[논문리뷰] StyleGAN-T: Unlocking the Power of GANs for Fast Large-Scale Text-to-Image Synthesis
arXiv 2023. [Paper] [Page] [Github]
Axel Sauer, Tero Karras, Samuli Laine, Andreas Geiger, Timo Aila
University of Tubingen, Tubingen AI Center | NVIDIA
23 Jan 2023
Introduction
Text-to-image 합성에서는 텍스트 프롬프트를 기반으로 새로운 이미지가 생성된다. 이 task의 state-of-the-art는 최근 두 가지 핵심 아이디어 덕분에 극적인 도약을 이루었다.
- 대규모 사전 학습된 언어 모델을 프롬프트용 인코더로 사용하면 일반적인 언어 이해를 기반으로 합성을 컨디셔닝할 수 있다.
- 수억 개의 이미지-캡션 쌍으로 구성된 대규모 학습 데이터를 사용하면 모델이 상상할 수 있는 거의 모든 것을 합성할 수 있다.
학습 데이터셋은 크기와 적용 범위가 계속해서 빠르게 증가하고 있다. 결과적으로 text-to-image model은 학습 데이터를 흡수할 수 있는 대용량으로 확장 가능해야 한다. 대규모 text-to-image 생성의 최근 성공은 이 속성들이 내장된 것으로 보이는 diffusion model (DM)과 autoregressive model (ARM)에 의해 주도되었으며, 고도의 multi-modal 데이터를 처리할 수 있는 능력을 가지고 있다.
흥미롭게도, 더 작고 덜 다양한 데이터셋에서 지배적인 생성 모델 계열인 GAN은 이 task에서 특별히 성공하지 못했다. 본 논문의 목표는 GAN이 경쟁력을 회복할 수 있음을 보여주는 것이다.
GAN이 제공하는 주요 이점은 inference 속도와 latent space 조작을 통한 합성 결과의 제어다. 특히 StyleGAN은 철저하게 연구된 latent space을 가지고 있어 생성된 이미지를 원칙적으로 제어할 수 있다. DM의 속도를 높이는 데 눈에 띄는 진전이 있었지만 단일 forward pass만 필요한 GAN보다 여전히 훨씬 뒤떨어져 있다.
StyleGAN-XL에서 discriminator 아키텍처가 재설계되기 전까지 GAN이 ImageNet 합성에서 diffusion model보다 유사하게 뒤처진다는 관찰에서 GAN이 격차를 좁힐 수 있다는 동기를 부여한다. StyleGAN-XL에서 시작하여 대용량, 매우 다양한 데이터셋, 강력한 텍스트 일치, 제어 가능한 변형과 텍스트 일치 사이의 trade-off 등 대규모 text-to-image task의 특정한 요구 사항을 고려하여 generator 및 discriminator 아키텍처를 다시 살펴본다.
저자들은 최종 모델을 대규모로 학습하는 데 사용할 수 있는 GPU의 제약(NVIDIA A100 64개, 4주)으로 인해 state-of-the-art 고해상도 결과에 충분하지 않을 가능성이 높기 때문에 우선 순위를 설정해야 했다고 한다. 고해상도로 확장하는 GAN의 능력은 잘 알려져 있지만, 대규모 text-to-image task로의 성공적인 확장은 아직 연구되지 않았다. 따라서 저자들은는 super-resolution 단계에 한정된 예산만을 투입하여 저해상도에서 이 task를 해결하는 데 주로 중점을 둔다.
StyleGAN-XL
본 논문의 아키텍처 설계는 StyleGAN-XL을 기반으로 하며 원래 StyleGAN과 유사하게 먼저 매핑 네트워크에 의해 정규 분포된 입력 latent code $z$를 처리하여 중간 latent coder $w$를 생성한다. 이 중간 latent는 StyleGAN2에 도입된 가중치 demodulation 기술을 사용하여 합성 네트워크에서 convolution layer를 변조하는 데 사용됩다. StyleGAN-XL의 합성 네트워크는 StyleGAN3의 alias-free primitive operation을 사용하여 translational equivariance을 달성한다. 즉, 합성 네트워크가 생성된 feature에 대해 선호하는 위치가 없도록 한다.
