[논문리뷰] SVDiff: Compact Parameter Space for Diffusion Fine-Tuning
arXiv 2023. [Paper] [Github]
Ligong Han, Yinxiao Li, Han Zhang, Peyman Milanfar, Dimitris Metaxas, Feng Yang
Rutgers University | Google Research
20 Mar 2023
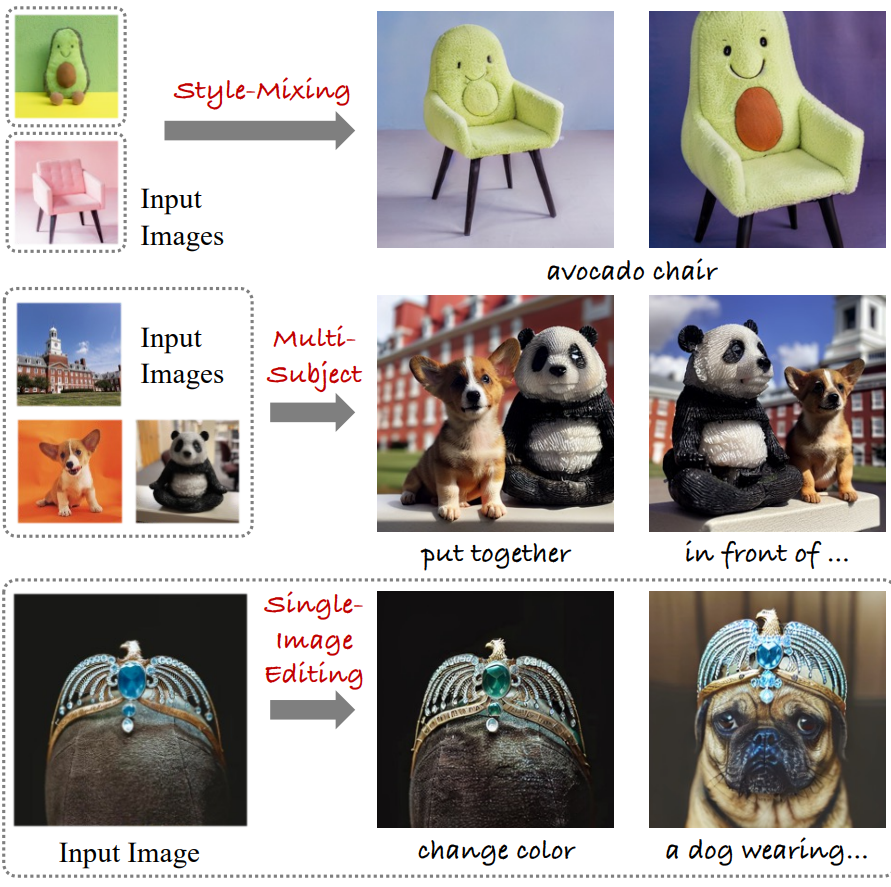
Introduction
최근 몇 년 동안 간단한 텍스트 프롬프트를 통해 고품질 이미지를 생성할 수 있는 diffusion 기반 text-to-image 생성 모델의 급속한 발전이 있었다. 이러한 모델은 놀라운 사실성과 다양성을 지닌 다양한 개체, 스타일 및 장면을 생성할 수 있다. 뛰어난 결과를 제공하는 이 모델은 연구자들이 이미지 편집을 위한 능력을 활용할 수 있는 다양한 방법을 조사하도록 영감을 주었다.
모델의 개인화와 커스텀화를 추구하면서 Textual-Inversion, DreamBooth. Custom Diffusion과 같은 일부 최근 연구들은 대규모 text-to-image diffusion model의 잠재력을 더욱 발휘했다. 사전 학습된 모델의 파라미터를 fine-tuning함으로써 이러한 방법을 통해 diffusion model을 특정 task 또는 개별 사용자 선호도에 맞게 조정할 수 있다.
유망한 결과에도 불구하고 대규모 text-to-image diffusion model을 fine-tuning하는 것과 관련된 몇 가지 제한 사항이 여전히 있다. 한 가지 제한 사항은 파라미터 공간이 커서 overfitting 또는 원래의 일반화 능력에서 벗어나는 결과를 초래할 수 있다는 것이다. 또 다른 문제는 특히 유사한 카테고리에 속할 때 여러 개인화된 개념을 학습하는 데 어려움이 있다는 것이다.
