[논문리뷰] StableRep: Synthetic Images from Text-to-Image Models Make Strong Visual Representation Learners
arXiv 2023. [Paper] [Github]
Yonglong Tian, Lijie Fan, Phillip Isola, Huiwen Chang, Dilip Krishnan
Google Research | MIT CSAIL
1 Jun 2023
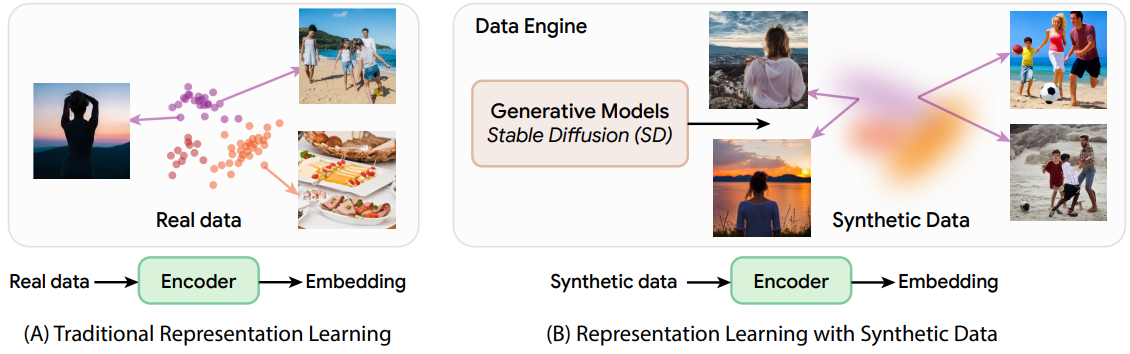
Introduction
데이터는 현대 기계 학습 시스템의 성공을 위한 핵심 구성 요소로서 가장 중요한 역할을 담당해 왔다. 특히 다양한 도메인의 foundation model은 방대하고 다양한 데이터셋에 크게 의존한다. 데이터 내에 캡슐화된 집단 정보를 통해 학습하므로 데이터의 품질, 수량, 다양성은 이러한 모델들의 성능과 효율성에 큰 영향을 미친다. 데이터 중심 시대에 핵심 질문은 AI 모델을 학습시키기 위해 어떻게 그렇게 많은 양의 다양한 데이터를 수집할 수 있는가 하는 것이다.
예를 들어, 새로운 컴퓨터 비전 문제를 해결하려고 하며 이에 대한 데이터(이미지)를 수집해야 한다. 이상적인 상황은 어느 곳에나 카메라를 배치하고 필요한 모든 것을 캡처하는 것이다. 하지만 현실적으로 데이터 수집은 쉽지 않다. 연구자들은 데이터를 수집하기 위해 인터넷을 크롤링했다. 이러한 방식으로 수집된 잡음이 많고 선별되지 않은 데이터는 실제 문제와의 도메인 격차를 나타낼 수 있으며 사회적 편견으로 인한 불균형을 반영할 수 있다. 사람이 라벨링을 통해 대용량 데이터의 불완전성을 제거하거나 줄이는 것은 비용이 많이 들고 엄두도 못 낼 수 있다.
그러나 데이터 수집을 자연어 명령으로 단순화할 수 있다면 어떨까? 거의 비용을 들이지 않고 몇 밀리초마다 사진을 찍을 수 있다면 어떨까? 이것은 환상적으로 들리지만 현대의 text-to-image 생성 모델이 이 비전에 접근하고 있다. 언젠가는 사진을 찍는 대신 이를 데이터 소스로 사용할 수 있다는 것이 오랫동안 꿈이었다. 본 논문에서는 이것이 대규모 시각적 표현 학습의 맥락에서 실용적인 옵션인지 연구하였다.