StyleGAN-XL은 여러 개의 discriminator head가 2개의 고정된 사전 학습된 feature 추출 네트워크 (DeiT-M과 EfficientNet)의 feature projection에서 작동하는 고유한 discriminator 디자인을 가지고 있다. Feature 추출 네트워크들의 출력은 randomized cross-channel 및 cross-scale mixing module을 통해 공급된다. 그 결과 각각 4개의 해상도 레벨을 가진 2개의 feature 피라미드가 생성되며 8개의 discriminator head에서 처리된다. 사전 학습된 추가 clasifier 네트워크는 학습 중에 guidance를 제공하는 데 사용된다.
StyleGAN-XL의 합성 네트워크는 점진적으로 학습되어 현재 해상도가 개선되지 않으면 새로운 합성 layer를 도입하여 시간이 지남에 따라 출력 해상도를 높인다. 이전의 점진적 성장 접근 방식과 달리 discriminator 구조는 학습 중에 변경되지 않는다. 대신 초기 저해상도 이미지는 discriminator에 맞게 필요에 따라 upsampling된다. 또한 이미 학습된 합성 layer는 추가 layer가 추가될 때 고정된다.
클래스 조건부 합성의 경우 StyleGAN-XL은 one-hot 클래스 레이블을 $z$에 임베딩하고 projection discriminator를 사용한다.
StyleGAN-T
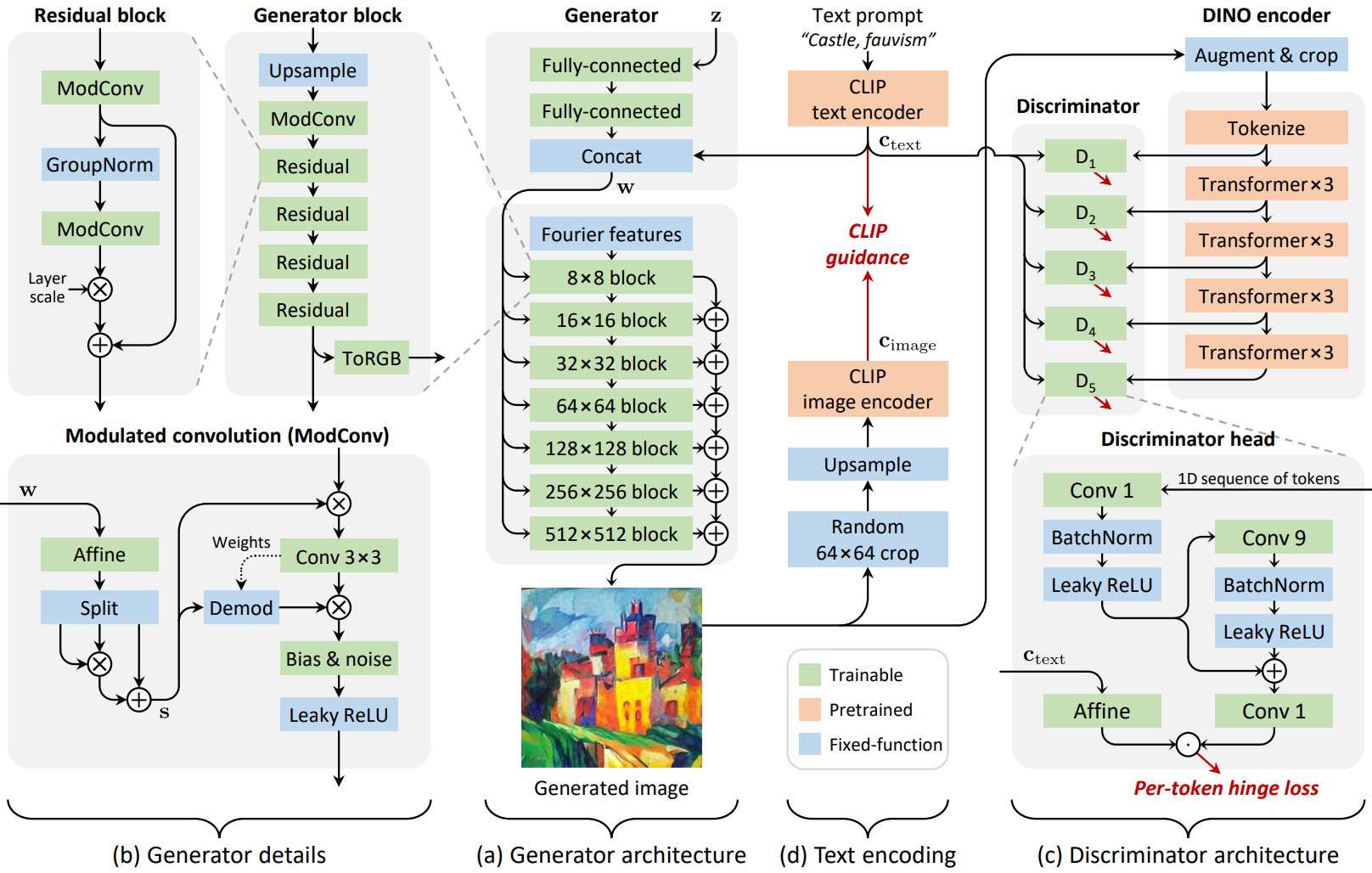
1. Redesigning the Generator
