[논문리뷰] StyleCrafter: Enhancing Stylized Text-to-Video Generation with Style Adapter
SIGGRAPH Asia 2024. [Paper] [Page] [Github]
Gongye Liu, Menghan Xia, Yong Zhang, Haoxin Chen, Jinbo Xing, Xintao Wang, Yujiu Yang, Ying Shan
Tsinghua University | Tencent AI Lab | CUHK
1 Dec 2023

Introduction
강력한 diffusion model의 인기는 콘텐츠 생성 분야에서 놀라운 발전을 가져왔다. 예를 들어, text-to-image (T2I) 모델은 다양한 시각적 개념을 포괄하는 텍스트 프롬프트에서 다양하고 생생한 이미지를 생성할 수 있다. 이러한 큰 성공은 모델의 발전뿐만 아니라 인터넷을 통해 다양한 이미지 데이터를 이용할 수 있게 된 덕분이다. 이와 달리 text-to-video (T2V) 모델은 특히 스타일 면에서 데이터 카테고리가 부족하다. 이는 기존 동영상이 주로 사실적인 feature를 갖고 있기 때문이다. 잘 학습된 T2I 모델에서 가중치를 초기화하거나 이미지나 동영상 데이터셋을 사용한 공동 학습과 같은 전략이 이 문제를 완화하는 데 도움이 될 수 있지만 생성된 스타일화(stylize)된 동영상은 일반적으로 스타일 충실도가 저하된다. AnimateDiff는 LoRA를 튜닝한 T2I 모델을 사전 학습된 시간 블록과 결합하여 인상적인 스타일화된 동영상을 만들 수 있다. 그러나 각 스타일에는 작은 예제 세트에 대한 LoRA fine-tuning이 필요하므로 이는 비효율적이며 어떤 스타일도 지원할 수 없다.
이러한 문제를 해결하기 위해 본 논문은 스타일 제어 어댑터로 사전 학습된 T2V 모델을 향상시켜 레퍼런스 이미지를 제공함으로써 모든 스타일의 동영상 생성을 가능하게 하는 일반적인 방법인 StyleCrafter를 제안한다. 두 가지 장점이 있다.
- 스타일 이미지는 스타일 feature guidance를 제공하여 zero-shot 방식으로 T2V 모델의 스타일화 능력을 보완한다.
- 레퍼런스 이미지는 텍스트 프롬프트에 비해 원하는 스타일을 더 정확하게 묘사한다.
어쨌든 이 목표를 달성하는 것은 쉽지 않다. 한편으로, 스타일 제어 어댑터는 콘텐츠 분리 방식으로 레퍼런스 이미지에서 정확한 스타일 feature를 추출해야 한다. 다른 한편으로, 스타일화된 동영상의 부족으로 인해 T2V 모델의 적응 학습이 어려워졌다.
스타일화된 동영상 데이터셋의 희소성을 고려하여, 저자들은 먼저 이미지 데이터셋의 이미지에서 원하는 스타일 feature를 추출하도록 스타일 어댑터를 학습시킨 다음, 맞춤형 fine-tuning 패러다임을 통해 학습된 스타일화 능력을 동영상 생성에 전달할 것을 제안하였다. 콘텐츠 스타일 분리를 촉진하기 위해 텍스트 프롬프트에서 스타일 설명을 제거하고 디커플링 학습 전략을 사용하여 레퍼런스 이미지에서만 스타일 정보를 추출한다. 특히, 텍스트 기반 콘텐츠 feature와 이미지 기반 스타일 feature의 균형을 맞추기 위해 scale-adaptive fusion module을 설계하여 다양한 텍스트와 스타일 조합에 대한 일반화를 돕는다. StyleCrafter는 텍스트 내용과 일치하고 레퍼런스 이미지의 스타일과 유사한 고품질의 스타일화된 동영상을 효율적으로 생성한다.
Method
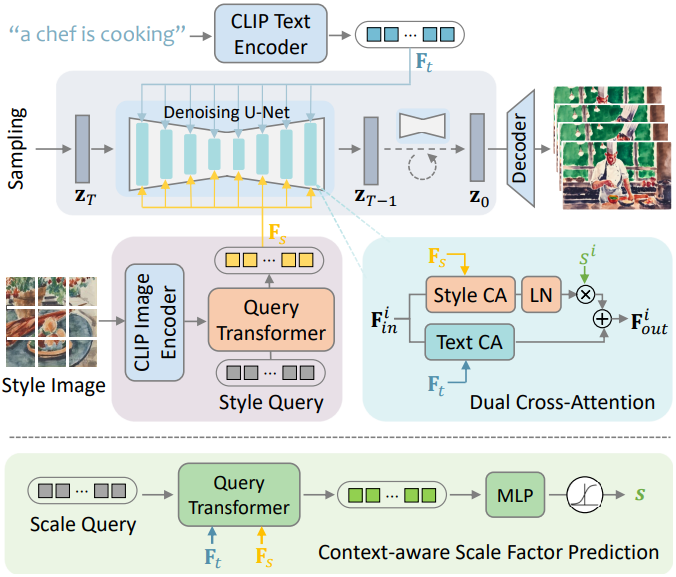
본 논문은 사전 학습된 T2V 모델에 스타일 어댑터를 장착하여 텍스트 프롬프트와 스타일 레퍼런스 이미지를 기반으로 스타일화된 동영상을 생성할 수 있는 방법을 제안한다. 개요 다이어그램은 위 그림에 설명되어 있다. 이 프레임워크에서 텍스트 설명은 동영상 콘텐츠를 제어하고 스타일 이미지는 시각적 스타일을 제어하여 동영상 생성 프로세스에 대한 명확한 제어를 보장한다. 스타일화된 동영상의 제한된 가용성을 고려하여 저자들은 2단계 학습 전략을 사용하였다. 처음에는 레퍼런스 기반 스타일 변조를 학습하기 위해 예술적 스타일이 풍부한 이미지 데이터셋을 활용한다. 이후 생성된 동영상의 시간적 품질을 향상시키기 위해 스타일 이미지와 사실적인 동영상이 혼합된 데이터셋에 대한 fine-tuning을 수행한다.
1. Reference-Based Style Modulation
스타일 어댑터는 입력 레퍼런스 이미지에서 스타일 feature를 추출하고 이를 denoising U-Net의 backbone feature에 주입하는 역할을 한다. T2V 모델은 일반적으로 이미지나 동영상 데이터셋으로 학습되므로 T2V 생성뿐만 아니라 T2I 생성도 지원한다. 스타일화된 동영상의 희소성을 극복하기 위해 스타일화된 이미지 데이터셋의 supervision 하에 스타일화된 이미지 생성을 위해 사전 학습된 T2V 모델을 기반으로 스타일 어댑터를 학습한다.
