[논문리뷰] SweetDreamer: Aligning Geometric Priors in 2D Diffusion for Consistent Text-to-3D
ICLR 2024. [Paper] [Page]
Weiyu Li, Rui Chen, Xuelin Chen, Ping Tan
HKUST | Light Illusions | South China University of Technology | Tencent AI Lab
4 Oct 2023
Introduction
생성 모델은 입력 텍스트 프롬프트를 통해 고도로 제어 가능한 방식으로 다양하고 고품질의 이미지 생성한다. 이 놀라운 성과는 쌍을 이루는 텍스트-이미지 데이터의 광범위한 코퍼스에서 확장 가능한 생성 모델, 특히 diffusion model을 학습시킴으로써 달성되었다. 3D에서 이러한 성공을 재현하려면 현재 주목을 받고 있는 방대한 양의 고품질 텍스트-3D 쌍을 수집하기 위한 상당한 노력이 분명히 필요하다. 그러나 고품질 3D 콘텐츠 획득과 관련된 높은 비용을 고려할 때 매우 다양한 주제를 다루는 포괄적인 3D 데이터셋을 수집하는 데 필요한 노력이 훨씬 더 중요하다는 것은 분명하다.
텍스트 제어 3D 생성 모델에 대한 여러 연구가 있었으며 그 중 2D 리프팅 기술이 특히 유망한 방향으로 떠오르며 해당 분야에서 점점 더 추진력을 얻고 있다. 이 기술은 2D 결과를 3D로 끌어올리고 최적화 프레임워크를 사용한다. 여기서 3D 표현은 사전 학습된 2D diffusion model에서 파생된 Score Distillation Sampling (SDS) loss를 사용하여 미분 가능한 parameterization으로 업데이트된다. SDS를 다양한 3D 표현과 결합함으로써 이 기술은 사용자가 제공하는 다양한 텍스트 프롬프트들에 대한 충실도가 높은 3D 개체와 장면을 생성할 수 있다.
그러나 2D 관찰을 3D로 끌어올리는 것은 본질적으로 모호하다. 2D diffusion model은 개별 이미지로부터 2D prior 정보만 학습하므로 리프팅 중 명확성을 위한 3D 지식이 부족하여 멀티뷰 불일치 문제(ex. multi-face Janus problem)가 발생한다. 광범위하고 포괄적인 3D 데이터셋에서 강력한 3D prior를 학습하는 것이 정답인 것처럼 보이지만 실제로는 풍부하게 사용 가능한 이미지에 비해 3D 데이터가 부족하다. 따라서 현재 설득력 있는 방향은 상대적으로 제한된 3D 데이터에서 학습된 3D prior를 일반화 가능성이 높은 2D diffusion prior에 통합하여 2D와 3D의 장점을 모두 얻는 것이다.
특히, 멀티뷰 불일치와 관련된 문제는 주로 두 가지 유형으로 분류될 수 있다.
- 기하학적 구조의 공간 배열의 모호성으로 인해 발생하는 기하학적 불일치 문제, 즉 기하학적 구조는 3D에서 다르게 위치하고 다른 방향을 지정할 수 있다. 동일한 2D projection을 가지는 많은 비합리적인 3D 구조가 2D prior를 속이며, 3D 인식이 부족한 2D prior에 의한 supervision에 의해 리프팅 중에 형상(geometry) 불일치가 더욱 악화된다.
- 외형 불일치 문제는 기하학적 구조를 해당 외형으로 매핑할 때 모호함으로 인해 발생하며, 2D diffusion의 3D 인식 부족으로 인해 더욱 악화된다.
경험적으로 기하학적 불일치 문제는 기존의 다양한 방법에서 대부분의 멀티뷰 불일치 결과에 기여하는 주요 원인인 반면, 외형 불일치 문제는 극단적인 경우에만 나타나므로 중요성이 낮다. 이는 3D 불일치 결과의 대부분이 2D diffusion의 guidance에 따라 생성되는 반복적인 기하학적 구조(일반적으로 여러 개의 손 또는 얼굴)를 나타낸다는 사실에 의해 입증된다. 일관된 3D 형상의 기하학적 힌트를 포함하면 외형 모델링에 크게 도움이 되므로 잘못 배치된 구조를 해결하는 것이 최종 결과에서 3D 불일치를 완화하는 데 중요한 역할을 한다. 이는 형상과 외형이 동시에 업데이트되는 1단계 텍스트-3D 파이프라인과 형상과 외형을 별도로 모델링하는 파이프라인 모두에 적용된다. 그러나 외형 불일치가 일관된 기하학적 3D 구조로 나타날 수 있는 예외적인 상황이 여전히 있을 수 있다는 점도 인정해야 한다.
