[논문리뷰] StyleGAN-XL: Scaling StyleGAN to Large Diverse Datasets
arXiv 2023. [Paper] [Page] [Github]
Axel Sauer, Katja Schwarz, Andreas Geiger
University of Tübingen and Max Planck Institute for Intelligent Systems
1 Feb 2022

Introduction
컴퓨터 그래픽은 오랫동안 semantic 속성을 직접 제어할 수 있는 고해상도의 사실적인 이미지를 생성하는 데 관심을 가져왔다. 최근까지 주요 패러다임은 세심하게 설계된 3D 모델을 만든 다음 사실적인 카메라 및 조명 모델을 사용하여 렌더링하는 것이었다. 다른 연구들은 데이터 중심 관점에서 문제에 접근한다. 특히, 확률적 생성 모델은 에셋 디자인에서 학습 절차와 데이터셋 디자인으로 패러다임을 전환했다.
StyleGAN은 이러한 모델 중 하나이며 많은 바람직한 속성을 나타낸다. StyleGAN은 높은 이미지 fidelity, 세밀한 semantic 제어, 그리고 최근에는 사실적인 애니메이션을 가능하게 하는 alias-free 생성을 달성하였다. 또한 신중하게 선별된 데이터셋, 특히 사람 얼굴에서 인상적인 포토리얼리즘에 도달한다. 그러나 ImageNet과 같은 구조화되지 않은 대규모 데이터셋에서 학습할 때 StyleGAN은 아직 만족스러운 결과를 얻지 못한다. 일반적으로 데이터 기반 방법을 괴롭히는 또 다른 문제는 더 큰 모델이 필요하기 때문에 더 높은 해상도로 확장할 때 엄청나게 비용이 많이 든다는 것이다.
처음에 StyleGAN은 변동 요인을 명시적으로 분리하여 더 나은 제어 및 interpolation 품질을 허용하도록 제안되었다. 그러나 ImageNet과 같은 복잡하고 다양한 데이터셋을 학습시킬 때 비용이 많이 드는 표준 generator 네트워크보다 더 제한적이다. StyleGAN과 StyleGAN2를 ImageNet으로 확장하려는 이전 시도들은 수준 이하의 결과로 이어져 매우 다양한 데이터셋에 대해 근본적으로 제한될 수 있다고 믿게 하였다.
BigGAN은 ImageNet에서 이미지 합성을 위한 state-of-the-art GAN 모델이다. BigGAN 성공의 주요 요인은 더 큰 batch 및 모델 크기이다. 그러나 BigGAN은 학습마다 성능이 크게 다르고 GAN 기반 이미지 편집에 필수적인 중간 latent space를 사용하지 않기 때문에 StyleGAN과 유사한 위치에 도달하지 못했다. 최근 BigGAN은 성능면에서 diffusion model로 대체되었다. Diffusion model은 GAN보다 더 다양한 이미지 합성을 달성하지만 inference가 상당히 느리고 GAN 기반 편집에 대한 이전 연구들을 직접 적용할 수 없다. 따라서 ImageNet에서 StyleGAN을 성공적으로 학습시키면 기존 방법에 비해 몇 가지 이점이 있다.
이전에 실패한 StyleGAN 확장 시도는 아키텍처 제약 조건이 스타일 기반 generator를 근본적으로 제한하는지 또는 누락된 부분이 올바른 학습 전략인지에 대한 질문을 제기한다. 최근 연구에서는 생성된 샘플과 실제 샘플을 사전 학습된 고정된 feature space에 투영하는 Projected GAN을 도입했다. GAN 설정을 이런 식으로 바꾸면 학습 안정성, 학습 시간, 데이터 효율성이 크게 향상된다.
