프롬프트에 있는 두 단어가 텍스트 self-attention 행렬에 따라 무시할 수 있는 수준의 구문적 관계를 갖는 경우 (\(T_{ij} \approx 0\)), 두 단어의 cross-attention map 유사도는 서로 유사하지 않아야 한다 (\(S_{ij} \approx 0\)). 지수 $\gamma$는 큰 값은 증폭하고 작은 값은 압축하는 역할을 하므로 temperature 제어 효과를 낸다.
실제로 이 최적화는 다음과 같이 inference 중 몇 개의 denoising step에서만 $z_t$에 적용된다.
\[\begin{equation} z_t^\prime = z_t - \alpha \cdot \nabla_{z_t} \mathcal{L} (z_t) \end{equation}\]Experiments
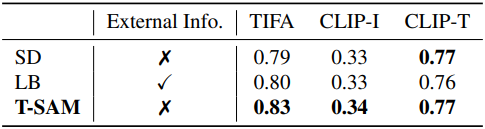
다음은 TIFA 벤치마크에서의 평가 결과이다.
다음은 TIFA 벤치마크에서 질문 유형에 따른 정확도를 비교한 그래프이다.

다음은 CLIP 유사도 점수를 비교한 표이다.
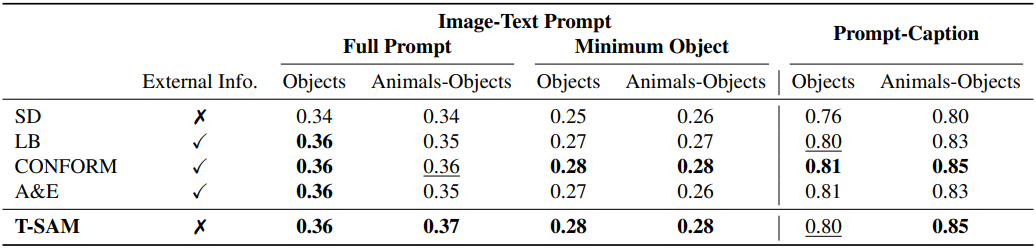
다음은 TIFA 벤치마크에 포함된 MSCOCO의 프롬프트를 사용한 비교 결과이다.

다음은 최신 SOTA 방법들과의 비교 결과이다.