이러한 발견은 일반화 능력을 유지하면서 일관된 3D 기하학적 구조를 생성할 수 있는 능력을 2D prior에 장착함으로써 text-to-3D의 기하학적 불일치 문제를 우선적으로 해결하도록 동기를 부여했다. 저자들은 리프팅 중에 3D 데이터셋의 잘 정의된 3D 형상과 정렬되는 방식으로 diffusion model의 2D 기하학적 prior를 적용하여 원점에서 발생하는 대부분의 불일치 문제를 해결하였다. 정렬된 기하학적 prior를 AGP (Aligned Geometric Priors)라고 한다. 구체적으로, 2D diffusion model을 fine-tuning하여 객체의 좌표 맵을 생성함으로써 3D에서의 기하학적 분포를 명확하게 하고, 추가 카메라 사양에 따라 이를 추가로 조절하여 3D 인식을 부여한다. 특히, 3D 데이터셋의 형상 정보와 외형 정보에 크게 의존하는 방법들과 완전히 대조적으로, 본 논문은 원치 않는 inductive bias를 더 유발할 수 있는 기하학적 및 시각적 외형 디테일에 대한 과도한 의존을 피하면서 대략적인 기하학적 구조만 활용한다. 이러한 기하학적 prior의 대략적인 정렬을 통해 멀티뷰 불일치 문제 없이 3D 개체를 생성할 수 있을 뿐만 아니라 2D diffusion model의 능력을 유지하여 3D 데이터셋에서 볼 수 없는 생생하고 다양한 개체를 생성할 수 있다.
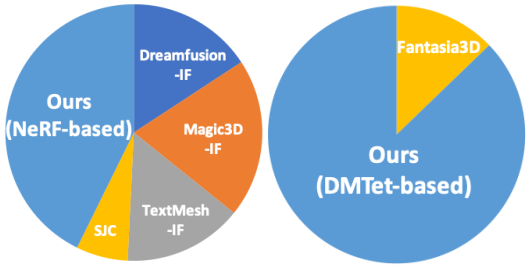
마지막으로 중요한 점은 AGP가 일반적으로 다른 방법들이 부족한 높은 호환성을 보유하고 있다는 것이다. AGP는 매우 일반적이며 다양한 3D 표현을 사용하여 다양한 SOTA 파이프라인에 원활하게 통합될 수 있으며, 처음 보는 형상 및 외형 측면에서 높은 일반화 가능성을 확보하는 동시에 멀티뷰 불일치를 크게 완화할 수 있다. AGP는 3D 일관성 비율이 85% 이상이며 새로운 SOTA를 달성하였다.
Method
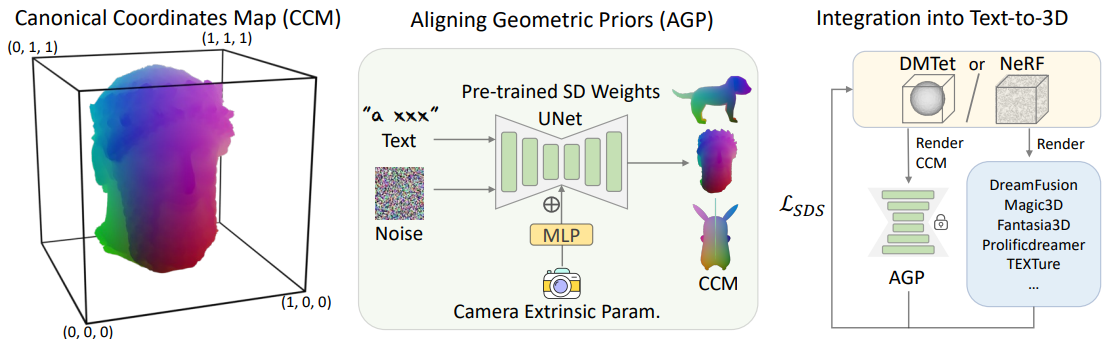
앞서 언급한 바와 같이 멀티뷰나 3D 불일치 문제는 3D에서 기하학적 구조가 잘못 배치되어 나타나는 기하학적 불일치 문제와 잘못된 시각적 외형 모델링과 관련된 외형 불일치 문제라는 두 가지 관점에서 분류할 수 있다. 기하학적 불일치가 대부분의 3D 불일치 결과의 주요 원인이므로 본 논문의 목표는 2D prior에 일반화 능력을 유지하면서 일관된 3D 기하학적 구조를 생성할 수 있는 능력을 갖추는 것이다. 결과적으로 생성된 일관적인 기하학적 구조는 text-to-3D 파이프라인에서 복잡한 기하학적 디테일과 시각적 외형을 모델링하는 데 중요한 역할을 한다.