본 논문은 overfitting을 완화하기 위해 GAN 연구들의 효율적인 파라미터 공간에서 영감을 얻어 모델의 가중치 행렬의 특이값만 fine-tuning함으로써 diffusion model에 대한 컴팩트하면서도 효율적인 파라미터인 spectral shift를 제안한다. 이 접근법은 학습 가능한 파라미터의 공간을 제한하면 대상 도메인에서 성능이 향상될 수 있음을 보여주는 GAN 적응의 이전 연구들에서 영감을 받았다. 널리 사용되는 다른 low-rank 제약 조건과 비교하여 spectral shift는 가중치 행렬의 전체 표현력을 활용하면서 더 작다 (ex. Stable Diffusion의 경우 1.7MB, 전체 가중치 체크포인트는 3.66GB의 스토리지를 사용). 컴팩트한 파라미터 공간을 통해 특히 prior-preservation loss가 적용되지 않는 경우 overfitting 및 language-drifting 문제를 해결할 수 있다.
본 논문은 여러 개인화된 개념을 학습하는 모델의 능력을 더욱 향상시키기 위해 간단한 Cut-Mix-Unmix data augmentation 기술을 제안한다. 이 기술은 제안된 spectral shift 파라미터 공간과 함께 의미적으로 유사한 카테고리에 대해서도 여러 개인화된 개념을 학습할 수 있다.
Method
1. Preliminary
Diffusion models
Stable Diffusion은 latent diffusion model (LDM)의 변형이다. LDM은 입력 이미지 $x$를 인코더 $\mathcal{E}$를 통해 latent code $z$로 변환한다. 여기서 $z = \mathcal{E}(x)$이고 latent space $Z$에서 noise 제거 프로세스를 수행한다. 간단히 말해서 LDM \(\hat{\epsilon}_\theta\)는 denoising 목적 함수로 학습된다.
\[\begin{equation} \mathbb{E}_{z, c, \epsilon, t} [\| \hat{\epsilon}_\theta (z_t \vert c, t) - \epsilon \|_2^2 ] \\ \epsilon \sim \mathcal{N}(0, I), \quad t \sim \textrm{Uniform} (1, T) \end{equation}\]여기서 $(z, c)$는 데이터 조건 쌍(이미지 latent와 텍스트 임베딩)이다. 간결함을 위해 $t$를 생략한다.
Few-shot adaptation in compact parameter space of GANs
FSGAN의 방법은 특이값 분해 (Singular Value Decomposition, SVD)를 기반으로 하며, few-shot 설정에서 GAN을 적응시키는 효과적인 방법을 제안한다. GAN의 파라미터 공간에서 도메인 적응을 위한 컴팩트한 업데이트를 학습하기 위해 SVD를 활용한다. 특히 FSGAN은
\[\begin{equation} W_\textrm{tensor} \in \mathbb{R}^{c_\textrm{out} \times c_\textrm{in} \times h \times w} \end{equation}\]형태인 GAN의 컨볼루션 커널을
\[\begin{equation} W = \textrm{reshape} (W_\textrm{tensor}) \in \mathbb{R}^{c_\textrm{out} \times (c_\textrm{in} \times h \times w)} \end{equation}\]형태인 2D 행렬 $W$로 재구성한다. 그런 다음 FSGAN은 사전 학습된 GAN의 generator와 discriminator 모두의 이러한 재구성된 가중치 행렬에 대해 SVD를 수행하고 표준 GAN 목적 함수를 사용하여 특이값을 새 도메인에 적용한다.
2. Compact Parameter Space for Diffusion Fine-tuning
Spectral shifts
핵심 아이디어는 FSGAN에서 diffusion model의 파라미터 공간으로의 spectral shift 개념을 도입하는 것이다. 이를 위해 사전 학습된 diffusion model의 가중치 행렬에 대해 SVD를 먼저 수행한다. 가중치 행렬을 $W$로 표시하면 그 SVD는 $W = U \Sigma V^\top$이며, 여기서 $\Sigma = \textrm{diag}(\sigma)$이고 $\sigma = [\sigma_1, \sigma_2, \cdots]$는 내림차순 특이값이다. SVD는 일회성 계산이며 캐싱될 수 있다. 이 절차는 아래 그림에서 설명되어 있다.
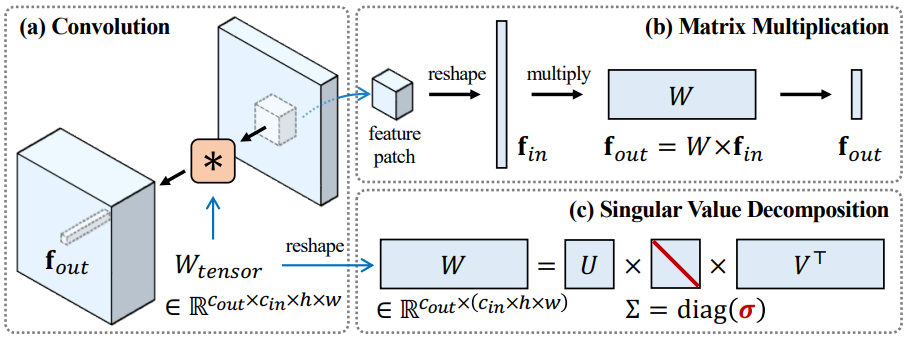
패치 레벨 convolution은 행렬 곱셈 \(f_\textrm{out} = W f_\textrm{in}\)으로 표현될 수 있다. 여기서 $f_\textrm{in} \in \mathbb{R}^{(c_\textrm{in} \times h \times w) \times 1}$은 flatten된 패치 feature이고 $f_\textrm{out} \in \mathbb{R}^{c_\textrm{out}}$은 주어진 패치의 pre-activation feature 출력이다. 직관적으로 spectral shift의 최적화는 특이 벡터가 고유값 문제의 닫힌 형식의 해에 해당한다는 사실을 활용한다.
