[논문리뷰] Is synthetic data from generative models ready for image recognition?
ICLR 2023. [Paper] [Github]
Ruifei He, Shuyang Sun, Xin Yu, Chuhui Xue, Wenqing Zhang, Philip Torr, Song Bai, Xiaojuan Qi
The University of Hong Kong | University of Oxford | ByteDance
14 Oct 2022
Introduction
지난 10년 동안 대규모의 주석이 달린 데이터를 기반으로 한 딥러닝은 이미지 인식 (image recognition) 분야에 혁명을 일으켰다. 그러나 대규모 레이블이 지정된 데이터셋을 수동으로 수집하는 것은 비용과 시간이 많이 소요되며, 최근 데이터 개인정보 보호 및 사용 권한에 대한 우려로 인해 이 프로세스가 더욱 방해받고 있다. 동시에, 실제 데이터 분포를 모델링하는 것을 목표로 하는 생성 모델은 이제 충실도가 높고 사실적인 이미지를 생성할 수 있다. 특히, 최근의 text-to-image 생성 모델은 텍스트 설명에서 고품질 이미지를 합성하는 데 획기적인 발전을 이루었다. 이로 인해 저자들은 다음과 같은 질문을 하게 되었다.
생성 모델의 합성 데이터가 이미지 인식 task에 준비되어 있는가?
이미지 인식 task을 위해 생성 모델에서 합성 데이터를 탐색하려는 초기 시도가 몇 가지 있다. 유망하기는 하지만 초기 연구들은 소규모 또는 특정 설정에 대한 task만 다루었다. 또한 모두 GAN 기반 모델에 초점을 맞추고 있으며 인식 task에 더 많은 이점을 제공하는 혁신적인 text-to-image 생성 모델을 탐색하지 않는다.
본 논문에서는 이미지 인식을 위한 SOTA text-to-image 생성 모델에 대한 첫 번째 연구를 제시하였다. Text-to-image 생성 능력을 통해 대규모의 고품질 레이블 데이터를 생성할 수 있을 뿐만 아니라 특정 레이블 공간, 즉 다운스트림 task의 레이블 공간을 대상으로 하는 합성 데이터를 생성하여 도메인 커스터마이징할 수도 있다. 본 논문의 연구는 하나의 오픈 소스 text-to-image 생성 모델인 GLIDE를 사용하여 수행되었다. 저자들은 다음 두 가지 질문을 조사하여 이미지 인식을 위한 합성 데이터의 이점과 함정을 밝히려고 시도하였다.
- 생성 모델의 합성 데이터가 분류 모델을 개선할 준비가 되어 있는가?
- 합성 데이터가 transfer learning(ex. 모델 사전 학습)을 위한 실행 가능한 소스가 될 수 있는가?
저자들은 더 많은 shot이 존재할수록 합성 데이터의 긍정적인 영향이 감소하기 때문에 zero-shot과 few-shot 설정만 연구하였다. 그리고 사전 학습된 대규모 가중치를 동결하여 초기화된 feature extractor를 사용하여 SOTA 방법인 CLIP을 조사하였다. 연구 결과는 다음과 같다.
- Zero-shot 설정: 실제 데이터를 사용할 수 없는 경우 합성 데이터가 17개의 다양한 데이터셋에 대한 분류 결과를 크게 향상할 수 있다. 성능은 평균 top-1 accuracy가 4.31% 증가하고 심지어 EuroSAT 데이터셋에서는 17.86%나 향상되었다. 이 설정에서 합성 데이터를 더 잘 활용하기 위해 저자들은 데이터 다양성을 높이고 데이터의 잡음을 줄이며 데이터 신뢰성을 향상시키는 유용한 전략도 조사하였다. 이는 다양한 텍스트 프롬프트를 디자인하고 CLIP feature를 사용하여 텍스트와 합성 데이터의 상관관계를 측정함으로써 달성된다.
