[논문리뷰] T2I-Adapter: Learning Adapters to Dig out More Controllable Ability for Text-to-Image Diffusion Models
arXiv 2023. [Paper] [Github]
Chong Mou, Xintao Wang, Liangbin Xie, Yanze Wu, Jian Zhang, Zhongang Qi, Ying Shan, Xiaohu Qie
Peking University Shenzhen Graduate School | ARC Lab, Tencent PCG | University of Macau | Shenzhen Institute of Advanced Technology
16 Feb 2023

Introduction
방대한 데이터와 엄청난 컴퓨팅 파워에 대한 학습 덕분에 주어진 텍스트/프롬프트 조건으로 이미지를 생성하는 것을 목표로 하는 T2I (text-to-image) 생성이 강력한 생성 능력을 입증했다. 생성 결과는 일반적으로 풍부한 텍스처, 명확한 가장자리, 합리적인 구조, 의미 있는 semantic을 갖는다. 이 현상은 잠재적으로 T2I 모델이 낮은 수준 (ex. 텍스처), 중간 수준 (ex. 가장자리)에서 높은 수준 (ex. semantic)에 이르기까지 다양한 수준의 정보를 암시적으로 잘 캡처할 수 있음을 나타낸다.
본 논문에서는 T2I 모델이 암시적으로 학습한 능력, 특히 상위 수준 구조와 semantic 능력을 어떻게든 “발굴”한 다음 이를 명시적으로 사용하여 생성을 보다 정확하게 제어할 수 있는지를 연구하였다.
저자들은 소형 어댑터 모델이 새로운 생성 능력을 학습하는 것이 아니라 제어 정보에서 T2I 모델의 내부 지식으로의 매핑을 학습하기 때문에 이러한 목적을 달성할 수 있다고 생각하였다. 즉, 여기서 주요 문제는 “정렬” 문제, 즉 내부 지식과 외부 제어 신호가 일치하여야 한다는 것이다.
따라서 본 논문은 상대적으로 적은 양의 데이터로 이러한 정렬을 학습하는 데 사용할 수 있는 경량 모델인 T2I-Adapter를 제안한다. T2I-Adapter는 사전 학습된 T2I diffusion model (즉, Stable Diffusion (SD))에 추가 guidance를 제공한다. 이러한 방식으로 서로 다른 조건에 따라 다양한 어댑터를 학습할 수 있으며 사전 학습된 T2I 모델에 대해 보다 정확하고 제어 가능한 생성 guidance를 제공할 수 있다. 아래 그림 2에서 볼 수 있듯이 guidance 정보를 주입하기 위한 추가 네트워크인 T2I-Adapter는 다음과 같은 실질적인 가치가 있다.
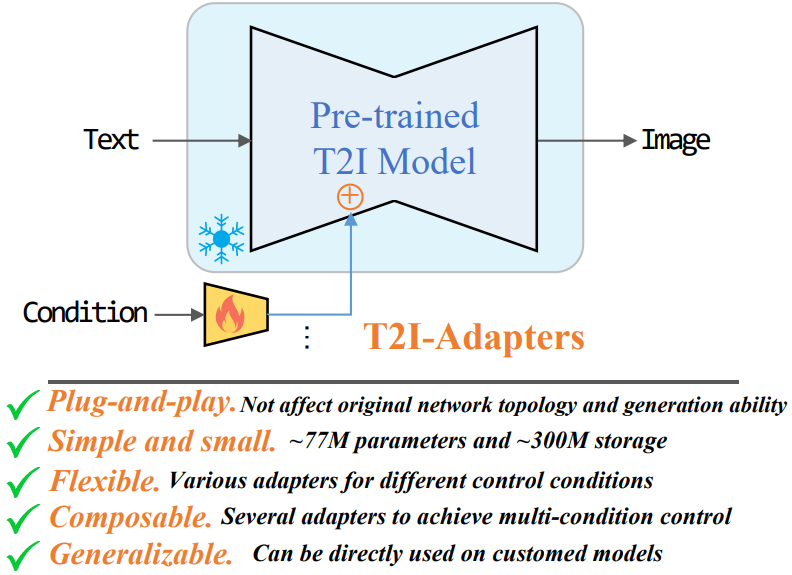
- Plug-and-play: 기존 T2I diffusion model (즉, SD)의 원래 네트워크 토폴로지와 생성 능력에 영향을 미치지 않는다.
- 간단하고 작다: 낮은 학습 비용으로 기존 T2I diffusion model에 쉽게 삽입할 수 있으며 diffusion process에서 한 번의 inference만 필요하다. 또한 파라미터 수가 적고 저장 공간이 작다.
- 유연하다: 공간적 색상 제어와 정교한 구조 제어를 포함하여 다양한 제어 조건에 대해 다양한 어댑터를 학습할 수 있다.
- 결합 가능하다: 여러 조건 제어를 위해 하나 이상의 어댑터를 쉽게 결합할 수 있다.
- 일반화 가능하다: 일단 학습되면 동일한 T2I 모델에서 fine-tuning되는 한 커스텀 모델에서 직접 사용할 수 있다.
Method
1. Overview of T2I-Adapter