이를 위해 3D 데이터셋의 잘 정의된 3D 형상과 일치하는 방식으로 2D diffusion의 기하학적 prior를 보장한다. 특히, 표준 지향적이고 정규화된 광범위하고 다양한 3D 모델로 구성된 3D 데이터셋에 액세스할 수 있다고 가정한다. 그런 다음 랜덤 뷰에서 깊이 맵을 렌더링하고 이를 표준 좌표 맵으로 변환한다. 단지 기하학적 디테일을 생성하기보다는 정렬을 위해 3D 데이터를 사용하는 것이기 때문에 다소 대략적인 기하학적 구조에서만 렌더링한다. 이러한 3D 데이터를 사용하면 두 가지 이점이 있다.
- 모든 형상이 3D로 잘 정의되어 있으므로 공간 배열에 모호함이 없다.
- 시점을 모델에 추가로 주입함으로써 시점 인식과 궁극적으로 3D 인식을 부여할 수 있다.
그런 다음 2D diffusion model fine-tuning하여 지정된 뷰에서 표준 좌표 맵을 생성하고 결국 2D diffusion의 기하학적 prior를 정렬한다. 마지막으로, 정렬된 기하학적 prior (AGP)는 다양한 text-to-3D 파이프라인에 원활하게 통합되어 불일치 문제를 크게 완화하여 고품질의 다양한 3D 콘텐츠를 생성할 수 있다. 위 그림은 개요를 보여준다.
1. Alignning geometric priors in 2d diffusion
Canonical Coordinates Map (CCM)
모델링을 용이하게 하기 위해 동일한 카테고리 내의 모든 객체가 공개적으로 액세스할 수 있는 다양한 데이터셋에서 학습 데이터의 표준 방향을 준수한다고 가정한다. 객체의 방향은 카테고리별로 표준화된 것으로 가정하지만, 본 논문의 목표는 카테고리별 데이터 사전 학습이 아니다. 대신, 본 논문의 목표는 3D 데이터셋의 다양한 객체에서 일반적인 지식을 추출하여 2D 기하학적 prior를 정렬하는 데 도움이 되도록 하는 것이다. 표준 객체 공간은 단위 입방체 \(\{x, y, z\} \in [0, 1]\) 내에 포함된 3D 공간으로 정의된다. 구체적으로, 객체가 주어지면 단단한 bounding box의 최대 범위가 길이가 1이고 원점 중심에 오도록 객체의 크기를 균일하게 조정하여 크기를 정규화한다. 학습을 위해 정규적으로 방향이 지정되고 균일하게 정규화된 객체로부터 랜덤 뷰로 좌표 맵을 렌더링할 수 있지만, 객체에서 렌더링된 좌표 맵의 세 구성 요소를 이방성(anisotropic)으로 스케일링하여 각 구성 요소의 값이 0과 1 사이의 범위 내에 있도록 한다. 이 이방성 정규화는 다양한 시점에서 얇은 구조의 공간 좌표 불일치를 증폭시켜 3D 구조에 대한 인식을 용이하게 하고 후속 학습에서 3D 인식을 향상시킨다.
Camera Condition
표준 좌표 맵에는 대략적인 시점 정보가 포함되어 있지만 diffusion model에서는 이를 활용하는 데 어려움이 있다. 따라서 MVDream을 따라 시점 인식을 향상시키기 위해 카메라 정보를 모델에 주입한다. 구체적으로, 카메라의 extrinsic parameter를 diffusion model에 명시적으로 입력한다. 이 파라미터는 diffusion model의 중간 레이어에 공급되기 전에 MLP를 통과한다. 일관된 3D 객체를 생성하기 위해 정확한 시점 인식에 의존하는 다른 모델과 달리, 본 논문의 모델에서 카메라 조건을 사용하는 것은 나중에 일관된 3D 개체로 발전할 대략적인 형상을 대략적으로 생성하는 것뿐이다.
