[논문리뷰] SuperGaussian: Repurposing Video Models for 3D Super Resolution
ECCV 2024. [Paper] [Page]
Yuan Shen, Duygu Ceylan, Paul Guerrero, Zexiang Xu, Niloy J. Mitra, Shenlong Wang, Anna Frühstück
University of Illinois at Urbana Champaign | Adobe Research | University College London
2 Jun 2024
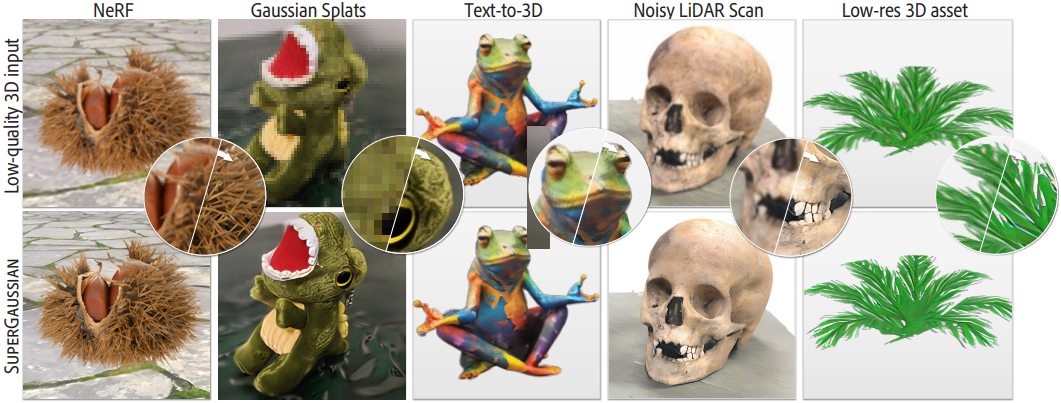
Introduction
현재 방법들로 생성된 3D 모델은 이미지나 동영상에 대한 SOTA 생성 모델이 달성하는 디테일과 정확성이 여전히 부족하다. 여러 가지 문제로 인해 이러한 제한이 발생한다.
- 3D 표현의 선택. 그리드 기반 모델은 생성된 형상에 대한 prior가 필요하지 않기 때문에 가장 많이 사용되지만, 규칙적인 구조로 인해 생성 결과의 충실도가 제한된다.
- 고품질이면서도 다양한 3D 데이터를 대량으로 확보하는 것이 여전히 어렵다. SOTA 이미지 및 동영상 모델은 수십억 개의 샘플로 학습되지만 3D 학습 데이터셋에는 기껏해야 수백만 개의 물체가 포함되어 있다.
본 논문의 목표는 일반적인 coarse한 3D 표현에서 시작하여 카테고리별 학습 없이 coarse한 3D 입력 모델을 ‘업샘플링’하는 것이다. 모든 3D 표현은 부드러운 궤적을 따라 여러 시점에서 렌더링되고 중간 동영상 표현에 매핑될 수 있다. 따라서 기존 동영상 모델의 용도를 변경하여 3D 업샘플링 또는 super-resolution을 수행하는 것이 가능하다. 이러한 모델은 대규모 동영상 데이터셋으로 학습되므로 일반적인 시나리오에 적용할 수 있는 강력한 prior를 제공한다. 중요한 과제는 3D 일관성을 보장하는 것이다. 그러나 동영상 모델은 시간적으로 부드럽지만 3D 일관성이 보장되지는 않는다. 이미지 대신 동영상을 사용하는 본 논문의 접근 방식은 시간이 지남에 따라 일관성을 크게 향상시킨다.
저자들은 기존 워크플로에 통합할 수 있는 간단하고 모듈식이며 일반적인 접근 방식을 통해 이러한 문제를 해결하였다. 먼저, 샘플링된 뷰 궤적을 바탕으로 coarse한 3D 입력에서 동영상을 렌더링한다. 그런 다음, 사전 학습된 동영상 기반 업샘플러를 사용하여 렌더링된 동영상을 업샘플링한다.
3D 통합을 위해 3D Gaussian Splatting (3DGS)을 출력 표현으로 사용한다. 물체 중심 표현인 Gaussian splat은 개별 물체를 인코딩하는 데 이상적으로 적합하며 로컬한 디테일을 캡처할 수 있다. 또한 Gaussian splat은 단순성, 인코딩된 모델의 충실도, 렌더링 효율성 사이에서 적절한 균형을 유지한다.
Method
1. Overview
본 논문의 목표는 coarse한 3D 표현이 주어지면 super-resolution을 수행하여 3D 표현의 충실도를 높이고 더 많은 로컬 디테일을 캡처하는 것이다. 3D 콘텐츠가 다양한 시점에서 3D 장면을 묘사하는 동영상으로 표현될 수 있다는 관찰을 바탕으로, 3D 업샘플링을 위해 기존 동영상 업샘플링 prior를 활용한다.
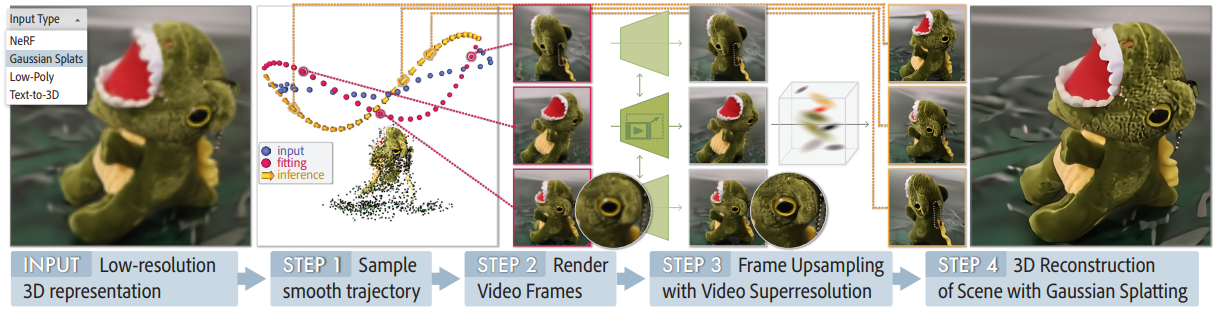