- Few-shot 설정: Zero-shot만큼 중요하지는 않지만 합성 데이터도 유익하고 새로운 SOTA를 달성하였다. 합성 데이터와 다운스트림 task 데이터 사이의 도메인 격차는 classifier 학습에 대한 합성 데이터의 효율성을 더욱 향상시키는 데 있어 하나의 과제이다. 다행히도 이 설정에서는 실제 데이터 샘플에 대한 접근성이 다운스트림 task의 데이터 분포에 대한 유용한 정보를 제공할 수 있다. 따라서 저자들은 도메인 격차를 줄이고 효율성을 높이기 위해 생성 프로세스의 guidance로 실제 이미지를 사용할 것을 제안하였다.
- Transfer learning을 위한 대규모 모델 사전 학습: 합성 데이터는 모델 사전 학습에 적합하고 효과적이며 우수한 transfer learning 성능을 제공하고 심지어 ImageNet 사전 학습보다 뛰어난 성능을 발휘한다. 특히, 합성 데이터는 unsupervised model의 사전 학습에서 놀라울 정도로 잘 작동하며, ViT 기반 backbone을 선호한다. 또한 데이터 생성을 위한 레이블 공간(ex. 텍스트 프롬프트)을 늘리면 데이터 양과 다양성이 확대되어 성능이 더욱 향상될 수 있다. 게다가 합성 데이터는 실제 데이터(ex. ImageNet)와 협력하여 모델이 ImageNet에서 사전 학습된 가중치로 초기화될 때 향상된 성능을 얻을 수 있다.
Is Synthetic Data Ready for Image Recognition?
데이터가 부족한(ex. zero-shot, few-shot) 이미지 분류를 위한 모델 설정
CLIP은 zero-shot 학습을 위한 SOTA 접근 방식이므로 저자들은 사전 학습된 CLIP 모델을 기반으로 zero-shot 및 few-shot 설정에 대한 연구를 수행하여 강력한 baseline에 따른 합성 데이터를 더 잘 이해하는 것을 목표로 하였다. 데이터가 부족한 이미지 분류를 위해 사전 학습된 CLIP을 더 잘 조정하려는 시도가 몇 번 있었으며, 사전 학습된 feature space를 더 잘 보존하기 위해 이미지 인코더를 고정하였다. 저자들은 다양한 튜닝 방법들이 모두 classifier 가중치를 학습하는 다양한 방법으로 간주될 수 있다고 주장한다.
저자들은 간단한 튜닝 방법인 Classifier Tuning (CT)를 채택하였다. 구체적으로 k-way classification의 경우 프롬프트 $s_i$ = “a photo of a \(\{c_i\}\)“와 함께 클래스 이름 \(C = \{c_1, \ldots, c_k\}\)를 CLIP의 텍스트 인코더 $h$에 입력하여 텍스트 feature $h(s_i)$를 얻는다. 그런 다음 $h(s_i)$를 사용하여 classifier 가중치 $W \in \mathbb{R}^{d \times k}$를 구성할 수 있다. 여기서 $d$는 텍스트 feature의 차원이다. 마지막으로 이미지 인코더 $g$를 classifier 가중치 $W$와 결합하여 분류 모델 $f(x) = g(x)^\top W$를 얻는다. 저자들은 복잡하게 설계된 튜닝 방법과 대신 합성 데이터의 효율성을 더 잘 조사하기 위해 더 간단한 CT를 사용하였으며, CT는 다른 튜닝 방법과 비교하여 성능이 유사하다.
1. 합성 데이터는 zero-shot 이미지 인식을 위해 준비되어 있는가?
본 논문의 목표는 합성 데이터가 zero-shot task에 어느 정도 도움이 되는지, zero-shot 학습을 위해 합성 데이터를 더 잘 활용하는 방법을 조사하는 것이다.
Zero-shot 이미지 인식
저자들은 목표 카테고리의 실제 학습 이미지가 없는 zero-shot 제로샷 학습 설정을 연구하였다. CLIP 모델은 대규모 이미지-캡션 쌍으로 사전 학습되었으며, 쌍을 이루는 이미지 인코더 $g$의 이미지 feature와 텍스트 인코더 $h$의 텍스트 feature 간의 유사도는 사전 학습 중에 최대화된다. 사전 학습된 feature extractor는 주어진 이미지에서 $g$의 feature를 $h$의 다른 클래스의 텍스트 feature와 비교하고 이미지가 CLIP 텍스트-이미지 feature space에서 가장 큰 유사도를 갖는 클래스에 추가로 할당되는 zero-shot task를 해결하는 데 사용될 수 있다.