Fine-tuning 2D Diffusion for Alignment
표준 좌표 맵 쌍과 해당 카메라 사양이 주어지면 2D diffusion model의 아키텍처를 유지하면서 카메라 extrinsic parameter로 컨디셔닝되도록 약간 조정한다. 이를 통해 사전 학습된 2D diffusion model을 transfer learning에 활용할 수 있으므로 3D 데이터셋에서 볼 수 없는 매우 다양한 주제에 대한 일반화 능력을 상속받을 수 있다. 마지막으로 원래 RGB 이미지 또는 latent 이미지를 생성하기 위해 의도된 diffusion model을 fine-tuning하여 시점 조건 하에서 표준 좌표 맵을 생성하고 결국 2D diffusion의 기하학적 prior를 정렬한다.
Implementation Details
기본적으로 저자들은 일반적으로 사용되는 사전 학습된 text-to-image diffusion model인 Stable Diffusion v2.1을 기반으로 실험을 수행하였다.
3D 데이터셋: 저자들은 아티스트가 만든 약 80만 개의 모델이 포함된 공개 3D 데이터셋인 Objaverse를 사용하여 fine-tuning을 위한 데이터를 생성하였다. 특히 좌표계에 대한 명시적인 사양은 없지만 많은 아티스트는 여전히 3D 에셋을 만들 때 방향에 관한 규칙을 고수한다. 따라서 3D 객체의 상당 부분은 표준 방향을 유지하고 방향이 잘못된 객체가 소수만 있으며, 잘못된 방향을 수동으로 수정할 필요 없이 만족스러운 결과를 얻을 수 있다. 반면, 텍스트 주석에 상당한 잡음이 존재하기 때문에 저자들은 3D 캡션 모델을 사용하여 각 3D 에셋의 텍스트 설명을 보강하고 학습 중에 증강된 캡션과 원본 텍스트 주석 사이를 무작위로 전환하였다. 또한 관련성을 보장하기 위해 태그 기반 필터링 프로세스를 적용하여 포인트 클라우드나 low poly model과 같은 3D 에셋을 제거하여 약 27만 개의 개체를 생성하였다.
카메라 샘플링: 3D 개체에서 표준 좌표 맵을 렌더링한다. 카메라는 0.9 ~ 1.1 범위의 거리에 무작위로 배치되며 시야는 45도로 설정되었다. 또한 카메라의 고도는 -10도에서 45도 사이에서 무작위로 변경되었다. 시각적 외형 정보에 의존하지 않기 때문에 학습 데이터 생성을 위해 빠른 rasterization renderer를 활용하여 ray tracing renderer와 관련된 계산을 피할 수 있다.
학습: 저자들은 Stable Diffusion의 latent space에서 모델을 fine-tuning한다. 표준 좌표 맵은 latent diffusion model에 대한 latent 이미지로 직접 처리된다. 이는 VAE의 인코딩 및 디코딩 프로세스를 포함하지 않고 AGP를 빠르게 학습할 수 있다는 매력적인 feature로 이어진다. 기본 최적화 설정과 $\epsilon$-prediction을 유지한다. 카메라 extrinsic parameter를 diffusion model의 조건으로 입력했기 때문에 목적 함수는 이제 다음과 같다.
\[\begin{equation} \mathcal{L}_\textrm{LDM} := \mathbb{E}_{c, y, z, t, \epsilon \in \mathcal{N}(0, 1)} [\| \epsilon - \epsilon_\theta (c, \tau_\theta (y), z_t, t) \|_2^2] \end{equation}\]여기서 $c$는 카메라의 extrinsic parameter, $y$는 입력 텍스트 프롬프트, $\tau_\theta (y)$는 토크나이저를 사용하여 임베딩된 feature, $z_t$는 timestep $t$에서 깨끗한 latent $z$에 noise $\epsilon$을 추가하여 생성된 noisy latent이다.
2. Integration into Text-to-3D
다양한 3D 표현을 사용하여 AGP를 기존 파이프라인에 통합하면 불일치 문제를 크게 완화하고 SOTA text-to-3D 성능을 달성할 수 있다. 이러한 호환성을 보여주기 위해 저자들은 서로 다른 3D 표현을 활용하는 두 가지 SOTA text-to-3D 방법을 사용하였다.
