[논문리뷰] T-Stitch: Accelerating Sampling in Pre-trained Diffusion Models with Trajectory Stitching
ICLR 2025. [Paper] [Page] [Github]
Zizheng Pan, Bohan Zhuang, De-An Huang, Weili Nie, Zhiding Yu, Chaowei Xiao, Jianfei Cai, Anima Anandkumar
Monash University | NVIDIA | University of Wisconsin | Caltech
21 Feb 2024
Introduction
본 논문에서는 기존 diffusion model들의 효율적인 샘플링 방법을 보완하여 다양한 denoising step에 연산을 동적으로 할당하여 diffusion model의 효율성을 개선하는 간단하면서도 효과적인 전략인 Trajectory Stitching (T-Stitch)을 제안하였다. 핵심 아이디어는 기존 방법들처럼 모든 denoising step에서 동일한 모델을 사용하는 대신, 여러 denoising step에서 다양한 크기의 diffusion model을 적용하는 것이다.
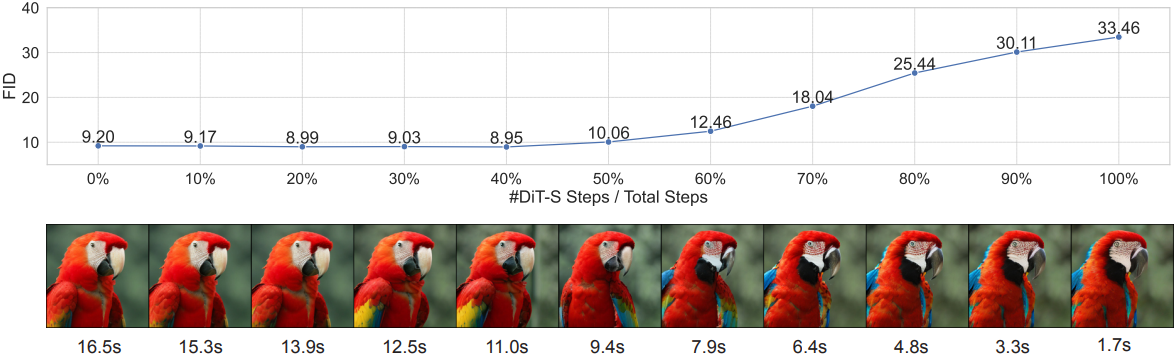
초기 denoising step에서 먼저 더 작은 diffusion model을 적용한 다음, 이후 denoising step에서 더 큰 diffusion model으로 전환함으로써 생성 품질을 희생하지 않고도 전체 계산 비용을 줄일 수 있다. 위 그림은 DiT-S와 DiT-XL을 사용한 T-Stitch의 예시이며, DiT-S는 DiT-XL보다 계산적으로 훨씬 저렴하다. T-stitch에서 DiT-S의 비율이 증가함에 따라 inference 속도를 계속 높일 수 있으며, 처음 40%의 step에서 DiT-S를 사용하더라도 생성 품질(FID)이 저하되지 않아 약 1.5배의 손실 없는 속도 향상이 나타났다.
T-Stitch는 두 가지 핵심 통찰력에 기초한다.
- 동일한 데이터 분포에서 학습된 서로 다른 diffusion model은 공통적인 latent space를 가진다. 따라서 서로 다른 diffusion model은 유사한 샘플링 궤적을 공유하는 경향이 있어 서로 다른 모델 크기와 아키텍처에 걸쳐 스티칭이 가능하다.
- 주파수 관점에서, denoising process는 초기 step에서 저주파 성분을 생성하는 데 초점을 맞추는 반면, 이후 step에서는 고주파 신호를 타겟으로 한다. 작은 모델은 고주파 디테일에 효과적이지 않지만, 처음에 좋은 글로벌 구조를 생성할 수 있다.
T-Stitch는 생성 품질을 크게 떨어뜨리지 않고도 대규모 diffusion model을 상당히 빠르게 만들며, 이는 다양한 아키텍처와 diffusion model 샘플러에서 일관되게 나타났다. 또한 재학습 없이 널리 사용되는 대규모 diffusion model에 직접 적용될 수 있다 (ex. Stable Diffusion (SD)).
