[논문리뷰] StyleSwin: Transformer-based GAN for High-resolution Image Generation
CVPR 2022. [Paper] [Github]
Bowen Zhang, Shuyang Gu, Bo Zhang, Jianmin Bao, Dong Chen, Fang Wen, Yong Wang, Baining Guo
University of Science and Technology of China | Microsoft Research Asia
20 Dec 2021

Introduction
이미지 생성 모델링은 최근 몇 년 동안 극적인 발전을 보였으며 그 중 GAN은 틀림없이 고해상도 이미지 합성에서 가장 강력한 품질을 제공한다. 초기 시도는 적절한 정규화 또는 adversarial loss 디자인을 통해 학습을 안정화하는 데 초점을 맞추었지만 최근의 눈에 띄는 성능 향상은 주로 self-attention 채택, 공격적인 모델 확장, 스타일 기반 generator와 같은 더 강력한 모델링 용량을 목표로 하는 아키텍처 수정에 기인한다. 최근 transformer의 광범위한 성공에 힘입어 몇몇 연구들은 표현력 증가와 장거리 의존성을 모델링하는 능력이 복잡한 이미지 생성에 도움이 될 수 있기를 바라며 순수 transformer를 사용하여 생성 네트워크를 구축하려고 시도했지만 아직 특히 고해상도에서 고품질 이미지 생성은 여전히 어려운 일이다.
본 논문은 고해상도 이미지 생성을 위한 경쟁력 있는 GAN을 구성하기 위해 transformer를 사용할 때 핵심 요소를 탐구하는 것을 목표로 한다. 첫 번째 장애물은 네트워크가 고해상도 (ex. 1024$\times$1024)로 확장될 수 있도록 2차 계산 비용을 길들이는 것이다. Window 기반 로컬 attention이 계산 효율성과 모델링 능력 사이의 균형을 맞추기 때문에 Swin transformer를 기본 빌딩 블록으로 활용한다. 이와 같이, 더 높은 스케일을 위해 point-wise MLP로 줄이는 것과는 반대로 모든 이미지 스케일을 특성화하기 위해 증가된 표현력을 활용할 수 있으며 합성은 섬세한 디테일을 가진 고해상도로 확장 가능하다. 게다가, 로컬 attention은 로컬 inductive bias를 도입하므로 generator가 처음부터 이미지의 규칙성을 다시 학습할 필요가 없다. 이러한 장점으로 인해 간단한 transformer 네트워크가 convolution보다 훨씬 뛰어난 성능을 발휘한다.
본 논문은 SOTA와 경쟁하기 위해 세 가지 아키텍처 적응을 추가로 제안한다.
- Transformer GAN에 대한 다양한 스타일 주입 접근 방식을 경험적으로 비교하면서 스타일 기반 아키텍처에서 로컬 attention을 사용하여 생성 모델 용량을 강화한다.
- 로컬 attention으로 인한 제한된 receptive field를 확대하기 위해 double attention을 도입한다. 여기서 각 레이어는 로컬 window와 shifted window 모두에 attend하여 많은 계산 오버헤드 없이 generator 용량을 효과적으로 개선한다.
- 이미지 합성에 절대적 위치를 활용할 수 있도록 각 레이어에 sinusoidal positional encoding을 도입한다.
위의 기술을 갖춘 StyleSwin이라고 하는 네트워크는 256$\times$256 해상도에서 유리한 생성 품질을 보여준다.
그럼에도 불구하고 저자들은 고해상도 이미지를 합성할 때 블로킹 아티팩트를 관찰하였다. 블록 방식으로 attention을 독립적으로 계산하면 공간적 일관성이 깨지기 때문에 이러한 아티팩트가 발생한다. 즉, 합성 네트워크에 적용될 때 block-wise attention는 특별한 처리가 필요하다. 저자들은 이러한 블로킹 아티팩트를 해결하기 위해 다양한 솔루션을 경험적으로 조사하여 스펙트럼 도메인에서 아티팩트를 검사하는 wavelet discriminator가 아티팩트를 효과적으로 억제하여 transformer 기반 GAN이 시각적으로 만족스러운 출력을 생성할 수 있음을 발견했다.
