[논문리뷰] SuperDec: 3D Scene Decomposition with Superquadric Primitives
ICCV 2025 (Oral). [Paper] [Page] [Github]
Elisabetta Fedele, Boyang Sun, Leonidas Guibas, Marc Pollefeys, Francis Engelmann
ETH Zurich | Stanford University | Microsoft
1 Apr 2025

Introduction
장면 수준에서 3D 장면의 압축성을 최적화하는 것은 여전히 어려운 과제이지만, 직육면체나 superquadric과 같은 primitive를 사용하면 개별 object를 간결하고 해석 가능한 형태로 분해할 수 있다. 이러한 방법들은 크게 두 가지 유형으로 나뉘는데, 하나는 학습 기반으로 정확도를 희생하면서 속도를 우선시하는 방식이고, 다른 하나는 최적화 기반으로 정확도는 높지만 계산 시간이 더 오래 걸리는 방식이다. 이러한 방법들은 특정 object shape에 대해서는 정확할 수 있지만, 다양한 shape을 포함하는 데이터셋에서는 일반화 성능이 저하되는 문제가 있다. 전자는 특정 카테고리에 대한 학습이 필요하고, 후자는 휴리스틱에 의존하기 때문에 확장성이 제한적이다.
본 논문은 개별 object 카테고리에 대한 primitive의 추상화 능력에 착안하여, 복잡한 3D 장면을 압축된 superquadric 집합으로 표현하는 방법을 제안하였다. 이를 위해 일반적인 object 수준의 shape prior를 학습하여 압축성을 최적화하고, 3D instance segmentation 방법인 Mask3D를 활용하여 전체 3D 장면에 적용 가능하도록 확장하였다.
본 논문에서는 직육면체보다 더 정확한 shape 모델링을 제공하면서도 추가적인 파라미터 비용이 최소화되는 superquadric을 building block으로 선택했다. 다양한 shape에 일반화할 수 있는 모델을 얻기 위해, 로컬 포인트 기반 feature를 사용하여 예측된 primitive를 반복적으로 개선했다.
ShapeNet 데이터셋에서 본 방법은 기존 SOTA 대비 L2 오차를 6배 낮추면서도 필요한 primitive의 개수는 절반으로 줄였다. ScanNet++와 Replica 데이터셋에서는 ShapeNet 데이터셋으로만 학습했음에도 불구하고 실제 장면 환경에서 본 방법이 우수한 성능을 보임을 입증했다.
Method
본 논문의 궁극적인 목표는 superquadric primitive를 이용한 3D 장면 분해이다. 이를 위해 우선 단일 object 분해에 초점을 맞추고, 3D instance segmentation과 결합하여 전체 3D 장면에 적용하였다.
1. Single Object Decomposition
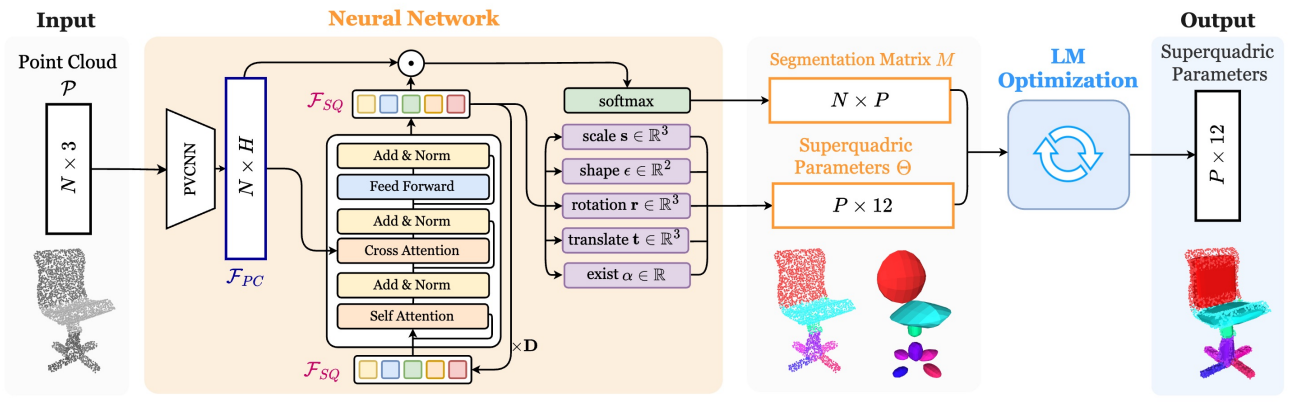
모델은 크게 두 가지 구성 요소로 이루어져 있다. 첫 번째는 superquadric 파라미터와 점들을 superquadric에 연결하는 segmentation 행렬을 동시에 예측하는 self-supervised feed-forward 신경망이고, 두 번째는 가벼운 Levenberg–Marquardt (LM) 최적화 알고리즘이다.