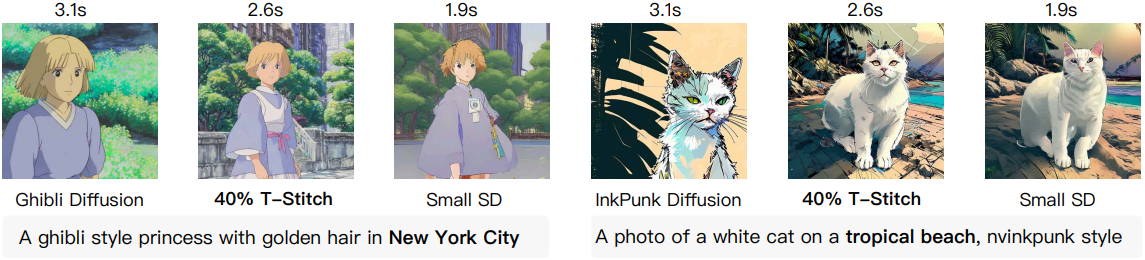
위 그림은 stylize된 SD 모델에 더 작은 SD 모델을 스티칭한 예시이다. 놀랍게도 T-Stitch는 속도를 향상시킬 뿐만 아니라 프롬프트 정렬도 개선한다. 이는 stylize된 모델의 fine-tuning 프로세스가 프롬프트 정렬을 저하시키기 때문일 수 있다.
또한, T-Stitch는 다음과 같은 여러 장점들이 추가로 있다.
- 기존의 빠른 샘플링 방법들과 함께 사용할 수 있다. 큰 diffusion model의 궤적은 step 수를 줄이거나 압축 기술을 사용하여 계산 비용을 줄임으로써 여전히 가속화할 수 있다.
- 궤적 schedule이 주어진 스티칭된 diffusion model을 fine-tuning할 때 생성 품질이 더욱 개선될 수 있다.
- 큰 diffusion model을 적용되는 timestep에서만 fine-tuning함으로써, 큰 diffusion model은 고주파 디테일을 제공하는 데 더 특화되고 생성 품질을 더욱 개선할 수 있다.
- 추가 학습 없이도 모델 스티칭을 위해 설계된 학습 기반 방법에 대한 품질-효율성 trade-off를 개선한다.
- 두 가지 모델 크기에만 국한되지 않으며, 다양한 diffusion model 아키텍처에도 적용할 수 있다.
Method
여러 사전 학습된 diffusion model을 샘플링 궤적을 따라 직접 연결할 수 있는 이유는 무엇인가?
동일한 모델 패밀리의 diffusion model은 일반적으로 동일한 모양의 latent 입력 및 출력을 취한다 (ex. DiT는 4$\times$32$\times$32). 따라서, 여러 denoising step에서 다른 diffusion model을 적용할 때 차원 불일치가 없다.
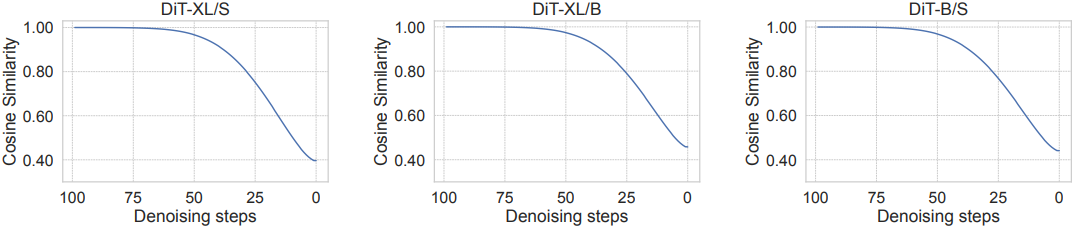
더 중요한 것은, Score-Based Generative Modeling through Stochastic Differential Equations 논문에서 지적했듯이, 동일한 데이터셋에서 학습된 다른 diffusion model은 종종 유사한 latent 임베딩을 학습한다는 것이다. 위 그림에서 볼 수 있듯이, 초기 denoising step에서 특히 더 그렇다. 이는 대규모 diffusion model의 샘플링 속도를 가속화하기 위해, 처음에 사전 학습된 작은 모델을 활용하는 새로운 step 수준의 스티칭 전략을 제안하도록 동기를 부여하였다.