전체 가중치 행렬을 fine-tuning하는 대신 업데이트된 가중치 행렬과 원래 가중치 행렬의 특이값 간의 차이로 정의되는 spectral shift $\delta$를 최적화하여 가중치 행렬만 업데이트한다. 업데이트된 가중치 행렬은 다음에 의해 재조립될 수 있다.
\[\begin{equation} W_\delta = U \Sigma_\delta V^\top\\ \Sigma_\delta = \textrm{diag} (\textrm{ReLU} (\sigma + \delta)) \end{equation}\]Training loss
Fine-tuning은 가중된 prior-preservation loss와 함께 diffusion model 학습에 사용된 것과 동일한 loss function을 사용하여 수행된다.
\[\begin{equation} \mathcal{L} (\delta) = \mathbb{E}_{z^\ast, c^\ast, \epsilon, t} [\| \hat{\epsilon}_\theta (z_t^\ast \vert c^\ast) - \epsilon \|_2^2] + \lambda \mathcal{L}_\textrm{pr} (\delta) \mathcal{L}_\textrm{pr} (\delta) = \mathbb{E}_{z^\textrm{pr}, c^\textrm{pr}, \epsilon, t} [\| \hat{\epsilon}_{\theta_\delta} (z_t^\textrm{pr} \vert c^\textrm{pr}) - \epsilon \|_2^2 ] \end{equation}\]여기서 $(z^\ast, c^\ast)$는 모델이 적응되는 타겟 데이터 조건 쌍을 나타내고 $(z^\textrm{pr}, c^\textrm{pr})$은 사전 학습된 모델에 의해 생성된 prior 데이터 조건 쌍을 나타낸다. 이 loss function은 GAN에 대한 Model Rewriting에서 제안한 것을 diffusion model의 컨텍스트로 확장하며 prior-preservation loss는 smoothing 항으로 사용된다. Prior-preservation loss를 활용할 수 없는 단일 이미지 편집의 경우 $\lambda = 0$으로 설정한다.
Combining spectral shifts
또한 개별적으로 학습된 spectral shift를 새로운 모델에 결합하여 새로운 렌더링을 생성할 수 있다. 이를 통해 보간, style mixing, 다중 개체 생성 등을 포함한 애플리케이션을 사용할 수 있다. 여기서 저자들은 덧셈과 보간이라는 두 가지 일반적인 전략을 고려하였다. $\delta’$에 $\delta_1$과 $\delta_2$을 더하기 위해 다음 식을 사용한다.
\[\begin{equation} \Sigma_{\delta'} = \textrm{diag} (\textrm{ReLU} (\sigma + \delta_1 + \delta_2)) \end{equation}\]또한 다음과 같이 $0 \le \alpha \le 1$로 두 모델 사이를 보간한다.
\[\begin{equation} \Sigma_{\delta'} = \textrm{diag} (\textrm{ReLU} (\sigma + \alpha \delta_1 + (1 - \alpha) \delta_2)) \end{equation}\]이를 통해 모델 간의 원활한 전환이 가능하고 서로 다른 이미지 스타일 간에 보간할 수 있다.
3. Cut-Mix-Unmix for Multi-Subject Generation
Stable Diffusion 모델을 여러 개념으로 동시에 학습한 경우, 모델이 어려운 구성이나 유사한 카테고리의 주제에 대해 하나의 이미지로 렌더링할 때 스타일을 혼합하는 경향이 있다. 본 논문은 개인화된 스타일을 혼합하지 않도록 모델을 명시적으로 안내하기 위해 Cut-Mix-Unmix라는 간단한 기술을 제안한다.