Zero-shot 이미지 인식을 위한 합성 데이터
CLIP 모델은 사전 학습을 위한 대규모 비전-언어 데이터셋 덕분에 강력한 zero-shot 성능을 보이지만 다운스트림 zero-shot classification task를 위해 모델을 배포할 때 피할 수 없는 CLIP 사전 학습 데이터의 데이터 잡음 또는 사전 학습과 zero-shot task 간의 레이블 공간 불일치로 인해 발생할 수 있는 몇 가지 단점이 여전히 있다. 따라서 저자들은 주어진 레이블 공간을 사용하여 CLIP 모델을 더 잘 적용하기 위해 합성 데이터를 사용할 수 있는지 여부를 연구하였다.
어떻게 데이터를 생성하는가?
사전 학습된 text-to-image 생성 모델이 주어지면 새로운 샘플을 합성하기 위한 기본 전략(B)은 대상 카테고리의 레이블 이름을 사용하여 언어 입력을 구축하고 해당 이미지를 생성하는 것이다. 그런 다음, 쌍을 이루는 레이블 이름과 합성된 데이터를 사용하여 feature extractor가 고정시키고 classifier를 학습시킬 수 있다.
어떻게 다양성을 풍부하게 할 것인가?
레이블 이름만 입력으로 사용하면 합성 이미지의 다양성이 제한되고 합성 데이터의 효율성을 검증하는 데 문제가 발생할 수 있다. 따라서 “Colossal Clean Crawled Corpus” 데이터셋에서 사전 학습된 word-to-sentence T5 모델을 활용하고 CommonGen 데이터셋에서 fine-tuning하여 언어 프롬프트와 생성된 이미지의 다양성을 높이고 합성 데이터의 잠재력을 더 잘 발휘할 수 있도록 한다. 이 전략을 language enhancement(LE)라고 부른다. 구체적으로, 텍스트-이미지 생성 프로세스를 위한 언어 프롬프트로 클래스 이름을 포함하는 다양한 문장을 생성하는 word-to-sentence 모델에 각 클래스의 레이블 이름을 입력한다. 예를 들어, 클래스 레이블이 “비행기”인 경우 모델의 향상된 언어 프롬프트는 “해변과 도시 위를 떠다니는 흰색 비행기”가 될 수 있다. 향상된 텍스트 설명은 풍부한 컨텍스트 설명을 도입한다.
어떻게 데이터 노이즈를 줄이고 robustness를 높이는가?
합성된 데이터에 품질이 낮은 샘플이 포함될 수 있는 것은 불가피하다. 이는 언어 프롬프트에 원하지 않는 항목이 포함될 수 있으므로 LE가 포함된 설정에서는 더욱 심각하다. 따라서 저자들은 이러한 샘플을 배제하기 위해 CLIP Filter(CF) 전략을 도입하였다. 구체적으로, CLIP zero-shot 분류 신뢰도는 합성 데이터의 품질을 평가하는 데 사용되며 신뢰도가 낮으면 제거된다. 또한, 소프트 타겟은 하드 타겟보다 샘플 노이즈에 대해 더 강력하므로 저자들은 정규화된 CLIP score를 타겟으로 사용하는 soft cross-entropy loss(SCE)를 사용하여 데이터 노이즈에 대한 robustness를 향상시킬 수 있는지 연구하였다.
주요 결과
다음은 여러 데이터셋의 테스트셋 top-1 accuracy이다. (o: object-level. s: scene-level. f: fine-grained. t: textures. si: satellite images. r: robustness.)
