[논문리뷰] SV3D: Novel Multi-view Synthesis and 3D Generation from a Single Image using Latent Video Diffusion
ECCV 2024 (Oral). [Paper] [Page] [Hugging Face]
Vikram Voleti, Chun-Han Yao, Mark Boss, Adam Letts, David Pankratz, Dmitry Tochilkin, Christian Laforte, Robin Rombach, Varun Jampani
Stability AI
18 Mar 2024
Introduction
하나의 이미지에서 3D 물체를 재구성하는 것은 생성 AI의 발전을 활용해 최근에야 유용한 결과가 나오기 시작했다. 이는 생성 모델의 대규모 사전 학습을 통한 다양한 도메인에 대한 충분한 일반화를 통해 가능해졌다. 일반적인 전략은 이미지 기반 2D 생성 모델을 사용하여 보이지 않는 새로운 뷰에 대한 3D 최적화 loss function을 제공하는 것이다. 또한 여러 연구에서는 하나의 이미지에서 새로운 뷰를 합성(NVS)한 다음 이를 3D 생성에 사용하였다.
이러한 생성 기반 재구성 방법의 주요 문제는 기본 생성 모델의 멀티뷰 일관성이 부족하여 일관되지 않은 새로운 뷰를 생성한다는 것이다. 일부 연구들은 NVS 중에 3D 표현을 공동으로 추론하여 멀티뷰 일관성을 해결하려고 시도하지만 이는 높은 계산량을 요구하며 종종 일관되지 않은 형상 및 텍스처 디테일로 만족스럽지 못한 결과를 초래한다. 본 논문에서는 NVS를 위해 고해상도 이미지 조건부 video diffusion model을 적용하여 이러한 문제를 해결하였다.
본 논문은 latent video diffusion model (Stable Video Diffusion, SVD)에 명시적인 카메라 포즈 조건을 사용하여 주어진 물체에 대한 여러 새로운 뷰를 생성한다. SVD는 동영상 생성을 위한 탁월한 멀티뷰 일관성을 보여주며 이를 NVS용으로 재활용한다. 또한 SVD는 대규모 3D 데이터보다 쉽게 사용할 수 있는 대규모 이미지 및 동영상 데이터에 대해 학습되므로 일반화 능력도 우수하다.
3D 물체 생성을 위한 세 가지 유용한 속성, 포즈 제어 가능, 멀티뷰 일관성, 일반화 가능을 사용하여 단일 이미지에서 NVS용 video diffusion model을 적용한다. 이 NVS 네트워크를 SV3D라고 부른다. 본 논문은 명시적으로 포즈가 제어된 뷰 합성을 위해 video diffusion model을 적용한 최초의 논문이다.
그런 다음 NeRF와 DMTet 메쉬를 coarse-to-fine 방식으로 최적화하여 3D 물체 생성을 위해 SV3D 모델을 활용한다. SV3D의 멀티뷰 일관성을 활용하여 새로운 뷰 이미지에서 직접 고품질 3D 메쉬를 생성할 수 있다. 또한 SV3D가 예측한 새로운 뷰에서 볼 수 없는 영역의 3D 품질을 더욱 향상시키기 위해 마스킹된 Score Distillation Sampling (SDS) loss를 설계하였다. 또한, 3D 형상 및 텍스처와 함께 분리된 조명 모델을 공동으로 최적화하여 조명 문제를 효과적으로 줄였다.
SV3D: Novel Multi-view Synthesis
주요 아이디어는 공간적 3D 일관성을 위해 video diffusion model의 시간적 일관성을 사용하는 것이다. SVD를 fine-tuning하여 하나의 이미지를 기반으로 3D 물체 주위를 도는 궤도 동영상을 생성한다. 이 궤도 동영상은 동일한 고도나 일정한 간격으로 있을 필요는 없다. SVD는 실제 고품질 동영상의 대규모 데이터셋에서 부드럽고 일관된 동영상을 생성하도록 학습되었기 때문에 이 작업에 매우 적합하다. 뛰어난 데이터 양과 품질로 인해 데이터가 더욱 일반화되고 멀티뷰의 일관성이 유지되며 SVD 아키텍처의 유연성으로 인해 카메라 제어를 위한 fine-tuning이 가능해졌다.
이전 연구들에서는 이미지 diffusion model을 fine-tuning하거나, video diffusion model을 처음부터 학습하거나 fine-tuning하여 물체 주위의 동일한 고도에서 뷰를 생성했다. 그러나 본 논문은 이러한 방법이 video diffusion model의 잠재력을 완전히 활용하지 못한다고 주장한다.