StyleGAN-XL은 StyleGAN3 layer를 사용하여 translational equivariance을 달성한다. Equivariance는 다양한 애플리케이션에 바람직할 수 있지만 성공적인 DM/ARM 기반 방법 중 어느 것도 equivariance가 아니기 때문에 text-to-image 합성에는 필요하지 않을 것이다. 또한 equivariance 제약 조건은 계산 비용을 추가하고 대규모 이미지 데이터셋이 일반적으로 위반하는 학습 데이터에 특정 제한을 부과한다.
이러한 이유로 낮은 레벨의 디테일의 확률적 변화를 촉진하는 출력 skip connection과 공간적 noise 입력을 포함하여 합성 layer에 대해 equivariance를 버리고 StyleGAN2 backbone으로 전환한다. 이러한 변경 후 generator의 상위 레벨 아키텍처는 위 그림의 (a)에 나와 있다. Generator 아키텍처의 디테일에 대한 두 가지 변경 사항을 추가로 제안한다 (위 그림의 (b)).
Residual convolutions
모델 용량을 크게 늘리는 것을 목표로 하므로 generator는 너비와 깊이 모두에서 확장할 수 있어야 한다. 그러나 기본 구성에서 generator의 깊이가 크게 증가하면 학습에서 초기 mode collapse가 발생한다. 최신 CNN 아키텍처의 중요한 구성 요소는 입력을 정규화하고 출력을 확장하는 쉽게 최적화할 수 있는 residual block이다. 저자들은 convolution layer의 절반을 residual로 만들고 정규화를 위해 GroupNorm으로 래핑하고 기여도를 확장하기 위해 Layer Scale로 래핑한다. 초기 값이 $10^{-5}$로 낮은 layer scale은 convolution layer의 기여도를 점진적으로 감소시켜 초기 학습 iteration을 상당히 안정화시킨다. 이 설계를 통해 가벼운 구성에서 약 2.3배, 최종 모델에서 4.5배까지 총 layer 수를 상당히 늘릴 수 있다. 공정한 비교를 위해 StyleGAN-XL baseline의 파라미터 수를 일치시킨다.