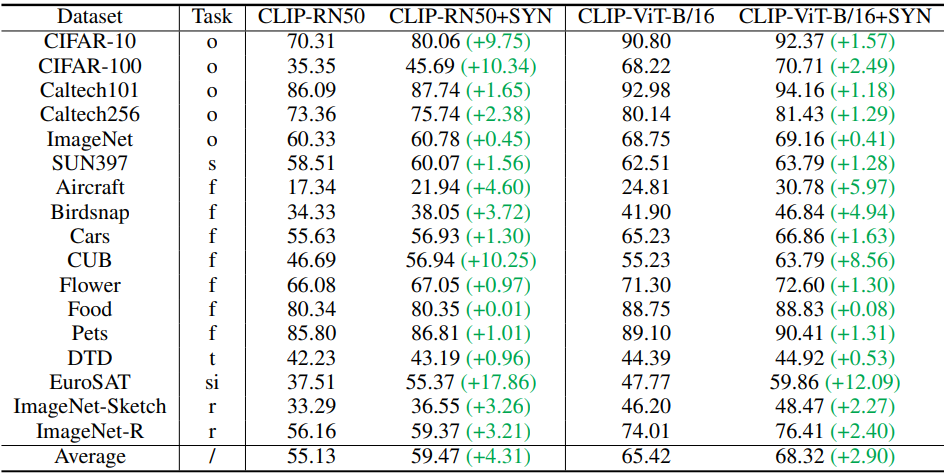
다음은 Language Enhancement (LE), CLIP-based Filtering (CF), Soft-target Cross-Entropy (SCE)에 대한 ablation 결과이다.

다음은 파라미터 튜닝 비율에 따른 정확도를 비교한 표이다. (EuroSAT)

다음은 카테고리별 실제 데이터의 학습 이미지 수에 따른 정확도를 비교한 표이다. (CIFAR-100)

카테고리당 95개의 이미지(총 9.500개)로 학습시키면 5만개의 합성 데이터와 비슷한 성능을 얻을 수 있다. 이는 다운스트림 task를 해결할 때 합성 데이터가 실제 데이터만큼 효율적이고 효과적이지 않다는 것을 나타낸다. 실제 데이터와 비슷한 성능을 얻으려면 약 5배 더 많은 데이터가 필요하다. 합성 데이터의 양을 더 늘려도 다운스트림 classification task에 대한 성능 향상이 더 이상 없다.
결론
- 합성 데이터의 언어 다양성과 신뢰도가 중요하다.
- CLIP에는 classifier 튜닝만으로 충분하며, 사전 학습된 인코더를 사용한 튜닝은 주로 도메인 격차로 인해 성능 저하가 발생한다.
- 합성 데이터는 처음부터 학습할 때 성능이 떨어지며 실제 데이터보다 데이터 효율성이 훨씬 낮다.
2. 합성 데이터는 few-shot 이미지 인식을 위해 준비되어 있는가?
저자들은 few-shot task에 대한 합성 데이터의 효율성과 더 많은 shot이 포함됨에 따라 합성 데이터가 성능에 어떤 영향을 미치는지 살펴보았다. 또한, 합성 데이터를 더 잘 활용하기 위한 효과적인 전략을 설계하였다.
Few-shot 이미지 인식
저자들은 few-shot 이미지 인식을 위한 모델로 CLIP 기반 방법을 채택하였다. 다양한 프롬프트 학습 기반 방법은 classifier 가중치를 튜닝하는 것으로 처리될 수 있다. 따라서 저자들은 합성 데이터를 사용하여 classifier 가중치를 튜닝하는 방법을 연구하였다. N-way M-shot에서는 각 테스트 클래스의 $M$개의 실제 이미지가 제공되며, 실험에서는 \(M \in \{1, 2, 4, 8, 16\}\)이다. 총 $N \times M$개의 학습 샘플을 사용하여 $N$개의 클래스의 테스트셋에서 유리한 성능을 달성하는 것이 목표이다.
Few-shot 이미지 인식을 위한 합성 데이터
Few-shot task를 위해 CLIP 모델을 더 잘 적용하는 방법을 연구하려는 몇 가지 시도가 있었지만 모두 모델 최적화 수준에 초점을 맞추고 데이터 수준에서 탐색한 것은 없다. 본 논문에서는 few-shot 이미지 인식 task를 해결하기 위해 합성 데이터를 사용할 수 있는지 여부와 방법을 체계적으로 연구하였다.
Zero-shot task를 위한 합성 데이터의 경험을 바탕으로 zero-shot 설정에서 가장 좋은 전략(LE+CF)을 기본 전략(B)으로 채택한다. 또한, few-shot에서의 실제 샘플은 classification task의 데이터 분포에 대한 유용한 정보를 제공할 수 있으므로 저자들은 합성 데이터를 더 잘 사용하기 위해 도메인 내 실제 데이터를 활용하는 두 가지 새로운 전략을 개발하였다.