문제 설정
물체의 이미지 $I \in \mathbb{R}^{3 \times H \times W}$가 주어지면 카메라 포즈 궤적 $\pi$를 따라 $K = 21$개의 멀티뷰 이미지로 구성된 물체 주위의 궤도 동영상 $J \in \mathbb{R}^{K \times 3 \times H \times W}$를 생성하는 것이다. \(\pi \in \mathbb{R}^{K \times 2} = \{(e_i, a_i)\}_{i=1}^K\)은 고도 $e$와 방위각 $a$의 튜플 시퀀스이다. 카메라는 항상 물체의 중심을 바라보고 있으므로 모든 시점은 고도와 방위각이라는 두 가지 파라미터로만 지정할 수 있다. Video diffusion model에 의해 학습된 조건부 분포 $p(J \vert I, \pi)$로부터 샘플을 반복적으로 denoise하여 이 궤도 동영상을 생성한다.
SV3D 아키텍처
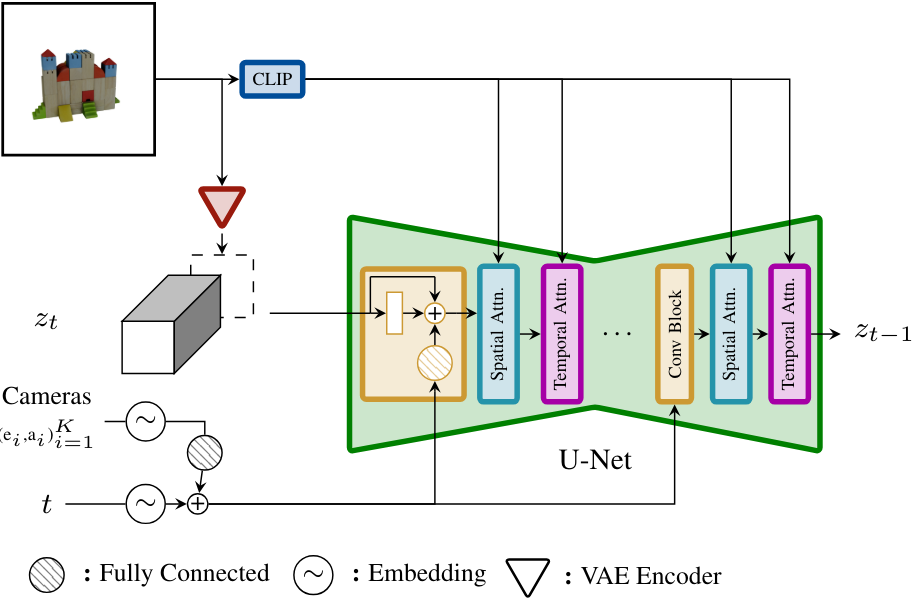
위 그림에서 볼 수 있듯이 SV3D의 아키텍처는 UNet으로 구성된 SVD 아키텍처를 기반으로 하며, 각 레이어에는 Conv3D 레이어가 있는 하나의 residual block 시퀀스와 attention layer가 있는 두 개의 transformer block이 포함되어 있다.
- 벡터 컨디셔닝 ‘fps id’와 ‘motion bucket id’는 SV3D와 관련이 없으므로 제거한다.
- 컨디셔닝 이미지는 SVD의 VAE 인코더에 의해 latent space에 삽입된 후 noisy latent $z_t$와 concatenate된다.
- 컨디셔닝 이미지의 CLIP 임베딩 행렬은 각 transformer block의 cross-attention layer에 key와 value로 제공되며 query는 해당 레이어의 feature이다.
- 카메라 궤적은 timestep과 함께 residual block에 공급된다. 카메라 포즈 $e_i$, $a_i$와 timestep $t$는 먼저 sinusoidal position embedding에 임베딩된다. 그런 다음 카메라 포즈 임베딩을 서로 concatenate하고 선형 변환한 후 timestep 임베딩에 더해진다. 이는 모든 residual block에 공급되어 블록의 출력 feature에 더해진다.