이를 위해 저자들은 최고의 오픈 소스 test-to-image 모델 중 하나인 Stable Diffusion을 사용하기로 결정했다. CC12M과 RedCaps와 같은 대규모 이미지-텍스트 데이터셋의 텍스트로 Stable Diffusion을 프롬프팅하여 이미지를 합성한다. 놀랍게도 저자들의 조사에 따르면 classifier-free guidance scale을 적절하게 구성하면 self-supervised learning이 동일한 샘플 크기의 실제 이미지에 대한 학습과 동등하거나 더 나은 성능을 발휘할 수 있는 이미지를 합성할 수 있는 것으로 나타났다. 저자들은 이미지 내 불변성(intra-image invariance)을 촉진하는 contrastive self-supervised learning 아이디어에서 영감을 받아 캡션 내 불변성(intra-caption invariance)을 촉진하는 표현 학습 접근 방식을 개발하였다. 동일한 텍스트 프롬프트에서 생성된 여러 이미지를 서로에 대한 positive로 처리하고 이를 multi-positive contrastive loss에 사용하여 이를 달성한다. 합성 이미지만을 사용한 학습에도 불구하고 StableRep이라고 하는 이 접근 방식은 다양한 표현 평가 벤치마크에서 CLIP과 같은 SOTA 방법보다 성능이 뛰어나다.
직관적으로 합성 데이터가 실제 데이터보다 나을 수 있는 이유 중 하나는 Stable Diffusion의 guidance scale, 텍스트 프롬프트, latent noise를 통해 샘플링을 더 높은 수준으로 제어할 수 있기 때문이다. 또한 생성 모델은 학습 데이터 이상으로 일반화할 수 있는 잠재력을 갖고 있으므로 실제 데이터보다 더 풍부한 학습 세트를 제공한다.
Standard Self-supervised Learning on Synthetic Images
일반적인 시각적 표현 학습 알고리즘은 이미지 데이터셋 \(\{x_i\}_{i=1}^N\)을 입력으로 사용하고 이미지 $x$를 벡터 $e$에 삽입하는 이미지 인코더 $F : x \mapsto e$를 생성한다. 본 논문에서는 실제 이미지 데이터셋 대신 생성 모델 $G$를 사용하여 좋은 $F$를 생성하려고 한다. 구체적으로 텍스트 $t$와 latent noise $z$ 쌍을 이미지 $x$에 매핑하는 text-to-image 생성 모델 $G: (t, z) \mapsto x$에 중점을 둔다. 최고의 성능을 발휘하는 여러 가지 text-to-image 모델이 있지만 저자들은 공개적으로 사용 가능하고 널리 사용되는 Stable Diffusion v1-5을 사용하여 탐색을 수행하였다.
1. Synthetic images from Stable diffusion
Stable Diffusion은 오토인코더의 latent space에서 diffusion process를 실행하는 DDPM이다. 이는 조건부 score 추정치 $\epsilon (t, z_\lambda)$와 unconditional 추정치 $\epsilon (z_\lambda)$를 각 step $\lambda$의 guidance scale $w$와 선형적으로 결합하는 classifier-free guidance를 통해 샘플 품질과 텍스트-이미지 정렬을 향상시킨다.
\[\begin{equation} \tilde{\epsilon} (t, z_\lambda) = w \epsilon (t, z_\lambda) + (1 - w) \epsilon (z_\lambda) \end{equation}\]Stable Diffusion 모델 $G_\textrm{sd}$는 텍스트 소스를 사용하여 이미지를 생성한다. 처음부터 캡션 모음을 수집하는 대신 CC3M, CC12M과 같은 기존의 선별되지 않은 이미지-텍스트 쌍 데이터셋의 텍스트 부분을 사용한다. 이미지 캡션 데이터셋 \(\{t_i\}_{i=1}^N\)이 주어지면 캡션당 하나의 이미지를 생성하여 동일한 크기의 합성 이미지 데이터셋을 구성한다.
2. Self-supervised learning on synthetic images
최근 대표적인 self-supervised learning 알고리즘은 주로 두 가지 계열에서 나온다.
- 동일한 이미지의 다양한 augmentation의 임베딩 간의 불변성을 장려하는 contrastive learning
- 모델이 마스킹되지 않은 패치를 사용하여 마스킹된 패치를 예측하는 masked image modeling
본 논문에서는 단순성과 강력한 성능으로 인해 전자에서 SimCLR을 선택하고 후자에서 MAE를 선택했다. 저자들은 ViT 아키텍처에 중점을 두고 있으며 언급하는 경우를 제외하고는 CC3M의 캡션을 사용하였다.