SuperGaussian은 두 가지 주요 단계로 구성된다. 먼저, 해상도를 높이고 선명한 결과를 얻기 위해 coarse한 3D 표현에서 렌더링된 동영상을 업샘플링한다. 그런 다음 3D 재구성을 수행하여 일관된 3D 표현을 생성한다. 대규모 동영상 데이터셋에서 학습된 동영상 업샘플러의 prior를 활용하는 것 외에도 도메인별 저해상도 동영상에 대한 fine-tuning을 수행한다. 따라서 SuperGaussian은 다양한 3D 캡처 및 생성 프로세스로 인해 발생하는 복잡한 성능 저하를 처리할 수 있다. 각 구성 요소는 고도로 모듈화되어 있으며 다른 SOTA 방법으로 쉽게 대체될 수 있다.
2. Problem Formulation
본 논문의 프레임워크는 정적 장면의 다양한 coarse한 3D 표현 세트 \(\psi_\textrm{low}\)를 처리할 수 있다. 예를 들어, \(\psi_\textrm{low}\)는 Gaussian Splats, NeRF, 메쉬, 저품질 캡처 동영상, text-to-3D 방법으로 생성된 3D object일 수 있다. \(\psi_\textrm{low}\)는 여러 시점에서 렌더링되어 일반적인 중간 표현인 동영상를 생성할 수 있다.
시점 \(\xi_{1 \ldots T}^{1 \ldots N}\)를 사용하여 $N$개의 부드러운 궤적에서 각 3D 입력을 렌더링하여 일련의 RGB 이미지 \(I_{1 \ldots T}^{1 \ldots N}\)를 생성한다. 아래 첨자는 각 궤적의 시점이나 포즈를 나타내며, 위 첨자는 궤적 ID이다.
저자들은 동영상 업샘플러가 충분한 시간적 정렬을 활용할 수 있을 정도로 인접한 프레임 사이의 카메라 움직임이 충분히 작다고 가정하였다. 일련의 동영상 업샘플링을 출력으로 수행한 후 Gaussian Splats 형식으로 높은 충실도의 3D 표현 \(\psi_\textrm{high}\)를 생성한다. 이 때, 카메라 뷰는 알고 있으므로 추정할 필요가 없다. 이 최종 3D 최적화는 최종 3D 출력을 생성하고 그 과정에서 정제된 동영상 표현에 남아 있는 시간적 불일치를 제거한다.
3. Initial Upsampling
먼저 타겟 장면 근처의 궤적을 수동으로 샘플링한다. 각 동영상의 카메라 경로를 설명하는 궤적 \(I_{1 \ldots T} \in \{\mathbb{R}^{W \times H \times 3}\}\)이 주어지면 동영상 업샘플러는 $r$배 업샘플링 (실험에서는 $r = 4$)을 사용하여 궤적을 출력한다.
\[\begin{equation} \hat{I}_{1 \ldots T} = f (I_{1 \ldots T}) \in \mathbb{R}^{rW \times rH \times 3} \end{equation}\]여기서 $f$는 동영상 업샘플러이고, \(\hat{I}_{1 \ldots T}\)는 업샘플링된 동영상이다. 입력 3D 표현의 coarse한 수준으로 인해 렌더링 충실도에 한계가 생기므로 초기 렌더링 해상도가 충분히 높아야 한다.
본 논문의 프레임워크는 사전 학습된 SOTA 동영상 업샘플러를 쉽게 통합할 수 있다. 본 논문에서는 VideoGigaGAN을 사용한다. 심각한 도메인 편향이 있는 입력 표현을 처리하는 경우 추가적인 fine-tuning이 필요하다. 예를 들어 확대 후 줄무늬 또는 얼룩 같은 아티팩트가 있는 경우 Gaussian Splats의 렌더링은 SOTA 동영상 업샘플러의 augmentation과 다른 degradation을 따른다.
