[논문리뷰] Training-Free Structured Diffusion Guidance for Compositional Text-to-Image Synthesis (StructureDiffusion)
ICLR 2023. [Paper] [Github]
Weixi Feng, Xuehai He, Tsu-Jui Fu, Varun Jampani, Arjun Akula, Pradyumna Narayana, Sugato Basu, Xin Eric Wang, William Yang Wang
University of California, Santa Barbara | University of California, Santa Cruz | Google
9 Dec 2022

Introduction
Text-to-Image (T2I) 합성은 텍스트 프롬프트를 입력으로 하여 자연스럽고 충실한 이미지를 생성하는 것이다. 최근에는 DALL-E 2, Imagen, Parti와 같은 초대형 비전-언어 모델을 통해 생성된 이미지의 품질이 크게 향상되었다. 특히 Stable Diffusion은 수십억 개의 텍스트-이미지 쌍을 학습한 후 탁월한 성능을 보여주는 SOTA 오픈 소스 구현이다.
고화질 이미지를 생성하는 것 외에도 여러 객체를 일관된 장면으로 구성하는 능력도 필수적이다. 사용자의 텍스트 프롬프트가 주어지면 T2I 모델은 텍스트에 언급된 대로 필요한 모든 시각적 개념을 포함하는 이미지를 생성해야 한다. 이러한 능력을 달성하려면 모델이 전체 프롬프트와 프롬프트의 개별 언어 개념을 모두 이해해야 한다. 결과적으로 모델은 여러 개념을 결합하고 학습 데이터에 포함된 적이 없는 새로운 객체를 생성할 수 있어야 한다. 본 논문에서는 복잡한 장면에서 여러 객체를 사용하여 제어 가능하고 일반화된 텍스트-이미지 합성을 달성하는 것이 필수적이므로 생성 프로세스의 합성 능력을 개선하는 데 주로 중점을 두었다.
속성 바인딩은 기존 대규모 diffusion 기반 모델에 대한 중요한 합성 문제이다. 동일한 장면에서 여러 객체를 생성하는 능력이 향상되었음에도 불구하고 기존 모델은 “흰색 건물 앞의 갈색 벤치”와 같은 프롬프트가 주어지면 여전히 실패한다. 대신 출력 이미지에는 “흰색 벤치”와 “갈색 건물”이 포함되어 있다. 이는 강력한 학습 세트의 편향 또는 부정확한 언어 이해로 인해 발생할 수 있다. 실용적인 관점에서 이러한 두 객체의 바인딩 문제를 설명하고 해결하는 것은 여러 객체가 포함된 더 복잡한 프롬프트를 이해하는 기본 단계이다. 따라서 속성을 올바른 개체에 바인딩하는 방법은 보다 복잡하고 안정적인 합성을 위한 근본적인 문제이다. 이전 연구들에서는 합성적 T2I를 다루었지만, 본 논문에서는 색상이나 재료와 같은 반사실적 속성이 있는 개방형 전경 객체를 다룬다.
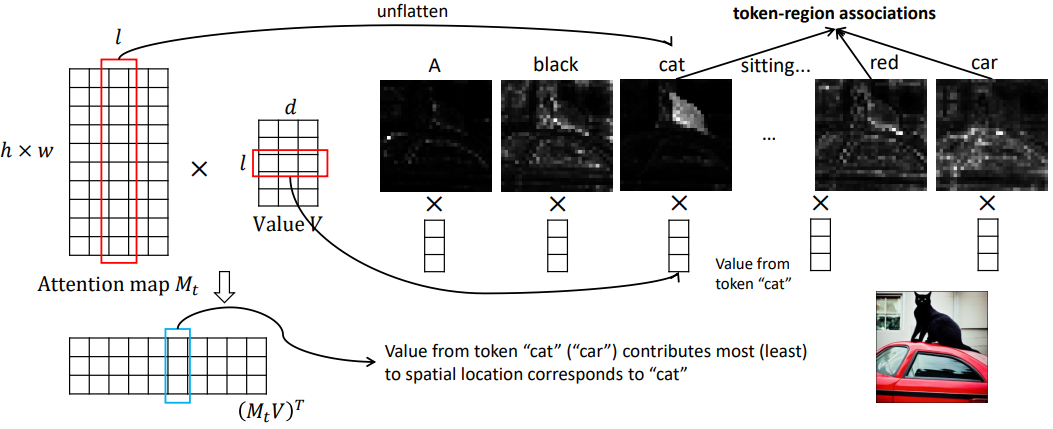
SOTA T2I 모델이 대규모 텍스트-이미지 데이터셋에 대해 학습을 받았음에도 불구하고 일부 간단한 프롬프트에 대해서는 여전히 부정확한 결과가 발생할 수 있다. 따라서 저자들은 합성 능력을 향상시키기 위한 대안적이고 데이터 효율적인 방법을 찾고자 하였다. 저자들은 속성-객체 관계 쌍이 문장의 파싱 트리에서 무료로 텍스트 범위로 얻어질 수 있음을 관찰하였다. 따라서 diffusion guidance process에 구성 트리나 장면 그래프와 같은 프롬프트의 구조화된 표현을 결합할 것을 제안하였다. 텍스트 범위는 전체 이미지의 제한된 영역만 나타낸다. 일반적으로 semantic을 해당 이미지에 매핑하기 위해서는 좌표와 같은 공간 정보가 입력으로 필요하다. 그러나 좌표 입력은 T2I 모델로 해석될 수 없다. 대신, attention map이 학습된 T2I 모델에서 토큰-영역 관계를 제공한다는 관찰을 활용하였다. Cross-attention 레이어의 key-value 쌍을 수정하여 각 텍스트 범위의 인코딩을 2D 이미지 공간의 attend된 영역에 매핑한다.