Projected GAN 학습의 이점을 활용하면 StyleGAN을 ImageNet으로 확장할 수 있다. 그러나 Projected GAN의 장점은 unimodal 데이터셋에서 StyleGAN으로 부분적으로만 확장된다. 저자들은 이 문제를 연구하고 이를 해결하기 위한 아키텍처 변경을 제안한다. 그런 다음 최신 StyleGAN3에 맞는 progressive growing 전략을 설계한다. Projected GAN과 함께 이러한 변경 사항을 통해 ImageNet에서 StyleGAN을 학습시키려는 이전 시도들을 능가하였다고 한다. 저자들은 결과를 더욱 개선하기 위해 Projected GAN에 사용되는 사전 학습된 feature network를 분석하고 CNN과 ViT를 함께 사용하면 성능이 크게 향상된다는 사실을 발견했다. 마지막으로, 추가적인 클래스 정보를 주입하기 위해 diffusion model에 원래 도입된 기술인 classifier guidance를 활용한다.
Scaling StyleGAN to ImageNet
StyleGAN은 ImageNet에서 잘 작동하는 기존 접근 방식에 비해 몇 가지 장점이 있다. 그러나 naive한 학습 전략은 state-of-the-art 성능을 달성하지 못한다. 저자들은 실험을 통해 최신 StyleGAN3조차도 제대로 확장되지 않는다는 것을 확인했다. 특히 고해상도에서는 학습이 불안정해진다. 따라서 본 논문의 목표는 ImageNet에서 StyleGAN3 generator를 성공적으로 학습시키는 것이다. 본 논문의 모델을 StyleGAN-XL이라 부른다 (아래 그림 참고).
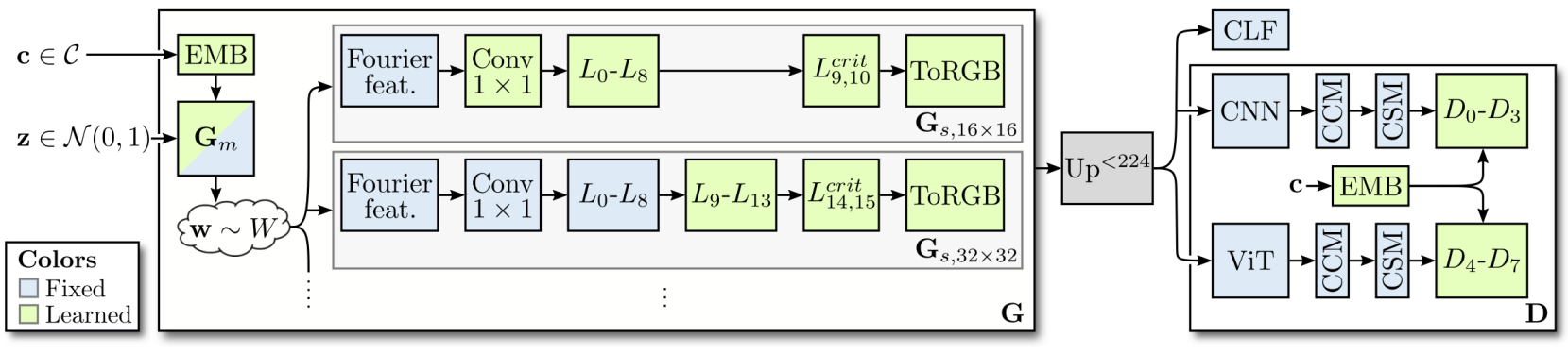
1. Adapting Regularization and Architectures
다양한 클래스 조건부 데이터셋에 대한 학습은 표준 StyleGAN 구성에 몇 가지 조정을 도입해야 한다. StyleGAN3의 translational-equivariant인 StyleGAN3-T layer를 사용하여 generator 아키텍처를 구성한다. 초기 실험에서 저자들은 rotational-equivariant인 StyleGAN3-R이 더 복잡한 데이터셋에서 지나치게 대칭적인 이미지를 생성하여 만화경과 같은 패턴을 생성한다는 사실을 발견했다.
Regularization
GAN 학습에서는 generator와 discriminator 모두에 대해 정규화를 사용하는 것이 일반적이다. 정규화는 FFHQ나 LSUN과 같은 unimodal 데이터셋에서 결과를 개선하는 반면 multi-modal 데이터셋에서는 해로울 수 있다. 따라서 가능하면 정규화를 피하는 것을 목표로 한다. 최신 StyleGAN3에서는 style mixing이 불필요하다는 것을 알게 되었다. 따라서 StyleGAN-XL도 style mixing을 비활성화한다.