SimCLR
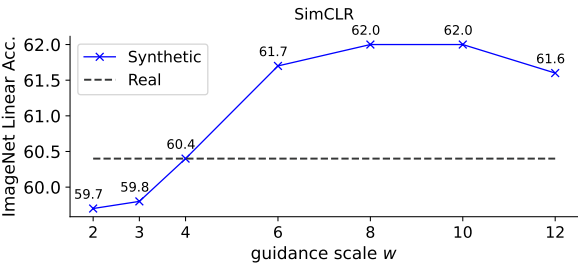
저자들은 합성 이미지 데이터셋에서 ViT-B/16을 사용하여 SimCLR을 직접 학습시키고 ImageNet에서 linear probing 평가를 통해 표현 품질을 측정하였다. 고려해야 할 한 가지 요소는 classifier-free guidance scale $w$이다. 이는 합성된 이미지의 다양성과 품질 사이에서 균형을 이루고 학습된 표현에 영향을 미칠 수 있기 때문이다. 이를 연구하기 위해 {2, 3, 4, 6, 8, 10, 12}의 각 $w$에 대해 SimCLR을 학습시키기 위해 크기 $N$의 복사본을 생성한다. 위 그래프는 $w$의 영향을 시각화한 것이다. 최적의 $w$는 약 8이다. 이는 $w = 2$가 최적인 FID와는 다르다.
합성 이미지를 생성하는 데 사용된 캡션 \(\{t_i\}_{i=1}^N\)도 $N$개의 실제 이미지와 쌍을 이룬다. 저자들은 이러한 실제 이미지를 사용하여 SimCLR 모델을 학습시켰다. 이 모델은 60.4%의 정확도를 달성했으며 ImageNet의 사전 학습에 비해 선형 정확도가 13% 감소했다. 이러한 격차는 일반적으로 선별되지 않은 사전 학습 데이터에서 관찰되었다. 그러나 흥미롭고 놀랍게도 $w = 8$인 합성 이미지는 실제 이미지보다 정확도가 1.6% 더 높다.
MAE
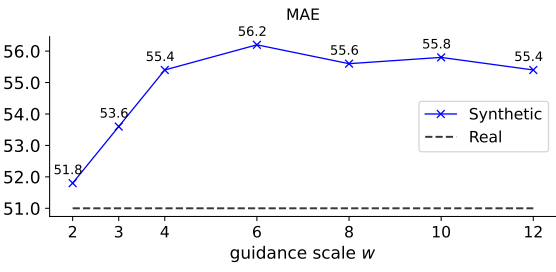
저자들은 MAE의 기본 hyperparameter에 따라 각 guidance scale $w$에 대해 ViT-B/16 모델을 학습시켰다. 위 그래프는 linear probing 결과이다. 합성 이미지의 정확도는 $w = 2$ 이후에 $w$에 따라 빠르게 증가하고 $w$가 클 때 점차 감소한다. MAE의 최적 $w$는 6이며 정확도가 8 또는 10에서 최고조에 달하는 SimCLR과 다르다. 이는 서로 다른 방법에 서로 다른 w가 필요할 수 있음을 시사한다. $w = 6$인 경우 합성 이미지는 실제 이미지보다 4.2% 더 나은 정확도를 갖는다.
MAE의 linear probing 정확도는 contrastive learning 방법보다 낮지만 fine-tuning을 통해 효율성을 높이는 경우가 많다. 저자들은 ImageNet에서 사전 학습된 MAE 모델을 fine-tuning할 때 합성 이미지가 여전히 실제 이미지보다 성능이 뛰어날 수 있음을 발견했다. 예를 들어, $w = 6$인 합성 이미지는 실제 이미지보다 0.3% 더 높다.