동영상 업샘플러를 fine-tuning하려면 모델링하려는 특정 degradation을 묘사하는 저해상도 및 고해상도 동영상 쌍이 필요하다. 이를 위해 다양한 3D 물체와 장면을 묘사하는 MVImgNet 데이터셋을 사용한다. 먼저, 저해상도 이미지셋을 얻기 위해 데이터셋의 원본 이미지를 64$\times$64 해상도로 다운샘플링한다. 그런 다음 저해상도 Gaussian Splat을 이러한 이미지에 적용한다. 동영상 업샘플러에 대한 입력으로 데이터셋에서 제공한 원래 카메라 궤적에서 최적화된 저해상도 Gaussian을 렌더링한다. 256$\times$256로 resize된 데이터셋의 원본 동영상를 GT로 사용한다. Charbonnier regression loss, LPIPS loss, GAN loss를 사용하여 모델을 fine-tuning한다.
4. 3D Optimization via Gaussian Splats
3DGS를 사용하여 업샘플링된 동영상에 Gaussian을 맞추기 위한 3D 최적화를 수행한다. 완벽한 카메라 정보를 가지고 있기 때문에 SfM을 사용하여 추정하는 대신 완벽한 카메라 정보를 최적화에 직접 제공한다. Loss function의 경우 3DGS와 동일하게 L1 loss와 SSIM loss를 사용한다. 3DGS를 사용하면 물체 중심 표현이 가능하고 학습 및 렌더링 측면에서 효율성이 높다는 장점이 있다. 게다가 업샘플링된 프레임에 대해 뷰에 따른 효과를 잘 캡처할 수 있다. 그러나 SuperGaussian은 다른 유형의 3D 표현(ex. NeRF)과 쉽게 통합될 수도 있다.
Experiments
- 구현 디테일
- fine-tuning
- GPU: A100 64개 (각 80GB VRAM)
- learning rate: $5 \times 10^{-5}$
- 가중치: LPIPS loss = 15 / Charbonnier regression loss = 10 / GAN loss = 0.05
- batch size: 64 (각각 동영상 프레임 12개)
- GigaGAN을 따라 discriminator에 $R_1$ 정규화 적용 (가중치: 0.02048, 간격: 16)
- Gaussian 최적화
- step: 2,000
- 약 30초 소요
- fine-tuning
1. Comparison
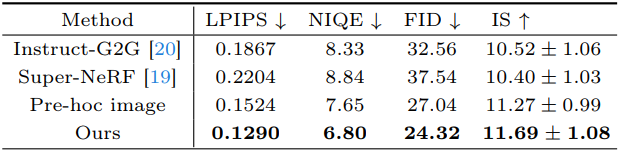
다음은 MVImgNet에서 저해상도 Gaussian Splatting은 업샘플링한 결과이다.

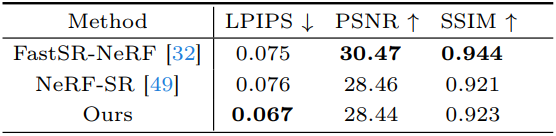
다음은 Blender 합성 데이터셋에 대한 결과이다.

2. Ablation Studies
다음은 업샘플링 prior에 대한 ablation 결과이다.

다음은 다양한 degradation에 대한 finetuning의 효과를 비교한 것이다.

다음은 궤적 샘플링에 대한 ablation 결과이다.


3. Additional Results
다음은 현실 scene에 대한 3D Gaussian splat을 업샘플링한 결과이다.

다음은 indoor scene에 대한 결과이다.

다음은 Instant3D로 생성한 text-to-3D 결과를 업샘플링한 예시이다.

다음은 multi-level 3D 업샘플링 예시이다.

Limitations
- 사전 학습된 동영상 모델을 사용하기 때문에 일반화 및 추론 속도를 향상시킬 수 없다.
- 입력에서 누락/폐쇄된 부분 또는 불충분한 시점 커버에서 복구할 수 없다.