Method
1. Transformer-based GAN architecture
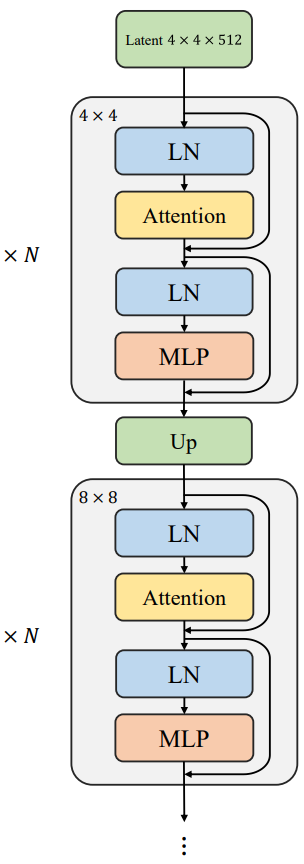
Latent 변수 $z \sim \mathcal{N} (0, I)$을 입력으로 받고 점진적으로 transformer 블록의 cascade를 통해 feature map을 업샘플링하는 위 그림과 같은 간단한 generator 아키텍처에서 시작한다.
2차 계산 복잡도로 인해 고해상도 feature map에서 전체 attention을 계산하는 것은 경제적이지 않다. 로컬 attention은 계산 효율성과 모델링 용량 사이의 trade-off를 달성하는 좋은 방법이다. 겹치지 않는 window에서 로컬로 multi-head self-attention (MSA)을 계산하는 기본 빌딩 블록으로 Swin transformer를 채택한다. 인접한 window 간의 정보 상호 작용을 위해 Swin transformer는 대체 블록으로 shifted window 파티션을 사용한다. 특히 레이어 $l$의 입력 feature map $x^l \in \mathbb{R}^{H \times W \times C}$가 주어지면 연속되는 Swin 블록은 다음과 같이 작동한다.
\[\begin{aligned} \hat{x}^l &= \textrm{W-MSA} (\textrm{LN} (x^l)) + x^l \\ x^{l+1} &= \textrm{MLP} (\textrm{LN} (\hat{x}^l)) + \hat{x}^l \\ \hat{x}^{l+1} &= \textrm{SW-MSA} (\textrm{LN} (x^{l+1})) + x^{l+1} \\ x^{l+2} &= \textrm{MLP} (\textrm{LN} (\hat{x}^{l+1})) + \hat{x}^{l+1} \end{aligned}\]여기서 W-MSA와 SW-MSA는 각각 일반 window와 shifted window 분할 하에서의 window 기반 MSA를 나타내고 LN은 layer normalization을 나타낸다. 이러한 block-wise attention는 이미지 크기에 대한 선형 계산 복잡도를 유도하기 때문에 네트워크는 미세 구조가 이러한 유능한 transformer로 모델링될 수 있는 고해상도 생성으로 확장 가능하다.
Discriminator는 adversarial training의 안정성에 심각한 영향을 미치기 때문에 convolution 기반 discriminator를 직접 사용한다. 실험에서 저자들은 이 기본 아키텍처에서 단순히 convolution을 transformer 블록으로 교체하면 향상된 모델 용량으로 인해 보다 안정적인 학습을 얻을 수 있음을 발견했다. 그러나 이러한 순진한 아키텍처는 transformer 기반 GAN을 SOTA와 경쟁하게 만들 수 없다.