정적 궤도 vs. 동적 궤도
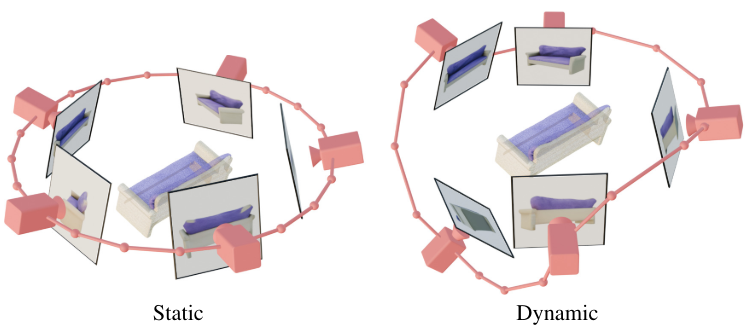
정적 궤도에서 카메라는 컨디셔닝 이미지의 고도와 동일한 고도에서 규칙적인 간격의 방위각으로 물체 주위를 회전한다. 정적 궤도의 단점은 컨디셔닝 고도각에 따라 물체의 상단이나 하단에 대한 정보를 얻지 못할 수 있다는 것이다. 동적 궤도에서는 방위각의 간격이 불규칙할 수 있으며 고도각은 뷰마다 다를 수 있다. 동적 궤도를 구축하기 위해 정적 궤도를 샘플링하고, 방위각에 작은 랜덤 노이즈를 추가하고, 고도각에 다양한 주파수를 갖는 사인파의 랜덤 가중치 결합을 추가한다. 이는 시간적 부드러움을 제공하고 카메라 궤적이 컨디셔닝 이미지와 동일한 방위각 및 고도에서 끝까지 순환하도록 보장한다.
Triangular CFG Scaling
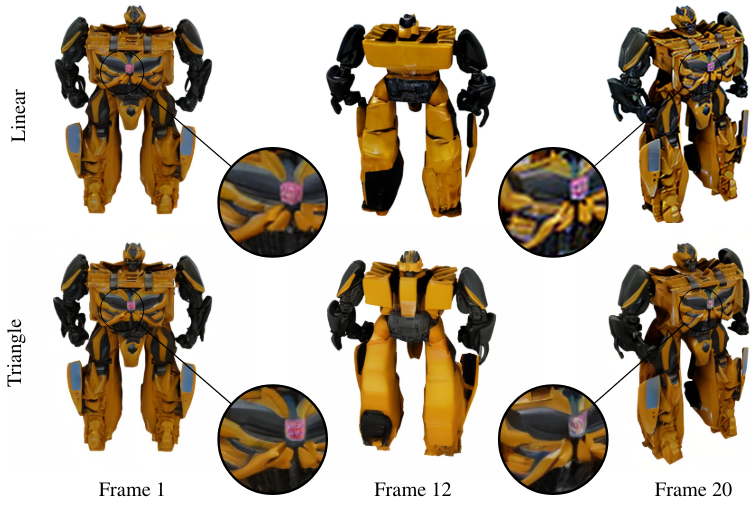
SVD는 생성된 프레임 전체에서 classifier-free guidance (CFG)를 위해 1에서 4까지 선형적으로 증가하는 스케일링을 사용한다. 그러나 이 스케일링으로 인해 위 그림의 프레임 20과 같이 생성된 궤도의 마지막 몇 프레임이 과도하게 선명해진다. 모델은 정면 이미지로 다시 돌아오는 동영상을 생성하므로 삼각파 CFG 스케일링을 사용한다. Inference 시 전면 뷰에서 CFG를 1로 두고 후면 뷰에서 2.5가 되도록 선형적으로 증가시킨 다음 전면 뷰까지 다시 1로 선형적으로 감소시킨다. 이러한 CFG 스케일링은 후면 뷰(프레임 12)에서 더 많은 디테일을 생성한다.
모델
저자들은 SVD에서 fine-tuning된 세 가지 image-to-3D 모델을 학습시켰다.
- $\textrm{SV3D}^u$: 단일 뷰 이미지로만 컨디셔닝된 상태에서 물체 주위의 정적 궤도 동영상을 생성. 모델이 컨디셔닝된 이미지에서 고도각을 추론할 수 있기 때문에 조건으로 주지 않음.
- $\textrm{SV3D}^c$: 입력 이미지와 일련의 카메라 고도 및 궤도의 방위각을 조건으로 동적 궤도에서 학습됨.
- $\textrm{SV3D}^p$: 학습 중 난이도를 점진적으로 높이기 위해 먼저 SVD를 fine-tuning하여 조건 없이 정적 궤도를 생성한 다음 카메라 포즈를 조건으로 동적 궤도를 추가로 fine-tuning.
1. Experiments and Results
- 데이터셋: Objaverse
- 학습 디테일
- 프레임 수: 21개
- 해상도: 576$\times$576
- FOV: 33.8도
- iteration: 10.5만 / effective batch size: 64
- GPU: 80GB A100 GPU 8개로 구성된 노드 4개 (6일 소요)
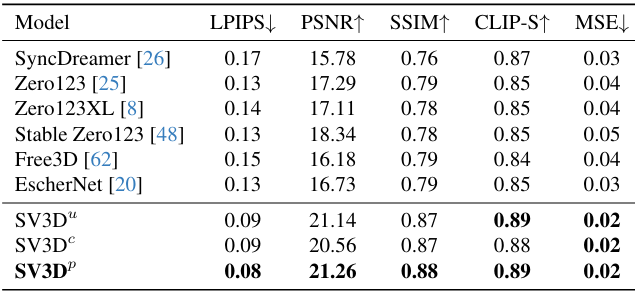
다음은 GSO의 정적 궤도(왼쪽)와 동적 궤도(오른쪽)에서의 성능을 비교한 표이다.