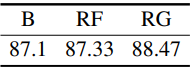
- Real Filtering (RF): 한 클래스 $c$의 합성 데이터가 주어지면 few-shot 실제 샘플의 feature를 사용하여 클래스 $c$와 다른 카테고리에 속하는 실제 샘플의 feature와 매우 유사한 feature를 갖는 합성 이미지를 필터링한다.
- Real Guidance (RG): 합성 이미지를 생성하기 위한 guidance로 few-shot 실제 샘플을 사용한다. Diffusion process를 가이드하기 위해 few-shot 실제 샘플에 noise를 추가하여 생성 시작 시 랜덤 노이즈를 대체한다.
주요 결과
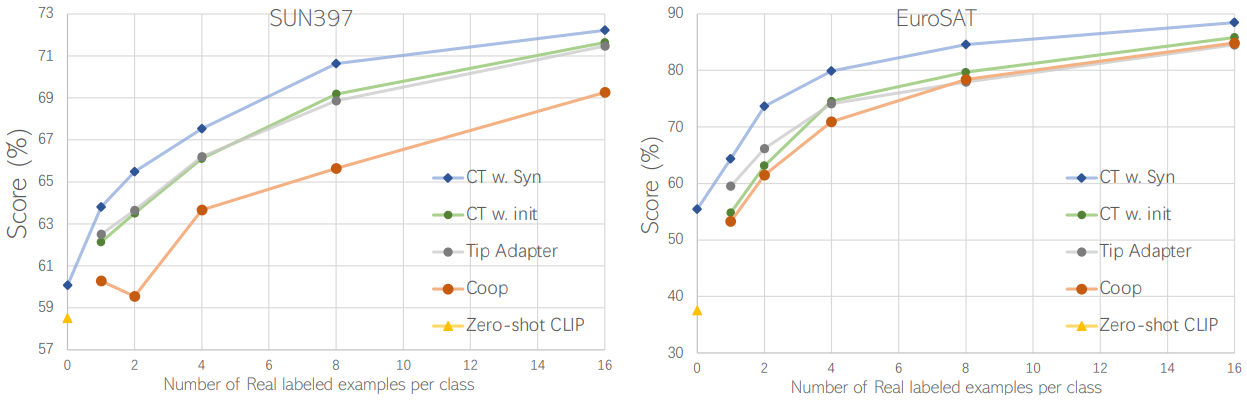
다음은 SUN397과 EuroSAT에 대한 few-shot image recognition 결과이다. CT w. init는 classifier 가중치를 CLIP 텍스트 임베딩으로 초기화한 모델이며, CT w. Syn는 실제/합성 데이터의 혼합 학습, Real Guidance, batch normalization 고정 전략을 모두 사용한 모델이다.
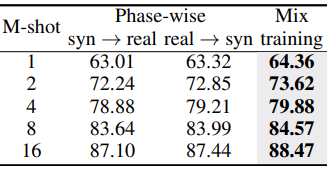
합성 데이터와 few-shot 실제 데이터라는 두 부분의 데이터가 있기 때문에 각 부분을 순서대로 학습하거나 혼합하여 학습할 수 있다. 다음은 이에 대한 비교 결과이다. (EuroSAT)
다음은 기본 전략(B), Real Filtering(RF), Real Guidance(RG)에 대한 ablation 결과이다. (EuroSAT, 16-shot)
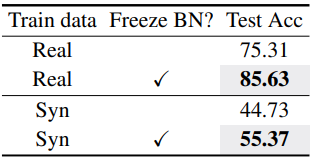
다음은 batch normalization (BN)을 고정하였을 때의 결과이다. (EuroSAT, 16-shot)
결론
- 합성 데이터는 few-shot 학습을 촉진할 수 있으며 실제 데이터 shot이 증가함에 따라 합성 데이터의 긍정적인 영향은 점차 줄어든다.
- 합성 데이터와 실제 데이터를 혼합하여 학습하는 것이 few-shot 학습에 적합하다.
- Batch normalization을 고정하는 것이 성능이 더 좋다.