Style injection
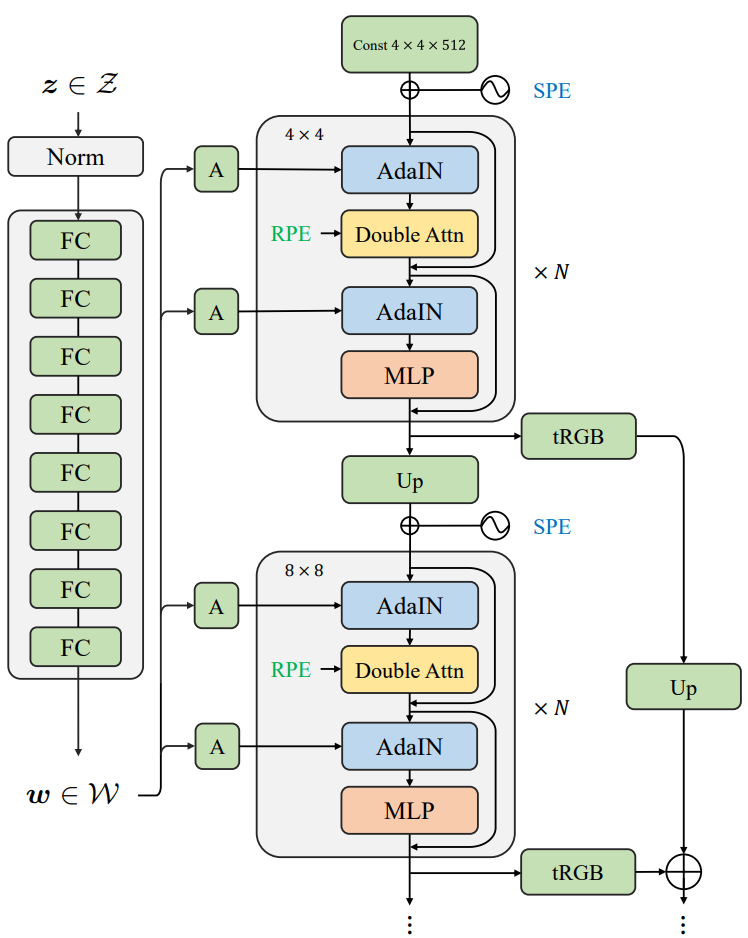
먼저 위 그림과 같이 generator를 스타일 기반 아키텍처에 적용하여 모델 능력을 강화한다. 비선형 매핑 $f : \mathcal{Z} \rightarrow \mathcal{W}$를 학습하여 latent code $z$를 $\mathcal{Z}$ space에서 $\mathcal{W}$ space로 매핑하여 기본 합성 네트워크에 주입되는 스타일을 지정한다. 저자들은 다음과 같은 스타일 주입 방식을 조사하였다.
- AdaNorm: 정규화 후 feature map의 평균과 분산을 변조한다. 저자들은 instance normalization (IN), batch normalization (BN), layer normalization (LN), RMSnorm을 포함한 여러 정규화 변형을 연구하였다. RMSNorm은 LN의 평균 중심화를 제거하므로 $\mathcal{W}$ code의 분산만 예측한다.
- Modulated MLP: Feature map을 변조하는 대신 linear layer의 가중치를 변조할 수도 있다. 구체적으로 transformer 블록 내 feed-forward network의 채널별 가중치 크기를 재조정한다. 이러한 스타일 주입은 AdaNorm보다 속도가 빠르다.
- Cross-attention: transformer가 $\mathcal{W}$ space에서 파생된 스타일 토큰에 추가로 attend하는 transformer별 스타일 주입

위 표는 고해상도 합성을 위해 batch size가 손상되기 때문에 AdaBN을 사용한 학습이 수렴하지 않는 것을 제외하고 위의 모든 스타일 주입 방법이 생성 모델링 용량을 크게 향상시킨다는 것을 보여준다. Modulated MLP와 cross attention은 스타일 정보를 한 번만 사용할 수 있지만, 반면 AdaNorm은 네트워크가 attention 블록과 FFN에서 스타일 정보를 두 번 활용할 수 있기 때문에 더 충분한 스타일 주입을 제공한다. 또한 AdaBN, AdaLN과 비교하여 AdaIN은 feature map이 정규화되고 독립적으로 변조되므로 더 미세하고 충분한 feature 변조를 제공하므로 기본적으로 AdaIN을 선택한다.
Double attention
그럼에도 불구하고 로컬 attention을 사용하면 형상을 캡처하는 데 중요한 장거리 의존성을 모델링하는 능력이 희생된다. Swin 블록이 사용하는 window 크기를 $\kappa \times \kappa$라고 하면 shifted window 전략으로 인해 receptive field가 Swin 블록을 하나 더 사용하여 각 차원에서 $\kappa$만큼 증가한다. Swin 블록을 사용하여 64 $\times$ 64 feature map을 처리하고 기본적으로 $\kappa = 8$을 선택한 다음 전체 feature map에 걸쳐 $64 / \kappa = 8$개의 변환기 블록이 필요하다고 가정한다.
확대된 receptive field를 위해 단일 transformer 블록이 로컬 window와 shifted window의 컨텍스트에 동시에 attend할 수 있도록 하는 double attention을 도입한다.
