[논문리뷰] StyleNAT: Giving Each Head a New Perspective
arXiv 2022. [Paper] [Github]
Steven Walton, Ali Hassani, Xingqian Xu, Zhangyang Wang, Humphrey Shi
SHI Labs | UT Austin | Picsart AI Research (PAIR)
10 Nov 2022
Introduction
적대적으로 학습된 생성 이미지 모델링은 오랫동안 CNN에 의해 지배되었다. 그러나 최근에는 Transformer 기반 GAN과 Diffusion 기반 GAN과 같은 새로운 아키텍처로 전환하는 데 진전이 있었다. 이 외에도 diffusion model과 VAE와 같은 다른 생성 모델링 방법은 GAN이 설정한 표준을 따라잡고 있다. Diffusion model과 VAE는 학습 분포의 밀도를 근사화할 수 있으므로 더 많은 feature를 통합할 수 있고 더 높은 재현율을 가질 수 있다는 점에서 몇 가지 장점이 있다. 그러나 이러한 방법은 GAN에 비해 훨씬 더 많은 정보를 처리해야 하므로 계산 비용이 많이 들고 학습하기 어렵다는 큰 단점도 있다.
Convolution model은 로컬한 receptive field를 활용하는 이점이 있는 반면, self attention 메커니즘이 있는 transformer 기반 모델은 글로벌 receptive field를 활용하는 이점이 있다. 이 때문에 콘텐츠 의존 가중치와 장거리 의존성을 모델링하는 능력 덕분에 생성된 이미지의 품질을 높이는 데 도움이 되는 self attention이 자연스러운 선택이 될 것이기 때문에 transformer를 이미지 생성에 통합하려는 노력이 있었다. Transformer는 연산 집약적이며 학습하기 어렵다는 큰 단점이 있다. Self attention은 2차적으로 증가하는 메모리와 FLOPs를 수반한다. 이는 latent 구조 전체에 표준 transformer를 적용하는 것이 단순히 계산적으로 불가능할 수 있음을 의미한다. 이것이 초기 transformer 기반 GAN이 convolution 기반 GAN과 경쟁하는 데 어려움을 겪었던 이유 중 일부이다.
아주 최근에는 일반적으로 전체 feature space에 attend하지 않는 제한된 attention 메커니즘에 대한 추진이 있었다. 이렇게 함으로써 이러한 transformer들은 계산 부담을 줄이고 수렴에 도움이 될 수 있는 고정 크기 receptive field에 압력을 가한다. 이 중 가장 인기 있는 Swin Transformer는 windows self attention (WSA) 메커니즘을 사용한다. 이 shifted window는 global attention을 더 작은 겹치지 않는 패치로 분할하여 선형 시간 및 공간 복잡도를 가진다. StyleSwin은 convolution model을 따라잡은 최초의 Transformer 기반 GAN 중 하나였다. 스타일 기반 generator는 Swin의 WSA attention 메커니즘을 기반으로 구축되었다. 그 성공에도 불구하고 당시의 기존 SOTA GAN을 능가하는 데 실패했다.
그러나 localize된 attention 메커니즘에는 다른 비용이 수반된다. 글로벌하게 attend할 수 없기 때문에 장거리 의존성을 포착할 수 없다. 이것은 Dilated Neighborhood Attention (DiNA)와 같은 연구로 이어졌으며, 이는 localize된 self attention을 기반으로 하는 모델에서 이 문제를 해결하기 위해 제안되었다. 이 연구는 Neighborhood Attention (NA)를 더욱 확장하여 어떤 점에 대한 self attention을 nearest neighbor에 직접 국한시키는 효율적인 sliding-window attention 메커니즘을 도입했다. Sliding window가 제공하는 유연성 덕분에 NA/DiNA를 쉽게 확장하여 전체 feature map에 걸쳐 더 많은 글로벌 컨텍스트를 캡처할 수 있다.
