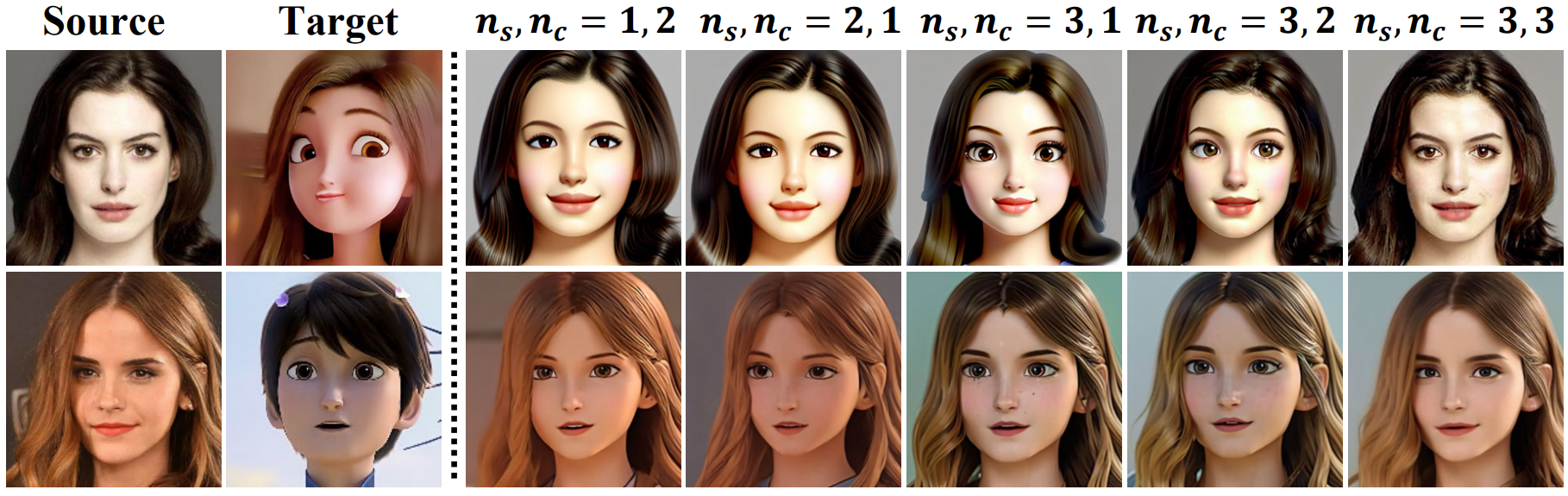[논문리뷰] StyO: Stylize Your Face in Only One-Shot
arXiv 2023. [Paper]
Bonan Li, Zicheng Zhang, Xuecheng Nie, Congying Han, Yinhan Hu, Tiande Guo
University of Chinese Academy of Sciences | MT Lab, Meitu Inc.
3 Mar 2023

Introduction
Face stylization은 얼굴 사진에서 개인화된 예술 초상화를 자동으로 생성하는 것을 목표로 한다. 최근 이 task에 대한 one-shot 솔루션은 실제로 배포를 더 쉽게 만드는 데이터 효율성이라는 중요한 기능으로 인해 많은 관심을 끌었다.
기존 연구들은 one-shot face stylization을 style transfer 문제, 즉 단일 대상 이미지의 얼굴 스타일을 원본 이미지의 얼굴로 옮기는 문제로 간주하고 GAN으로 이 문제를 해결하였다. 기존 연구들의 성공에도 불구하고 위 그림과 같이 SOTA 방법조차도 소스 콘텐츠(ex. 얼굴 및 머리 색상)를 유지하면서 합리적인 스타일(ex. 기하학 변형)을 달성하지 못한다. 두 가지 주요 원인으로 인해 발생한다.
- 대규모 실제 얼굴 데이터셋에 대하여 사전 학습된 GAN 모델에 크게 의존하므로 GAN의 능력 제한으로 인해 one-shot guidance로 다른 도메인에서 얼굴 스타일, 특히 형상 변경을 일치시키기 어렵다.
- Latent space에서 얼굴 이미지의 스타일 및 콘텐츠 정보를 함께 얽히게 하여 현재의 인코딩 및 inversion 기술이 stylize된 얼굴을 나타내는 정확한 latent code를 도출하기 어렵게 만든다.