모델 선택의 원칙
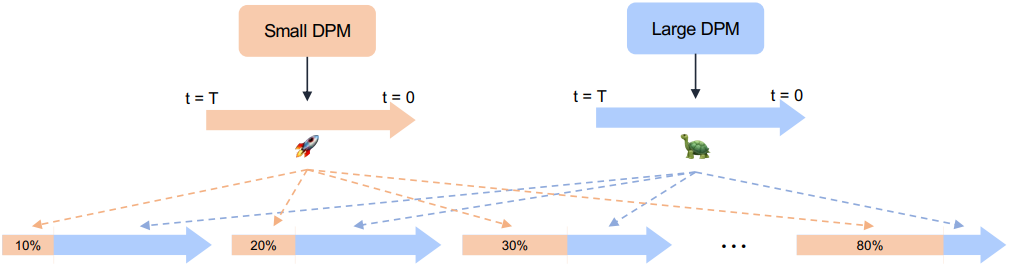
위 그림은 다양한 속도-품질 trade-off에 대한 제안된 T-Stitch의 프레임워크를 보여준다. 원칙적으로, 달성할 수 있는 가장 빠른 속도 또는 최악의 생성 품질은 가장 작은 모델에 의해 결정되는 반면, 가장 느린 속도 또는 최상의 생성 품질은 가장 큰 모델에 의해 결정된다. 따라서 속도를 높이고자 하는 큰 diffusion model이 주어지면, 더 빠르고, 충분히 최적화되었으며, 큰 모델과 동일한 데이터셋에서 학습되었거나 적어도 유사한 데이터 분포를 학습한 작은 모델을 선택한다.
모델 할당
기본적으로 T-Stitch는 샘플링 과정에서 두 개의 denoiser를 사용한다. 먼저 denoising 구간을 정의하며, 이는 전체 샘플링 step 수 $T$ 중 특정 범위를 의미한다. 이 구간의 길이를 전체 단계 수 $T$로 나눈 값을 $r \in [0,1]$이라고 한다.
다음으로, 모델 할당을 컴퓨팅 예산 할당 문제로 취급한다. 서로 다른 크기의 denoiser 간의 latent 유사도는 $T$가 0에 가까워질수록 점진적으로 감소한다. 이를 고려하여, 초기 denoising 구간에서는 연산 비용이 적게 드는 작은 denoiser를 사용하고, 이후 구간에서는 큰 denoiser를 적용하는 방식을 따른다.
작은 denoiser $D_1$과 큰 denoiser $D_2$가 있다고 가정하자. 이때, $D_1$은 처음 $\lfloor r_1 T \rceil$ 단계 동안 사용되고, $D_2$는 마지막 $\lfloor r_2 T \rceil$ 단계에서 사용된다 ($r_2 = 1 - r_1$). $r_1$을 증가시키면 자연스럽게 작은 denoiser에서 큰 denoiser로의 연산 예산이 점진적으로 전환되며, 이에 따라 품질과 효율성 간의 유연한 trade-off를 조절할 수 있다.
더 많은 trade-off를 위한 더 많은 denoiser
T-Stitch는 더 많은 denoiser를 채택하여 더 많고 더 나은 속도-품질 trade-off를 얻을 수 있다. 예를 들어, 중간 구간에서 중간 크기의 denoiser를 사용하여 더 많은 구성을 얻을 수 있다. 실제로, 시간 비용과 같은 컴퓨팅 예산이 주어지면 미리 계산된 lookup table을 통해 이 제약 조건을 충족하는 몇 가지 구성을 효율적으로 찾을 수 있다.
