[논문리뷰] StableV2V: Stablizing Shape Consistency in Video-to-Video Editing
arXiv 2024. [Paper] [Page] [Github]
Chang Liu, Rui Li, Kaidong Zhang, Yunwei Lan, Dong Liu
University of Science and Technology of China
17 Nov 2024

Introduction
동영상 편집을 위한 최근 연구에서는 원본 동영상의 모션 패턴을 전송하여 편집 프로세스에 적용한다. 기존 방법은 DDIM inversion 기반, one-shot tuning 기반, 학습 기반, 첫 번째 프레임 기반으로 분류할 수 있다.
DDIM inversion 기반 방법은 DDIM 반전을 활용하여 동영상의 모션 패턴을 latent feature의 형태로 저장한 다음 편집 시 diffusion model에 주입하여 편집된 프레임과 원본 프레임 간의 일관성을 강화한다. One-shot tuning 기반 방법은 동영상별 모델 가중치를 학습하여 각 동영상의 모션 패턴을 커스터마이징하는 것을 목표로 한다. 그러나 이 두 가지 유형은 사용자 프롬프트에서 요구하는 모양과 일치하지 않는 결과를 생성하는데, 특히 모양 차이가 큰 경우가 그렇다. 학습 기반 방법은 대규모 동영상-텍스트 데이터셋에서 diffusion model을 fine-tuning하여 동영상 편집을 위한 보다 일반적인 솔루션을 제공하지만, 일반적으로 편집할 영역을 정확하게 알려주기 위해 마스크 주석이 필요하므로 사용자가 상호 작용하기 어려우며, 글로벌 패러다임의 적용이 무시된다.
첫 번째 프레임 기반 방법은 동영상 편집을 이미지 편집과 모션 전송으로 분해하여 하나의 방법으로 글로벌 및 로컬 편집을 모두 수행할 수 있는 유연한 방법이다. 그럼에도 불구하고 DDIM inversion과 one-shot tuning의 필요성으로 인해 한계가 있다. 최근, 모션의 일관성을 제한하기 위해 space-time feature loss를 제안하는 DMT가 이러한 정렬 오류를 해결하는 가장 관련성 있는 연구로 평가되지만, 조건을 만족하는 능력이 떨어지거나 배경의 디테일 손실이 종종 관찰된다. 따라서 전달되는 모션과 사용자 프롬프트 간의 일관성이 보장될 필요가 있다.
따라서 본 논문에서는 모양에 일관된 방식으로 동영상 편집을 수행하는 StableV2V를 제안하며, 이 방법은 첫 번째 프레임 기반 패러다임을 기반으로 구축되었다. 이를 위해 다음의 세 가지 주요 구성 요소로 동영상 편집을 수행한다.
- Prompted First-frame Editor (PFE)
- Iterative Shape Aligner (ISA)
- Conditional Image-to-video Generator (CIG)
PFE는 외부 프롬프트를 편집된 콘텐츠로 변환하는 첫 번째 프레임 이미지 편집기 역할을 하며, 이후 프로세스에서 다른 프레임으로 전파되어 전체 동영상을 구성한다. 특히 복잡한 모양 차이가 있는 시나리오에서 사용자 프롬프트에 필요한 모양과 잘 맞는 정확한 guidance를 제공하기 위해 편집된 콘텐츠가 소스 동영상의 모션과 동일한 모션을 공유한다고 가정한다. ISA는 각 원본 동영상 프레임의 핵심 요소에서 편집된 프레임으로 평균 모션, 모양, 깊이를 반복적으로 전파하여 모든 편집된 프레임의 시뮬레이션된 optical flow와 depth map을 생성하고, 깊이 정제 네트워크를 통해 얻은 depth map을 추가로 보정하고 정확성을 보장한다. 결국, depth map을 중간 매개체로 활용하여 소스 동영상에서 정확한 모션을 제공하고, 이를 사용하여 CIG의 이미지-동영상 생성 프로세스를 가이드하여 최종 편집된 동영상을 얻는다.
또한, 저자들은 텍스트 및 이미지 기반 동영상 편집에 대한 포괄적인 평가를 수행하기 위해 DAVIS 기반 테스트 벤치마크인 DAVIS-Edit을 수집하였다. 기존의 SOTA 방법들과 비교하였을 때, StableV2V는 시각적 품질, 일관성, inference 효율성의 관점에서 성능이 우수하다.