본 논문에서는 One-shot으로 얼굴을 Stylizing하는 task의 최전선을 추진하기 위해 새로운 StyO 모델을 제안한다. 생성 다양성을 개선하기 위해 StyO는 GAN 대신 DDPM을 활용한다. Stylize된 얼굴을 정확하게 표현하기 위해 StyO는 disentanglement와 recombination(재조합) 전략을 활용한다. 특히 StyO는 소스 및 타겟 이미지의 스타일 및 콘텐츠 정보를 서로 다른 identifier로 분해한 다음 교차 방식으로 융합하여 프롬프트를 형성한다. 이는 DDPM이 합리적인 이미지를 생성하도록 유도하는 stylize된 얼굴의 표현 역할을 한다. 이러한 방식으로 StyO는 복잡한 이미지를 독립적이고 구체적인 속성으로 분해하고 입력 이미지의 다양한 속성 조합으로 one-shot face stylization을 단순화하여 타겟 이미지의 얼굴 스타일과 소스 이미지의 내용이 더 잘 일치하는 결과를 생성한다.
특히 StyO는 효율적인 Latent Diffusion Model (LDM)으로 구현된다. 이는 두 가지 핵심 모듈로 구성된다.
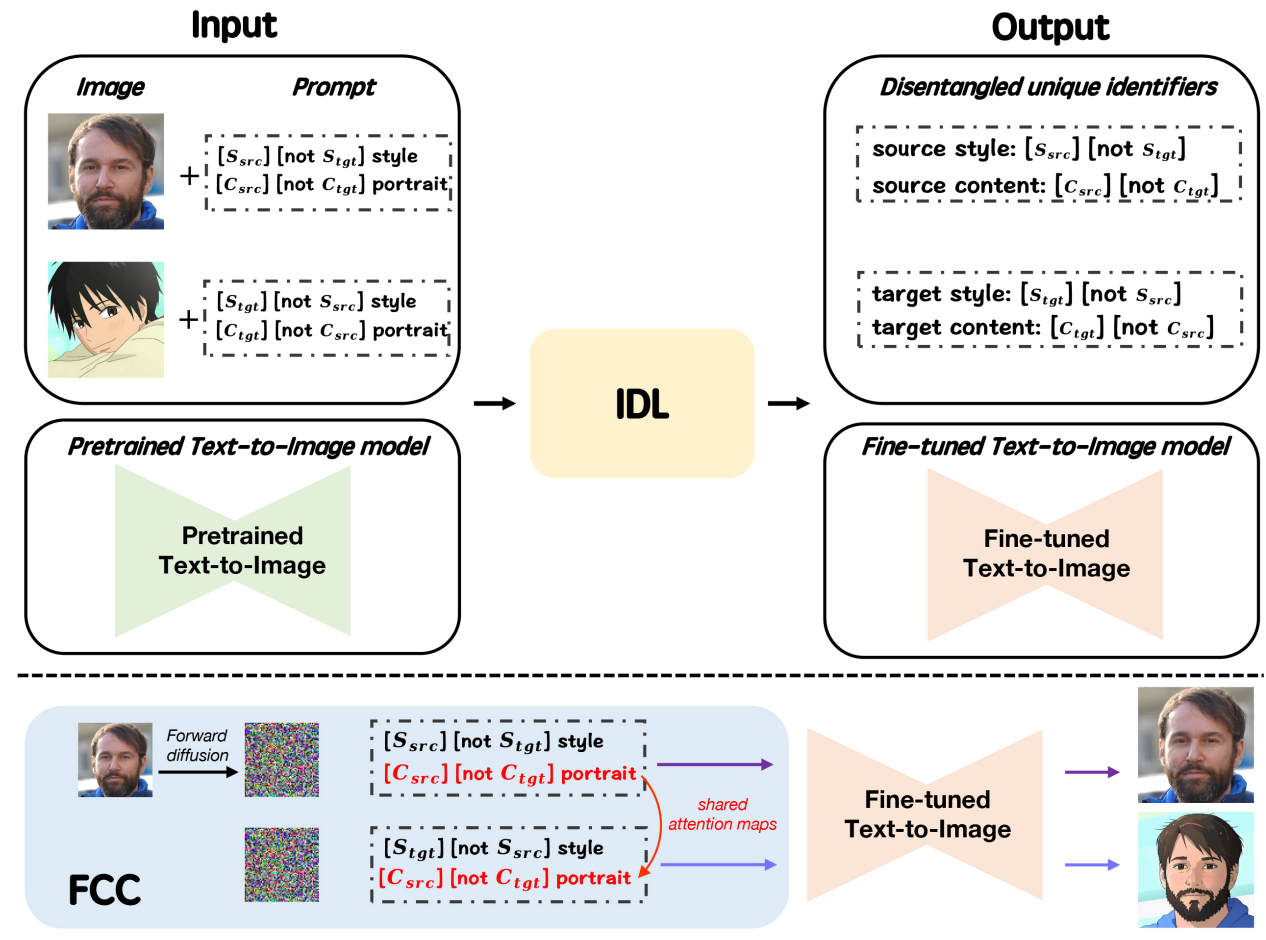
- Identifier Disentanglement Learner (IDL): IDL은 이미지의 스타일과 콘텐츠를 다른 identifier로 분리하는 것을 목표로 한다. 여기서 IDL은 LDM의 텍스트 기반 이미지 생성의 강력한 능력을 완전히 활용하기 위해 identifier를 text descriptor로 나타낸다. 그런 다음 IDL은 콘텐츠 및 스타일 identifier가 있는 입력 이미지에 대한 텍스트 설명으로 contrastive disentangled prompt template을 정의한다. 또한 소스 스타일과 동일한 스타일의 보조 이미지 셋을 설명하기 위해 소스 및 타겟 스타일 identifier만 있는 보조 프롬프트 템플릿을 도입한다. 