Feed-forward Neural Network
본 논문의 딥러닝 모델은 fully-supervised learning 방식의 Transformer 기반 segmentation 모델에서 영감을 얻었다. 이러한 모델들은 입력 픽셀이나 점에 대한 cross-attention을 통해 segmentation mask를 나타내는 일련의 query를 반복적으로 디코딩한다. 본 논문에서는 query가 superquadric을 나타낸다.
모델 디테일
각 $N$개의 점이 3D 좌표를 갖는 입력 포인트 클라우드 $\mathcal{P} \in \mathbb{R}^{N \times 3}$이 주어졌을 때, 먼저 PVCNN 포인트 인코더를 사용하여 풍부한 point feature \(\mathcal{F}_{PC} \in \mathbb{R}^{N \times H}\)를 추출한다. 동시에, 사인파 위치 인코딩을 사용하여 superquadric feature \(\mathcal{F}_{SQ} \in \mathbb{R}^{P \times H}\)를 초기화한다. 이러한 feature들을 self-attention, cross-attention, feed-forward layer를 활용하는 Transformer 디코더에 입력하여 정제한다.
정제된 \(\mathcal{F}_{PC}\)와 \(\mathcal{F}_{SQ}\)와는 두 개의 예측 head에 입력된다. Segmentation head는 \(\mathcal{F}_{SQ}\)와 \(\mathcal{F}_{PC}\)를 입력으로 받아 점과 superquadric을 연결하는 soft assignment matrix $M \in \mathbb{R}^{N \times P}$를 예측하며, 이 행렬은 다음과 같이 정의된다.
\[\begin{equation} m_{ij} = \sigma (\phi (\mathcal{F}_{PC}) \cdot \mathcal{F}_{SQ}) \end{equation}\]($\phi$는 학습되는 projection, $\sigma$는 softmax)
두 번째 head인 superquadric head는 \(\mathcal{F}_{SQ}\)를 입력으로 받아 각 superquadric에 대해 12개의 파라미터를 예측한다. 이 중 11개는 5-DoF shape과 6-DoF 포즈를 인코딩하고, 나머지 하나는 존재 확률 $\alpha$를 모델링하여 object당 가변적인 수의 superquadric을 구현할 수 있도록 한다.
Losses
본 논문에서는 GT 없이 self-supervised 방식으로 모델을 학습시켰다. 구체적으로, 전체 loss는 다음과 같이 정의된다.
\[\begin{equation} \mathcal{L} = \mathcal{L}_\textrm{rec} + \lambda_\textrm{par} \mathcal{L}_\textrm{par} + \lambda_\textrm{exist} \mathcal{L}_\textrm{exist} \end{equation}\]\(\mathcal{L}_\textrm{rec}\)는 예측된 superquadric들을 입력 포인트 클라우드 $\mathcal{P}$에 정렬하는 reconstruction loss이고, \(\mathcal{L}_\textrm{par}\)는 최소한의 primitive를 사용하도록 유도하는 parsimony loss이며, \(\mathcal{L}_\textrm{exist}\)는 existence loss이다. \(\mathcal{L}_\textrm{rec}\)는 세 가지 항으로 구성된다.
\[\begin{equation} \mathcal{L}_\textrm{rec} = \mathcal{L}_{\mathcal{P} \rightarrow SQ} + \mathcal{L}_{SQ \rightarrow \mathcal{P}} + \mathcal{L}_N \end{equation}\]첫 번째 두 항은 입력 포인트 클라우드와 superquadric 표면 사이의 양방향 Chamfer distance에 해당하며, 세 번째 항은 학습 중 수렴을 개선하기 위해 normal 정보를 통합하는 정규화 항 역할을 한다. Chamfer distance 거리를 계산하기 위해 $S$개의 점을 균일하게 샘플링하여 각 superquadric 표면을 근사화한다. 입력 포인트 클라우드의 $i$번째 점과 $j$번째 superquadric 표면에서 샘플링된 $s$번째 점 사이의 유클리드 거리를 \(d(\textbf{x}_i, \textbf{x}_{js}^\prime)\)로 나타낼 때, \(\mathcal{L}_{\mathcal{P} \rightarrow SQ}\)와 \(\mathcal{L}_{SQ \rightarrow \mathcal{P}}\)는 다음과 같이 정의된다.