- 형상과 모양 모델링을 명시적으로 분리하고 기본 표현에 하이브리드 표현 DMTet을 사용하는 Fantasia3D
- 3D 형상과 NeRF를 3D 표현으로 사용하는 DreamFusion
위 그림은 AGP를 이 두 가지 방법에 통합하는 시스템 파이프라인이다.
DMTet-based Pipeline
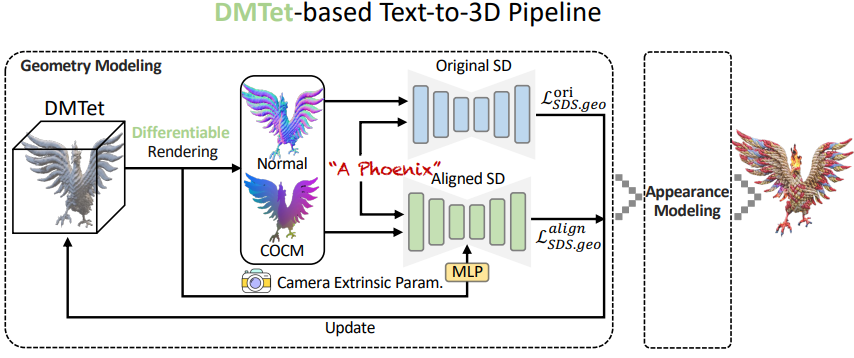
저자들은 AGP를 DMTet 기반 파이프라인인 Fantasia3D에 통합하였다. 필요한 것은 원래 파이프라인에서 형상 모델링을 supervise하기 위해 AGP를 통합하기 위한 추가 병렬 분기이다. AGP의 원활한 통합을 통해 원래 파이프라인에서처럼 신중하게 설계된 초기화 외형 필요 없이 고품질 및 뷰 일관성이 있는 결과를 쉽게 얻을 수 있다.
최적화: 구체적으로, 대략적인 형상 모델링 단계와 세밀한 형상 모델링 단계 모두에서 AGP에 의한 추가 supervision을 추가한다. 간단히 말해서 정렬된 diffusion model은 표준 좌표 맵을 입력으로 사용하고 SDS loss를 생성하여 3D 표현을 업데이트한다. 그러면 형상 모델링의 최종 loss는 다음과 같다.
\[\begin{equation} \mathcal{L}_{\textrm{SDS} \cdot \textrm{geo}} = \lambda^\textrm{ori} \mathcal{L}_{\textrm{SDS} \cdot \textrm{geo}}^\textrm{ori} + \lambda^\textrm{align} \mathcal{L}_{\textrm{SDS} \cdot \textrm{geo}}^\textrm{align} \end{equation}\]여기서 첫 번째 항은 원래 diffusion model에서 파생된 geometry SDS loss이고, 두 번째 항은 AGP에서 파생된 SDS loss이다. 여기서 $\lambda^\textrm{ori}$와 $\lambda^\textrm{align}$은 두 항의 균형을 맞추기 위한 가중치이다. 이 통합은 대략적인 형상 모델링 단계와 세밀한 형상 모델링 단계에서만 구현되고 외형 모델링 단계는 그대로 유지된다.
NeRF-based Pipeline
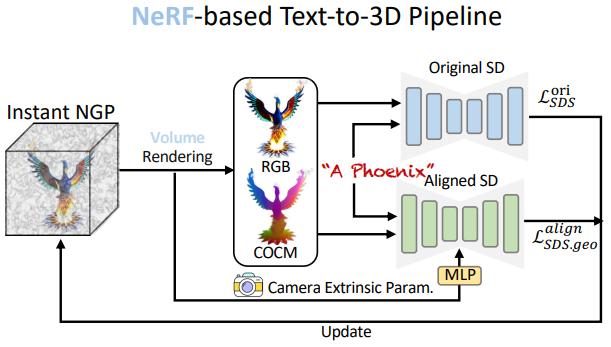
NeRF는 text-to-3D의 3D 표현을 위한 또 다른 일반적인 선택이다. 기존의 이산적인 메쉬에 비해 최적화에 더 친숙하고 뛰어난 사실성을 위해 볼륨 렌더링과 결합할 수도 있기 때문이다. 구체적으로 저자들은 NeRF를 3D 표현으로 사용하고 이를 NeRF 기반 파이프라인인 DreamFusion을 기반으로 하였다. 특히, 3D 장면은 환경 맵 모델링을 위한 추가 MLP가 포함된 Instant-NGP로 표현되므로 낮은 컴퓨팅 비용으로 풍부한 디테일의 모델링이 가능하다. 그런 다음 3D 개체/장면을 볼륨 렌더링하여 RGB 이미지를 얻고 이를 Stable Diffusion에 공급하여 SDS loss를 계산할 수 있다.