Content-Style Decoupled Data Augmentation
저자들은 WikiArt와 Laion-Aethetics-6.5+의 스타일 이미지를 사용하였다. 원본 이미지-캡션 쌍에서 캡션에 일반적으로 콘텐츠와 스타일 설명이 모두 포함되어 있으며 그 중 일부는 이미지 콘텐츠와 잘 일치하지 않는다. 콘텐츠 스타일 분리를 촉진하기 위해 BLIP-2를 사용하여 이미지 캡션을 재생성하고 정규식을 사용하여 특정 형태의 스타일 설명(ex. a painting of)을 제거한다. 또한, 이미지에는 스타일 정보와 콘텐츠 정보가 모두 포함되어 있으므로 콘텐츠 feature가 없는 추출된 스타일 feature를 보장하기 위한 decoupling supervision 전략을 구축하는 것이 필요하다.
저자들은 스타일 이미지의 모든 로컬한 영역이 동일한 스타일 표현을 공유하며 이는 텍스처와 색상 테마뿐만 아니라 구조와 semantic도 반영한다고 생각하였다. 이러한 통찰력을 바탕으로 각 스타일 이미지를 처리하여 다양한 전략을 통해 타겟 이미지와 스타일 이미지를 얻는다. 타겟 이미지의 경우 이미지의 짧은 쪽을 512로 조정한 다음 중앙 영역에서 타겟 콘텐츠를 자른다. 스타일 이미지의 경우 이미지의 짧은 쪽을 800으로 조정하고 로컬 패치를 무작위로 자른다. 이 접근 방식은 스타일 레퍼런스와 생성 타겟 간의 중복을 줄이는 동시에 글로벌 스타일 semantic을 완전하고 일관되게 유지한다.
Style Embedding Extraction
CLIP은 오픈 도메인 이미지에서 높은 수준의 semantic을 추출하는 놀라운 능력을 보여주었다. 이러한 이점을 활용하기 위해 사전 학습된 CLIP 이미지 인코더를 feature 추출기로 사용한다. 특히 원하는 스타일 임베딩이 T2V 모델에 대한 정확한 스타일 트리거 역할을 할 뿐만 아니라 보조 feature 레퍼런스도 제공해야 하므로 글로벌 semantic 토큰과 전체 로컬 토큰 256개(즉, Transformer의 마지막 레이어에서)를 모두 활용한다. 이미지 토큰은 스타일 정보와 콘텐츠 정보를 모두 포함하므로 학습 가능한 Query Transformer (Q-Former)를 추가로 사용하여 스타일 임베딩 $F_s$를 추출한다. Q-Former에 대한 입력으로 $N$개의 학습 가능한 스타일 쿼리 임베딩을 생성하며, self-attention 레이어를 통해 이미지 feature와 상호 작용한다. 이는 시각적 조건 추출을 위해 일반적으로 채택되는 아키텍처이다.
Adaptive Style-Content Fusion
추출된 스타일 임베딩으로 스타일과 텍스트 조건을 결합하는 두 가지 방법이 있다.
- 텍스트에 첨부: 스타일 임베딩을 텍스트 임베딩에 첨부한 다음 원래 텍스트 기반 cross-attention을 통해 백본 기능과 상호 작용
- Dual cross-attention: 스타일 임베딩을 위한 새로운 cross-attention 모듈을 추가한 다음 text-conditioned feature와 style-conditioned feature를 융합
저자들의 실험에 따르면 두 번째 방법은 텍스트와 스타일 조건의 역할을 분리하는 데 있어서 첫 번째 방법을 능가하며 생성된 동영상을 텍스트 내용과 일치시키고 레퍼런스 이미지의 스타일과 유사하게 만드는 데 도움이 된다. 공식은 다음과 같다.
\[\begin{equation} F_\textrm{out}^i = \textrm{TCA} (F_\textrm{in}^i, F_t) + s^i \cdot \textrm{LN} (\textrm{SCA}(F_\textrm{in}^i, F_s)) \end{equation}\]\(F_\textrm{in}^i\)는 레이어 $i$의 backbone feature이고, LN$은 layer normalization이며, TCA와 SCA는 각각 텍스트 기반 cross-attention과 스타일 기반 cross-attention이다. $s^i$는 텍스트 기반 feature와 스타일 기반 feature의 크기의 균형을 맞추기 위해 scale factor 예측 네트워크에 의해 학습된 scale factor이다.