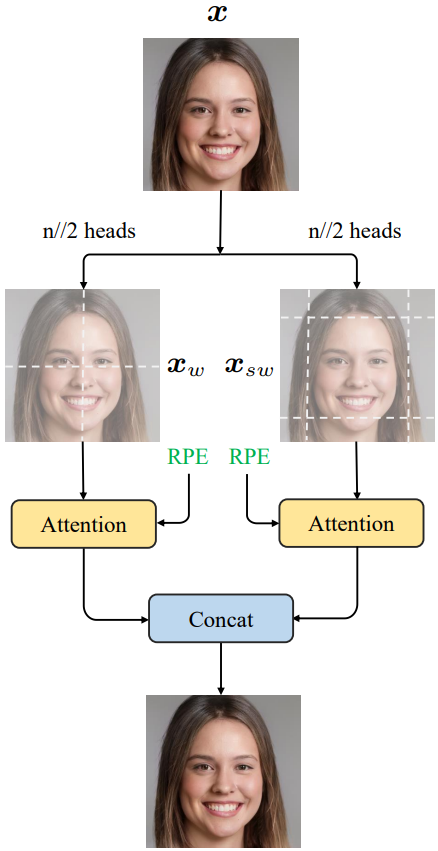
위 그림에서 볼 수 있듯이 $h$개의 attention head를 두 그룹으로 나눈다. Head의 전반부는 일반 window attention을 수행하는 반면 후반부는 shifted window attention을 계산한다. 이 두 그룹의 결과는 출력을 형성하기 위해 추가로 concat된다. 구체적으로, 일반 window 분할과 shifted window 분할 하에서의 겹치지 않는 패치를 각각 $x_w$와 $x_{sw}$로 표시하자. 즉, $x_w, x_{sw} \in \mathbb{R}^{\frac{HW}{\kappa^2} \times \kappa \times \kappa \times C}$라고 하면 double attention은 다음과 같다.
여기서 $W^O \in \mathbb{R}^{C \times C}$는 head들을 출력하기 위해 혼합하는 projection matrix이다. 위 식의 attention head는 다음과 같이 계산할 수 있다.
\[\begin{equation} \textrm{head}_i = \begin{cases} \textrm{Attn} (x_w W_i^Q, x_w W_i^K, x_w W_i^V) & \quad i \le \lfloor \frac{h}{2} \rfloor \\ \textrm{Attn} (x_{sw} W_i^Q, x_{sw} W_i^K, x_{sw} W_i^V) & \quad i > \lfloor \frac{h}{2} \rfloor \end{cases} \end{equation}\]여기서 $W_i^Q, W_i^K, W_i^V \in \mathbb{R}^{C \times (C/h)}$는 각각 $i$번째 head에 대한 query, key, value projection matrix이다. 각 차원의 receptive field가 하나의 추가 double attention 블록으로 $2.5\kappa$배 증가하여 더 큰 컨텍스트를 보다 효율적으로 캡처할 수 있다. 그래도 64$\times$64 입력의 경우 전체 feature map을 처리하려면 4개의 transformer 블록이 필요하다.
Local-global positional encoding
기본 Swin 블록에서 채택한 상대 위치 인코딩 (RPE)은 픽셀의 상대 위치를 인코딩하며 판별적 task에 중요하다. 이론적으로 RPE가 있는 multi-head local attention layer는 window 크기 커널의 모든 convolution layer를 표현할 수 있다. 그러나 convolution layer를 RPE를 사용하는 transformer로 대체할 때 한 가지 문제가 발생한다. ConvNet은 zero padding의 단서를 활용하여 절대 위치를 추론할 수 있지만 RPE를 사용하는 Swin 블록에는 이러한 기능이 없다. 한편 입과 같은 특정 구성 요소의 합성은 공간 좌표에 크게 의존하기 때문에 generator가 절대 위치를 인식하도록 하는 것이 필수적이다.
이를 고려하여 각 스케일에 sinusoidal position encoding (SPE)을 도입한다. 특히 스케일 업샘플링 후 다음 인코딩에 feature map이 추가된다.
\[\begin{equation} [\underbrace{\sin (\omega_0 i), \cos (\omega_0 i), \cdots}_{\textrm{horizontal dimension}}, \underbrace{\sin (\omega_0 j), \cos (\omega_0 j), \cdots}_{\textrm{vertical dimension}}] \in \mathbb{R}^C \\ \textrm{where} \quad \omega_k = 1 / 10000^{2k} \end{equation}\]여기서 $(i, j)$는 2D 위치이다. 실제로 RPE와 SPE를 함께 사용하여 최대한 활용한다. 각 transformer 블록 내에 적용되는 RPE는 로컬 컨텍스트 내의 상대적 위치를 제공하는 반면 각 스케일에 도입된 SPE는 글로벌 위치를 알려준다.