최적화: 리프팅 최적화 중에 표준 좌표 맵을 렌더링하고, RGB 이미지로 계산된 원래 SDS loss \(\mathcal{L}_\textrm{SDS}\) 외에도 NeRF의 형상 분기를 업데이트하는 데 도움이 되는 geometry SDS loss \(\mathcal{L}_{\textrm{SDS} \cdot \textrm{geo}}^\textrm{align}\)를 계산하기 위해 AGP에 표준 좌표 맵을 공급한다. 최종 loss는 다음과 같다.
\[\begin{equation} \mathcal{L}_\textrm{SDS} = \lambda^\textrm{ori} \mathcal{L}_\textrm{SDS}^\textrm{ori} + \lambda^\textrm{align} \mathcal{L}_\textrm{SDS}^\textrm{align} \end{equation}\]여기서 $\lambda^\textrm{ori}$와 $\lambda^\textrm{align}$은 두 항의 균형을 맞추기 위한 가중치이다. AGP는 이 파이프라인에서 일관되고 대략적인 형상을 모델링하며 외형 모델링은 그대로 유지한다.
Text-to-3D Generation
다음은 다양한 텍스트 프롬프트로부터 생성한 다양한 고품질 3D 결과들이다.

Quantitative Evaluation
다음은 여러 모델들과 3D 일관성 비율에 대하여 정량적으로 비교한 결과이다.

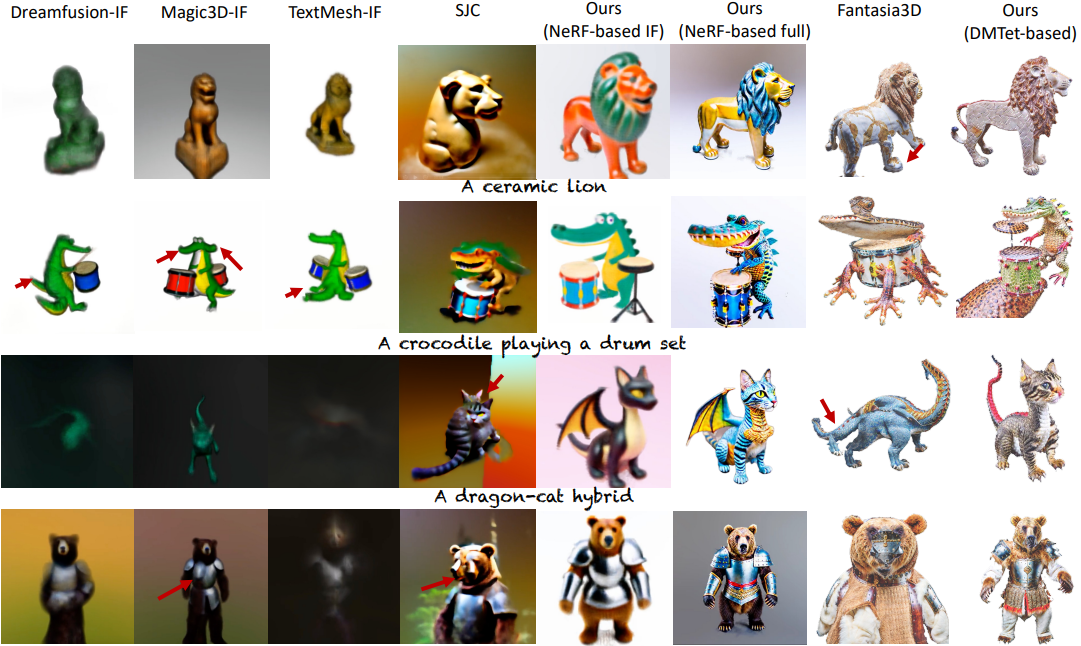
Qualitative Evaluation
다음은 여러 모델들과 시각적으로 비교한 결과이다.
User Study
다음은 user study 결과이다.