다른 SSL 방법들
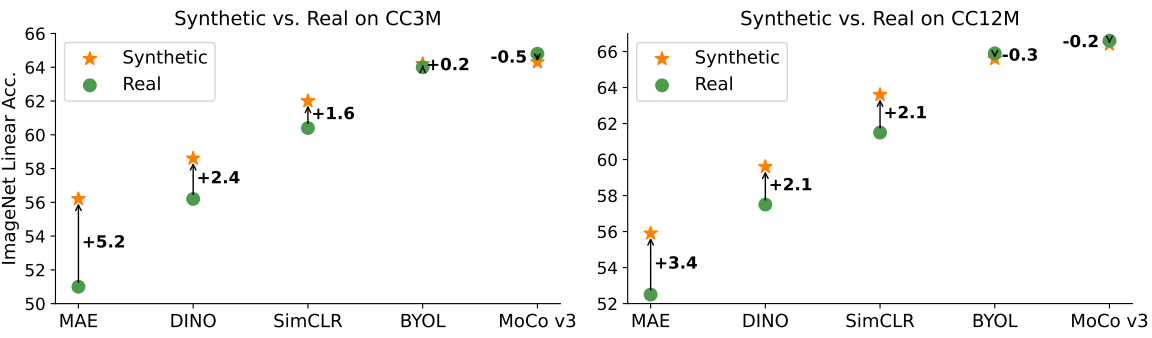
저자들은 합성 이미지를 다양한 self-supervised learning (SSL) 방법에 일반적으로 적용될 수 있는지 테스트하기 위해 BYOL, MoCo-v3, DINO라는 세 가지 대표적인 접근 방식을 시도하였다. 저자들은 각 방법에 대해 $w$를 튜닝하지 않고 대신 SimCLR에 대해 발견된 최적의 $w = 8$을 적용하였다. CC3M과 CC12M의 결과는 위 그림에 시각화되어 있다. 합성 이미지는 MAE, DINO, SimCLR의 경우 실제 이미지보다 크게 향상되고 BYOL의 경우 실제와 동등한 성능을 발휘하며 MoCo-v3의 경우 약간 더 나쁘다 ($w$를 튜닝하지 않았기 때문일 수 있음).
Multi-Positive Contrastive Learning with Synthetic Images
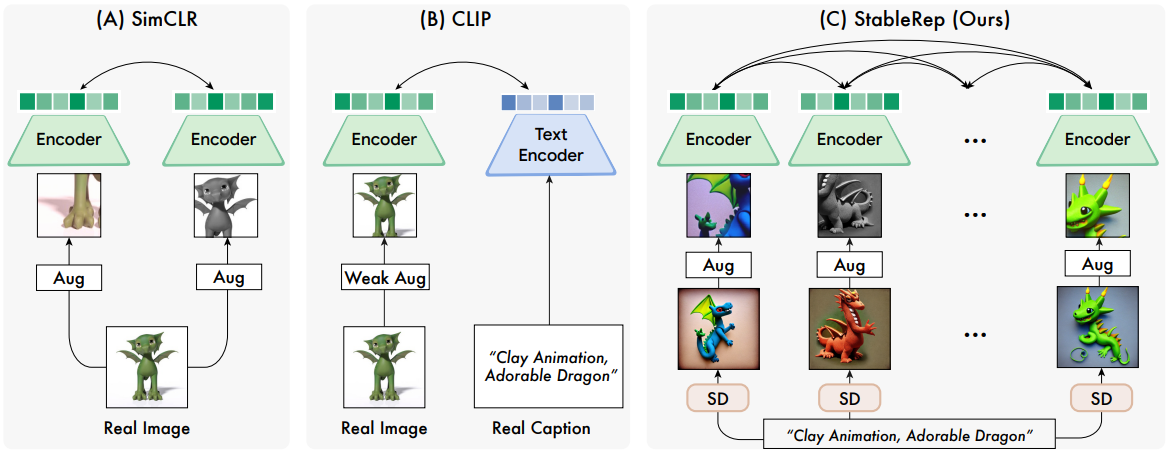
Text-to-image 생성 모델은 contrastive learning을 위한 positive 샘플을 구성하는 새로운 방법을 제공한다. 이미지 캡션이 주어지면 다양한 latent noise $z$를 사용하여 reverse process를 시작하여 여러 개의 다양한 샘플을 생성할 수 있다. 이러한 이미지들은 동일한 프롬프트를 사용하여 생성되므로 유사한 시각적 의미를 가지므로 contrastive learning에서 서로에 대한 다중 positive 샘플로 사용하기에 적합하다. 각 캡션에 대해 여러 이미지를 대규모로 수집하는 것은 불가능하기 때문에 이 속성은 생성 모델에 고유하다. 위 그림은 StableRep 파이프라인을 SimCLR 및 CLIP의 파이프라인과 비교한 것이다.