본 논문에서는 고해상도 이미지 생성을 위해 latent 구조 전체에서 서로 다른 유리한 지점을 통합하고 분할하여 NA/DiNA의 attention head의 힘을 확장하고자 한다. Hydra-NA라고 하는 이 방법은 전체 transformer보다 더 많이 설계되었지만 이전 로컬 attention 메커니즘의 능력을 크게 확장하고 NA/DiNA에 대한 추가 계산 비용이 거의 없다. 이러한 분할과 다양한 kernel 및 dilation의 사용을 통해 이러한 head는 훨씬 더 풍부한 능력을 구조에 통합할 수 있으므로 주어진 latent 구조에서 얻을 수 있는 정보 이득을 증가시킨다. Hydra-NA 모듈은 NA 모듈의 유연성을 증가시켜 다양한 생성 task에서 학습하려는 데이터에 더 잘 적응할 수 있도록 한다.
본 논문은 효율적이고 유연한 이미지 생성 프레임워크인 StyleNAT를 제안한다. 이 프레임워크는 메모리 및 계산 효율성이 높을 뿐만 아니라 Hydra-NA 디자인을 통해 NA와 dilated 변형을 통해 다양한 데이터셋과 task에 적응할 수 있다.
Methodology
StyleNAT 네트워크 아키텍처는 StyleGAN2의 아키텍처를 밀접하게 따르는 StyleSwin의 네트워크 아키텍처를 밀접하게 따른다.
1. Motivation
현재 CNN 기반 GAN에는 고품질의 설득력 있는 이미지를 지속적으로 생성하기 어려운 몇 가지 제한 사항이 있다. 특히 CNN은 장거리 feature를 캡처하는 데 어려움이 있지만 로컬한 inductive bias가 강하고 평행이동과 회전에 동등하다. 따라서 로컬한 inductive bias와 글로벌한 inductive bias를 모두 가지면서 이 동등성을 유지하는 아키텍처를 통합해야 한다.
반면 transformer는 강력한 글로벌 inductive bias를 가지고 있고 평행이동에 동등하며 전체 장면에서 장거리 feature를 캡처할 수 있다. Transformer의 단점은 계산 비용이 많이 든다는 것이다. Attention 가중치를 생성하는 데 필요한 메모리와 계산이 2차적으로 증가하므로 순수한 transformer 기반 GAN을 구축하는 것은 불가능하다. 따라서 GAN의 장점을 가질 수 있을 뿐만 아니라 학습하기에 효율적이면서도 글로벌 정보를 포함할 수 있는 transformer와 같은 구조를 구축해야 한다.
2. Giving Heads a New Perspective
StyleNAT의 핵심에는 유연한 Hydra-NA 아키텍처가 있다. 글로벌 attention head는 장면의 다양한 부분에 attend하는 방법을 학습할 수 있지만, 로컬 attention 메커니즘의 receptive field가 감소한다는 것은 이러한 관점이 제한된 관점에서만 수행될 수 있음을 의미한다.
이러한 attnetion head의 힘을 확장하기 위해 StyleSwin은 attention head를 반으로 나눈다. 절반은 windowed self-attention (WSA)를 사용하고 다른 절반은 shifted window self-attention (SWSA)를 사용한다. 이 방법은 여전히 전체적인 이미지를 인식하지 못하고 더 많은 파티션을 제공하더라도 이러한 head가 취할 수 있는 관점에 제한이 있다는 한계가 있다. 또한 분할된 self attention은 평행이동 동등성을 깨뜨린다. Hydra-NA는 유사한 목표를 달성하기 위해 다른 접근 방식을 취한다. 각각의 attention head는 latent 구조에 대한 고유한 관점을 가질 수 있다. Dilation factor에 따라 로컬에서 글로벌로 확장된다. 따라서 유연한 building block으로 NA/DiNA를 활용한다.
StyleNAT의 핵심 디자인 철학은 attention head를 여러 그룹으로 분할하는 것이며, 이는 여러 dilated 형태의 localized attention을 활용할 수 있다. Multiple-headed attention은 각 head가 다른 학습 가능한 feature 집합에서 작동하도록 하여 표준 attention 메커니즘의 힘을 확장한다. 이 head의 능력을 확장하기 위해 latent 구조에 대해 서로 다른 유리한 지점을 가질 수 있는 메커니즘을 만든다. 프레임워크에서는 head가 다른 NA kernel 크기와 다른 DiNA dilation을 활용할 수 있다. 이를 통해 일부 head는 작고 로컬한 receptive field 내의 feature에 집중할 수 있고, 다른 head는 중간 크기의 receptive field에 집중할 수 있으며, 다른 head는 큰 receptive field에 집중할 수 있다.