Method
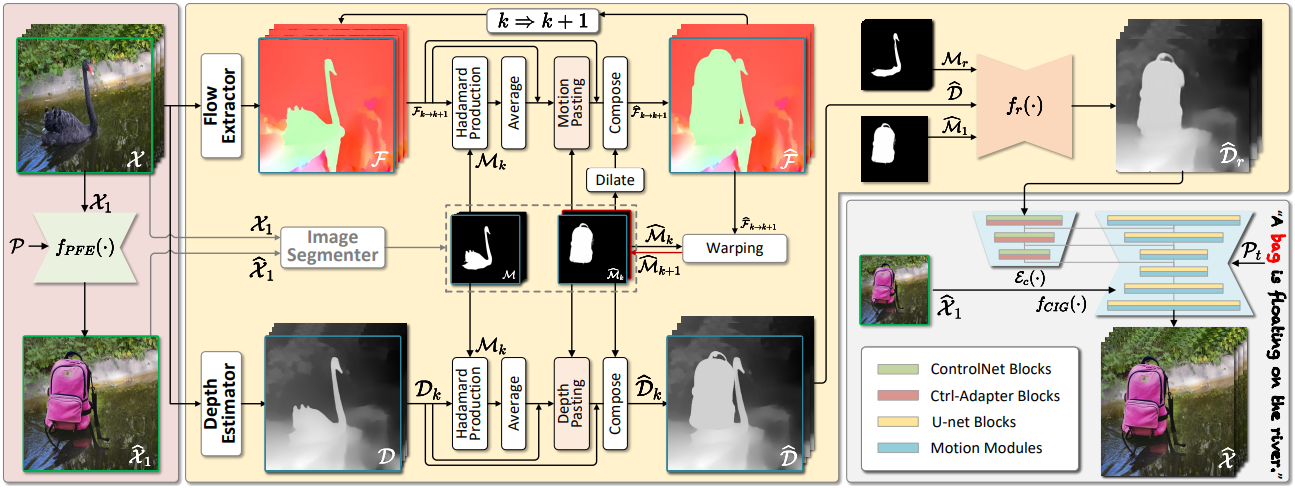
총 $N$개의 동영상 프레임이 있는 입력 동영상 \(\mathcal{X} = \{\mathcal{X}_1, \ldots, \mathcal{X}_N\}\)이 주어지면 PFE는 프롬프트 $\mathcal{P}$에 따라 첫 번째 동영상 프레임 \(\mathcal{X}_1\)을 \(\hat{\mathcal{X}}_1\)으로 편집한다. 그런 다음 ISA는 $\mathcal{X}$에서 depth map $\mathcal{D}$, optical flow $\mathcal{F}$, segmentation mask $\mathcal{M}$을 추출하고 \(\hat{\mathcal{X}}_1\)의 \(\hat{\mathcal{M}}_1\)과 $\mathcal{D}$, $\mathcal{F}$, $\mathcal{M}$를 기반으로 편집된 동영상의 depth map \(\hat{\mathcal{D}_r}\)을 시뮬레이션한다. CIG는 depth-guided image-to-video generator 역할을 하며, \(\hat{\mathcal{D}_r}\)과 \(\hat{\mathcal{X}}_1\)을 활용하여 전체 편집 동영상 \(\hat{\mathcal{X}}\)를 생성한다.
1. Prompted First-frame Editor
StableV2V는 동영상 편집을 이미지 편집과 제어된 image-to-video 생성으로 분해하는 첫 번째 프레임 기반 방법을 기반으로 구축되었으므로, 먼저 PFE로 프롬프트를 첫 번째 동영상 프레임의 편집된 콘텐츠로 변환한다. 입력 동영상 \(\mathcal{X} = \{\mathcal{X}_1, \ldots, \mathcal{X}_N\}\)이 주어지면 첫 번째 프레임 \(\mathcal{X}_1\)과 프롬프트 $\mathcal{P}$를 PFE로 보낸다.
\[\begin{equation} \hat{\mathcal{X}}_1 = f_\textrm{PFE} (\mathcal{X}_1, \mathcal{P}) \end{equation}\]저자들은 프롬프트 입력 $\mathcal{P}$로 텍스트 설명, 사용자 명령, 레퍼런스 이미지 등 다양한 프롬프트 유형을 고려하였으며, 이러한 프롬프트를 적절히 처리하기 위해 기존 이미지 편집기를 채택하였다. 예를 들어, SD Inpaint나 InstructPix2Pix와 같은 텍스트 기반 편집기를 활용하여 텍스트 입력을 처리하고 Paint-by-Example과 같은 모델을 채택하여 레퍼런스 이미지 프롬프트를 통합한다.