Path length regularization는 복잡한 데이터셋에서 좋지 않은 결과를 초래할 수 있으며 기본적으로 StyleGAN3에서는 비활성화되어 있다. 그러나 path length regularization은 고품질 inversion을 가능하게 하므로 매력적이다. 또한 저자들은 실제로 path length regularization를 사용할 때 불안정한 동작과 발산을 관찰하였다. 저자들은 모델이 충분히 학습된 후에, 즉 20만 개의 이미지 이후에만 정규화를 적용함으로써 이 문제를 피하였다.
Discriminator의 경우 Gradient Penalty 없이 Spectral Normalization을 사용한다. 또한 처음 20만 개의 이미지에 대해 $\sigma = 2$픽셀인 가우시안 필터로 모든 이미지를 흐리게 처리한다. StyleGAN3-R에 discriminator blurring이 도입되었으며, discriminator가 초기에 높은 주파수에 집중하는 것을 방지하여 저자들이 조사한 모든 설정에서 유익한 것으로 나타났다.
Low-Dimensional Latent Space
Projected GAN은 StyleGAN보다 FastGAN에서 더 잘 작동한다. 이러한 generator의 한 가지 주요 차이점은 latent space이다. StyleGAN의 latent space는 비교적 높은 차원이다(FastGAN: $\mathbb{R}^{100}$, BigGAN: $\mathbb{R}^{128}$, StyleGAN: $\mathbb{R}^{512}$). 최근 연구 결과에 따르면 자연 이미지 데이터셋의 고유 차원은 상대적으로 낮고 ImageNet의 차원 추정치는 약 40이다. 따라서 크기 512의 latent code는 매우 중복되어 학습 초기에 매핑 네트워크를 더 어렵게 만든다. 결과적으로 generator는 적응 속도가 느리고 Projected GAN의 속도 향상 혜택을 받을 수 없다. 따라서 StyleGAN의 latent code $z$의 차원을 64로 줄이고 Projected GAN과 결합하면 안정적인 학습을 한다. 매핑 네트워크 $G_m$의 모델 용량을 제한하지 않기 위해 스타일 코드 $w \in \mathbb{R}^{512}$의 원래 차원은 유지한다.
Pretrained Class Embeddings
클래스 정보에 따라 모델을 조정하는 것은 샘플 클래스를 제어하고 전반적인 성능을 향상시키는 데 필수적이다. StyleGAN의 클래스 조건부 버전은 one-hot encoding label이 512차원 벡터에 포함되고 $z$와 연결되는 CIFAR10에서 처음 제안되었다. Discriminator의 경우 클래스 정보가 마지막 discriminator layer에 project된다. 이렇게 하면 클래스별로 유사한 고품질의 샘플들이 생성된다. 저자들은 Projected GAN으로 학습할 때 클래스 임베딩이 무너진다고 가정한다. 따라서 이러한 붕괴를 방지하기 위해 사전 학습을 통해 임베딩 최적화를 쉽게 하는 것을 목표로 한다.
Efficientnet-lite0의 가장 낮은 해상도의 feature를 추출하고 공간적으로 pooling하고 ImageNet 클래스당 평균을 계산한다. 네트워크는 임베딩 차원을 작게 유지하기 위해 채널 수가 적다. 임베딩은 불균형을 피하기 위해 $z$의 크기와 일치하도록 linear projection을 통과한다. $G_m$과 $D_i$ 모두 임베딩으로 컨디셔닝된다. GAN 학습 중에 임베딩과 linear projection이 최적화되어 전문화가 가능하다. 이 구성을 사용하면 모델이 클래스당 다양한 샘플을 생성하고 recall이 증가한다.