Experiments
1. DiT Experiments
다음은 두 모델을 스티칭하였을 때의 FID를 스티칭 비율에 따라 비교한 그래프이다. (classifier-free guidance scale = 1.5)
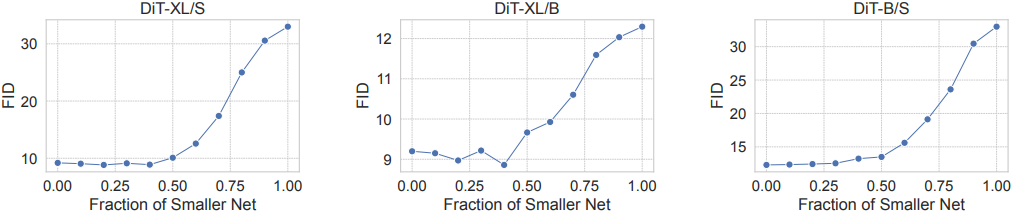
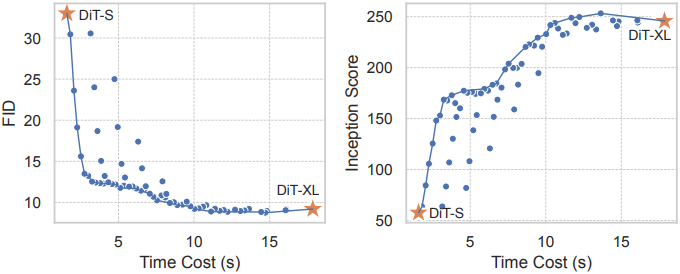
다음은 DiT-S, DiT-B, DiT-XL에 대한 속도-품질 trade-off이다. (guidance scale = 1.5)
2. U-Net Experiments
다음은 클래스 조건부 ImageNet에 대하여 LDM과 LDM-S에 T-Stitch를 적용한 결과이다. (DDIM 100 step, guidance scale = 3.0)

3. Text-to-Image Stable Diffusion
다음은 MS-COCO 256$\times$256에 대하여 BK-SDM Tiny와 SD v1.4에 T-Stitch를 적용한 결과이다.

다음은 fine-tuning된 큰 SD 모델과 사전 학습된 작은 SD 모델에 T-Stitch를 적용한 예시들이다.

4. Ablation Study
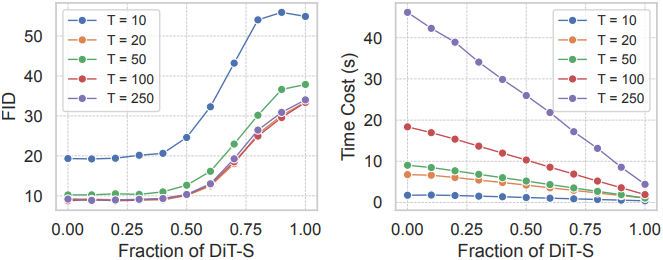
다음은 전체 denoising step의 수 $T$에 따른 (왼쪽) 품질과 (오른쪽) 속도를 비교한 그래프이다.
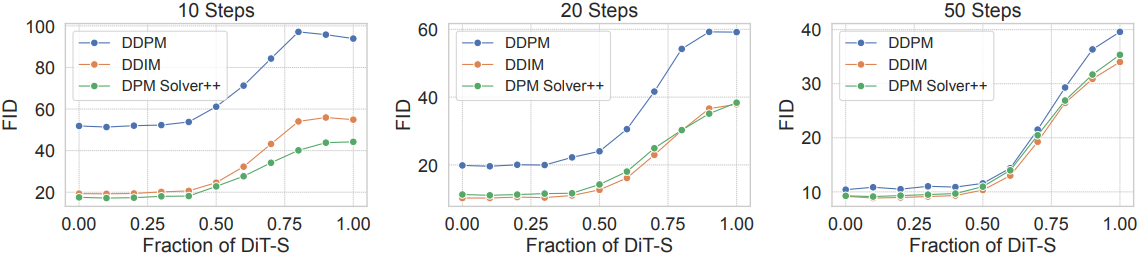
다음은 다양한 샘플러에 대한 ablation 결과이다. (guidance scale = 1.5)
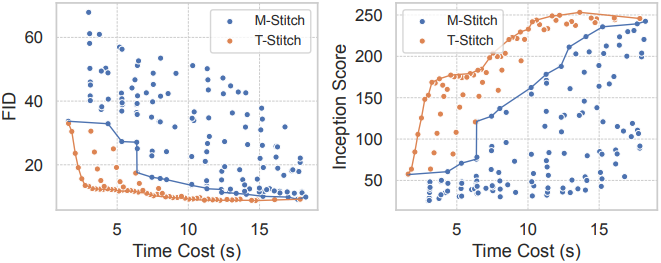
다음은 T-Stitch를 모델 스티칭 방법(M-Stitch)과 비교한 결과이다. (DiT, DDIM 100 step)
Limitations
- 큰 모델과 동일한 데이터 분포에서 학습된 더 작은 모델을 필요로 하기 때문에, 충분히 최적화된 작은 모델이 필요하다.
- Denoising을 위해 추가적으로 작은 모델을 채택하면 메모리 사용량이 약간 증가하다.
- 속도 향상 이득은 작은 모델의 효율성에 의해 제한된다.