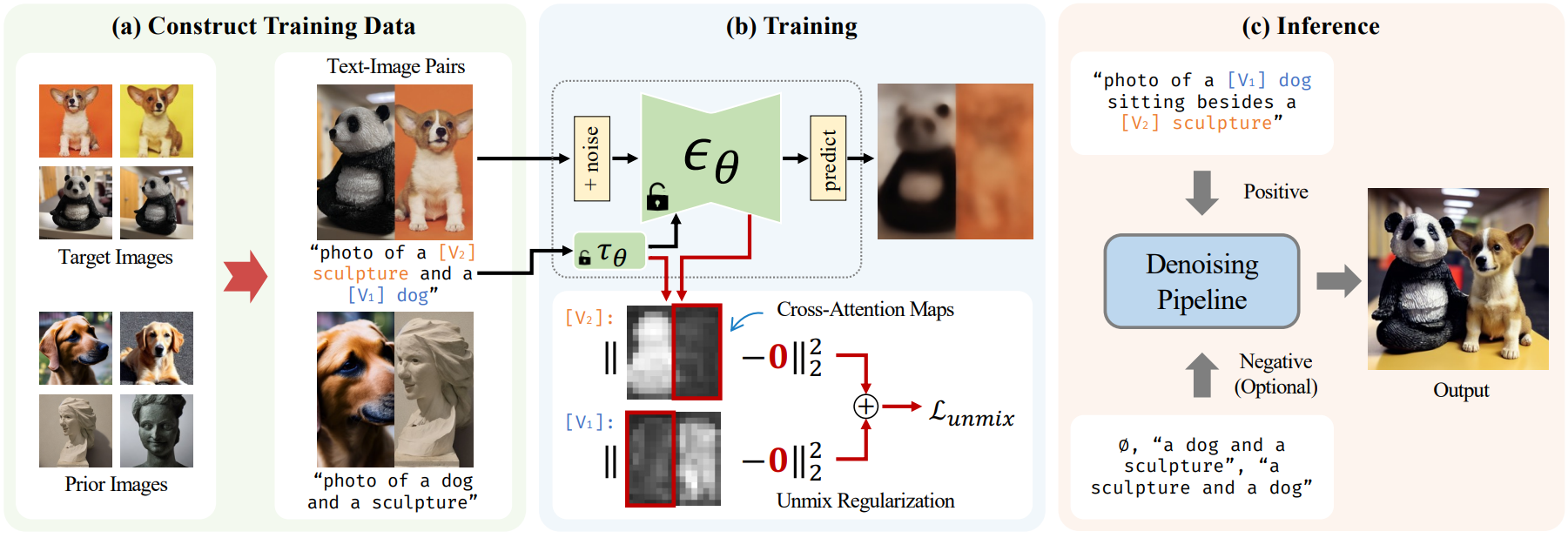
“올바르게” 잘라서 혼합한 이미지 샘플로 모델을 구성하고 제시함으로써 모델이 스타일을 혼합하지 않도록 지시한다. 이 방법에서는 CutMix와 비슷한 이미지 샘플과 해당 프롬프트를 수동으로 생성한다.
예시:
- “photo of a [$V_1$] dog on the left and a [$V_2$] sculpture on the right”
- “photo of a [$V_2$] sculpture and a [$V_1$] dog”
Prior loss 샘플은 유사한 방식으로 생성된다. 학습 중에 Cut-Mix-Unmix는 미리 정의된 확률 (일반적으로 0.6)로 적용된다. 이 확률을 1로 설정하면 모델이 주제를 구분하기 어려워지기 때문에 1로 설정되지 않는다. Inference하는 동안 학습 중에 사용된 것과 다른 프롬프트를 사용한다.
“a [$V_1$] dog sitting beside a [$V_2$] sculpture”
그러나 모델이 Cut-Mix-Unmix 샘플에 overfitting되는 경우 다른 프롬프트를 사용해도 아티팩트가 있는 샘플을 생성할 수 있다.
또한 cross-attention map에 “unmix” 정규화를 통합하여 fine-tuning 접근 방식을 확장한다. 두 주제 사이의 분리를 강화하기 위해 cross-attention map의 대응하지 않는 영역에서 MSE를 사용한다. 이 loss는 각 주제의 특수 토큰이 해당 주제에게만 집중하도록 한다. 이 확장의 결과로 아티팩트가 상당한 감소한다.