Stronger conditioning
변형 요소가 프롬프트마다 크게 다를 수 있기 때문에 text-to-image setting은 까다롭다. “얼굴 클로즈업”이라는 프롬프트는 다양한 눈 색깔, 피부색, 비율로 얼굴을 생성해야 하는 반면, “아름다운 풍경”이라는 프롬프트는 다양한 지역, 계절, 낮의 풍경을 생성해야 한다. 스타일 기반 아키텍처에서 이러한 모든 변형은 layer별 스타일에 의해 구현되어야 한다. 따라서 텍스트 컨디셔닝은 간단한 설정을 위해 필요한 것보다 훨씬 더 강력하게 스타일에 영향을 미칠 필요가 있다.
초기 테스트에서 저자들은 baseline 아키텍처에서 입력 latent $z$가 텍스트 임베딩 $c_\textrm{text}$를 지배하는 분명한 경향을 관찰하였으며, 이는 텍스트 일치를 좋지 않게 만든다. 이를 해결하기 위해 $c_\textrm{text}$의 역할을 증폭시키는 것을 목표로 하는 두 가지 변경 사항을 도입한다. 먼저 Disentangling Random and Cyclic Effects in Time-Lapse Sequences 논문의 관찰에 따라 텍스트 임베딩이 매핑 네트워크를 우회하도록 한다. 비슷한 디자인이 LAFITE에서도 사용되었으며 CLIP 텍스트 인코더가 텍스트 컨디셔닝을 위한 적절한 중간 latent space를 정의한다고 가정한다. 따라서 $c_\textrm{text}$를 $w$에 직접 연결하고 affine transform의 집합을 사용하여 layer별 스타일 $\tilde{s}$를 생성한다.
둘째, convolution을 그대로 변조하기 위해 결과 $\tilde{s}$를 사용하는 대신 동일한 차원 $\tilde{s}_{1,2,3}$의 세 벡터로 분할하고 최종 스타일 벡터를 다음과 같이 계산한다.
\[\begin{equation} s = \tilde{s}_1 \odot \tilde{s}_2 + \tilde{s}_3 \end{equation}\]이 연산의 핵심은 affine transform을 2차 다항식 네트워크로 효과적으로 전환하여 표현력을 높이는 element-wise 곱셈이다. DF-GAN의 스택된 MLP 기반 컨디셔닝 layer는 암시적으로 유사한 2차 항을 포함한다.
2. Redesigning the Discriminator
본 논문은 discriminator를 처음부터 다시 디자인하지만 고정되고 사전 학습된 feature network에 의존하고 여러 discriminator head를 사용한다는 StyleGAN-XL의 핵심 아이디어를 유지한다.
Feature network
Feature network의 경우 self-supervised DINO objective로 학습된 ViT-S를 선택한다. 네트워크는 가볍고 평가가 빠르며 높은 공간 해상도에서 semantic 정보를 인코딩한다. Self-supervised feature network를 사용하는 추가 이점은 잠재적으로 FID를 손상시킬 우려를 피할 수 있다는 것이다.
Architecture
Discriminator 아키텍처는 위 그림의 (c)에 나와 있다. ViT는 등방성이다. 즉, 표현 크기(토큰$\times$채널)와 receptive field가 네트워크 전체에서 동일하다. 이 등방성 덕분에 모든 discriminator head에 대해 동일한 아키텍처를 사용할 수 있으며 Transformer layer 사이에 균등한 간격을 둔다. 여러 개의 head가 유익한 것으로 알려져 있으며, 저자들은 디자인에 5개의 head를 사용하였다.
Discriminator head는 위 그림의 (c) 하단에 자세히 설명된 것처럼 최소한이다. Residual convolution의 kernel 너비는 토큰 시퀀스에서 head의 receptive field를 제어한다. 저자들은 공간적으로 재구성된 토큰에 적용된 2D convolution과 마찬가지로 토큰 시퀀스에 적용된 1D convolution이 잘 수행되는 것을 발견했으며, 이는 discrimination task가 토큰에 남아 있는 2D 구조로부터 이점을 얻지 못한다는 것을 나타낸다. 모든 head의 각 토큰에 대해 hinge loss를 독립적으로 평가한다.