3. 합성 데이터는 사전 학습을 위해 준비되어 있는가?
저자들은 합성 데이터가 대규모 사전 학습에 효과적인지 연구하였다. 또한 모델 사전 학습을 위해 합성 데이터를 더 잘 활용할 수 있는 효과적인 전략을 제시하였다.
Transfer Learning을 위한 사전 학습
최근에는 잘 학습된 feature extractor를 얻기 위해 먼저 대규모 데이터셋에서 모델을 사전 학습시킨 다음 레이블이 지정된 데이터를 사용하여 다운스트림 task에서 모델을 fine-tuning하는 것이 일반적인 관행이 되었다 (ex. transfer learning). Supervised pre-training, self-supervised pre-training, semi-supervised pre-training 등 다양한 성공적인 사전 학습 방법이 있다.
사전 학습을 위한 합성 데이터
사전 학습에서는 데이터 양과 다양성이 중요한 역할을 하기 때문에 합성 데이터의 규모를 최대화하기 위해 합성 데이터 생성 전략 LE만 채택한다. 저자들은 사전 학습을 위한 합성 데이터를 생성하기 위한 두 가지 세팅을 연구하였다.
- Downstream-aware: 다운스트림 task의 레이블 공간에 액세스할 수 있으므로 다운스트림 task의 레이블 공간에 따라 합성 데이터를 생성
- Downstream-agnostic: 사전 학습 단계에서는 다운스트림 task에 접근할 수 없으며 ImageNet-1K와 같은 비교적 일반적이고 다양한 레이블 공간으로 사용
사전 학습 방법으로는 supervised pre-training과 self-supervised pre-training 방법을 실험하였다.
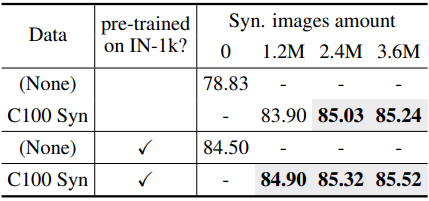
Downstream-aware에서의 결과
다음은 CIFAR-100에 대한 downstream-aware supervised pre-training 결과이다.
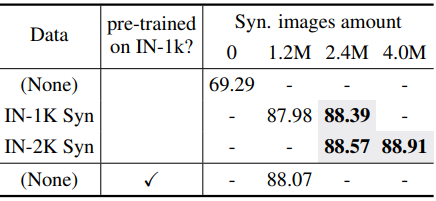
Downstream-agnostic에서의 결과
다음은 CIFAR-100에 대한 downstream-agnostic supervised pre-training 결과이다.
다음은 PASCAL VOC에서의 object detection에 대한 downstream-agnostic supervised pre-training 결과이다.
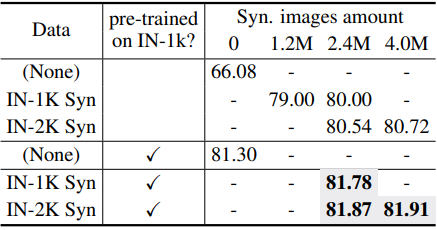
다음은 PASCAL VOC에서의 object detection에 대한 downstream-agnostic self-supervised pre-training (Moco v2) 결과이다.

결론
- 데이터 양은 합성 사전 학습에 긍정적인 영향을 미친다. 합성 데이터 크기를 늘리면 성능이 향상될 수 있지만 데이터 양이 증가함에 따라 점차 포화 상태가 된다.
- 사전 학습을 위한 합성 데이터는 사전 학습을 위한 실제 데이터와 직교한다.
- Downstream-aware의 경우 CIFAR-100에서 240만/360만 개의 합성 데이터를 사용하였을 때 120만 개의 ImageNet-1K에서 사전 학습한 것보다 훨씬 뛰어난 성능을 발휘한다.
- Downstream-agnostic의 경우 120만 개의 ImageNet-1K에서 사전 학습한 것과 비슷한 결과를 얻었다. Self-supervised pre-training은 supervised pre-training보다 더 나은 성능을 발휘하며, ViT 기반 backbone은 convolution 기반 백본보다 성능이 더 좋다. 게다가 레이블 공간 크기를 늘리면 성능이 더욱 향상될 수 있다.