2. Blocking artifact in high-resolution synthesis

위의 구조로 256$\times$256 이미지를 합성하여 SOTA 품질을 달성하지만, 이를 고해상도 합성에 직접 적용하면 위 그림과 같이 블로킹 아티팩트가 발생하여 이미지 품질에 심각한 영향을 미친다. Bilinear upsampling과 안티앨리어싱 필터를 사용하므로 이 아티팩트는 transposed convolution으로 인해 발생하는 체크보드 아티팩트가 아니다.
저자들은 블로킹 아티팩트가 transformer에 의해 발생한다고 추측하였다. 이를 확인하기 위해 64$\times$64에서 시작하는 attention 연산자를 제거하고 고주파 디테일을 특성화하기 위해 MLP만 사용하면, 아티팩트가 없는 결과를 얻는다. 더 나아가, 저자들은 이러한 아티팩트가 로컬 attention의 window 크기와 강한 상관관계가 있는 주기적인 패턴을 보인다는 것을 발견했다. 따라서 공간 일관성을 깨고 블로킹 아티팩트를 유발하는 것이 window 방식 처리라고 확신하였다.
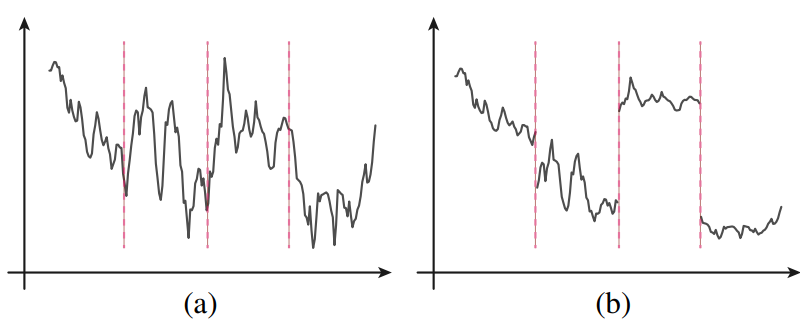
단순화하기 위해 위 그림의 1D 예시를 고려할 수 있다. (a)는 입력 신호이고 (b)는 window-wise attention 후의 출력 신호이다. Attention은 Strided window에서 로컬로 계산된다. 연속 신호의 경우 동일한 window 내의 값이 softmax 연산 후에 균일해지는 경향이 있으므로 window 방향 로컬 attention은 불연속적인 출력을 생성할 가능성이 높으므로 인접 window의 출력이 다소 뚜렷하게 나타난다. 2D 예시는 블록별 인코딩으로 인한 JPEG 압축 아티팩트와 유사하다.
3. Artifact suppression
Artifact-free generator
저자들은 먼저 generator를 개선하여 아티팩트를 줄이려고 시도하였다.
- Token sharing: 블로킹 아티팩트는 별개의 window에서 attention 컴퓨팅이 사용하는 key와 value가 갑자기 변경되기 때문에 발생하므로 window가 토큰을 공유하도록 한다. 그러나 특정 window에 독점적인 토큰이 항상 존재하기 때문에 여전히 아티팩트가 눈에 띈다.
- Sliding window attention: Sliding attention으로 generator를 학습시키는 것은 비용이 너무 많이 들기 때문에 inference에서만 sliding window만 채택한다.
- Reduce to MLPs on fine scales: Self attention을 제거하고 고주파 디테일을 모델링하는 능력을 희생하는 대가로 미세 구조 합성을 위해 point-wise MLP에 순전히 의존할 수 있다.
Artifact-suppression discriminator
실제로 256$\times$256 해상도의 초기 학습 단계에서 블로킹 아티팩트가 관찰되지만 학습이 진행됨에 따라 점차 사라진다. 즉, window 기반 attention이 아티팩트를 생성하는 경향이 있지만 generator는 아티팩트가 없는 솔루션을 제공할 수 있는 능력이 있다. Discriminator가 고주파 디테일 검사하지 못하기 때문에 아티팩트가 고해상도 합성을 방해한다. 이것은 아티팩트 억제를 위해 더 강력한 discriminator에 의지하도록 한다.