위 그림의 첫 번째 행에서 볼 수 있듯이 텍스트는 이미지 합성에 대한 구조적 guidance를 거의 제공하지 못하여 일부 복잡한 시나리오에서 무작위적이고 불안정한 결과를 초래한다. 이는 생성 능력이 부족해서가 아니라 SD의 내부 지식과 외부 제어를 완전히 일치시키기 위한 정확한 생성 지침을 텍스트가 제공할 수 없기 때문이다. 저자들은 이러한 정렬이 저렴한 비용으로 쉽게 학습될 수 있다고 믿는다.
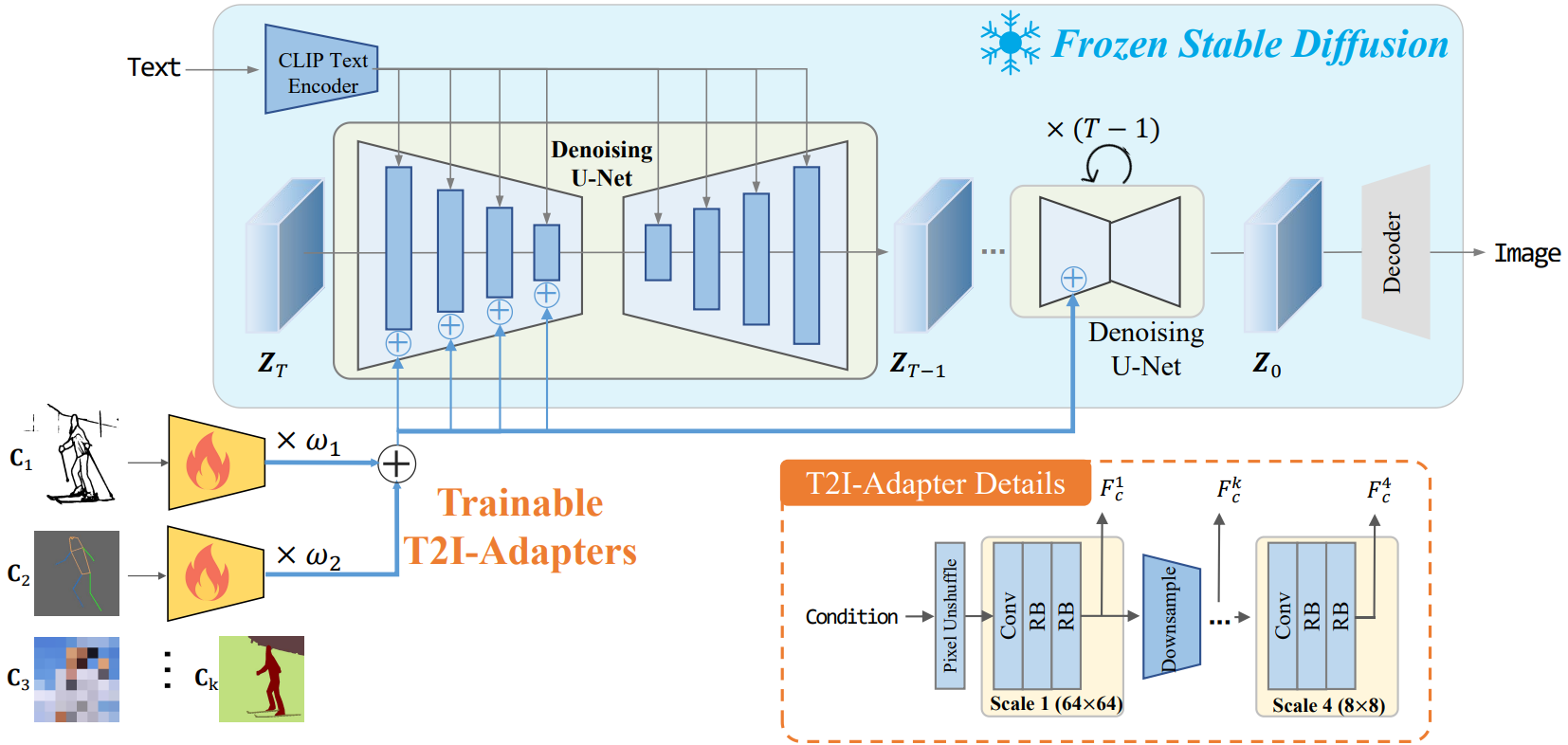
본 논문의 방법의 개요는 사전 학습된 SD 모델과 여러 T2I-Adapter로 구성된 위 그림에 나와 있다. 어댑터는 다양한 유형의 조건에서 guidance feature를 추출하는 데 사용된다. 사전 학습된 SD에는 입력 텍스트 feature와 추가 guidance feature를 기반으로 이미지를 생성하는 고정 파라미터가 있다.
2. Adapter Design
본 논문이 제안한 T2I-Adapter는 간단하고 가볍다. 4개의 feature 추출 블록과 3개의 다운샘플링 블록으로 구성되어 feature 해상도를 변경한다. 원래 조건 입력의 해상도는 512$\times$512이다. 여기서는 pixel unshuffle 연산을 사용하여 64$\times$64로 다운샘플링한다. 각 스케일에서 하나의 convolution layer와 두 개의 residual block (RB)을 사용하여 조건 feature $F_c^k$를 추출한다. 마지막으로, 멀티스케일 조건 feature \(F_c = \{F_c^1, F_c^2, F_c^3, F_c^4\}\)가 형성된다. $F_c$의 차원은 UNet denoiser의 인코더에서 중간 feature \(F_\textrm{enc} = \{F_\textrm{enc}^1, F_\textrm{enc}^2, F_\textrm{enc}^3, F_\textrm{enc}^4\}\)와 동일하다. 그런 다음 $F_c$는 각 스케일에서 $F_\textrm{enc}$와 더해진다. 요약하면 조건 feature 추출과 조건 연산은 다음 공식으로 정의할 수 있다.
\[\begin{aligned} & F_c = \mathcal{F}_\textrm{AD} (C)\\ & \hat{F}_\textrm{enc}^i = F_\textrm{enc}^i + F_c^i, \quad i \in \{1,2,3,4\} \end{aligned}\]여기서 $C$는 조건 입력이고, \(\mathcal{F}_\textrm{AD}\)는 T2I-Adapter이다.
구조 제어
T2I-Adapter는 스케치, 깊이 맵, semantic segmentation map, keypose를 포함한 다양한 구조 제어를 지원하는 좋은 일반화를 가지고 있다. 이러한 모드의 조건 맵은 task별 어댑터에 직접 입력되어 조건 feature $F_c$를 추출한다.
공간적 색상 팔레트