본 논문에서는 Stable Diffusion에서 유사한 관찰을 발견하고 이 속성을 활용하여 구조화된 cross-attention guidance를 구축하였다. 특히, 프롬프트에서 계층 구조를 얻기 위해 언어 파서를 사용한다. 시각적 개념이나 엔티티를 포함한 모든 수준에서 텍스트 범위를 추출하고 이를 별도로 인코딩하여 속성-객체 쌍을 서로 분리한다. Guidance를 위해 단일 텍스트 임베딩 시퀀스를 사용하는 대신 구조화된 언어 표현에서 여러 레이어의 엔티티 또는 엔티티 결합을 각각 강조하는 여러 시퀀스를 통해 합성 능력을 향상시킨다. 본 논문의 방법은 Structured Diffusion Guidance (StructureDiffusion)라고 부른다.
Diffusion Models & Structured Guidance
1. Background
Stable Diffusion
저자들은 SOTA T2I 모델인 Stable Diffusion에 대한 접근 방식과 실험을 구현하였다. Stable Diffusion은 오토인코더와 diffusion model로 구성된 2단계 방법이다. 사전 학습된 오토인코더는 이미지를 diffusion 학습을 위한 저해상도 latent map으로 인코딩한다. Inference 중에 diffusion model에서 생성된 출력을 이미지로 디코딩한다. Diffusion model은 랜덤 Gaussian noise $z^T$를 기반으로 저해상도 latent map을 생성한다. $z^T$가 주어지면 각 step $t$에서 noise 추정값을 출력하고 이를 $z^t$에서 뺀다. Noise가 없는 최종 latent map 예측 $z^0$은 오토인코더에 입력되어 이미지를 생성한다. Stable Diffusion은 noise 추정을 위해 수정된 UNet을 채택하고 텍스트 입력을 임베딩 시퀀스로 인코딩하기 위해 고정된 CLIP 텍스트 인코더를 채택한다. 다운샘플링 블록과 업샘플링 블록의 여러 cross-attention 레이어에서 이미지 공간과 텍스트 임베딩은 상호 작용한다.
CLIP Text Encoder
입력 프롬프트 $\mathcal{P}$가 주어지면 CLIP 인코더는 이를 임베딩 시퀀스 \(\mathcal{W}_p = \textrm{CLIP}_\textrm{text} (\mathcal{P})\)로 인코딩한다. 저자들의 주요 관찰은 CLIP 임베딩의 컨텍스트화가 잘못된 속성 바인딩의 잠재적인 원인이라는 것이다. 인과적 attention 마스크로 인해 시퀀스 후반부의 토큰은 그 앞의 토큰 semantic과 혼합된다. 예를 들어 사용자가 두 번째 개체에 대해 희귀한 색상 (ex. “a yellow apple and red bananas”)을 표시하면 “yellow” 임베딩이 “banana” 토큰에 attend하므로 Stable Diffusion은 바나나를 노란색으로 생성하는 경향이 있다.
Cross Attention Layers
Cross-attention 레이어는 CLIP 텍스트 인코더에서 임베딩 시퀀스를 가져와 이를 latent feature map과 융합하여 classifier-free guidance를 달성한다. 2D feature map을 $X^t$라 하면, $X^t$는 linear layer $f_Q (\cdot)$에 의해 query에 project되고 $Q^t \in \mathbb{R}^{n \times hw \times d}$로 재구성된다. 여기서 $n$은 attention head 수를 나타내고 $d$는 feature 차원이다. 마찬가지로 \(\mathcal{W}_p\)는 linear layer $f_K(\cdot)$, $f_V(\cdot)$에 의해 key와 value $K_p, V_p \in \mathbb{R}^{n \times l \times d}$로 project된다. Attention map은 query와 key 사이의 곱을 참조한다.
Cross Attention Controls
Prompt-to-prompt 논문에서는 공간 레이아웃이 Imagen의 attention map에 따라 달라지는 것을 관찰했다. 이러한 map은 생성된 이미지의 레이아웃과 구조를 제어하는 반면, value에는 attend된 영역에 매핑된 풍부한 semantic이 포함되어 있다. 따라서 attention map과 값을 별도로 제어함으로써 이미지 레이아웃과 콘텐츠를 분리할 수 있다고 가정한다.