2. Iterative Shape Aligner
첫 번째 편집된 프레임 \(\hat{\mathcal{X}}_1\)을 얻으면 다음 단계는 편집된 내용을 나머지 동영상 프레임으로 전파하는 것이다. 기존 연구에서는 소스 동영상에서 모션을 직접 전파하여 좋지 못한 결과를 얻었다. 이 경우 전달된 모션은 사용자가 기대하는 내용과 일관성을 유지하기 위해 어려움을 겪는다. 특히 사용자 프롬프트가 상당한 모양 변경을 일으킬 수 있는 경우 편집된 동영상에 아티팩트가 발생한다. 따라서 동영상 편집의 일관성을 보장하기 위해 이러한 정렬 오류를 해결하는 효과적인 디자인이 중요하다.
저자들은 전달된 모션과 사용자 프롬프트 간의 정렬을 확립하고 나중에 CIG가 최종 동영상을 제작할 수 있도록 정확한 guidance를 제공하는 ISA를 제안하였다. 구체적으로, 편집된 콘텐츠와 원본 콘텐츠가 동일한 모션 및 깊이 정보를 공유한다고 가정하고 depth map을 모션 정보를 전달하는 중간 매체로 간주한다. 이 가정에 따라 ISA는 모든 편집된 동영상 프레임의 모션 및 깊이 정보를 순차적으로 시뮬레이션하고 추가적인 정제 네트워크를 활용하여 CIG에 대한 정확한 모션 guidance를 얻는다.
모션 시뮬레이션
편집된 동영상의 모션 정보를 시뮬레이션하기 위해 optical flow를 사용하여 모션을 표현한다. Optical flow 추출기인 RAFT를 사용하여 $\mathcal{X}$에서 optical flow \(\mathcal{F} = \{\mathcal{F}_{1 \rightarrow 2}, \ldots, \mathcal{F}_{N-1 \rightarrow N}\}\)을 얻는다. 또한 SAM을 사용하여 $\mathcal{X}$의 모든 프레임과 \(\hat{\mathcal{X}}_1\)의 segmentation mask인 \(\mathcal{M} = \{\mathcal{M}_1, \ldots, \mathcal{M}_N\}\)과 \(\hat{\mathcal{M}}_1\)을 얻는다. 편집된 콘텐츠와 원본 콘텐츠가 동일한 모션 정보를 공유한다는 점을 고려하여 먼저 \(\mathcal{M}_k\) 내의 $k$번째 optical flow \(\mathcal{F}_{k \rightarrow k+1}\)의 평균값을 계산하여 평균 모션을 표현한다.
\[\begin{equation} \bar{\mathcal{F}}_{k \rightarrow k+1} = \frac{1}{\mathcal{M}_k} \sum_{(i,j) \in \mathcal{M}_k} \mathcal{F}_{k \rightarrow k+1} (i,j) \end{equation}\]그런 다음 \(\hat{\mathcal{M}_k}\)에서 모션 붙여넣기 연산을 수행하여 편집된 콘텐츠의 영역 내에서 optical flow를 시뮬레이션한다.
\[\begin{equation} \hat{\mathcal{F}}_k^\textrm{mp} (x,y) = \begin{cases} \bar{\mathcal{F}}_{k \rightarrow k+1}, & (x, y) \in f_d (\hat{\mathcal{M}}_k) \\ 0, & \textrm{otherwise} \end{cases} \end{equation}\]($f_d (\cdot)$는 binary dilation)
그런 다음, $k$번째 편집된 프레임 \(\hat{\mathcal{F}}_{k \rightarrow k+1}\)을 다음과 같이 얻는다.