이렇게 하면 스타일 및 콘텐츠 identifier가 이미지의 해당 특성을 올바르게 나타내는 데 도움이 되며 스타일/콘텐츠 정보가 해당 identifier가 아닌 프롬프트의 다른 단어와 관련될 위험을 피할 수 있다. 위에 정의된 프롬프트가 주어지면 StyO는 이미지 속성을 identifier에 주입하기 위해 사전 학습된 LDM을 fine-tuning하기 위해 텍스트-이미지 쌍을 구축하여 disentanglement 목표를 달성한다.
- Fine-grained Content Controller (FCC): FCC는 stylize된 얼굴 이미지를 생성하기 위해 IDL의 스타일과 콘텐츠 identifier를 재결합하는 것을 목표로 한다. 구체적으로, FCC는 타겟의 스타일과 소스의 콘텐츠로 stylize된 얼굴을 설명하기 위해 프롬프트 템플릿을 구성하며, 이는 stylization 결과를 도출하기 위한 LDM에 대한 조건으로 사용된다. 그러나 위의 재구성된 프롬프트에서만 머리 포즈, 머리 색깔, 수염 스타일 등과 같은 소스 이미지의 세밀한 디테일이 손실될 수 있다. 이 문제를 해결하기 위해 FCC는 제어 가능성을 향상시키기 위해 attention map에 대한 새로운 조작 메커니즘을 제시한다. 이는 cross attention layer의 attention map이 프롬프트의 텍스트와 의미론적으로 연관되어 있다는 사실에서 영감을 받았다. 따라서 FCC는 소스 콘텐츠에 대한 attention map을 추출하고 이를 사용하여 결과의 세밀한 디테일을 효과적으로 제어하는 stylize된 콘텐츠를 대체한다. 또한 FCC는 identifier를 반복하여 프롬프트를 보강할 것을 제안한다. 이 간단한 augmentation 전략은 성공적으로 생성 품질을 더욱 향상시킨다. 아래 그림과 같이 이 디자인을 통해 StyO는 소스 콘텐츠를 유지하면서 적절한 대상 스타일로 얼굴을 생성할 수 있다.