ProjectedGAN은 synchronous BatchNorm을 사용하여 discriminator에게 batch 통계를 제공한다. BatchNorm은 노드와 GPU 간의 통신이 필요하므로 다중 노드 설정으로 확장할 때 문제가 된다. 작은 가상 batch에 대한 batch 통계를 계산하는 변형 버전을 사용한다. Batch 통계는 장치 간에 동기화되지 않지만 로컬한 mini-batch별로 계산된다. 또한 실행 통계를 사용하지 않으므로 GPU 간의 추가 통신 오버헤드가 발생하지 않는다.
Augmentation
Discriminator의 feature network 전에 기본 파라미터를 사용하여 미분 가능한 data augmentation을 적용한다. 224$\times$224픽셀보다 큰 해상도에서 학습할 때 random crop을 사용한다.
3. Variation vs. Text Alignment Tradeoffs
Guidance는 현재 text-to-image diffusion model의 필수 구성 요소이다. Guidance는 원칙적인 방식으로 이미지 품질의 개선을 위해 variation을 교환하며, 텍스트 조건에 강력하게 일치하는 이미지를 선호한다. 실제로 guidance는 결과를 크게 향상시킨다. 따라서 저자들은 GAN의 맥락에서 guidance를 근사화하려고 한다.
Guiding the generator
StyleGAN-XL은 사전 학습된 ImageNet classes를 사용하여 학습 중에 추가 기울기를 제공하여 분류하기 쉬운 이미지로 generator를 guide한다. 이 방법은 결과를 크게 향상시킨다. Text-to-image의 맥락에서 “classification”에는 이미지에 캡션을 추가하는 것이 포함된다. 따라서 이 접근 방식의 자연스러운 확장은 clasifier 대신 CLIP 이미지 인코더를 사용하는 것이다. VQGAN-CLIP을 따라 각 generator 업데이트에서 캡션 $c_\textrm{image}$를 얻기 위해 생성된 이미지를 CLIP 이미지 인코더에 통과시키고 $c_\textrm{text}$를 포함하는 정규화된 텍스트에 대한 제곱 구면 거리를 최소화한다.
\[\begin{equation} \mathcal{L}_\textrm{CLIP} = \textrm{arccos}^2 (c_\textrm{image} \cdot c_\textrm{text}) \end{equation}\]이 추가적인 loss 항은 생성된 분포를 입력 텍스트 인코딩 $c_\textrm{text}$와 유사하게 캡션이 있는 이미지로 guide한다. 따라서 그 효과는 diffusion model의 guidance와 유사하다. 위 그림의 (d)는 본 논문의 접근 방식을 보여준다.
CLIP은 합성 중에 사전 학습된 generator를 guide하기 위해 이전 연구에서 사용되었다. 대조적으로, 저자들은 CLIP을 학습하는 동안 loss function의 일부로 사용한다. 학습 중 CLIP guidance가 지나치게 강하면 분포 다양성이 제한되고 궁극적으로 이미지 아티팩트가 도입되기 시작하므로 FID가 손상된다는 점에 유의해야 한다. 따라서 전체 loss에서 \(\mathcal{L}_\textrm{CLIP}\)의 가중치는 이미지 품질, 텍스트 컨디셔닝, 분포 다양성 사이의 균형을 맞출 필요가 있다. 본 논문은 가중치를 0.2로 설정했다. 또한 저자들은 guidance가 최대 64$\times$64 픽셀 해상도까지만 도움이 된다는 사실을 관찰했다. 더 높은 해상도에서는 임의의 64$\times$64 픽셀 crop에 \(\mathcal{L}_\textrm{CLIP}\)을 적용한다.