2. Structured Diffusion Guidance
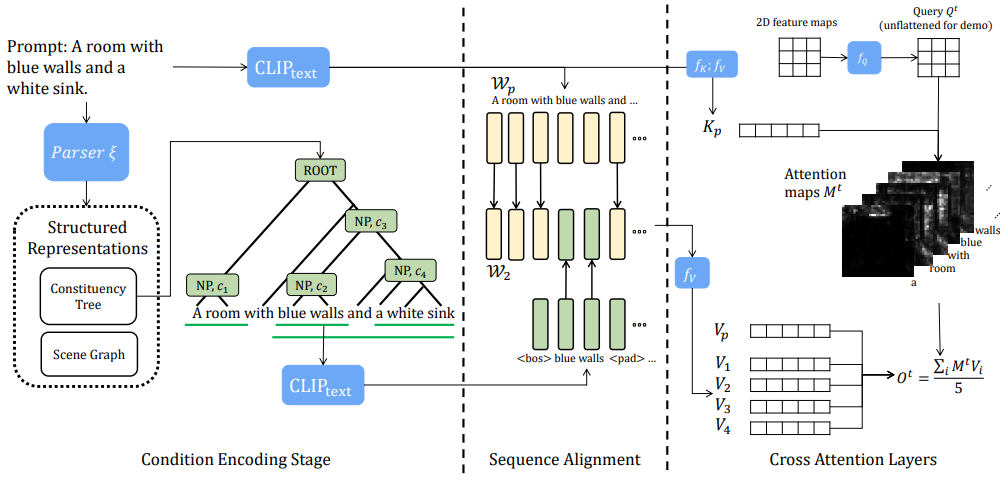
어려운 프롬프트가 주어지면 속성-객체 쌍은 구성 트리나 장면 그래프와 같은 많은 구조적 표현에서 무료로 사용할 수 있다. 저자들은 언어 구조를 cross-attention layer와 결합하는 암시적인 방법을 추구한다. 위 그림에서 볼 수 있듯이 여러 명사구(NP)를 추출하고 해당 semantic을 해당 영역에 매핑할 수 있다. $M^t$는 자연스러운 토큰-영역 관계를 제공하므로 이를 다른 NP의 여러 값에 적용하여 영역별 semantic guidance를 얻을 수 있다.
구체적으로, 파서 $\xi(\cdot)$가 주어지면 먼저 모든 레이어 레벨에서 \(\mathcal{C} = \{c_1, c_2, \ldots, c_k\}\). 파싱의 경우 트리 구조에서 모든 NP를 추출한다. 장면 그래프의 경우 객체들과 다른 객체와의 관계를 텍스트 세그먼트로 추출한다. 각 NP를 개별적으로 인코딩한다.
\[\begin{equation} \mathbb{W} = [\mathcal{W}_p, \mathcal{W}_1, \mathcal{W}_2, \ldots, \mathcal{W}_k], \\ \mathcal{W}_i = \textrm{CLIP}_\textrm{text} (c_i), \quad i = 1, \ldots, k \end{equation}\]임베딩 시퀀스 \(\mathcal{W}_i\)는 \(\mathcal{W}_p\)로 재정렬된다. $\langle \textrm{bos} \rangle$와 $\langle \textrm{pad} \rangle$ 사이의 임베딩은 \(\mathcal{W}_p\)에 삽입되어 \(\mathcal{W}_i\)로 표시되는 새로운 시퀀스를 생성한다. 전체 프롬프트 key가 누락된 객체 없이 레이아웃을 생성할 수 있다고 가정하고 \(\mathcal{W}_p\)를 사용하여 $K_p$와 $M^t$를 얻는다. $\mathbb{W}$로부터 일련의 값을 얻고 각각에 $M^t$를 곱하여 $\mathcal{C}$에서 $k$개의 NP의 결합을 얻는다.
\[\begin{equation} \mathbb{V} = [f_V (\mathcal{W}_p), f_V (\bar{\mathcal{W}}_1), \ldots, f_V (\bar{\mathcal{W}}_k)] = [V_p, V_1, \ldots, V_k] \\ O^t = \frac{1}{k+1} \sum_i (M^t V_i), \quad i = p, 1, \ldots, k \end{equation}\]\(f_V(\mathcal{W}_p)\)만을 사용한 것과 비교하면, 위 식은 $M^t$가 여전히 $Q^t$와 $K_p$로부터 계산되므로 이미지 레이아웃이나 구성을 수정하지 않는다. 그러나 Stable Diffusion은 생성된 이미지에서 객체를 생략하는 경향이 있으며, 특히 “and”라는 단어로 두 개체를 연결하는 개념 접속사의 경우 더욱 그렇다. 저자들은 $\mathcal{C}$로부터 일련의 attention map \(\mathbb{M} = \{M_p^t, M_1^t, \ldots\}\)를 계산하고 이를 $\mathbb{V}$에 곱하는 변형된 방법을 고안했다.
\[\begin{equation} \mathbb{K} = \{f_K (\mathcal{W}_i)\}, \quad \mathbb{M}^t = \{f_M (Q^t, K_i)\}, \quad i = p, 1, \ldots, k \\ O^t = \frac{1}{k+1} \sum_i (M_i^t V_k), \quad i = p, 1, \ldots, k \\ \end{equation}\]$O^t$는 특정 cross-attention layer의 출력과 최종 이미지 $x$를 생성하기 위한 다운스트림 레이어의 입력이다. 본 논문의 알고리즘은 학습이나 추가 데이터가 필요하지 않으며, Algorithm 1로 요약될 수 있다.