Method
1. Preliminaries
Text-to-image diffusion model은 latent noise와 텍스트 프롬프트 $\mathcal{P}$를 이미지 $x^0$에 매핑하는 생성 모델이다. 본 논문에서는 사전 학습된 LDM에 초점을 맞춘다. LDM은 먼저 사전 학습된 인코더 $\mathcal{E}$를 사용하여 이미지 $x^0$을 latent space로 인코딩한다.
\[\begin{equation} z^0 = \mathcal{E} (x^0) \end{equation}\]$x^0$는 사전 학습된 디코더 $\mathcal{D}$로 복구될 수 있다. 그런 다음 latent space에서 reverse process를 수행한다. 구체적으로, reverse process는 각 step에서 Gaussian transition으로 구성된 $z^0$에서 $z^T$까지의 고정 길이 Markov chain으로 알려져 있다. 각 \(t \in \{0, \cdots, T\}\)에 대해 transition은 다음을 만족한다.
\[\begin{equation} z^t = \sqrt{\alpha^t} z^0 + \sqrt{1 - \alpha^t} \epsilon, \quad \epsilon \sim \mathcal{N}(0, I) \end{equation}\]여기서 \(\{\alpha^t\}_{t=0}^T\)는 단조 감소 수열이며, $\alpha^0 = 1$이고 $\alpha^T$는 0에 가까워진다. 반대로, reverse process는
\[\begin{equation} z^{t-1} = \mu (z^t, \epsilon_\theta, t) + \sigma(t) w, w \sim \mathcal{N}(0, I) \end{equation}\]로 주어진 순차적인 가우시안 샘플링으로 구성된다. 여기서 $\mu$와 $\sigma$는 가우시안 분포의 파라미터를 계산하기 위한 미리 정의된 함수다. $\mu$는 attention 메커니즘이 장착된 시간으로 컨디셔닝된 UNet인 $\epsilon_\theta$에 의해 parameterize되며, 다음 목적 함수로 학습된다.
\[\begin{equation} \min_\theta \mathbb{E}_{z^0, \epsilon, t} \| \epsilon - \epsilon_\theta (z^t, t, \gamma) \|_2^2 \end{equation}\]$\gamma$는 고정 모델 $\phi$(ex. CLIP 텍스트 인코더)에 의해 매핑된 $\mathcal{P}$의 텍스트 임베딩이다. Reverse process는 최종 샘플 $z^0$가 latent의 분포를 따르고 생성된 이미지가 프롬프트와 일치하도록 한다.
2. Framework of StyO
얼굴 도메인의 소스 이미지 $x_\textrm{src}$와 예술적인 초상화 도메인의 타겟 이미지 $x_\textrm{tgt}$이 주어지면 타겟 스타일뿐만 아니라 소스 콘텐츠와 이미지를 합성하는 것이 목표이다. 본 논문은 LDM을 기반으로 task를 처리하기 위해 identifier disentanglement learninger (IDL)과 fine-grained content controller (FCC)로 구성된 StyO라는 새로운 접근 방식을 제안한다. 일반적으로 StyO는 콘텐츠와 스타일을 나타내는 분리된 identifier를 IDL을 통해 학습하고, 재조합 identifier로 구성된 프롬프트로 stylize된 이미지를 유추할 때 FCC를 통해 세분화된 콘텐츠 디테일을 유지할 수 있다. StyO의 상세 스케치는 아래 그림과 같다.
Identifier Disentanglement Learner
주어진 이미지에서 콘텐츠 및 스타일 정보를 추출하기 위해 positive-negative identifier와 information descriptor를 사용하여 각 이미지에 대한 텍스트 레이블을 구성하는 contrastive disentangled prompt template을 설계한다. 이러한 이미지-텍스트 쌍은 콘텐츠와 스타일이 identifier로 인코딩되도록 triple reconstruction loss로 LDM을 fine-tuning하는 데 사용된다.
Contrastive Disentangled Prompt Template
먼저 각 이미지를 새로운 contrastive disentangled prompt template으로 레이블링한다.