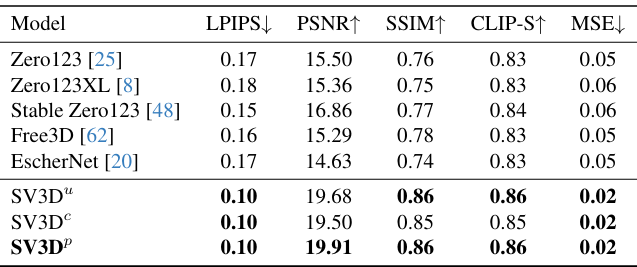
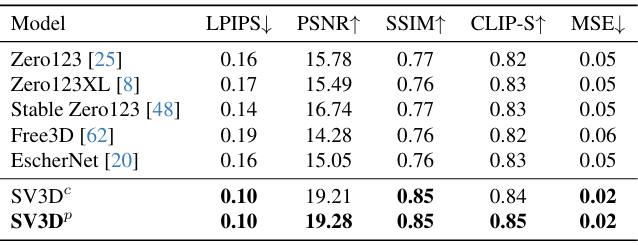
다음은 OmniObject3D의 정적 궤도(왼쪽)와 동적 궤도(오른쪽)에서의 성능을 비교한 표이다.
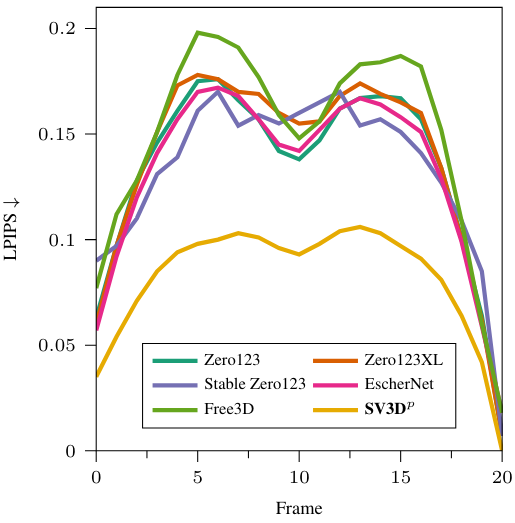
다음은 각 프레임별 LPIPS를 다른 방법들과 비교한 그래프이다.
다음은 다른 방법들과 시각적으로 비교한 것이다.

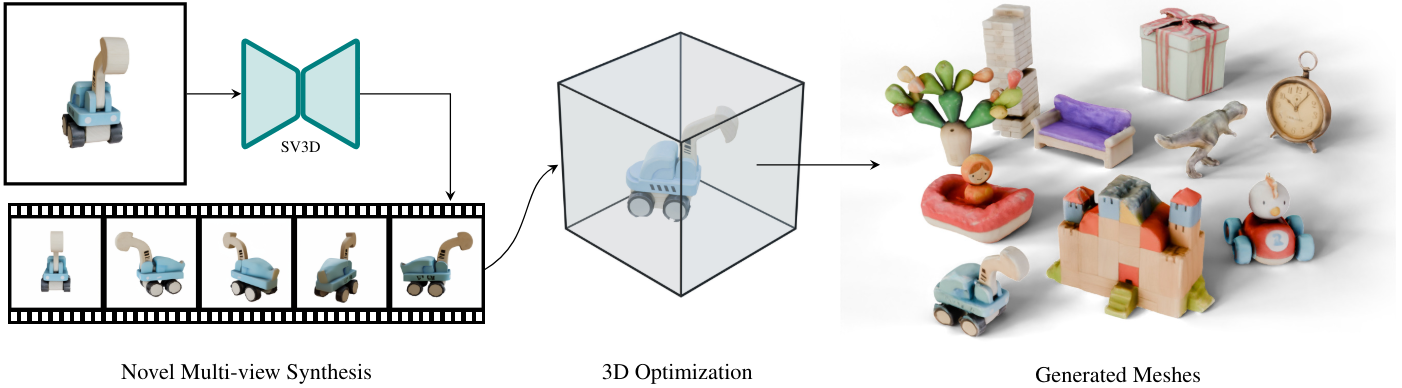
3D Generation from a Single Image Using SV3D
SV3D를 활용하여 하나의 이미지에서 물체의 3D 메쉬를 생성한다. 한 가지 방법은 SV3D에서 생성된 정적/동적 궤도 샘플을 직접 재구성 대상으로 사용하는 것이다. 또 다른 방법은 Score Distillation Sampling (SDS) loss를 사용하는 것이다.