2. Reintroducing Progressive Growing
빠르고 안정적인 학습을 위해 GAN의 출력 해상도를 점진적으로 늘리는 방식이 도입되었다. 원래 공식은 학습 중에 $G$와 $D$ 모두에 layer를 추가하고 기여도가 점차 사라진다. 그러나 이후 연구에서는 텍스처 고착 아티팩트에 기여할 수 있으므로 폐기되었다. 최근 연구에 따르면 이러한 아티팩트의 주요 원인은 앨리어싱이므로 이를 방지하기 위해 StyleGAN의 각 layer를 재설계한다. 이것은 가능한 한 앨리어싱을 억제하는 것을 목표로 신중하게 만들어진 전략으로 progressive growing을 다시 적용할 수 있도록 동기를 부여하였다. $16^2$픽셀만큼 작은 매우 낮은 해상도에서 먼저 학습하면 고해상도 ImageNet에서 어려운 학습을 더 작은 하위 작업으로 나눌 수 있다. 이 아이디어는 diffusion model에 대한 최신 연구와 일치한다. Diffusion model들은 최종 이미지를 생성하기 위해 독립적인 저해상도 모델과 upsampling 모델을 쌓는 2단계 모델을 사용하여 ImageNet에서 FID의 상당한 개선을 보였다.
일반적으로 GAN은 엄격한 샘플링 속도 진행을 따른다. 즉, 각 해상도에서 고정된 필터 파라미터를 사용하여 upsampling 연산이 뒤따르는 고정된 양의 layer가 있다. StyleGAN3는 이러한 진행을 따르지 않는다. 대신 layer 수는 출력 해상도와 관계없이 14로 설정되며 up/downsampling 연산의 필터 파라미터는 주어진 구성에서 안티앨리어싱을 위해 신중하게 설계된다. 마지막 두 layer는 고주파 디테일을 생성하기 위해 중요하게 샘플링된다. Layer를 추가할 때 중간 layer로 사용되면 앨리어싱이 발생하므로 이전에 중요하게 샘플링된 layer를 버리는 것이 중요하다. 또한 유연한 layer 사양을 준수하기 위해 추가된 layer의 필터 파라미터를 조정한다. 대조적으로 discriminator에는 layer를 추가하지 않는다. 대신 사전 학습된 feature network $F$를 완전히 활용하기 위해 더 작은 이미지를 학습할 때 데이터와 합성 이미지를 모두 $F$의 학습 해상도($224^2$픽셀)로 upsampling한다.
11개의 layer를 사용하여 $16^2$의 해상도에서 progressive growing을 시작한다. 해상도가 높아질 때마다 2개의 layer를 버리고 7개의 새 layer를 추가한다. 경험적으로 layer 수가 적을수록 성능이 저하된다. 최종 단계($1024^2$)에서는 마지막 2개를 버리지 않기 때문에 5개 layer만 추가한다. $1024^2$의 최대 해상도에서는 39개의 layer를 가진다. 고정된 growing schedule 대신 FID 감소가 멈출 때까지 각 단계를 학습한다. 더 높은 해상도에서는 더 작은 batch size로도 충분하다 ($64^2$ ~ $256^2$: 256, $512^2$ ~ $1024^2$: 128). 새 layer가 추가되면 저해상도 layer가 고정되어 mode collapse를 방지한다.
3. Exploiting Multiple Feature Networks
Projected GAN의 ablation study에서는 대부분의 사전 학습된 feature network $F$가 학습 데이터, 사전 학습 목적 함수, 네트워크 아키텍처와 관계없이 Projected GAN 학습에 사용될 때 FID 측면에서 유사하게 수행된다는 것을 발견했다. 그러나 여러 $F$를 결합하는 것이 유리한지는 ablation study에서 다루지 않았다.
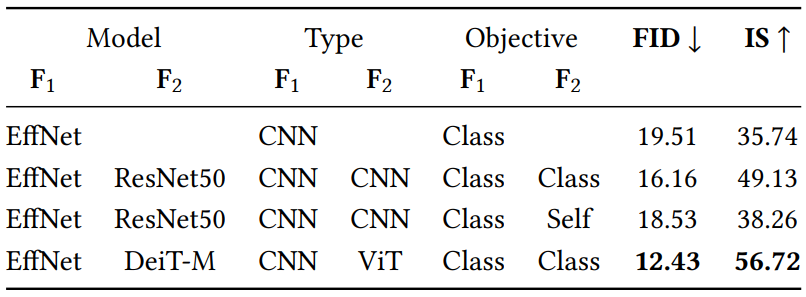
표준 구성인 EfficientNet-lite0에서 시작하여 사전 학습 목적 함수 (classification 또는 self-supervision), 아키텍처(CNN 또는 ViT(Vision Transformer))의 영향을 확인하기 위해 두 번째 $F$를 추가한다. 위 표의 결과는 CNN을 추가하면 FID가 약간 낮아지는 것을 보여준다. 사전 학습 목적 함수가 다른 네트워크를 결합해도 두 개의 classifier 네트워크를 사용하는 것보다 이점이 없다. 그러나 EfficientNet을 ViT와 결합하면 성능이 크게 향상된다. 이 결과는 supervised 표현과 self-supervised 표현이 유사하지만 ViT와 CNN이 서로 다른 표현을 학습한다는 최근 연구의 결과와 동일하다. 두 아키텍처를 결합하면 Projected GAN에 보완적인 효과가 있는 것으로 보인다. 더 많은 네트워크를 추가해도 크게 개선되지 않는다.