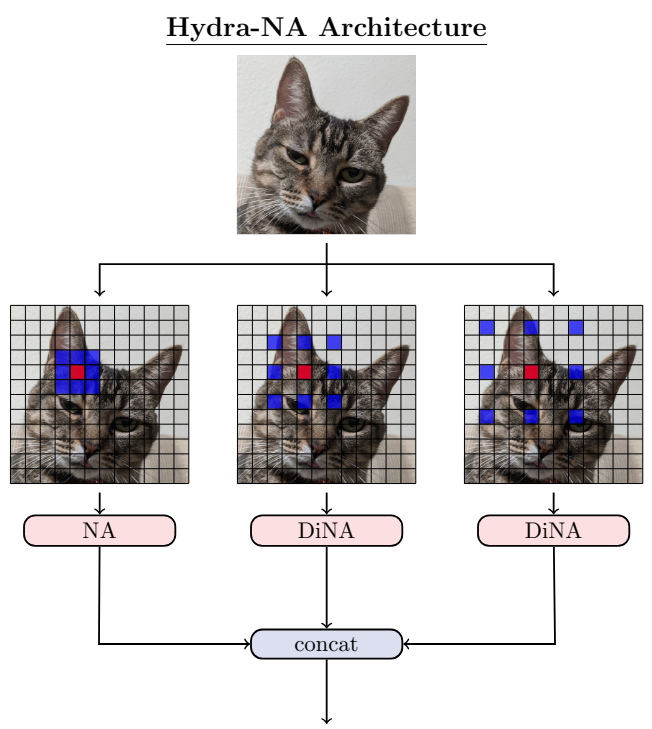
이 구조는 위 그림에 나와 있다. 그림에는 3개의 파티션이 표시되어 있지만 head 수를 초과하지 않는 한 임의의 수를 사용할 수 있다.
3. StyleNAT
해석 가능성의 모든 이점을 통합하기 위해 StyleGAN과 동일한 스타일 기반 아키텍처를 사용하지만 Hydra-NA를 사용하여 모델의 inductive power를 높이려고 한다. 이를 위해 저자들은 일정한 커널 크기인 7로 수렴하고 progressive dilation 체계를 포함하도록 선택했다.
이와 관련하여 파티션에는 dense 커널과 sparse 커널이 모두 있다. 저자들은 이 프레임워크를 사용하여 두 가지 주요 디자인을 선택하였다. 하나는 글로벌/sparse 커널과 결합된 로컬/dense 커널이 있는 이중 파티션이고, 다른 하나는 파티션 수에 따라 sparsity와 receptive field가 증가하는 progressive dilation 디자인이다.
Experiments