SV3D는 기존 방법들에 비해 더 일관된 멀티뷰를 생성하므로 재구성을 위해 SV3D 출력만 사용하여 이미 더 높은 품질의 3D 재구성이 가능하다. 그러나 이러한 naive한 접근 방식이 보이지 않는 영역에 대해 baking된 조명 (사전 적용된 조명), 거친 표면, 잡음이 있는 텍스처와 같은 아티팩트를 초래하는 경우가 많다. 따라서 본 논문은 이러한 문제를 해결하기 위한 몇 가지 기술을 추가로 제안하였다.
Coarse-to-Fine 학습
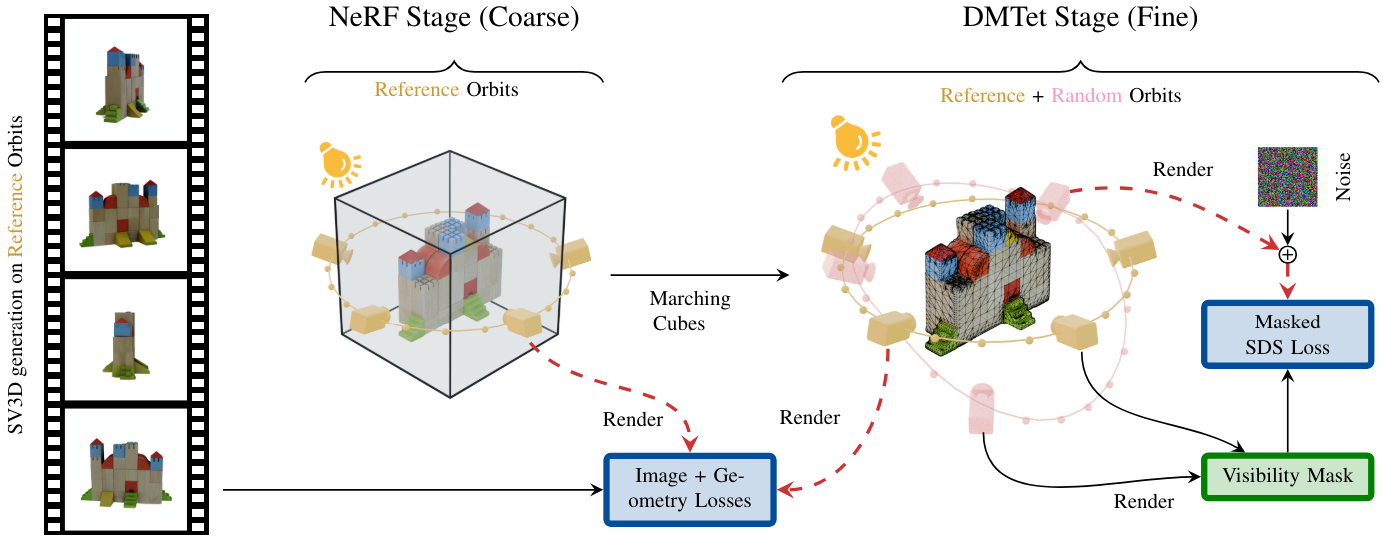
입력 이미지로부터 3D 메쉬를 생성하기 위해 2단계의 coarse-to-fine 학습 방식을 채택한다. 위 그림은 3D 최적화 파이프라인의 개요이다. Coarse stage에서는 SV3D로 생성된 이미지를 낮은 해상도에서 재구성하기 위해 Instant-NGP NeRF를 학습시킨다. Fine stage에서는 marching cube를 사용하여 학습된 NeRF에서 메쉬를 추출하고 DMTet 표현을 채택하여 전체 해상도에서 SDS 기반 diffusion guidance를 사용하여 3D 메쉬를 fine-tuning한다. 마지막으로 xatlas를 사용하여 UV unwrapping을 수행하고 메쉬를 추출한다.
분리된 조명 모델
일반적으로 SDS 기반 최적화 기술은 반복할 때마다 랜덤 조명을 사용한다. 그러나 SV3D로 생성된 동영상은 일관된 조명을 받고 있다. 따라서 조명 효과를 분리하고 보다 깨끗한 텍스처를 얻기 위해 24개의 Spherical Gaussian (SG)으로 간단한 조명 모델을 피팅한다. 백색광을 모델링하므로 SG에 대해 스칼라 진폭만 사용한다. Cosine shading 항이 다른 SG로 근사되는 Lambertian shading만 고려한다. 렌더링된 이미지와 SV3D 생성 이미지 간의 재구성 loss를 사용하여 조명 SG의 파라미터를 학습시킨다.