“a drawing with [$S^{+}$][$S^{-}$] style of [$C^{+}$][$C^{-}$] portrait”
여기서 “style”과 “portrait”은 information descriptor이다. “[$S^{+}$]”/”[$S^{-}$]”는 스타일에 연결된 positive/negative identifier이며, “[$C^{+}$]”/”[$C^{-}$]”는 콘텐츠에 연결된 positive/negative identifier이다. 특히 positive identifier는 이미지에 해당하는 semantic 의미를 보유할 것으로 예상된다. 소스/타겟 이미지와 대하여 “[$S^{+}$]”와 “[$C^{+}$]”에 각각 “[$S_\textrm{src}$]”/”[$S_\textrm{tgt}$]”와 “[$C_\textrm{src}$]”/”[$C_\textrm{tgt}$]”을 사용한다. 반대로, negative identifier는 이미지에 표시되지 않는 요소를 나타내기 위해 제안된 명명법이다. Negative identifier를 구성하기 위해 positive identifier에 부정자(ex. “not”, “without”, “except”)를 사용한다. 예를 들어, 소스 이미지에 대하여 “[$S^{-}$]”로 “[not $S_\textrm{tgt}$]”를 사용하고 “[$C^{-}$]”로 “[not $C_\textrm{tgt}$]”를 사용한다. 이러한 대조 프롬프트 디자인은 소스 이미지와 타겟 이미지 사이의 상당한 시각적 차이를 강조하고 제한된 주어진 데이터를 효과적으로 활용하여 disentangle된 학습을 촉진할 것이다.
Task 관련 데이터 $x_\textrm{src}$와 $x_\textrm{tgt}$ 외에도 보조 이미지셋 $x_\textrm{aux}$를 도입하여 disentanglement를 더욱 향상시킨다. 여기서 약 200개의 얼굴이 FFHQ에서 랜덤하게 샘플링되고
“a drawing with [$S_\textrm{src}$][not $S_\textrm{tgt}$] style of portrait”
이라는 동일한 프롬프트로 레이블이 지정된다. $x_\textrm{aux}$와 $x_\textrm{src}$의 프롬프트 간의 대조는 소스 콘텐츠를 descriptor “portrait” 대신 identifier “[$C^{+}$]”/”[$C^{-}$]”“로 인코딩하고 $x_\textrm{src}$와 $x_\textrm{tgt}$ 간의 스타일 구분을 강화하는 데 도움이 된다.
요약하면 각 이미지에 해당하는 프롬프트를 다음과 같이 설정한다.
- 소스 이미지의 프롬프트 \(\mathcal{P}_\textrm{src}\):