색상은 구조 외에도 이미지의 기본 구성 요소이며 주로 색조(hue)와 공간 분포라는 두 가지 측면을 포함한다. 본 논문에서는 생성된 이미지의 색조와 색상 분포를 대략적으로 제어하기 위해 공간적 색상 팔레트를 설계한다. 공간적 팔레트를 학습하려면 이미지의 색조와 색상 분포를 표현해야 한다. 여기서는 high bicubic downsampling을 사용하여 충분한 색상 정보를 보존하면서 이미지의 semantic 정보와 구조적 정보를 제거한다. 그런 다음 가장 nearest upsampling을 적용하여 이미지를 원래 크기로 복원한다. 마지막으로 색상과 색상 분포는 여러 공간 배열 색상 블록으로 표시된다. 경험적으로 64배 다운샘플링과 업샘플링을 활용하여 이 프로세스를 완료한다. 학습하는 동안 색상 맵을 $C$로 활용하여 \(\mathcal{F}_\textrm{AD}\)를 통해 $F_c$를 생성한다.
다중 어댑터 제어
하나의 어댑터를 조건으로 사용하는 것 외에도 T2I 어댑터는 여러 조건을 지원한다. 이 전략에는 추가 학습이 필요하지 않다. 수학적으로 이 프로세스는 다음과 같이 정의할 수 있다.
\[\begin{equation} F_c = \sum_{k=1}^K \omega_k \mathcal{F}_\textrm{AD}^k (C_k), \quad k \in [1, K] \end{equation}\]여기서 $k$는 $k$번째 guidance를 나타낸다. $\omega_k$는 각 어댑터의 결합 강도를 제어하기 위한 조정 가능한 가중치이다. 이 결합 가능한 속성은 몇 가지 유용한 애플리케이션으로 이어진다. 예를 들어 스케치 맵을 사용하여 생성된 결과에 대한 구조 guidance를 제공하고 공간 색상 팔레트를 사용하여 생성된 결과에 색상을 지정할 수 있다.
3. Model Optimization
최적화하는 동안 SD의 파라미터를 고정하고 T2I-Adapter만 최적화한다. 각 학습 샘플은 원본 이미지 $X_0$, 조건 맵 $C$, 텍스트 프롬프트 $y$를 포함하는 triplet이다. 최적화 프로세스는 SD와 유사하다. 구체적으로 이미지 $X_0$가 주어지면 먼저 오토인코더의 인코더를 통해 latent space $Z_0$에 이미지를 삽입한다. 그런 다음 timestep $t$를 무작위로 샘플링하고 해당 noise를 $Z_0$에 추가하여 $Z_t$를 생성한다. 수학적으로 T2I-Adapter는 다음을 통해 최적화된다.
\[\begin{equation} \mathcal{L}_\textrm{AD} = \mathbb{E}_{Z_0, t, F_c, \epsilon \sim \mathcal{N}(0, 1)} [\| \epsilon - \epsilon_\theta (Z_t, t, \tau (y), F_c) \|_2^2] \end{equation}\]학습 중 균일하지 않은 timestep 샘플링
Diffusion model에서 시간 임베딩은 샘플링에서 중요한 조건이다. 저자들은 어댑터에 시간 임베딩을 도입하는 것이 guidance 능력을 향상시키는 데 도움이 된다는 것을 발견했다. 그러나 이 디자인에서는 어댑터가 각 iteration에 참여해야 하므로 단순하고 작다는 동기를 위반한다. 따라서 적절한 학습 전략을 통해 이 약점을 바로잡아야 한다.