렌더링된 조명 $L$을 사용하여 입력 이미지 $\textbf{I}$의 HSV 값 성분을 복제하는 loss 항을 사용하여 baking된 조명을 줄인다.
\[\begin{equation} \mathcal{L}_\textrm{illum} = \vert V (\textbf{I}) - L \vert^2 \\ \textrm{where} \quad V(\textbf{c}) = \max (c_r, c_g, c_b) \end{equation}\]이러한 변화를 고려할 때 분리된 조명 모델은 조명 변화를 적절하게 표현할 수 있으며 baking된 조명을 크게 줄일 수 있다.

위 그림은 조명 모델링 유무에 따른 샘플 재구성을 보여준다. 결과를 보면 base color에서 조명 효과를 분리할 수 있음을 알 수 있다.
1. 3D Optimization Strategies and Losses
Photometric loss들을 사용한 재구성
SV3D로 생성된 이미지를 ground truth로 두고 2D 재구성 loss들을 적용하여 3D 모델을 학습시킬 수 있다. 픽셀 레벨 MSE loss, 마스크 loss, LPIPS loss를 사용하여 NeRF 또는 DMTet에서 렌더링된 이미지에 photometric loss를 적용한다. 이러한 photometric loss는 미분 가능한 렌더링 파이프라인을 통해 조명 모델을 최적화한다.
궤적 학습

3D 생성을 위해 SV3D를 사용하여 카메라 궤도 $\pi_\textrm{ref}$를 따라 여러 시점의 이미지를 생성한다. 위 그림은 SV3D의 정적 및 동적 궤도 출력을 사용한 샘플 재구성을 보여준다. 정적 궤도(고정된 고도)에서는 일부 상단/하단 뷰가 누락되기 때문에 학습 시 동적 궤도를 사용하는 것은 고품질 3D 출력에 매우 중요하다. 따라서 $\textrm{SV3D}^c$와 $\textrm{SV3D}^p$의 경우 상단 및 하단 뷰가 포함되도록 고도가 사인 함수를 따르는 동적 궤도에서 이미지를 렌더링한다.
SV3D 기반 SDS loss
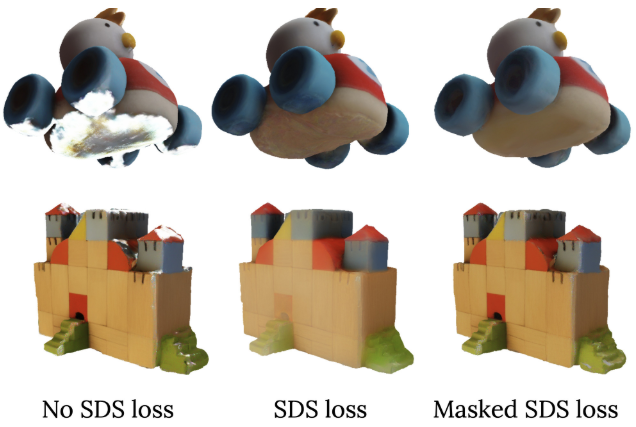
재구성 loss 외에도 Score Distillation Sampling (SDS)를 통해 SV3D를 사용할 수도 있다. 위 그림은 SDS loss를 사용 유무에 따른 샘플 재구성 결과를 보여준다. 동적 궤도를 사용한 학습은 전반적인 visibility를 향상시키지만 때로는 부분적인 visibility, 자체 가려짐 또는 이미지 간의 일관성 없는 텍스처/모양으로 인해 출력 텍스처에 여전히 잡음이 있다. 따라서 SV3D를 diffusion guidance로 사용하여 SDS loss를 사용하여 보이지 않는 영역을 처리한다.