여기서 동기는 서로 다른 스타일 장르가 콘텐츠 표현에 대해 서로 다른 강세를 가질 수 있다는 것이다. 예를 들어, 추상적 스타일은 내용의 구체성을 감소시키는 경향이 있는 반면, 사실주의 스타일은 내용의 정확성과 특수성을 강조하는 경향이 있다. 따라서 저자들은 텍스트와 스타일 이미지에 따라 fusion scale factor를 예측하는 context-aware scale factor 예측 네트워크를 제안하였다. 구체적으로, 학습 가능한 factor query를 생성하고, 텍스트 feature $F_t$와 스타일 feature $F_s$와 상호 작용하여 Q-Former를 통해 스케일 feature를 생성한 다음 레이어별 scale factor $s \in \mathbb{R}^{16}$에 project된다.
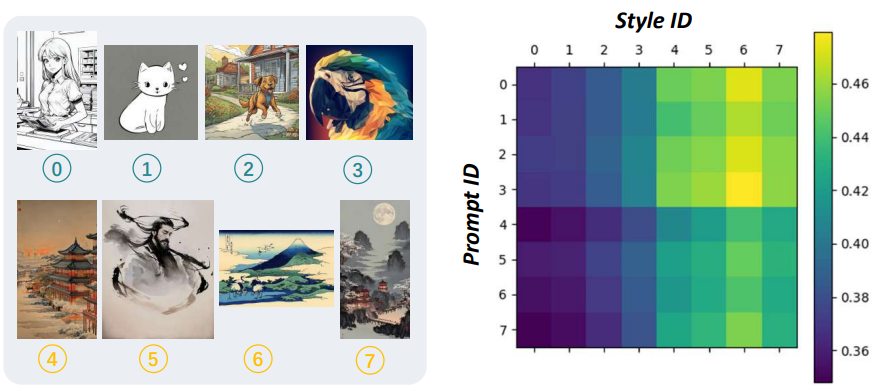
위 그림은 여러 컨텍스트 스타일 입력에 걸쳐 학습된 scale factor를 보여준다. 이는 적응형 scale factor가 스타일 장르와 강한 상관관계를 가지며 텍스트 프롬프트에도 의존한다는 것을 보여준다. 풍부한 스타일 semantic이 포함된 스타일 레퍼런스들은 일반적으로 스타일을 강조하기 위해 더 높은 scale factor를 생성한다. 복잡한 프롬프트는 콘텐츠 제어를 향상시키기 위해 더 낮은 factor를 생성하는 경향이 있다.
2. Temporal Adaptation to Stylized Features
사전 학습된 T2V 모델이 주어지면 이미지 데이터셋에 대해 학습된 스타일 어댑터는 스타일화된 이미지 생성에 잘 작동한다. 그러나 시간적 지터링과 시각적 아티팩트에 취약하며 만족스러운 스타일화된 동영상을 생성하는 데 여전히 어려움을 겪는다. 가능한 원인은 cross-frame 연산, 즉 시간적 self-attention이 스타일화된 이미지 생성 과정에 포함되지 않아 호환되지 않는 문제를 유발한다는 것이다. 따라서 통합된 스타일 어댑터를 사용하여 시간적 self-attention을 fine-tuning하는 것이 필요하다. 이미지와 동영상 공동 학습으로 스타일리시한 이미지와 사실적인 동영상이 혼합된 데이터셋에 대한 fine-tuning이 수행된다. 이는 시간 블록의 적응 학습이며 모델이 효율적으로 수렴된다.
Classifier-Free Guidance for Multiple Conditions
T2I 모델과 달리 동영상 모델은 제한된 스타일 생성 능력으로 인해 스타일 guidance에 더 높은 민감도를 나타낸다. 스타일과 컨텍스트 guidance 모두에 통합된 $\lambda$를 사용하면 바람직하지 않은 생성 결과가 발생할 수 있다. 이와 관련하여 저자들은 여러 조건의 classifier-free guidance에 대한 보다 유연한 메커니즘을 채택했다. 텍스트 조건부 분포 $\epsilon (z_t, c_t)$와 unconditional 분포 $\epsilon (z_t, \varnothing)$을 대조하여 컨텍스트 정렬을 제어하는 텍스트 기반 classifier-free guidance를 기반으로 하여, 텍스트-스타일 기반 분포 $\epsilon (z_t, c_t, c_s)$와 텍스트 기반 분포 $\epsilon (z_t, c_t)$ 사이의 차이를 style guidance $\lambda_s$로 강조한다. 전체 공식은 다음과 같다.
\[\begin{aligned} \hat{\epsilon} (z_t, c_t, c_s) = \epsilon (z_t, \varnothing) &+ \lambda_s (\epsilon (z_t, c_t, c_s) - \epsilon (z_t, c_t)) \\ &+ \lambda_t (\epsilon (z_t, c_t) - \epsilon (z_t, \varnothing)) \end{aligned}\]여기서 $c_t$와 $c_s$는 각각 텍스트 조건과 스타일 조건이다. $\varnothing$은 텍스트나 스타일 조건을 사용하지 않음을 나타낸다. 실험에서는 VideoCrafter에서 권장되는 텍스트 guidance 구성을 따라 $\lambda_t = 15.0$으로 설정하고 스타일 guidance는 경험적으로 $\lambda_s = 7.5$로 설정한다.
Experiments
- 구현 디테일
- Base T2V model: VideoCrafter
- 첫 번째 단계
- 데이터셋: 이미지 데이터셋 (WikiArt, Laion-Aethetics-6.5+)
- step: 4만
- batch size: 256
- 두 번째 단계
- 데이터셋: 이미지 데이터셋 & 동영상 데이터셋 (WebVid-10M)
- step: 2만
- batch size: 동영상 데이터는 8, 이미지 데이터는 128
- 이미지 데이터의 비율: 20%
1. Style-Guided Text-to-Image Generation
다음은 스타일 기반 T2I 생성을 정량적으로 비교한 표이다. 400쌍의 테스트셋에 대한 이미지-텍스트 정렬(Text)과 스타일 적합성(Style)에 대한 CLIP score를 평가한 결과이다.