- 데이터셋: FFHQ, LSUN Church
1. FFHQ
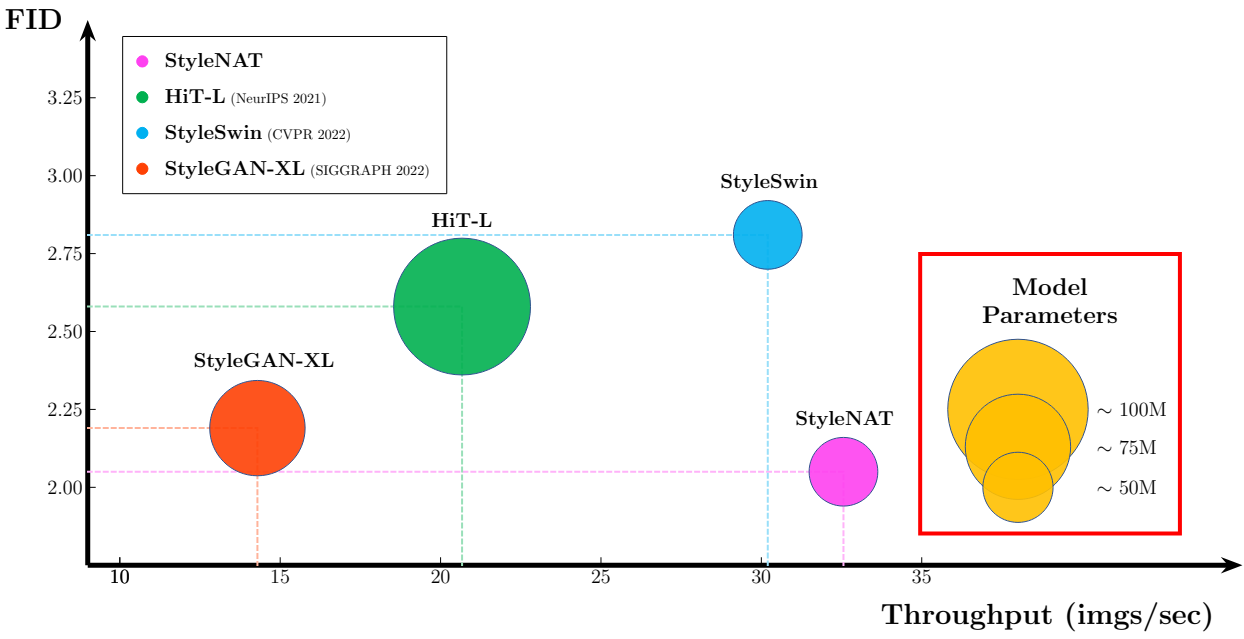
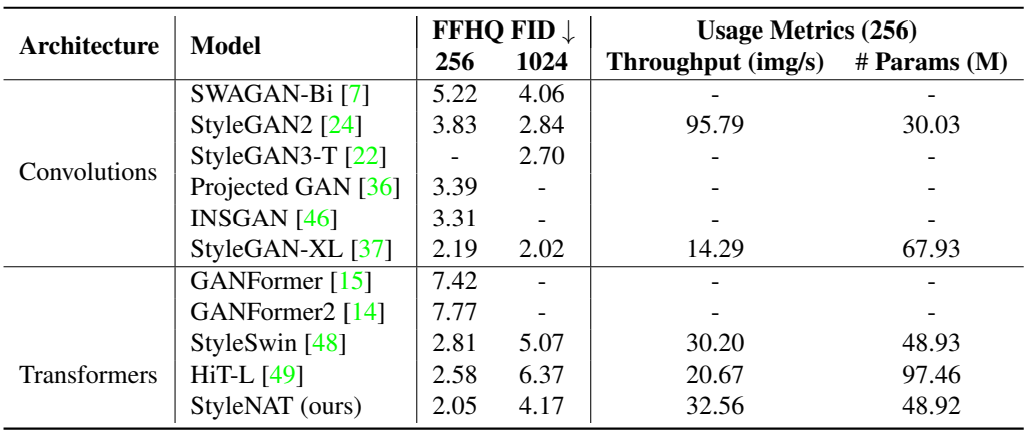
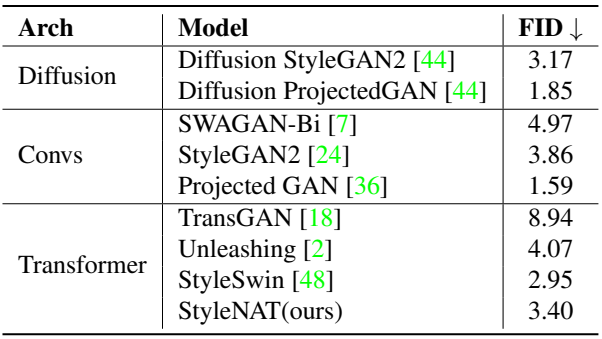
다음은 FFHQ에서의 FID50k 결과를 비교한 표이다.
다음은 FFHQ에 대한 샘플들이다.

2. LSUN Church
다음은 LSUN Church Outdoor (256)에서의 FID50k 결과를 비교한 표이다.
다음은 LSUN Church에 대한 샘플들이다.

3. Ablation
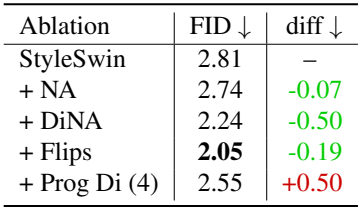
다음은 FFHQ-256에서의 ablation study 결과이다. Flips는 horizontal flip augmentation, Prog Di (4)는 4개로 분할된 progressive dilation을 뜻한다.
다음은 head 분할 수에 대한 비교이다. (LSUN Church)