4. Single-Image Editing
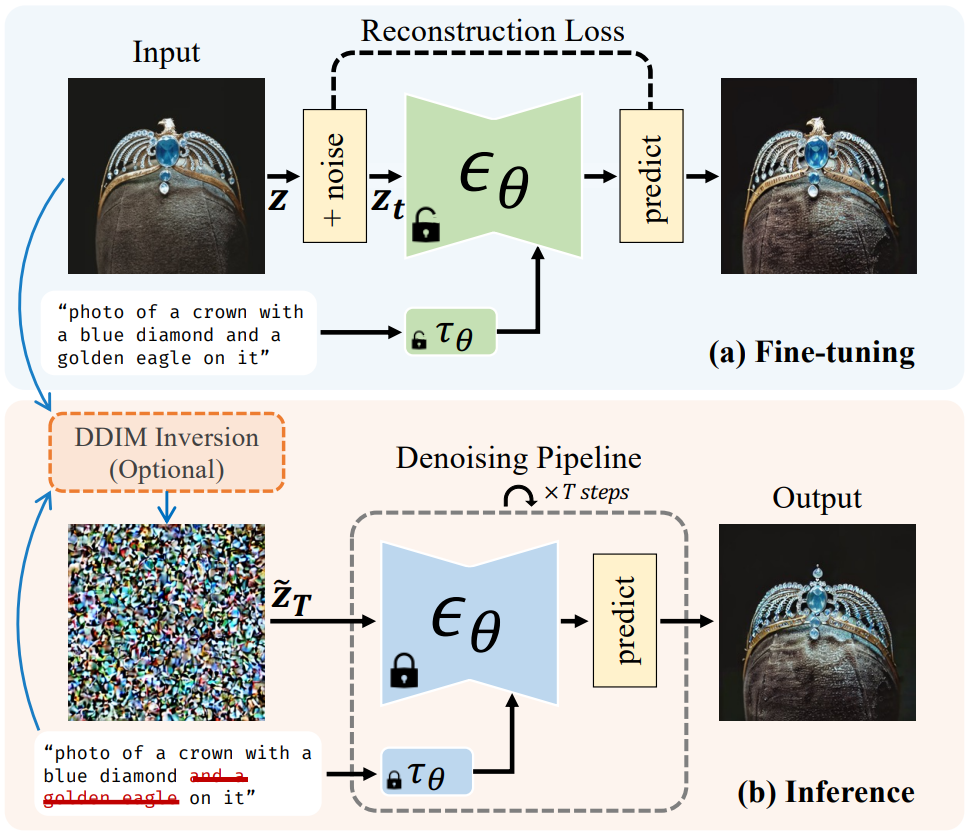
본 논문은 이미지-프롬프트 쌍으로 diffusion model을 fine-tuning하는 CoSINE (Compact parameter space for SINgle image Editing)이라는 단일 이미지 편집을 위한 프레임워크를 제시하였다. CoSINE의 절차는 위 그림에 요약되어 있다. 원하는 편집은 프롬프트를 수정하여 inference 시에 얻을 수 있다. Fine-tuning 중에 overfitting을 완화하기 위해 CoSINE은 전체 가중치 대신 spectral shift 파라미터 공간을 사용하여 overfitting과 language drifting의 위험을 줄인다. CoSINE의 목적은 정확한 재구성보다는 보다 유연한 편집을 가능하게 하는 것이다.
큰 구조적 변경이 필요하지 않은 편집의 경우 DDIM inversion으로 결과를 개선할 수 있다. 샘플링 전에 classifier-free guidance 1로 타겟 텍스트 프롬프트 $c$로 컨디셔닝된 DDIM inversion을 실행하고 입력 이미지 $z^\ast$를 latent noise map으로 인코딩한다.
\[\begin{equation} z_T = \textrm{DDIMInvert} (z^\ast, c; \theta') \end{equation}\]$\theta’$은 fine-tuning된 모델의 파라미터이며, 위 식에서 inference 파이프라인이 시작된다. 예상대로 큰 구조적 변화는 denoising process에서 더 많은 noise를 주입해야 할 수 있다. 여기서 저자들은 두 가지 유형의 noise 주입을 고려하였다.
- DDIM에서 $\eta > 0$로 설정
- Spherical linear interpolation으로 $z_T$와 랜덤 noise $\epsilon \sim \mathcal{N} (0, I)$ 사이를 보간한다.
두 번째의 경우는 다음과 같이 계산된다.
\[\begin{equation} \tilde{z}_T = \textrm{slerp} (\alpha, z_T, \epsilon) = \frac{\sin ((1- \alpha) \phi)}{\sin (\phi)} z_T + \frac{\sin (\alpha \phi)}{\sin (\phi)} \epsilon \\ \textrm{where} \quad \phi = \textrm{arccos } (\cos (z_T, \epsilon)) \end{equation}\]Fine-tuning 기반 단일 이미지 편집에서 overfitting과 language drifting을 해결하기 위해 Imagic과 같은 다른 접근 방식이 제안되었다. Imagic은 입력 이미지와 타겟 텍스트 설명에 대한 diffusion model을 fine-tuning한 다음 최적화된 텍스트 임베딩과 타겟 텍스트 임베딩 사이를 보간하여 overfitting을 방지한다. 그러나 Imagic은 테스트 시에 각 타겟 텍스트 프롬프트를 fine-tuning해야 한다.