4. Classifier Guidance for GANs
Diffusion Models Beat GANs on Image Synthesis 논문은 클래스 정보를 diffusion model에 주입하기 위한 classifier guidance를 도입했다. Classifier guidance는 사전 학습된 classifier의 기울기 \(\nabla_{x_t} \log p_\phi (c \vert x_t, t)\)를 추가하여 timestep $t$에서 각 diffusion step을 수정한다. 클래스 조건부 모델에 guidance를 적용하고 상수 $\lambda > 1$로 clasifier 기울기를 조정하면 최상의 결과를 얻을 수 있다. 본 논문의 모델이 이미 임베딩을 통해 클래스 정보를 수신하더라도 classifier guidance에서 이익을 얻을 수 있음을 나타낸다.
먼저 사전 학습된 분류자 CLF를 통해 생성된 이미지 $x$를 전달하여 클래스 레이블 $c_i$를 예측한다. 그런 다음 cross-entropy loss
\[\begin{equation} \mathcal{L}_{CE} = -\sum_{i=0}^C c_i \log \textrm{CLF}(x_i) \end{equation}\]를 generator loss에 대한 추가적인 항으로 추가하고 이 항을 상수 $\lambda$로 조정한다. Classifier의 경우 학습에 많은 오버헤드를 추가하지 않으면서 강력한 classification 성능을 나타내는 DeiT-small을 사용한다. $\lambda = 8$이 경험적으로 잘 작동한다고 한다. Classifier guidance는 고해상도($> 32^2$)에서만 잘 작동한다. 그렇지 않으면 mode collapse로 이어진다.
5. Ablation Study
다음은 위에서 설명한 요소들에 대한 ImageNet $128^2$에서의 ablation study 결과이다.

Results
1. Image Synthesis
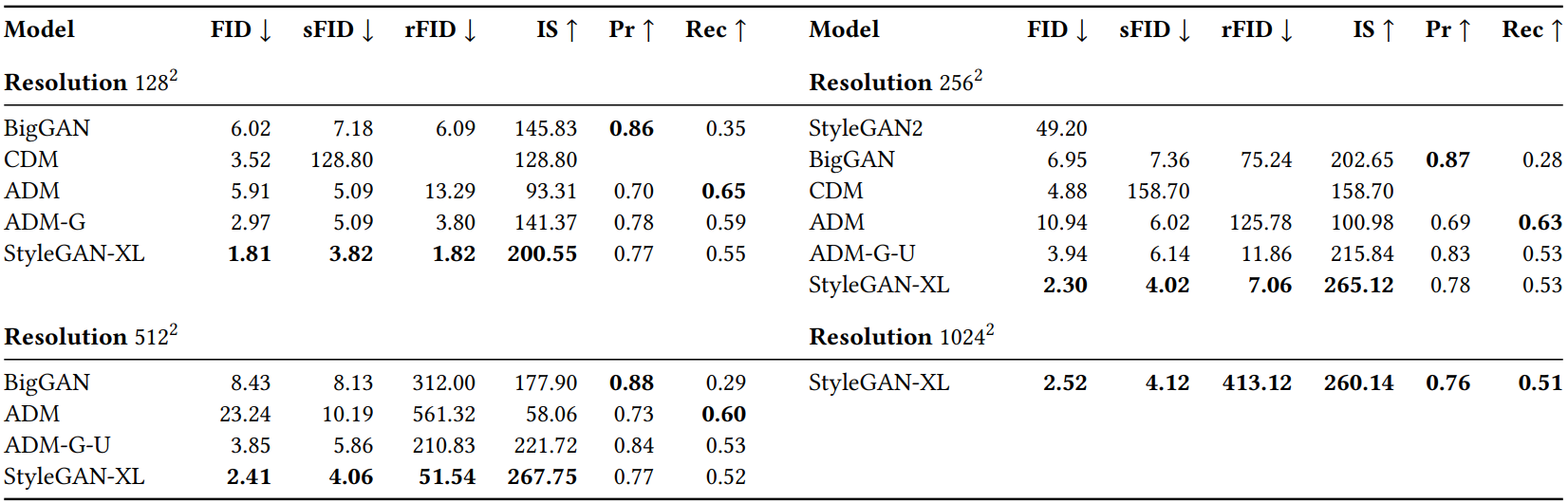
다음은 ImageNet에서의 이미지 합성 성능을 비교한 표이다.