Guiding the text encoder
흥미롭게도 사전 학습된 generator를 사용하는 이전 방법들은 낮은 레벨에서의 이미지 아티팩트 발생을 보고하지 않았다. 저자들은 고정된 generator가 아티팩트들을 억제하는 prior 역할을 한다고 가정하였다.
이를 바탕으로 텍스트 일치를 더욱 개선한다. 첫 번째 단계에서 generator는 학습 가능하고 텍스트 인코더는 정지된다. 그런 다음 generator가 정지되고 대신 텍스트 인코더가 학습 가능해지는 두 번째 단계를 도입한다. Generator 컨디셔닝에 관해서는 텍스트 인코더만 학습시킨다.
Discriminator와 guidance 항은 여전히 원래 고정 인코더에서 $c_\textrm{text}$를 받는다. 이 두 번째 단계에서는 50의 매우 높은 CLIP guidance 가중치를 허용하여 아티팩트를 막고 FID를 손상시키지 않고 텍스트 일치를 크게 개선한다. 첫 번째 단계에 비해 두 번째 단계는 훨씬 짧을 수 있다. 수렴 이후 첫 번째 단계를 계속한다.
Explicit truncation
일반적으로 variation은 truncation trick을 사용하여 GAN에서 더 높은 fidelity로 교환된다. 여기서 샘플링된 latent $w$는 주어진 컨디셔닝 입력과 관련하여 평균으로 보간된다. 이런 식으로 truncation은 모델이 더 잘 수행되는 고밀도 영역으로 $w$를 이동시킨다. 구현에서 $w = [f(z), c_\textrm{text}]$이고, 여기서 $f(\cdot)$는 매핑 네트워크를 나타내므로 프롬프트당 평균은 \(\tilde{w} = \mathbb{E}_z [w] = [\tilde{f}, c_\textrm{text}]\)로 지정된다. 여기서 $\tilde{f} = \mathbb{E}_z [f(z)]$이다. 따라서 학습 중에 $\tilde{f}$를 추적하고 inference 시간에 스케일링 파라미터 $\psi \in [0, 1]$에 따라 $\tilde{w}$와 $w$ 사이를 보간하여 truncation을 구현한다.

위 그림은 truncation의 영향을 보여준다. 실제로 본 논문은 CLIP guidance와 truncation의 결합에 의존한다. Guidance는 모델의 전체 텍스트 일치를 개선하고 truncation은 특정 샘플의 품질과 일치를 더욱 향상시켜 일부 variation을 제거할 수 있다.
Experiments
1. Quantitative Comparison to State-of-the-Art
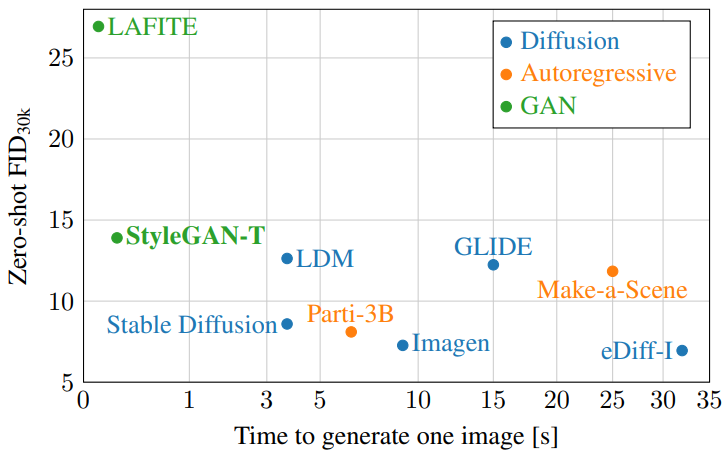
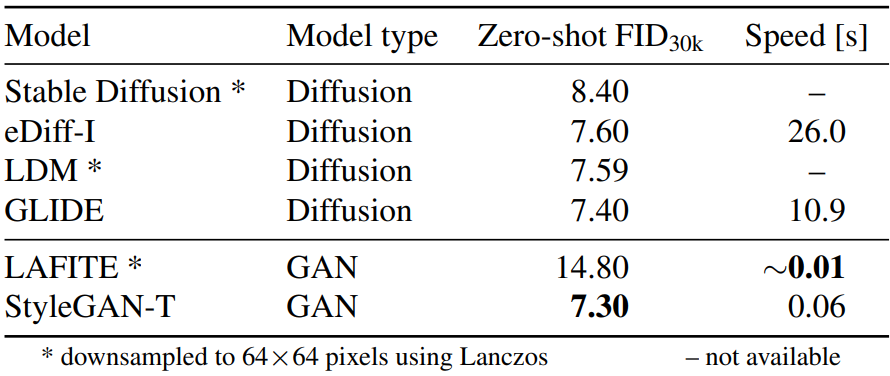
다음은 MS COCO 64$\times$64에서 FID를 비교한 표이다.