Multi-positive contrastive loss
저자들은 multi-positive contrastive learning을 매칭 문제로 설명한다. 인코딩된 앵커 샘플 $a$와 인코딩된 후보 집합 \(\{b_1, b_2, \ldots, b_K\}\)를 생각해보자. $a$가 각 $b$와 일치할 가능성을 설명하는 contrastive 카테고리 분포 $q$를 계산한다.
\[\begin{equation} q_i = \frac{\exp (a \cdot b_i / \tau)}{\sum_{j=1}^K \exp (a \cdot b_j / \tau)} \end{equation}\]여기서 $\tau \in \mathbb{R}_{+}$는 스칼라 temperature hyperparameter이고, $a$와 모든 $b$는 $\ell_2$ 정규화되었다. 직관적으로 이는 모든 인코딩된 후보에 대한 K-way softmax classification 분포이다. 앵커 $a$와 일치하는 후보가 하나 이상 있다고 생각해보자. 그러면 ground-truth 카테고리 분포 $p$는 다음과 같다.
\[\begin{equation} p_i = \frac{\unicode{x1D7D9}_{\textrm{match}(a, b_i)}}{\sum_{j=1}^K \unicode{x1D7D9}_{\textrm{match}(a, b_j)}} \end{equation}\]여기서 indicator 함수 \(\unicode{x1D7D9}_{\textrm{match}(\cdot, \cdot)}\)는 앵커와 후보가 일치하는지 여부를 나타낸다. 그러면 multi-positive contrastive loss는 ground-truth 분포 $p$와 contrastive 분포 $q$ 사이의 cross-entropy이다.
\[\begin{equation} \mathcal{L} = H (p, q) = - \sum_{i=1}^K p_i \log q_i \end{equation}\]이는 널리 사용되는 multi-positive contrastive loss의 일반화된 형태이다.

Batched multi-positive contrastive learning 알고리즘의 PyTorch-like pseudo-code는 Algorithm 1과 같다. 각 batch는 $n \times m$개의 이미지로 구성된다. 즉, $n$개의 캡션 각각에 대해 $m$개의 이미지를 샘플링한다는 의미이다. 여기서는 동일한 캡션의 이미지가 다르더라도 여전히 data augmentation을 적용하며, 이는 사전 생성된 합성 이미지에 대해 여러 epoch의 학습을 수행하므로 overfitting을 줄이기 위한 것이다.
Experiments
- 아키텍처
- Backbone: ViT
- CLS 토큰에 3-layer MLP projection head를 적용
- hidden layer 차원: 4096
- 출력 차원: 256
- Batch Normalization 적용
- 학습 디테일
- batch size: 8192
- optimizer: AdamW ($\beta_1$ = 0.9, $\beta_2$ = 0.98)
- learning rate: 0.0032
- weight decay: 0.1
- 각 텍스트 프롬프트마다 10개의 이미지를 미리 생성
- 각 iteration에서 10개 중 6개를 랜덤하게 선택하여 학습 batch 구성
1. Main results on CC12M and RedCaps
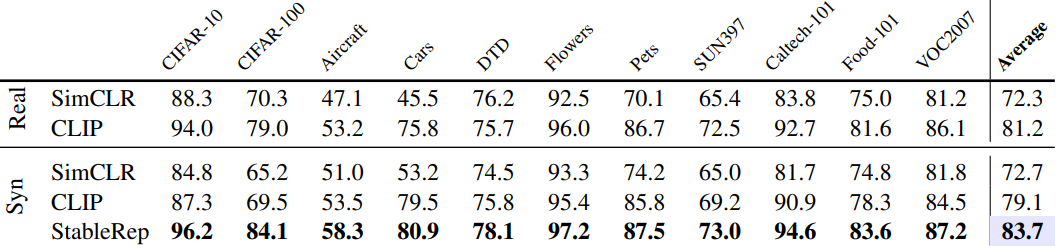
다음은 ImageNet에서의 linear probing 결과이다.