Experiment
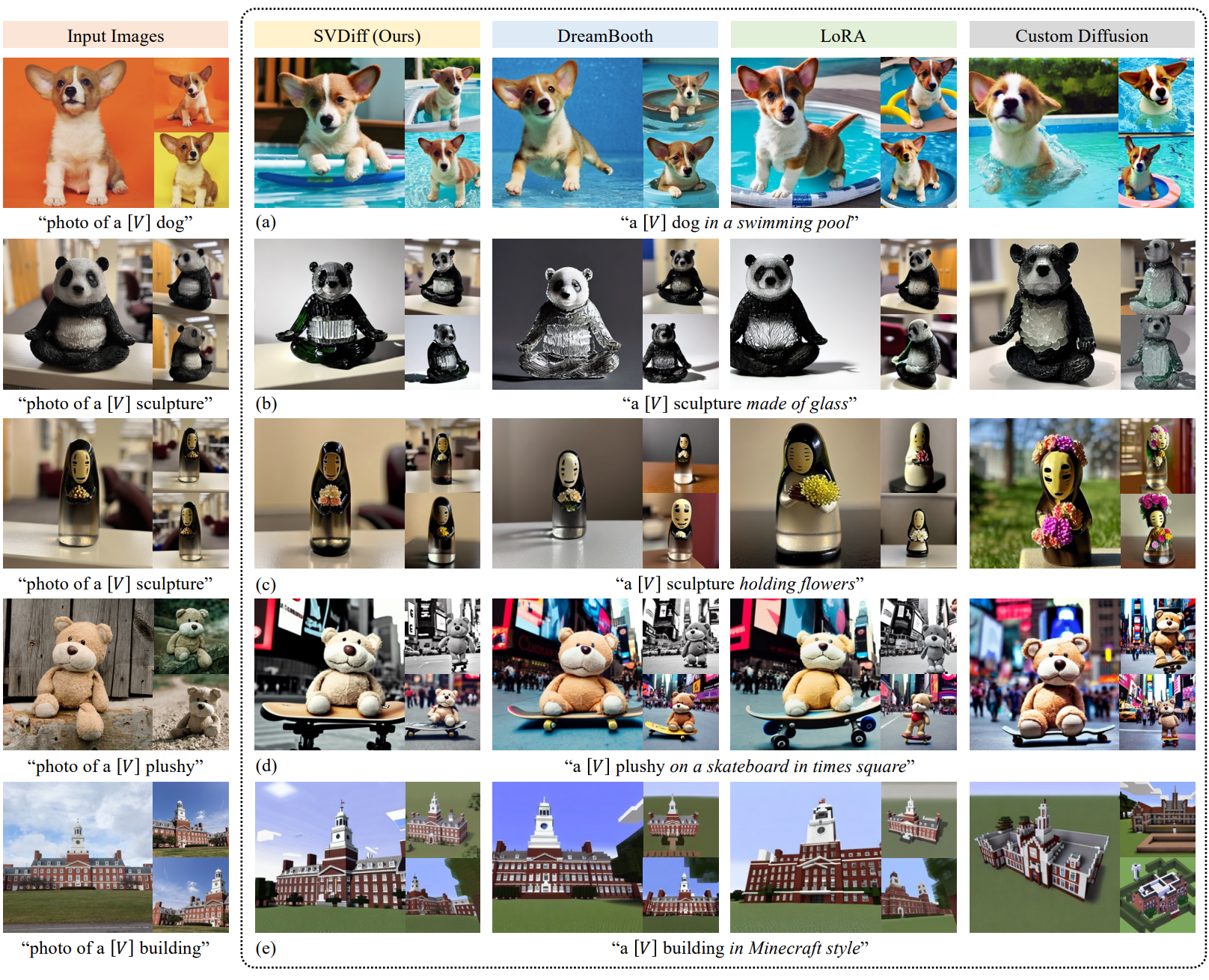
1. Single-Subject Generation
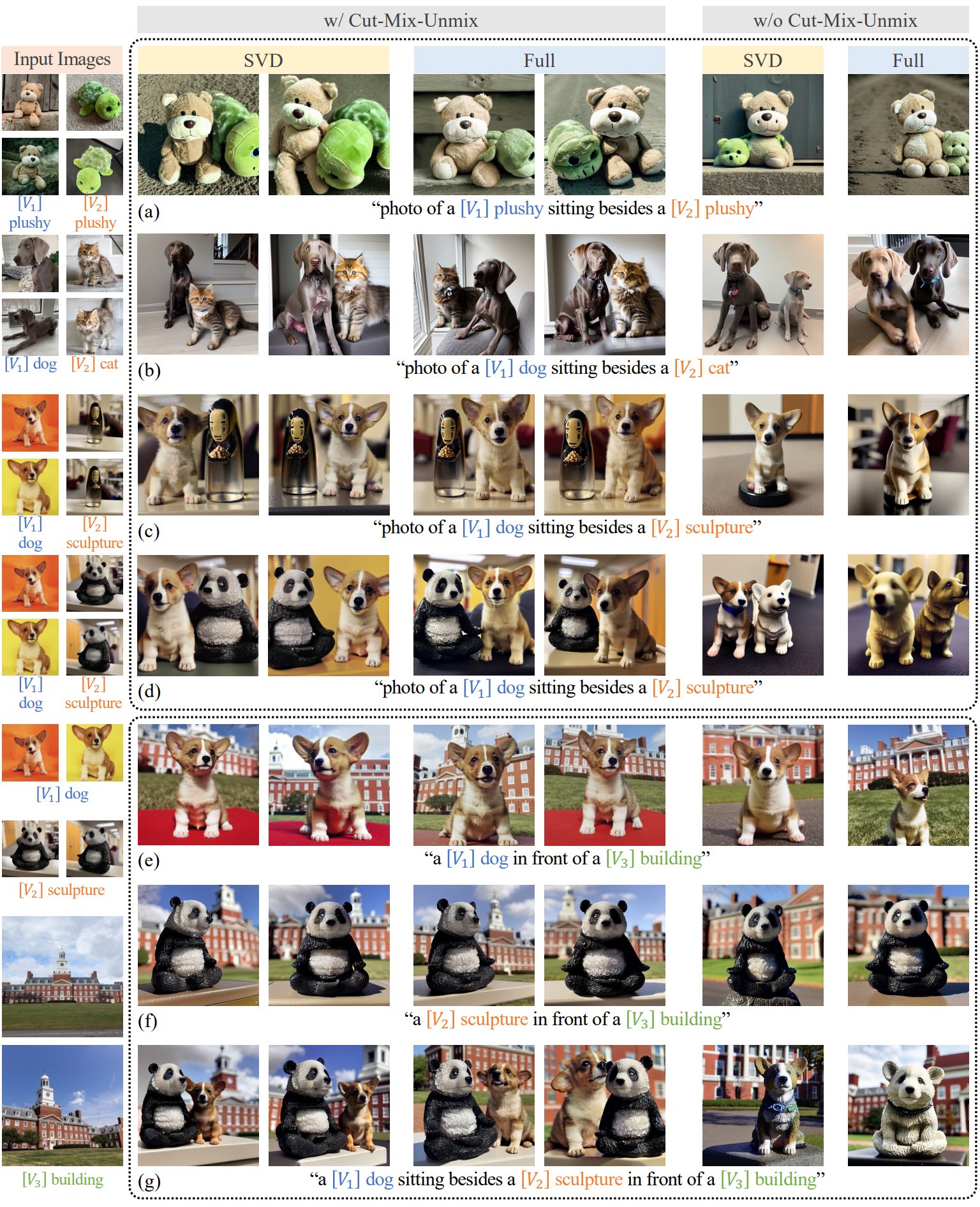
2. Multi-Subject Generation