“a drawing with [$S_\textrm{src}$][not $S_\textrm{tgt}$] style of [$C_\textrm{src}$][not $C_\textrm{tgt}$] portrait”
- 타겟 이미지의 프롬프트 \(\mathcal{P}_\textrm{tgt}\):
“a drawing with [$S_\textrm{tgt}$][not $S_\textrm{src}$] style of [$C_\textrm{tgt}$][not $C_\textrm{src}$] portrait”
- 보조 이미지 셋의 프롬프트 \(\mathcal{P}_\textrm{aux}\):
“a drawing with [$S_\textrm{src}$][not $S_\textrm{tgt}$] style of portrait”
Triple Reconstruction Loss
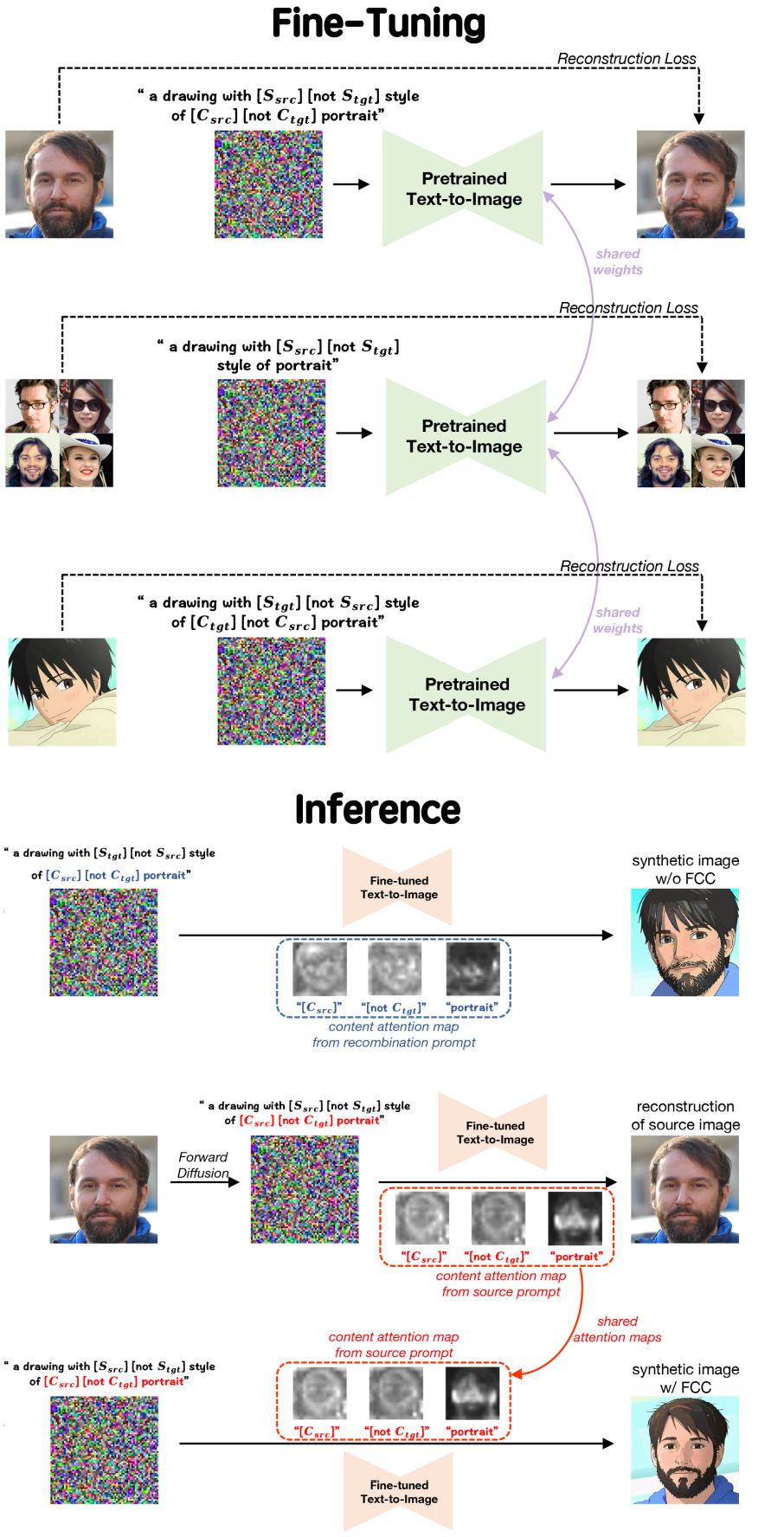
Diffusion model의 fine-tuning은 이미지 편집 및 image-to-image transition과 같은 많은 사용 사례와 관련된 강력한 기술이다. Identifier가 의도한 대로 작동하도록 하려면 텍스트-이미지 쌍 \(\{(\mathcal{P}_i, x_i)\}_i \in \{\textrm{src},\textrm{tgt},\textrm{aux}\}\)을 사용하여 이 간단한 접근 방식을 선택한다. Triple reconstruction loss로 text-to-image 모델을 튜닝하여 개별 identifier에 다른 정보를 주입한다.
\[\begin{aligned} &\min_{theta} \mathbb{E}_{z_\textrm{src}, z_\textrm{tgt}, z_\textrm{aux}, \epsilon, t} \| \epsilon - \epsilon_\theta (z_\textrm{src}^t, t, \gamma_\textrm{src}) \| \\ &\quad + \| \epsilon - \epsilon_\theta (z_\textrm{tgt}^t, t, \gamma_\textrm{tgt}) \| + \| \epsilon - \epsilon_\theta (z_\textrm{aux}^t, t, \gamma_\textrm{aux}) \| \end{aligned}\]여기서 $z_\textrm{src} = E(x_\textrm{src})$, \(\gamma_\textrm{src} = \phi (\mathcal{P}_\textrm{src})\)이며 tgt와 aux도 마찬가지다. IDL을 구현함으로써 주어진 이미지에 편향된 튜닝된 모델과 disentangled identifier를 얻을 수 있다.
Fine-grained Content Controller
제안된 IDL은 identifier의 재조합을 통해 소스 identity와 예술적 스타일을 효과적으로 융합한다.