구체적으로 DDIM inference 샘플링을 3단계, 즉 초기, 중간, 후기 단계로 균등하게 나눈다. 그런 다음 세 단계 각각에 guidance 정보를 추가한다. 저자들은 중간 단계와 후기 단계에서 guidance를 추가하는 것이 결과에 거의 영향을 미치지 않는다는 것을 발견했다 (위 그림 참조). 이는 초기 샘플링 단계에서 생성 결과의 주요 내용이 결정됨을 나타낸다. 따라서 나중 섹션에서 $t$를 샘플링하면 학습 중에 guidance 정보가 무시된다. 어댑터의 학습을 강화하기 위해 불균일 샘플링을 채택하여 초기 샘플링 단계에서 $t$가 떨어질 확률을 높인다. 여기서는 $t$의 분포로 3차 함수
를 사용한다.

위 그림은 색상 guidance와 keypose guidance에 대한 균일 샘플링과 불균일 샘플링 사이를 비교한 것이다. $t$의 균일한 샘플링은 특히 색상 제어에서 약한 guidance 문제가 있음을 알 수 있다. 큐빅 샘플링 전략은 이러한 약점을 바로잡을 수 있다.
Experiment
- 구현 디테일
- 학습 중에 입력 이미지와 조건 맵을 512$\times$512로 조정한 후 사전 학습된 SD v1.4를 적용
- epochs: 10
- batch size: 8
- optimizer: Adam
- learning rate: $1 \times 10^{-5}$
- NVIDIA Tesla 32G-V100 GPU 4개로 3일 소요
- 데이터셋
- 스케치 맵: COCO17 (이미지 16.4만 개)
- semantic segmentation map: COCO-Stuff (이미지 16.4만 개)
- keypose map, 색상 맵, 깊이 맵: LAION-AESTHETICS (이미지-텍스트 쌍 60만 개)
- MM-Pose로 keypose map 추출
- MiDaS로 깊이 맵 추출
1. Comparison
다음은 다른 방법들과 본 논문의 방법과 비교하여 시각화한 것이다.

다음은 COCO validation set에서 정량적으로 평가한 표이다.