\[\begin{equation} \hat{\mathcal{F}}_{k \rightarrow k+1} = \mathcal{F}_{k \rightarrow k+1} \odot (1 - f_d (\hat{\mathcal{M}}_k)) + \hat{\mathcal{F}}_k^\textrm{mp} \end{equation}\]\(\hat{\mathcal{F}}_{k \rightarrow k+1}\)이 시뮬레이션되면 \(\hat{\mathcal{M}}_k\)를 warping하여 \(\hat{\mathcal{M}}_{k+1}\)을 얻는다.
\[\begin{equation} \hat{\mathcal{M}}_{k+1} = f_w (\hat{\mathcal{M}}_k, \hat{\mathcal{F}}_{k \rightarrow k+1}) \end{equation}\]$k = 1$에서 $k = N-1$까지 optical flow를 반복적으로 시뮬레이션하여 결국 모든 편집된 프레임의 optical flow \(\hat{\mathcal{F}} = \{\hat{\mathcal{F}}_{1 \rightarrow 2}, \ldots, \hat{\mathcal{F}}_{N-1 \rightarrow N}\}\)을 얻는다.
깊이 시뮬레이션
편집된 동영상의 모션 정보를 시뮬레이션한 후, 다음 단계는 image-to-video generator를 위한 guidance, 즉 depth map을 얻는 것이다. 이를 위해 모션 시뮬레이션과 유사한 절차를 수행한다. 구체적으로, 먼저 MiDaS를 사용하여 $\mathcal{X}$에서 depth map \(\mathcal{D} = \{\mathcal{D}_1, \ldots, \mathcal{D}_N\}\)을 추출한다. $k$번째 depth map \(\mathcal{D}_k\)가 주어지면 다음과 같이 모션과 유사하게 평균 깊이를 계산한다.
\[\begin{equation} \bar{\mathcal{D}}_k = \frac{1}{\mathcal{M}_k} \sum_{(i,j) \in \mathcal{M}_k} \mathcal{D}_k (i,j) \end{equation}\]그런 다음, 다음과 같이 시뮬레이션된 $k$번째 depth map \(\hat{\mathcal{D}}_k\)를 구성한다.
\[\begin{aligned} \hat{\mathcal{D}}_k^\textrm{dp} (x, y) &= \begin{cases} \bar{\mathcal{D}}_k, & (x, y) \in \hat{\mathcal{M}}_k \\ 0, & \textrm{otherwise} \end{cases} \hat{\mathcal{D}}_k &= \mathcal{D}_k \odot (1 - \hat{\mathcal{M}}_k) + \hat{\mathcal{D}}_k^\textrm{dp} \end{aligned}\]모든 depth map \(\mathcal{D} = \{\mathcal{D}_1, \ldots, \mathcal{D}_{N-1}\}\)을 반복함으로써, 모든 편집된 동영상 프레임의 시뮬레이션된 depth map \(\hat{\mathcal{D}} = \{\hat{\mathcal{D}}_1, \ldots, \hat{\mathcal{D}}_N\}\)을 얻을 수 있다. 시뮬레이션된 depth map \(\hat{\mathcal{D}}\)는 합성을 통해 얻어지므로, 아래 그림에서 볼 수 있듯이 종종 원본 콘텐츠의 영역에 불필요한 깊이 정보가 포함되어 있다. 이는 \(\hat{\mathcal{D}}\)의 정확성을 보장하기 위해 \(\hat{\mathcal{D}}\)를 더욱 디테일하게 다듬어야 함을 나타낸다.

Shape-guided Depth Refinement
\(\hat{\mathcal{D}}\)를 정제하기 위해, optical flow를 완성하여 동영상을 인페인팅하는 ProPainter의 패러다임에 기반한 깊이 정제 네트워크를 제안하였다. 나아가, 정제의 모양 일관성을 보장하기 위해 첫 번째 프레임의 모양 마스크 \(\hat{\mathcal{M}}_1\)을 통합한다. $\mathcal{M}$과 $\hat{\mathcal{M}}$이 주어지면, 마스크 영역 \(\mathcal{M}_r\)과 마스킹된 depth map \(\hat{\mathcal{D}}_m\)은 다음을 통해 얻는다.
\[\begin{aligned} \mathcal{M}_r &= f_d ((1 - \hat{\mathcal{M}}) \odot \mathcal{M}) \\ \hat{\mathcal{D}}_m &= \mathcal{M}_r \odot \hat{\mathcal{D}} \end{aligned}\]그런 다음 \(\hat{\mathcal{D}}_m\), \(\mathcal{M}_r\), \(\hat{\mathcal{M}}_1\)을 concat하여 shape-guided refinement network $f_r (\cdot)$로 보내면 최종 depth map \(\hat{\mathcal{D}}_r\)이 생성된다.