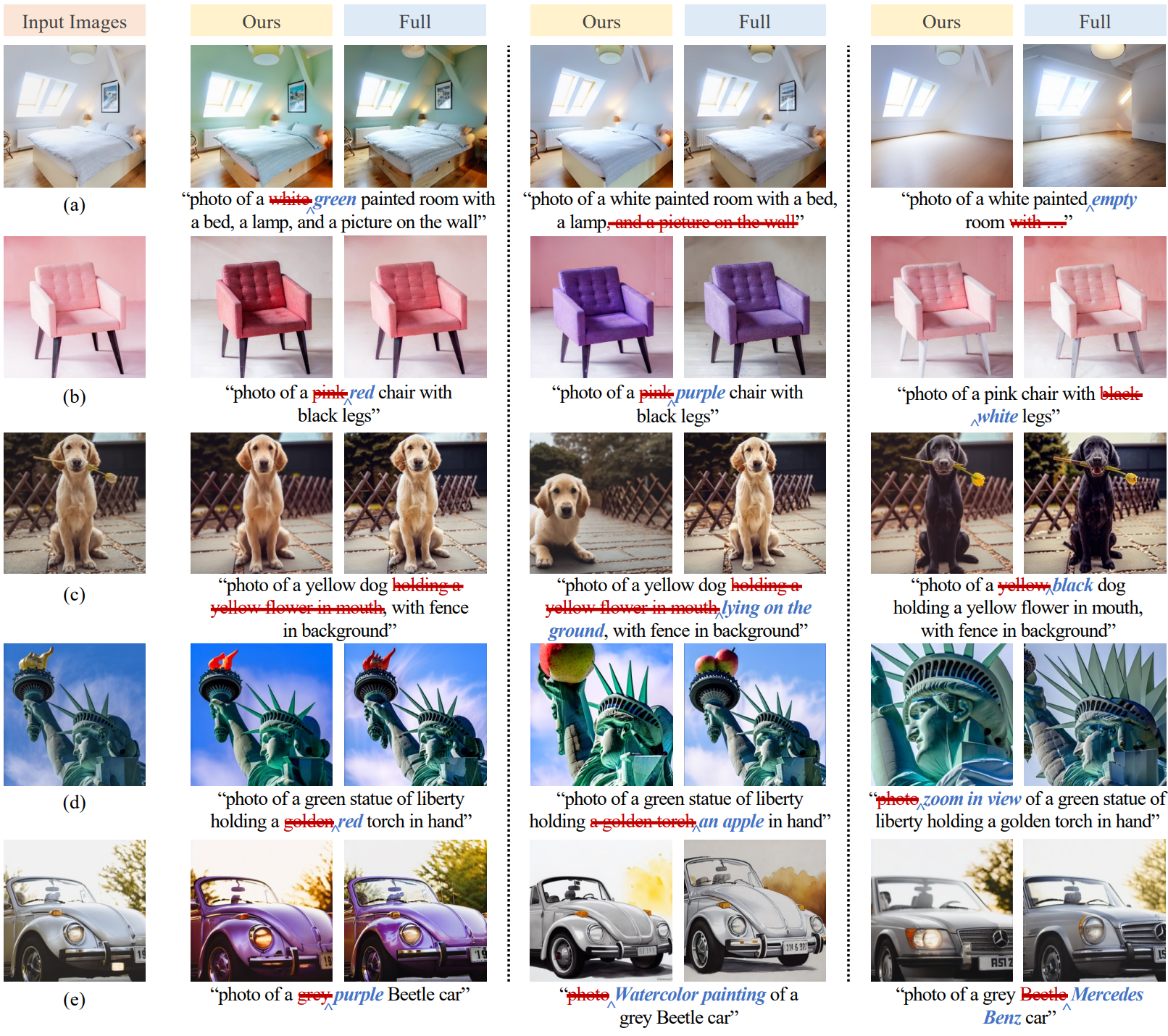
3. Single Image Editing
4. Analysis and Ablation
Weight combination

Style transfer and mixing

Interpolation