구체적으로, 랜덤한 카메라 궤도 $\pi_\textrm{rand}$를 샘플링하고 $\theta$로 parameterize된 3D NeRF/DMTet을 사용하여 $\pi_\textrm{rand}$를 따라 뷰 $\hat{\textbf{J}}$를 렌더링한다. 그런 다음 레벨 $t$의 noise $\epsilon$이 $\hat{\textbf{J}}$의 latent 임베딩 \(\textbf{z}_t\)에 더해지고 다음과 같은 SDS loss가 미분 가능 렌더링 파이프라인을 통해 역전파된다.
\[\begin{equation} \mathcal{L}_\textrm{sds} = \mathbb{E}_{t, \epsilon} \bigg[ w(t) (\epsilon_\phi (\textbf{z}_t; \textbf{I}, \pi_\textrm{rand}, t) - \epsilon) \frac{\partial \hat{\textbf{J}}}{\partial \theta} \bigg] \end{equation}\]여기서 $w$는 $t$에 따른 가중치이고, $\epsilon$는 추가된 noise, $\epsilon_\phi$는 예측된 noise이다. $\phi$는 SV3D의 파라미터, $\theta$는 NeRF/DMTet의 파라미터이다.
마스킹된 SDS loss
SDS loss를 naive하게 추가하면 oversaturation되거나 흐릿해지는 등 불안정한 학습과 입력 이미지에 불충실한 텍스처가 생길 수 있다. 따라서 보이지 않거나 가려진 영역에만 SDS loss를 적용하는 소프트 마스킹 메커니즘을 설계하여 명확하게 보이는 표면의 텍스처를 유지하면서 누락된 디테일을 다시 칠할 수 있도록 한다. 또한 DMTet 최적화의 마지막 단계에서만 Masked SDS loss를 적용하여 수렴 속도를 크게 향상시킨다.
구체적으로, 먼저 $\pi_\textrm{rand}$에서 렌더링한다. 각각의 랜덤 카메라 뷰에 대해 가시적인 점 $\textbf{p} \in \mathbb{R}^3$와 해당 표면 normal $n$을 얻는다. 그런 다음 각 레퍼런스 카메라 $i$의 위치 \(\bar{\pi}_\textrm{ref}^i \in \mathbb{R}^3\)을 향한 표면 $\textbf{p}$의 뷰 방향 \(\textbf{v}_i\)를
\[\begin{equation} \textbf{v}_i = \frac{\bar{\pi}_\textrm{ref}^i - \textbf{p}}{\| \bar{\pi}_\textrm{ref}^i - \textbf{p} \|} \end{equation}\]로 계산한다. \(\textbf{v}_i\)와 $\textbf{n}$ 사이의 내적을 기반으로 레퍼런스 카메라로부터 이 표면의 visibility를 추론한다. 값이 높을수록 대략적으로 레퍼런스 카메라에서 표면의 visibility가 더 높아짐을 나타내기 때문에 visibility의 가능성이 최대인 레퍼런스 카메라 $c$를 선택한다.
\[\begin{equation} c = \max_i (\textbf{v}_i \cdot \textbf{n}) \end{equation}\]$c$의 보이지 않는 영역에만 SDS loss를 적용하려고 하므로 smoothstep function $f_s$를 사용하여 $c$의 visibility 범위를 \(\textbf{v}_c \cdot \textbf{n}\)으로 부드럽게 클리핑한다. 이러한 방식으로 pseudo visibility mask
\[\begin{equation} M = 1 − f_s (\textbf{v}_c \cdot \textbf{n}, 0, 0.5) \\ \textrm{where} \quad f_s(x, f_0, f_1) = \bigg( \frac{x - f_0}{f_1 - f_0} \bigg)^2 (3 - 2x) \end{equation}\]를 생성한다. 따라서 $M$은 각 랜덤 카메라 렌더링에 대해 계산되고 결합된 visibility mask $\textbf{M}$은 SDS loss에 적용된다.
\[\begin{equation} \mathcal{L}_\textrm{mask-sds} = \textbf{M} \mathcal{L}_\textrm{sds} \end{equation}\]Geometric prior
렌더링 기반 최적화는 이미지 수준에서 작동하므로 출력 모양을 정규화하기 위해 몇 가지 geometric prior를 채택한다. 부드러운 3D 표면을 장려하기 위해 RegNeRF의 smooth depth loss와 SAMURAI의 bilateral normal smoothness loss를 추가한다. 또한 Omnidata에서 normal 추정치를 얻고 MonoSDF와 유사한 mono normal loss를 계산하여 출력 메쉬의 표면을 효과적으로 부드럽게 만들 수 있다.