다음은 같은 $w$에 대한 다양한 해상도에서의 샘플들이다.

2. Inversion and Manipulation
GAN-editing 방법은 먼저 주어진 이미지를 latent space으로 invert시킨다. 즉, $G_s$를 통과했을 때 이미지를 최대한 충실하게 재구성하는 스타일 코드 $w$를 찾는다. 그런 다음 $w$를 조작하여 semantic 편집을 할 수 있다.
Inversion
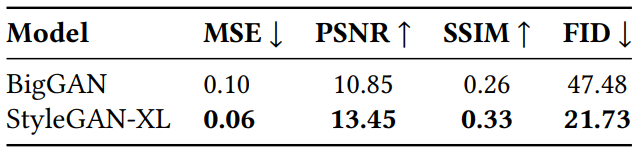
다음은 inversion 결과를 나타낸 표이다. 모델에서 얻은 inversion과 reconstruction 대상 사이에서 측정하였다.
다음은 interpolation의 예시이다.

Image Manipulation
다음은 image editing(왼쪽)과 style mixing(오른쪽)의 예시이다.

다음은 랜덤 샘플이 주어지면 StyleMC에서 찾은 latent space에서 semantic 방향을 따라 이미지를 조작한 예시이다. 위에서부터 “smile”, “no stripes”, “big eyes” 방향으로 latent space를 조작하였다.

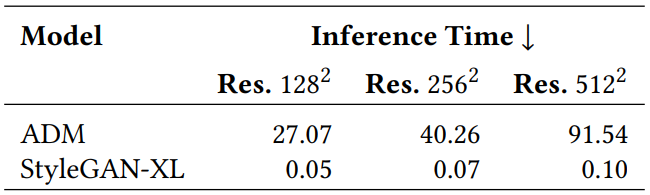
3. Inference Speed
다음은 ADM과 StyleGAN-XL의 inference 시간을 비교한 표이다.
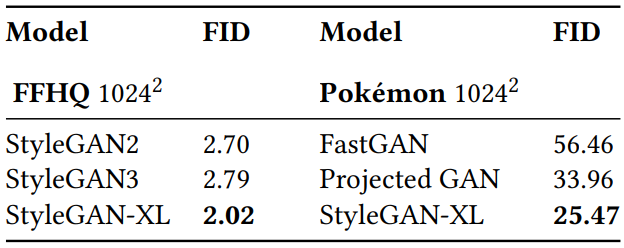
4. Results on Unimodal Datasets
다음은 unimodal 데이터셋인 FFHQ $1024^2$와 Pokémon $1024^2$에서의 성능을 비교한 표이다.
Limitations
- StyleGAN-XL은 StyleGAN3보다 3배 더 크므로 fine-tuning을 위한 시작점으로 사용할 때 더 높은 계산 오버헤드가 필요하다.
- StyleGAN3과 StyleGAN-XL은 편집하기 더 어렵다. (ex. $\mathcal{W}$를 통한 고품질 편집은 StyleGAN2를 사용하는 것이 훨씬 더 쉽다.)