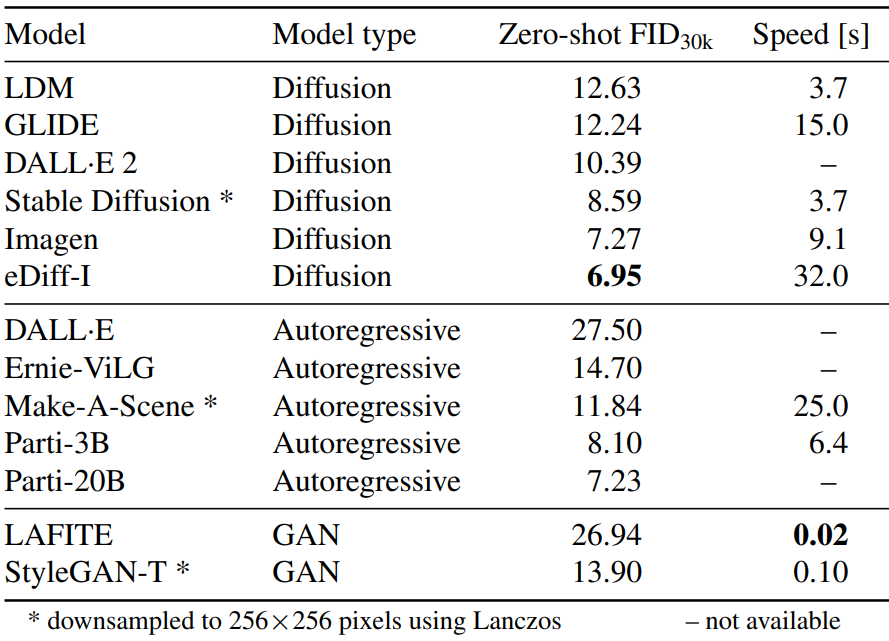
다음은 MS COCO 256$\times$256에서 FID를 비교한 표이다.
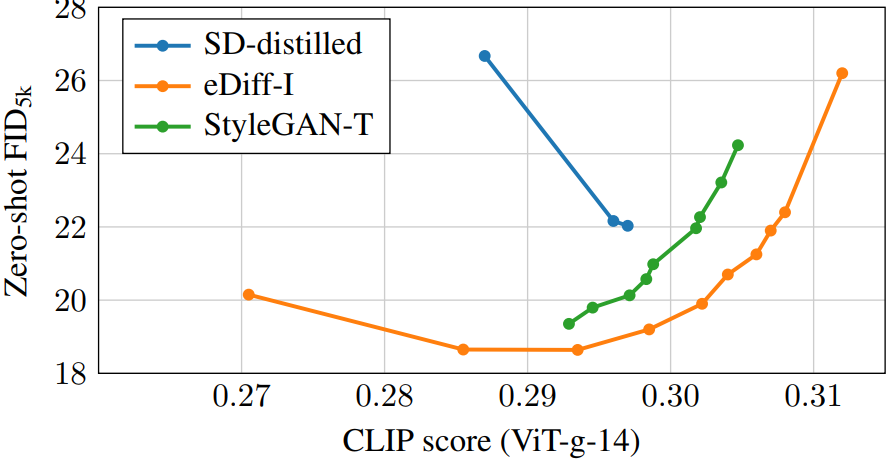
2. Evaluating Variation vs. Text Alignment
다음은 FID와 CLIP score를 비교한 그래프이다.