2. Experiments and Results
- 구현 디테일
- coarse stage: 600 steps
- fine stage: 1000 steps
- 전체 메쉬 추출 시 SDS loss를 사용하지 않으면 8분 소요, 사용하면 20분 소요
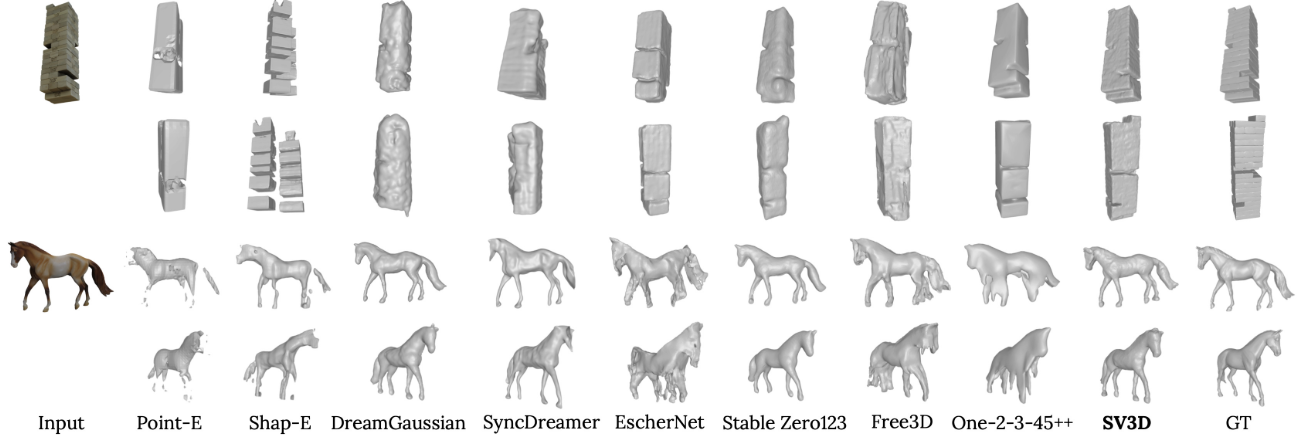
다음은 다양한 방법들의 3D mesh들을 시각적으로 비교한 것이다.
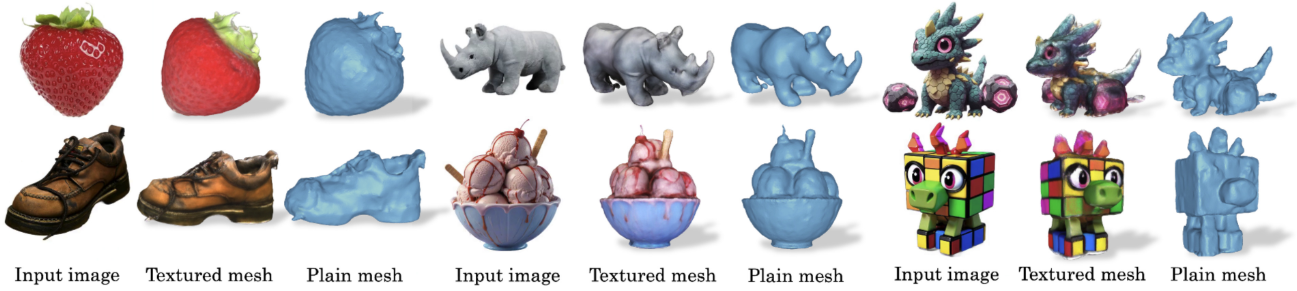
다음은 현실 이미지들에 대한 3D 메쉬 렌더링 결과이다.
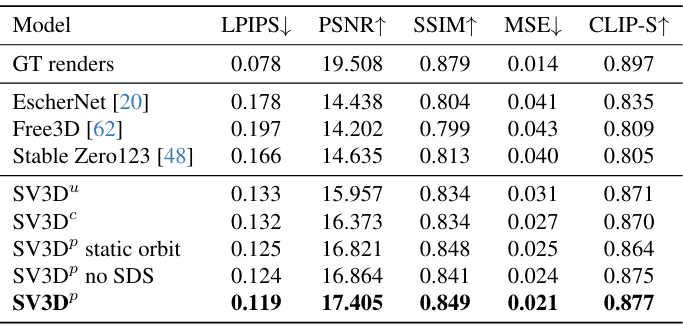
다음은 GSO 데이터셋에서 2D metric들을 비교한 표이다.
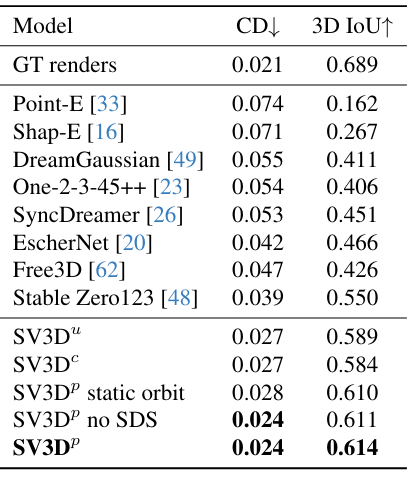
다음은 3D metric들 (Chamfer distance (CD), 3D IoU)을 비교한 표이다.