\[\begin{aligned} \mathcal{L}_{\mathcal{P} \rightarrow SQ} &= \frac{1}{N} \sum_{i=1}^N \sum_{j=0}^P m_{ij} \min_{s \in [S]} d (\textbf{x}_i, \textbf{x}_{js}^\prime) \\ \mathcal{L}_{SQ \rightarrow \mathcal{P}} &= \frac{1}{S \sum_{j=1}^P \alpha_j} \sum_{s=1}^P \alpha_j \sum_{s=1}^S \min_{i \in [N]} d (\textbf{x}_i, \textbf{x}_{js}^\prime) \end{aligned}\]마지막 항인 \(\mathcal{L}_N\)은 reconstruction loss로 정의되며, 학습 중 normal 정보를 통합하여 수렴 속도를 높이는 데 사용된다.
정확도뿐만 아니라 간결성도 추구하기 때문에 더 적은 primitive를 사용하도록 유도하는 parsimony loss를 도입한다. 이를 위해 parsimony loss를 다음과 같이 정의한다.
\[\begin{equation} \mathcal{L}_\textrm{par} = \left( \frac{1}{P} \sum_{j=1}^P \sqrt{\frac{1}{N} \sum_{i=1}^N m_{ij}} \right)^2 \end{equation}\]마지막으로, 존재 확률 예측을 담당하는 linear head가 예측된 segmentation 결과를 GT로 사용하는 existence loss \(\mathcal{L}_\textrm{exist}\)를 적용한다. 구체적으로, threshold \(\epsilon_\textrm{exist}\)가 주어졌을 때, $j$번째 superquadric의 GT 존재 여부를 \(\hat{\alpha}_j = m_j > \epsilon_\textrm{exist}\)로 정의하고 \(\mathcal{L}_\textrm{exist}\)를 다음과 같이 정의한다.
\[\begin{equation} \mathcal{L}_\textrm{exist} = \frac{1}{P} \sum_{j=1}^P \textrm{BCE} (\alpha_j, \hat{\alpha}_j) \end{equation}\]($\textrm{BCE}$는 binary cross entropy)
Optimization
최적화 모듈은 예측된 soft assignment matrix $M$과 superquadric 파라미터 $\Theta$를 입력으로 받아 Levenberg-Marquardt (LM) 알고리즘을 사용하여 superquadric 파라미터를 더욱 정밀하게 조정한다. 구체적으로, $N$개의 점으로 이루어진 포인트 클라우드가 주어졌을 때, 두 residual 집합을 계산하여 $j$번째 superquadric의 파라미터 \(\Theta_j\)를 반복적으로 정밀하게 조정한다. 첫 번째 residual 집합은 다음과 같이 정의된다.
\[\begin{equation} r_{ij} = m_{ij} \tilde{d}_j (\textbf{x}_i), \quad i \in [1, N], \; j \in [1, P] \end{equation}\](\(\tilde{d}_j (\textbf{x}_i)\)는 $j$번째 superquadric에 대한 \(\textbf{x}_i\)의 radial distance)
두 번째 residual 집합은 정규화에 사용되며, 주어진 superquadric의 표면에서 $K$개의 점 $p_1, \ldots, p_K$를 샘플링한 다음 각 점과 포인트 클라우드 사이의 거리를 계산하여 얻는다.
\[\begin{equation} r_{ij} = \min_k \| \textbf{p}_{i-N} - \Pi_j (\textbf{x}_k) \|_2, \quad i \in [N+1, N+K], \; j \in [1, P], \; k \in [1, N] \end{equation}\]2. Decomposition of Full 3D Scenes
단일 object 학습 후, SuperDec을 전체 3D 장면으로 확장하는 것은 간단하다. 장면 수준의 포인트 클라우드가 주어지면 Mask3D를 사용하여 3D object instance mask를 추출한다. 각 object는 중심에 맞춰지고 단위 구로 균일하게 rescaling된다. 그런 다음 모델을 사용하여 각 object에 superquadric primitive를 개별적으로 예측한다. ShapeNet으로 학습된 본 논문의 모델은 추가적인 fine-tuning 없이도 ScanNet++와 Replica의 실제 3D 장면에서 우수한 일반화 성능을 보였다.
Experiments
1. Comparing with State-of-the-art Methods
다음은 ScanNet에서의 비교 결과이다.