다음은 텍스트 인코더의 효과를 나타낸 FID-CLIP score 그래프이다.
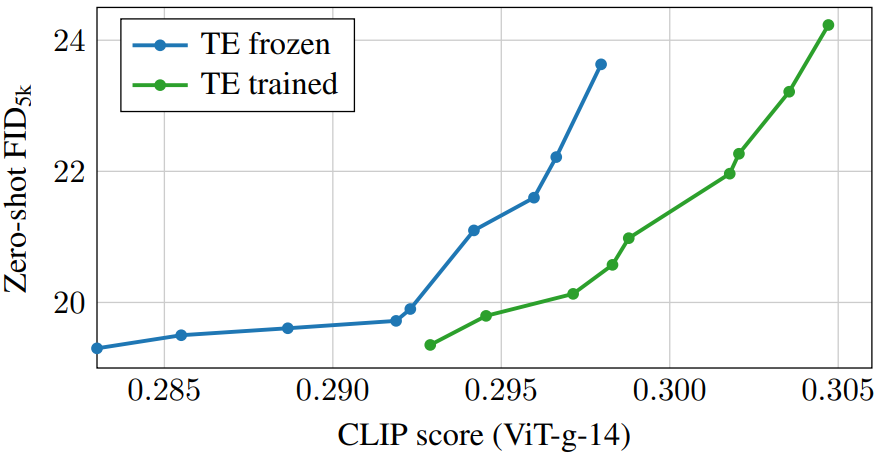
텍스트 인코더를 학습시키면 전체적인 텍스트 일치가 좋아지는 것을 볼 수 있다.
3. Qualitative Results
다음은 예시 이미지들과 이미지들의 interpolation을 보여주는 그림이다.

다음은 latent 조작의 예시이다.

다음은 고정된 random seed에 대하여 캡션 “astronaut, {X}”의 X를 변화시키면서 생성한 샘플들이다.

4. Architecture ablation
다음은 아키텍처에 대한 ablation을 나타낸 표이다.
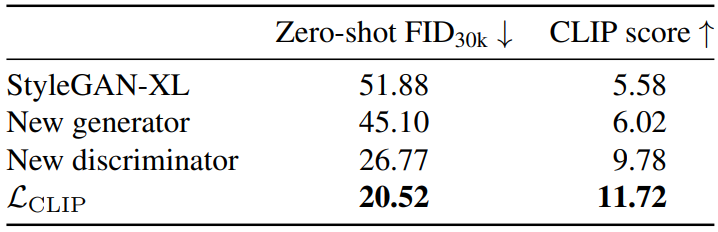
Generator의 재설계, discriminator의 재설계, CLIP guidance의 도입은 각각 FID와 CLIP score를 모두 개선하는 것을 볼 수 있다.
Limitations

기본 언어 모델로 CLIP을 사용하는 DALL·E 2와 유사하게 StyleGAN-T는 객체에 속성을 바인딩하고 이미지에서 일관된 텍스트를 생성하는 측면에서 때때로 어려움을 겪는다(위 그림 참고). 더 큰 언어 모델을 사용하면 런타임이 느려지는 대신 이 문제를 해결할 수 있다.
CLIP loss를 통한 guidance는 우수한 텍스트 일치에 필수적이지만 guidance 강도가 높으면 이미지 아티팩트가 발생한다. 가능한 해결책은 앨리어싱 또는 기타 이미지 품질 문제가 없는 고해상도 데이터에서 CLIP을 재학습시키는 것이다.