Experiment
- 데이터셋
- Attribute Binding Contrast set (ABC-6K)
- 서로 다른 객체를 수정하는 최소 두 가지 색상 단어가 포함되어 있는 MSCOCO의 프롬프트로 구성
- Contrast 캡션을 만들기 위해 두 가지 색상 단어의 위치를 전환
- 6400개의 캡션 (3200개의 contrastive pairs)
- Concept Conjunction 500 (CC-500)
- 두 가지 개념을 함께 결합하는 덜 자세한 프롬프트로 구성
- 프롬프트는 “a red apple and a yellow banana”와 같은 문장 패턴을 따르며 속성 설명과 함께 두 객체를 연결
1. Compositional Prompts
다음은 텍스트-이미지 정렬과 이미지 충실도 측면에서 StructureDiffusion의 생성된 이미지를 다른 모델들과 비교한 표이다.

다음은 ABC-6K에 대한 결과를 정성적으로 비교한 것이다.

2. Concept Conjunction
다음은 두 가지 측면을 강조하는 CC-500 프롬프트에 대하여 정성적으로 비교한 결과이다.

다음은 CC-500에 대한 세분화된 인간 평가 및 자동 평가 결과이다.

3. Scene Graph Input
다음은 장면 그래프 파서를 구조화된 표현을 사용하였을 때 생성된 샘플들이다.

4. Ablation Study
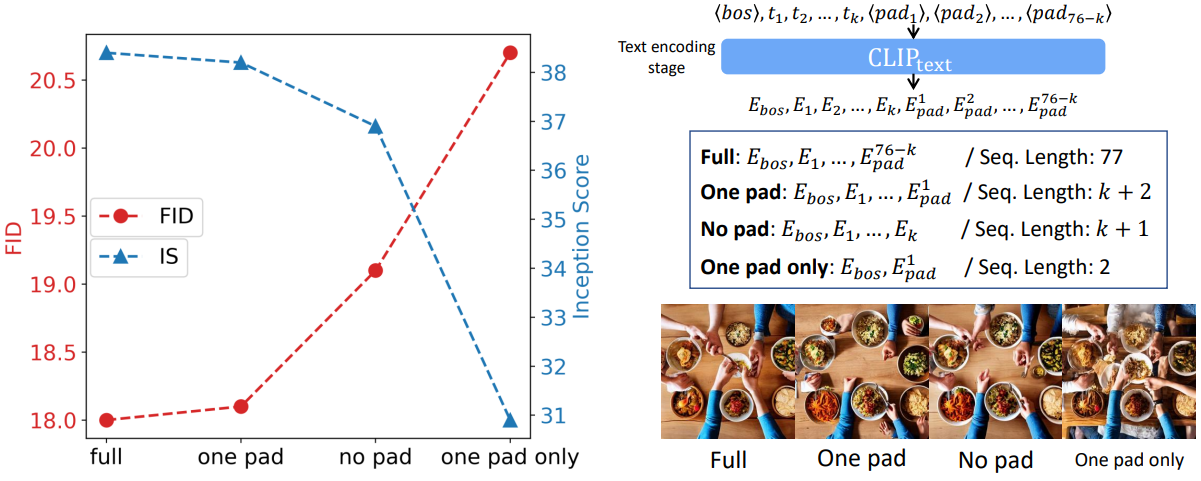
다음은 텍스트 시퀀스 임베딩에 대한 ablation 결과이다.