다음은 스타일 기반 T2I 생성을 시각적으로 비교한 결과이다.

2. Style-Guided Text-to-Video Generation
다음은 스타일 기반 T2V 생성을 정량적으로 비교한 표이다. 240쌍의 테스트셋에 대한 이미지-텍스트 정렬(Text)과 스타일 적합성(Style), 시간적 품질(Temporal)에 대한 CLIP score를 평가한 결과이다.
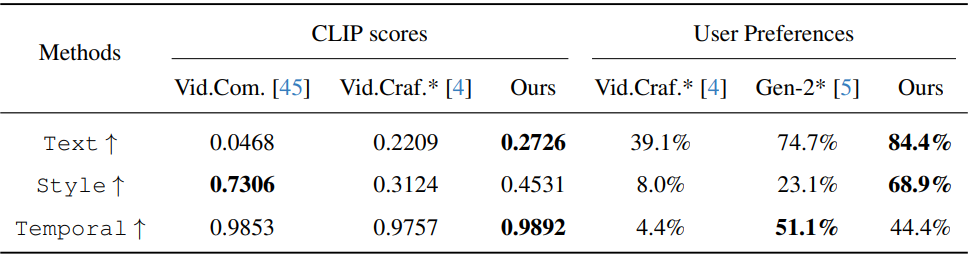
다음은 스타일 기반 T2V 생성을 시각적으로 비교한 결과이다.