다음은 ImageNet의 다양한 도메인에서의 linear probing 결과이다.
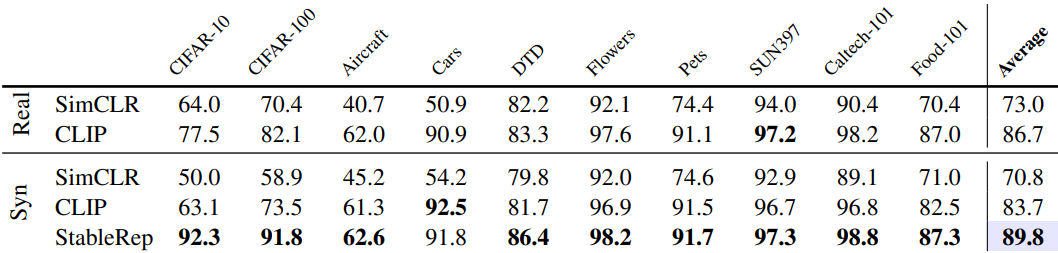
다음은 few-shot 이미지 분류 결과이다.
다음은 UperNet을 사용한 ADE20k semantic segmentation 결과(mIoU)이다.
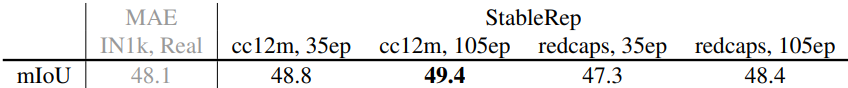
2. Ablation analysis
다음은 생성 예산 $T$가 주어지면 $T/l$개의 캡션을 사용하고 캡션당 $l$개의 이미지를 생성하였을 때의 결과이다. $l = 1$이면 SimCLR이다.
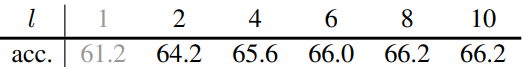
다음은 batch size가 $C$일 떄 $C/m$개의 캡션과 캡션당 $m$개의 이미지를 샘플링하여 각 batch를 구성하였을 때의 결과이다. $m = 1$이면 SimCLR이다.
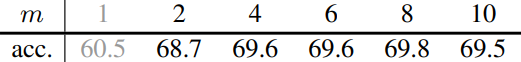
다음은 guidance scale $w$, 모델 크기, 학습 epoch 수에 대한 ablation study 결과이다.

Adding Language Supervision
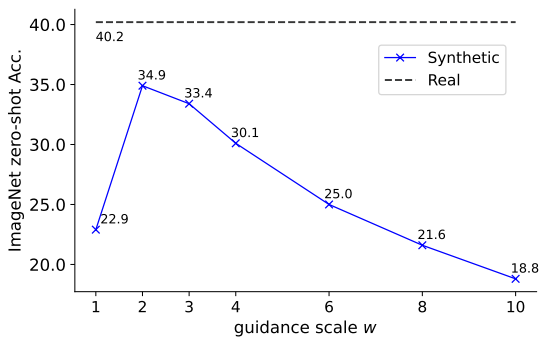
합성 이미지를 사용한 CLIP 학습은 어떻게 작동할까? 저자들은 각 guidance scale $w$에 대한 복사본(캡션당 하나의 이미지)을 생성하고 각 복사본을 사용하여 CLIP을 학습시킴으로써 이 질문을 연구하였다. 위 그림은 zeor-shot ImageNet 정확도를 보여준다. SSL 방식과 달리 CLIP은 더 낮은 $w$를 선호한다. 최적의 $w = 2$로 CLIP은 34.9%의 zero-shot 정확도를 달성하며, 이는 실제 이미지 학습(40.2%)보다 5.4% 낮다.