2. Applications
다음은 단일 어댑터 제어를 시각화한 것이다.

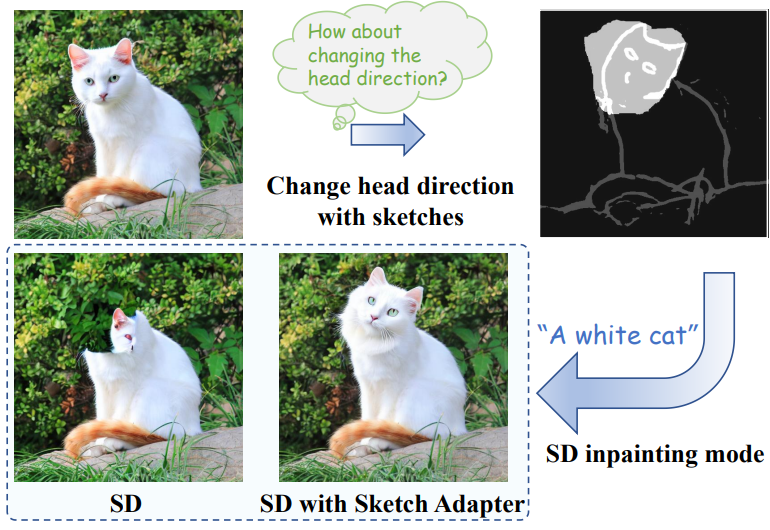
다음은 스케치 어댑터의 이미지 편집 능력을 나타낸 그림이다.
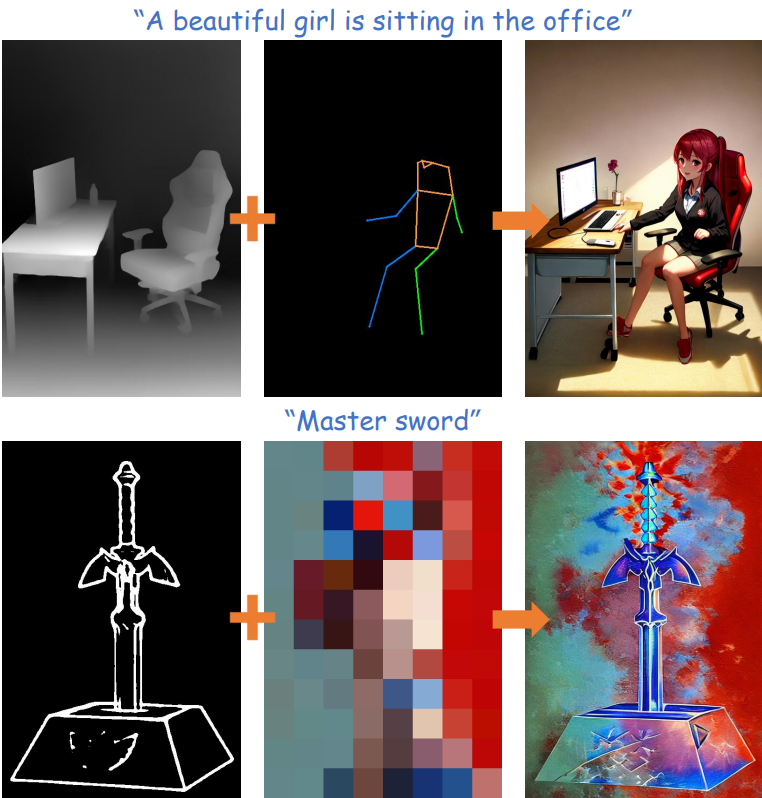
다음은 결합 가능한 다중 어댑터 제어를 시각화한 것이다. 위는 깊이 + keypose이고 아래는 스케치 + 색상 맵이다.
다음은 T2I-Adapter의 일반화 가능한 능력을 나타낸 그림이다.

3. Ablation Study
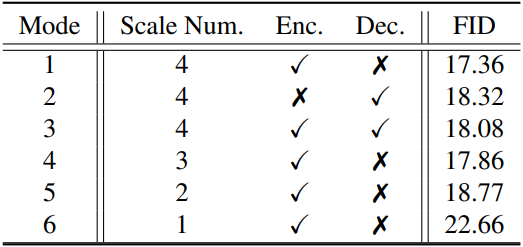
다음은 ablation study 결과이다.
다음은 T2I-Adapter의 기본, 소형, 초소형 버전의 생성 품질 비교.

Limitation
다중 어댑터 제어의 경우 guidance feature를 조합하려면 수동 조정이 필요하다.