다음은 여러 레퍼런스에서의 스타일 기반 T2V 생성을 정량적으로 비교한 표이다. 60쌍의 테스트셋에 대한 이미지-텍스트 정렬(Text)과 스타일 적합성(Style), 시간적 품질(Temporal)에 대한 CLIP score를 평가한 결과이다.

다음은 여러 레퍼런스에서의 스타일 기반 T2V 생성을 시각적으로 비교한 결과이다.

3. Ablation Study
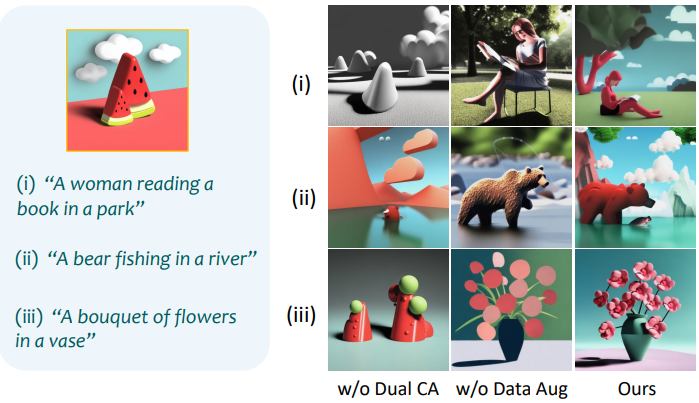
Data Augmentation & Dual Cross-Attention
다음은 스타일 변조 설계에 대한 ablation study 결과이다.
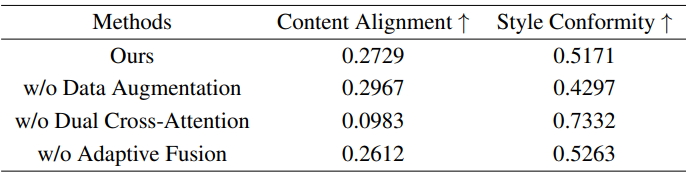
다음은 dual cross-attention과 data augmentation의 효과를 시각적으로 비교한 것이다.
Adaptive Style-Content Fusion
다음은 적응형 콘텐츠-스타일 융합의 효과를 시각적으로 비교한 것이다.

Two-Stage Training Scheme
다음은 다양한 학습 방식에 대해 비교한 것이다.

다음은 2단계 학습 방식에 대한 ablation study 결과이다.

Limitations
레퍼런스 이미지가 타겟 스타일을 충분히 표현할 수 없거나 제시된 스타일이 극도로 눈에 띄지 않는 경우 원하는 결과를 생성할 수 없다.