이러한 차이는 위 그림에 표시된 것처럼 생성된 이미지와 입력 텍스트 간의 정렬 불량으로 설명될 수 있다. 이는 특히 세분화된 클래스의 경우에 해당된다.
StableRep loss에 \(0.5 \times (\mathcal{L}_\textrm{i2t} + \mathcal{L}_\textrm{t2j})\)를 추가하여 StableRep에 언어 supervision을 추가할 수 있다. 여기서 \(\mathcal{L}_\textrm{i2t}\), \(\mathcal{L}_\textrm{t2i}\)는 image-to-text 및 text-to-image contrastive loss이다. Supervision을 추가하면 ImageNet linear probing의 경우 CC12M에서는 StableRep이 72.8%에서 74.4%로, RedCaps에서는 73.7%에서 75.4%로 향상된다. 이를 StableRep+라고 부른다.
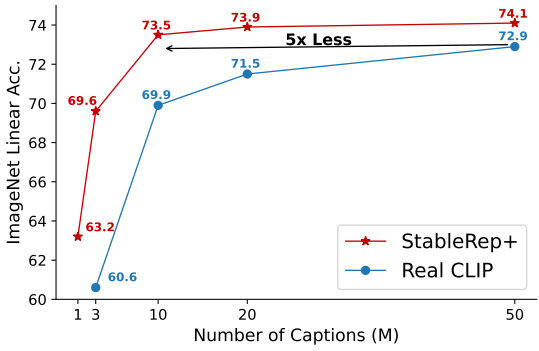
그런 다음 저자들은 StableRep+를 LAION-400M의 무작위로 선택된 50M 부분 집합으로 확장하였다. 이 실험에서는 $w = 2$인 캡션당 2개의 이미지만 생성하고 50M 데이터의 다양한 규모의 무작위 부분 집합을 사용하여 실제 이미지로 CLIP을 학습시키고 합성 이미지로 StableRep+를 학습시켰다. 결과는 위 그림과 같다. StableRep+는 CLIP보다 지속적으로 더 나은 정확도를 달성하였다. 특히 10M 캡션을 사용하는 StableRep+는 50M 캡션을 사용하는 CLIP보다 성능이 뛰어나 5배의 시간 캡션 효율성(2.5배 이미지 효율성)을 제공한다.
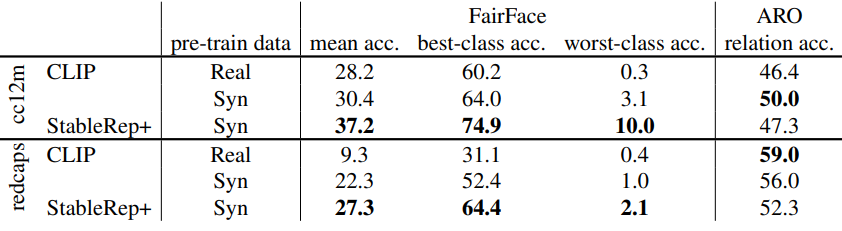
저자들은 추가로 FairFace완 ARO 벤치마크에서 학습된 모델의 공정성과 합성적 이해를 연구하였다. 결과는 아래 표와 같다.
Limitations
- 동일한 양의 실제 이미지와 비교하여 합성 이미지에 대한 self-supervised 방법이 효과적인 이유를 아직 이해하지 못했다.
- 현재 이미지 생성 프로세스는 xFormers가 활성화된 동안 A100 GPU에서 이미지당 약 0.8초, V100 GPU에서 이미지당 2.2초로 여전히 느리다.
- 입력 프롬프트와 생성된 이미지 간의 의미 불일치 문제를 해결하지 않았으며, 이는 합성 데이터의 품질과 유용성에 영향을 미칠 수 있다.
- 합성 데이터는 모드 붕괴로 인한 편향과 원형적인 이미지를 출력하는 경향을 악화시킬 가능성이 있다.
- 합성 데이터로 작업할 때 이미지 속성이 문제가 된다.