- Stylized portrait의 프롬프트 $\mathcal{P}_\textrm{sty}$:
“a drawing with [$S_\textrm{tgt}$][not $S_\textrm{src}$] style of [$C_\textrm{src}$][not $C_\textrm{tgt}$] portrait”
그럼에도 불구하고, 소스 얼굴과 높은 상관관계가 있는 합성은 포즈와 소스 이미지의 일부 얼굴 feature 측면에서 눈에 띄는 다양성을 나타낸다. 이러한 다양성은 추가 사용자 지정 옵션을 제공할 수 있지만 모델이 소스 얼굴을 정확하게 캡처하는 예술적인 초상화를 일관되게 생성하는 것이 바람직하다. 이 문제를 완화하기 위해 소스 이미지의 섬세한 디테일을 합성 이미지로 추가 전송하는 Fine-grained Content Controller (FCC) 모듈을 도입한다. FCC는 cross attention control을 고안하고 텍스트 프롬프트를 보강하여 stylize된 초상화의 콘텐츠 attention map이 소스 얼굴의 콘텐츠 attention map과 밀접하게 일치하도록 한다.
Cross Attention Control
LDM은 cross attention 메커니즘을 활용하여 조건부 텍스트 feature를 기반으로 latent feature를 수정한다. 텍스트 임베딩 $\gamma \in \mathbb{R}^{s \times d_1}$과 latent feature $z \in \mathbb{R}^{hw \times d_2}$가 주어진다고 하자. 여기서 $s$는 토큰 수를 나타내고 $h$와 $w$는 latent feature의 높이와 너비이며, $d_1$과 $d_2$는 각각 feature의 차원이다. Cross attention은 먼저 query $Q = z W^q$, key $K = \gamma W^k$, value $V = \gamma W^v$를 계산한다. 그런 다음 latent feature는 다음에 의해 업데이트된다.
\[\begin{equation} M(z, \gamma) = \textrm{softmax} \bigg( \frac{QK^\top}{\sqrt{d}} \bigg) \\ \textrm{Attn} (z, \gamma) = M (z, \gamma) V \end{equation}\]여기서 $d$는 key와 query feature의 차원이다.
Prompt-to-prompt 논문은 attention map $M$이 합성 이미지의 공간적 레이아웃에 강한 영향을 미친다는 것을 발견하였다. 이에 저자들은 얼굴 도메인에서 소스 이미지의 attention mask로 합성 이미지의 attention mask를 제한하여 stylize된 인물 사진의 포즈와 얼굴 디테일을 제어하도록 영감을 받았다. 구체적으로, \(\mathcal{P}_\textrm{src}\)와 \(\mathcal{P}_\textrm{sty}\)에 의해 유발되는 LDM의 피드포워드 프로세스를 고려하면 latent feature와 텍스트 feature는 각각 $(z_\textrm{sty}, z_\textrm{src})$와 $(\gamma_\textrm{sty}, \gamma_\textrm{src})$이다. Cross attention을 다음과 같이 조건 형식으로 수정한다.
\[\begin{equation} \textrm{Attn} (z_\textrm{sty}, \gamma_\textrm{sty}; z_\textrm{src}, \gamma_\textrm{src}) = M_\textrm{ctr} V_\textrm{sty} \\ \quad \textrm{where } M_\textrm{ctr}^i = \begin{cases} M_\textrm{src}^i & \quad i \in \textrm{Content Index} \\ M_\textrm{sty}^i & \quad \textrm{otherwise} \end{cases} \end{equation}\]$M_\textrm{sty}$와 $M_\textrm{src}$는 해당 텍스트 feature와 latent feature에 의해 계산된 attention map이며, 위첨자 $i$는 행렬의 $i$번째 열을 나타내고 Content Index는 \(\mathcal{P}_\textrm{src}\)의 “[$C_\textrm{src}$]”, “[not $C_\textrm{tgt}$]”, “portrait” 인덱스를 포함한다. \(\mathcal{P}_\textrm{src}\)와 \(\mathcal{P}_\textrm{sty}\)의 토큰은 길이가 같으므로 FCC는 해당 콘텐츠 identifier의 attention map을 실제로 교환하여 stylize된 초상화의 콘텐츠를 소스 이미지 쪽으로 가져온다.
Augmented Text Prompt
텍스트 프롬프트는 LDM에 대한 합성 내용을 제어하는 데 중요한 요소이며 품질을 개선하면 일반적으로 합성의 semantic 디테일이 직접 향상된다. IDL에서 얻은 disentangled identifier를 활용하여 stylize된 초상화에 대한 더 나은 사용자 정의 및 제어를 제공하는 증강된 텍스트 프롬프트(augmented text prompt)를 도입한다. Identifier “[$C$]”와 $n \in \mathbb{Z}^{+}$가 주어지면, identifier를 $n$번 반복하는 것으로 augmented identifier “[$C$]”$\ast n$을 정의한다. 증강된 텍스트 프롬프트 \(\mathcal{P}_\textrm{src}^\textrm{aug}\)와 \(\mathcal{P}_\textrm{sty}^\textrm{aug}\)는 다음과 같이 augmented identifier로 구성된다.