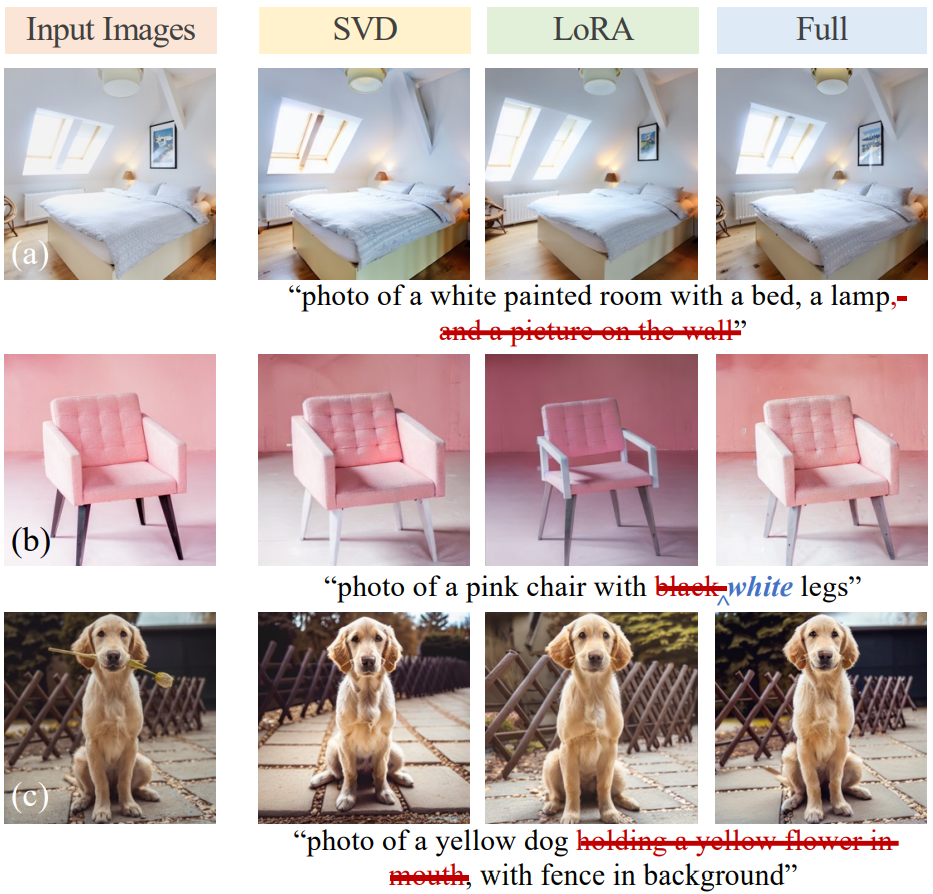
5. Comparison with LoRA
Limitation
- 더 많은 피사체가 추가됨에 따라 Cut-Mix-Unmix의 성능 저하
- 단일 이미지 편집에서 부적절하게 보존된 배경의 가능성