- Patch discriminator: Patch discriminator는 제한된 receptive field를 가지고 있으며 특히 로컬 구조에 페널티를 주는 데 사용할 수 있다.
- Total variation annealing: 네트워크의 아티팩트를 억제하기 위해 학습 시작 시 큰 total variation loss를 적용한다. 그런 다음 loss 가중치는 학습이 끝날 때까지 선형적으로 0으로 감소한다. 아티팩트를 완전히 제거할 수 있지만 이러한 제약은 과도하게 평활화된 결과를 선호하고 고주파 디테일에 불가피하게 영향을 미친다.
- Wavelet discriminator: 아래 그림에서 볼 수 있듯이 주기적인 아티팩트 패턴은 스펙트럼 영역에서 쉽게 구분할 수 있다. (b)는 아티팩트가 있는 이미지의 푸리에 스펙트럼이고 (c)는 아티팩트가 없는 이미지의 푸리에 스펙트럼이다. 이에 영감을 받아 공간적 discriminator를 보완하기 위해 wavelet discriminator에 의지한다.
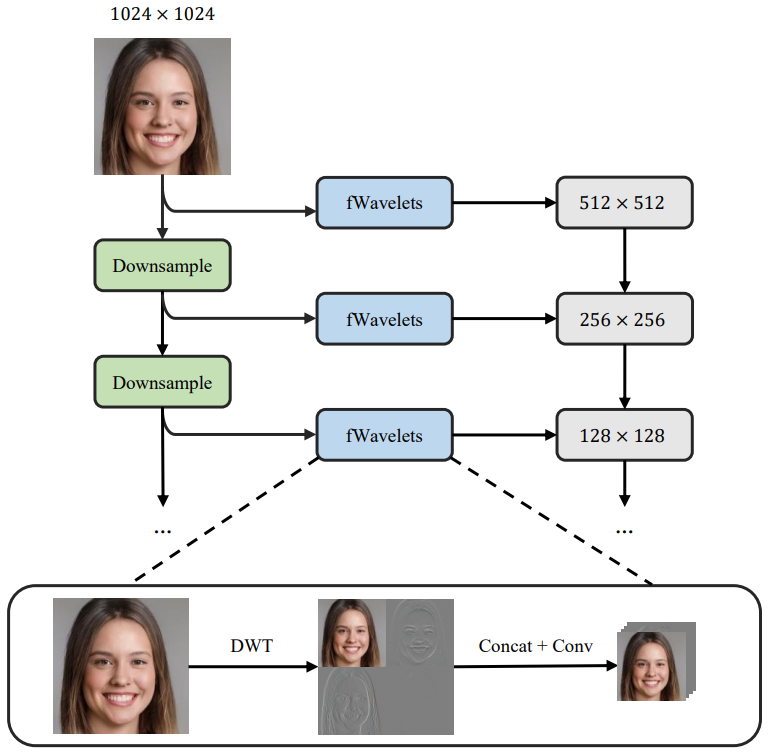
위 그림은 wavelet discriminator의 구조이다. Discriminator는 입력 이미지를 계층적으로 다운샘플링하고 각 스케일에서 discrete wavelet decomposition 후 실제 이미지에 대한 주파수 불일치를 검사한다. 이러한 wavelet discriminator는 블로킹 아티팩트를 방지하는 데 매우 효과적이다. 한편, 분포 매칭에 부작용을 일으키지 않아 generator가 풍부한 디테일을 생성하도록 효과적으로 가이드한다.