\[\begin{equation} \hat{\mathcal{D}}_r = f_r (\hat{\mathcal{D}}_m, \mathcal{M}_r, \mathcal{M}_1) \end{equation}\]이런 방식으로 ISA는 편집된 동영상의 정확하게 시뮬레이션된 depth map \(\hat{\mathcal{D}}_r\)을 얻을 수 있으며, \(\hat{\mathcal{D}}_r\)은 나중에 CIG에 정확한 guidance를 제공하는 데 중심적인 역할을 한다.
3. Conditional Image-to-video Generator
\(\hat{\mathcal{D}}_r\)을 얻으면 CIG의 최종 목표는 편집된 동영상 \(\hat{\mathcal{X}}\)를 생성하는 것이다. 구체적으로 CIG는 컨트롤러 모델과 image-to-video generator라는 두 가지 구성 요소로 구성되어 있으며, Ctrl-Adapter를 컨트롤러로 사용하여 \(\hat{\mathcal{D}}_r\)을 주입하고 I2VGen-XL을 활용하여 편집된 내용을 \(\hat{\mathcal{X}}_1\)에서 \(\hat{\mathcal{X}}\)의 다른 모든 프레임으로 전파한다.
텍스트 프롬프트 \(\mathcal{P}_t\)와 \(\hat{\mathcal{D}}_r\)이 주어지면 CIG는 다음과 같이 최종 편집된 동영상 \(\hat{\mathcal{X}}\)를 생성한다.
\[\begin{equation} \hat{\mathcal{X}} = \{\hat{\mathcal{X}}_1, \ldots, \hat{\mathcal{X}}_N\} = f_\textrm{CIG} (\hat{\mathcal{X}}_1, \mathcal{P}_t, \mathcal{E}_c (\hat{\mathcal{D}}_r)) \end{equation}\]Experiments
1. Performance Comparison and Human Evaluation
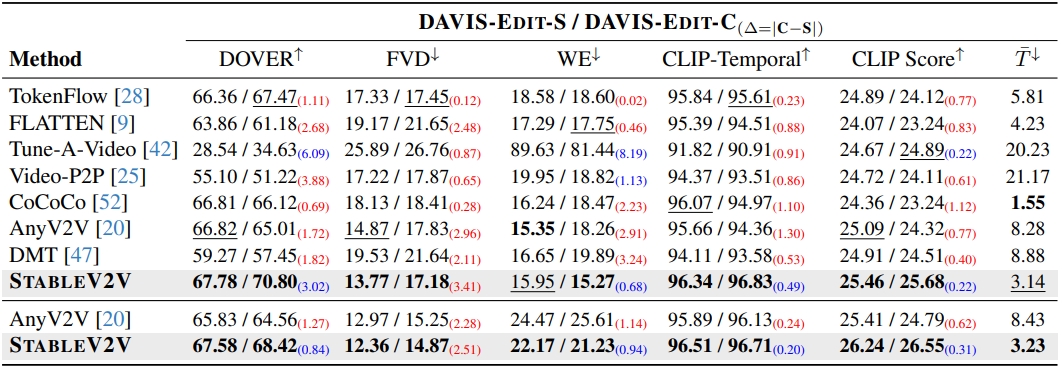
다음은 DAVIS-Edit에서 다른 방법들과 StableV2V를 비교한 표이다. (위는 텍스트 기반 편집, 아래는 이미지 기반 편집)
다음은 텍스트 및 이미지 기반 편집 결과를 비교한 것이다.

다음은 human evaluation 결과이다.

2. Applications
다음은 StableV2V을 활용한 다양한 application의 예시이다.

3. Ablation Studies
다음은 텍스트 기반 편집에서 PFE에 대한 ablation 결과이다.


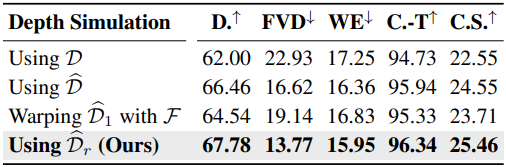
다음은 깊이 시뮬레이션에 대한 ablation 결과이다.