- 소스 얼굴의 증강된 프롬프트 \(\mathcal{P}_\textrm{src}^\textrm{aug}\):
“a drawing with ([$S_\textrm{src}$][not $S_\textrm{tgt}$])$\ast n_s$ style of ([$C_\textrm{src}$][not $C_\textrm{tgt}$])$\ast n_c$ portrait”
- Stylize된 얼굴의 증강된 프롬프트 \(\mathcal{P}_\textrm{sty}^\textrm{aug}\):
“a drawing with ([$S_\textrm{tgt}$][not $S_\textrm{src}$])$\ast n_s$ style of ([$C_\textrm{src}$][not $C_\textrm{tgt}$])$\ast n_c$ portrait”
\(\mathcal{P}_\textrm{src}\)와 \(\mathcal{P}_\textrm{sty}\) 대신 \(\mathcal{P}_\textrm{src}^\textrm{aug}\)를 사용하여 소스 얼굴을 재구성하고 \(\mathcal{P}_\textrm{sty}^\textrm{aug}\)를 사용하여 cross attention control를 통해 stylize된 초상화를 생성한다. Stylization 정도와 identity 보존을 제어하기 위해 두 개의 hyperparameter인 $n_s$와 $n_c$가 도입되었다. 학습 중에 사용되는 단일 identifier와 비교할 때 $n_s$와 $n_c$의 균형이 더 나은 효과를 가져올 것이다. 사실 두 hyperparameter의 최적값을 결정하는 것은 복잡하지 않다. 실험을 통해 $n_s$와 $n_c$를 작은 값($\le 3$)으로 설정하면 만족스러운 결과를 얻을 수 있음을 알 수 있다.
Inference with FCC
이를 바탕으로 FCC로 생성하는 과정은 다음과 같이 요약할 수 있다.
- 소스 이미지의 noisy latent $z_\textrm{src}^T$를 얻기 위해 forward process를 수행한다. 랜덤 Gaussian noise와 비교할 때 $z_\textrm{src}^T$는 $x_\textrm{src}$를 복원하기 전에 더 나은 prior를 제공한다.
- 그런 다음 $z_\textrm{src}^T$에서 시작하여 \(\mathcal{P}_\textrm{src}^\textrm{aug}\)에 의해 프롬프트되는 reverse process를 수행한다.
- 다시 한 번 $z_\textrm{src}^T$에서 시작하여 \(\mathcal{P}_\textrm{sty}^\textrm{aug}\)에 의해 stylize된 초상화를 합성하도록 유도하는 reverse process를 수행하는 동시에 조건부 cross attention을 구현하여 소스 이미지에서 세분화된 디테일를 가져온다.
Experiments
- 데이터셋: LAION-5B
- Implementation Details
- IDL: Adam optimizer, learning rate $10^{-6}$, 400 iteration
- FCC: $n_s = 3$, $n_c = 1$, scale guidance 7.5, LDM과 동일한 hyperparameter
1. Comparison with SOTA methods
Qualitative Comparison

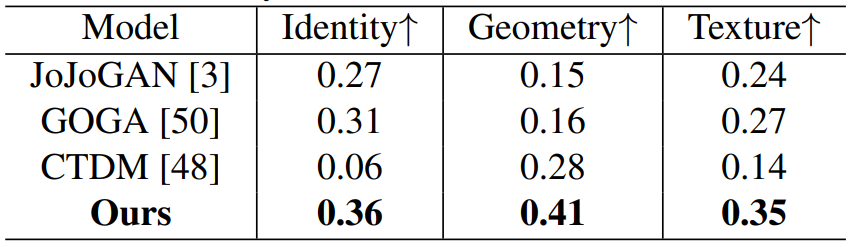
Quantitative Comparison
2. Ablation Study
Effect of Contrastive Disentangled Prompt Template

Effect of Fine-grained Content Controller

Hyper-parameters in Augmented Text Prompt