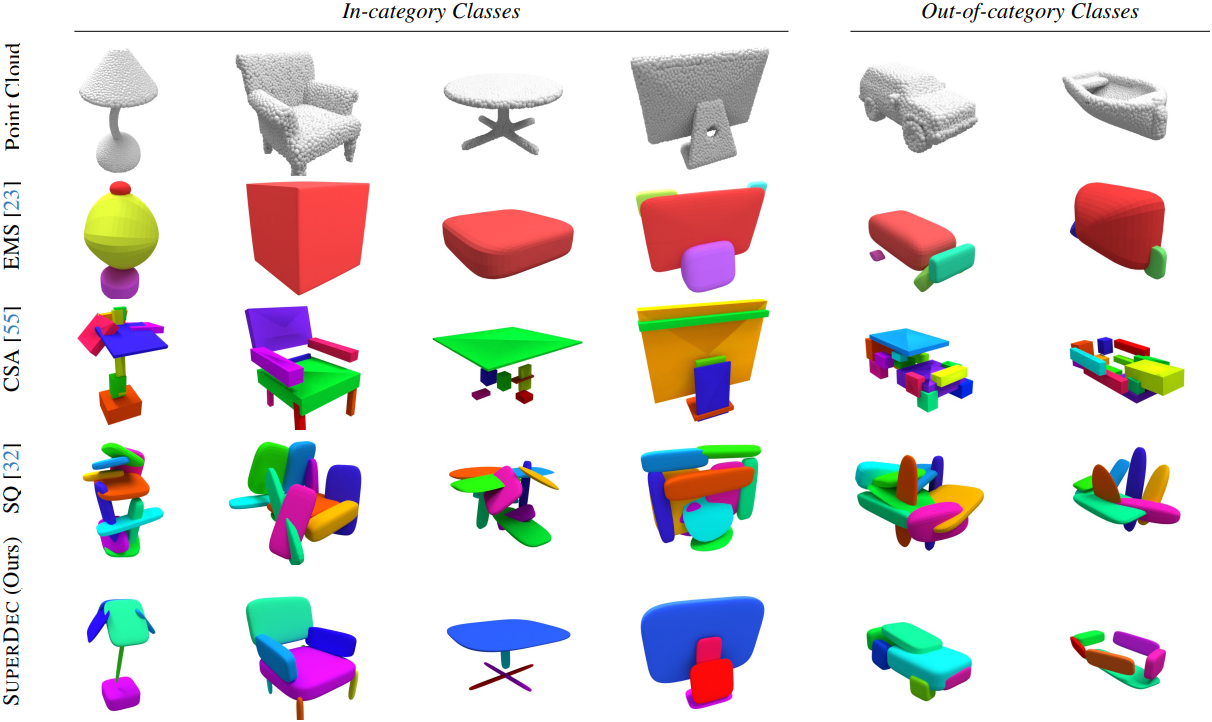

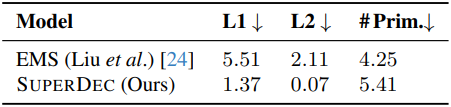
다음은 ScanNet++에서 object-level 평가 결과이다.
2. Down-stream Applications
다음은 ScanNet++에서의 path planning 결과이다. (장면 15개 평균)
다음은 계산된 grasping 포즈를 시각화한 결과이다.

다음은 현실 로봇 실험 결과이다.

다음은 SuperDec을 사용한 공간 제어 예시이다. (프롬프트: “A corner of a room with a plant”)

다음은 SuperDec을 사용한 semantic 제어 예시이다.

3. Analysis Experiments
다음은 ScanNet에서의 segmentation 결과이다.
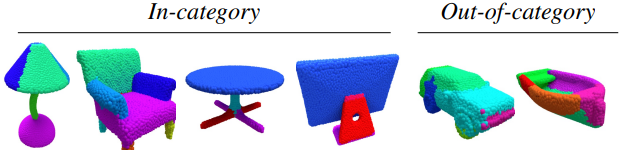
다음은 primitive embedding에 대한 t-SNE 시각화 결과이다.
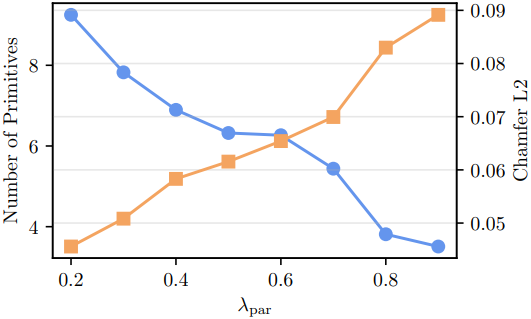
다음은 primitive 수와 L2 Chamfer distance 사이의 trade-off를 나타낸 그래프이다.