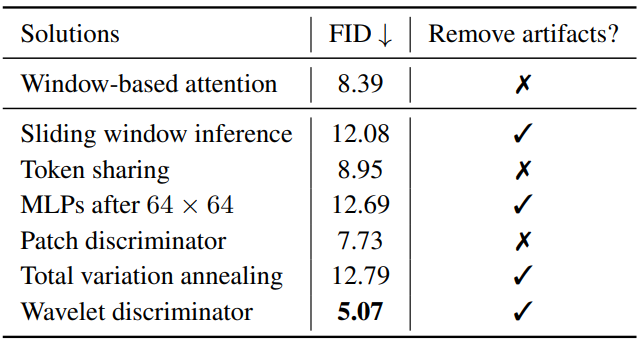
위 표는 위의 아티팩트 억제 방법을 비교하여 시각적 아티팩트를 완전히 제거할 수 있는 네 가지 접근 방식이 있음을 보여준다. 그러나 sliding window inference는 학습-테스트 차이로 인해 어려움을 겪는 반면, MLP는 고해상도 단계에서 미세한 디테일을 합성하지 못하여 둘 다 더 높은 FID로 이어진다. 한편, annealing에 따른 total variation은 여전히 FID를 악화시킨다. 이에 비해 wavelet transformer는 가장 낮은 FID를 달성하고 가장 시각적으로 만족스러운 결과를 산출한다.
Experiments
- 데이터셋: CelebA-HQ, LSUN Church, FFHQ
- 구현 디테일
- optimizer: Adam ($\beta_1$ = 0.0, $\beta_2$ = 0.99)
- learning rate: TTUR 사용
- generator: $5 \times 10^{-5}$
- discriminator: $2 \times 10^{-4}$
- batch size: 256$\times$256는 32, 1024$\times$1024는 16
- 8개의 32GB V100 GPU 사용
1. Quantitative results
다음은 256$\times$256 해상도에서 SOTA 이미지 생성 방법들과 비교한 표이다.
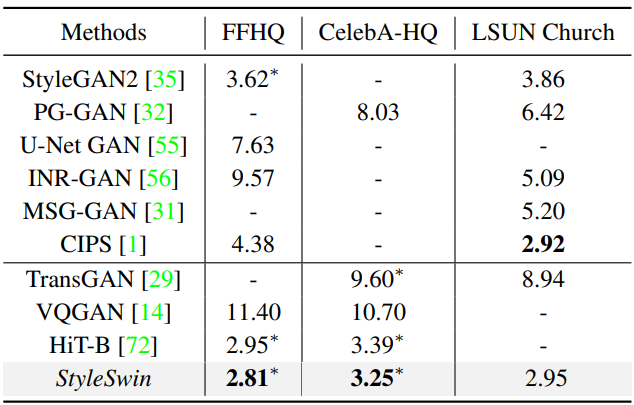
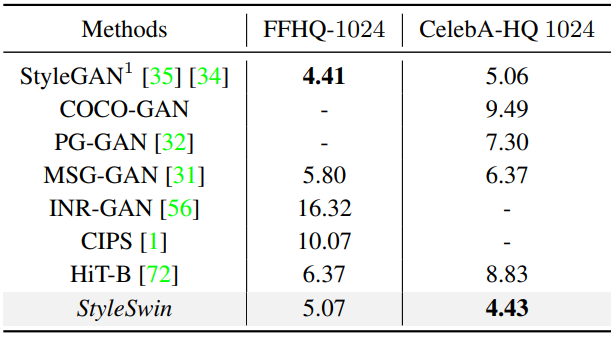
다음은 1024$\times$1024 해상도에서 SOTA 이미지 생성 방법들과 비교한 표이다.
2. Qualitative results
다음은 FFHQ-1024 (a)와 CelebA-HQ-1024 (b)로 학습된 StyleSwin이 생성한 이미지 샘플들이다.

다음은 LSUN Church-256으로 학습된 StyleSwin이 생성한 이미지 샘플들이다.

3. Ablation
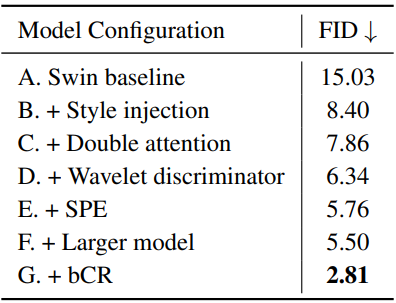
다음은 FFHQ-256에서 수행한 ablation study의 결과이다.
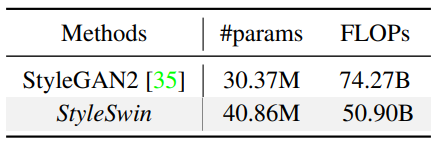
4. Parameters and Throughput
다음은 StyleGAN2와 파라미터 수와 FLOPs를 비교한 표이다.