[논문리뷰] Splatt3R: Zero-shot Gaussian Splatting from Uncalibrated Image Pairs
arXiv 2024. [Paper] [Page] [Github]
Brandon Smart, Chuanxia Zheng, Iro Laina, Victor Adrian Prisacariu
University of Oxford
25 Aug 2024

Introduction
본 논문은 단 한 번의 forward pass로 sparse하고 calibration되지 않은 이미지로부터 3D 장면 재구성 및 novel view synthesis (NVS)를 달성하는 것을 목표로 한다. 기존 generalizable 3DGS 모델들은 픽셀 정렬된 3D Gaussian들을 사용하여 장면을 표현하였다. 이러한 Gaussian들의 3D 위치는 입력 이미지에서 알려진 intrinsic과 extrinsic 파라미터를 사용하여 계산된 광선을 따른 깊이를 사용하여 parameterize된다.
이러한 방법들은 알려진 카메라 파라미터에 의존하기 때문에 실제 환경에서 calibration되지 않은 이미지에 직접 사용할 수 없다. 실제 포즈는 사용 가능하다고 가정하거나, 카메라 포즈 추정은 전처리 단계로 간주된다. 기존 방법들은 일반적으로 동일한 장면의 수십 또는 수백 장의 이미지에 대해 SfM을 실행하여 포즈를 재구성한 데이터셋에서 테스트된다.
본 논문에서는 두 개의 calibration되지 않은 이미지를 입력으로 받아 장면을 표현하는 3D Gaussian을 출력하는 feed-forward 모델인 Splatt3R를 소개한다. 구체적으로, feed-forward 모델을 사용하여 각 이미지에 대해 픽셀 정렬된 3D Gaussian을 예측하고, 미분 가능한 렌더러를 사용하여 새로운 뷰를 렌더링한다. 카메라 intrinsic, extrinsic, 깊이 정보와 같은 추가 정보에 의존하지 않고 이를 구현하였다.
명시적인 포즈 정보가 없으면 3D Gaussian 중심을 어디에 배치할지 식별하는 것이 문제가 된다. 포즈 정보가 있더라도 반복적인 3DGS 최적화는 local minima에 취약하다. 저자들은 각 학습 샘플에 대해 GT 3D 포인트 클라우드를 명시적으로 예측하도록 하여 카메라 포즈 부족과 local minima 문제를 함께 해결하고자 하였다. 특히 MASt3R의 픽셀 정렬 3D 포인트 클라우드를 생성하는 데 사용된 아키텍처가 기존 픽셀 정렬된 3DGS 아키텍처와 밀접하게 일치하기 때문에, 사전 학습된 MASt3R 모델에 Gaussian 디코더를 추가하는 것만으로도 포즈가 없고 일반화 가능한 NVS 모델을 개발하기에 충분하다.
대부분의 기존 generalizable 3DGS 방법의 주목할 만한 한계 중 하나는 더 먼 시점으로 extrapolation하는 법을 학습하는 대신 입력 스테레오 뷰 사이에 있는 새로운 시점만 학습시킨다는 것이다. 이러한 extrapolation된 시점의 문제점은 입력 카메라 뷰에 가려지거나 완전히 frustum 외부에 있는 점을 보는 경우가 많다는 것이다. 따라서 이러한 점에 대한 새로운 뷰 렌더링 loss는 역효과를 낳고 모델의 성능을 저하시킬 수 있다.
본 논문은 두 컨텍스트 이미지 사이에 있는 뷰에 대한 새로운 뷰 렌더링 loss만 학습시킴으로써 장면의 보이지 않는 부분을 재구성하려는 시도를 피하였다. 그러나 이는 모델이 스테레오 baseline을 넘어서는 뷰에 대한 새로운 뷰 렌더링을 정확하게 생성하도록 학습되지 않았음을 의미한다. 이를 해결하기 위해 학습 중에 알려진 GT 포즈와 depth map을 사용하여 계산된 frustum culling 및 covisibility 테스트에 기반한 loss 마스킹 전략을 사용하였다. MSE loss와 LPIPS loss는 렌더링 중 재구성이 가능한 부분에만 적용되며, 이를 통해 장면의 보이지 않는 부분에서 모델이 업데이트되는 것을 방지한다. 이를 통해 더 넓은 baseline을 사용한 학습이 가능하고, 스테레오 baseline을 벗어난 새로운 뷰로 학습시킬 수 있다.
Method
1. Feed-forward 3D Gaussians
Generalizable 3DGS 방법들은 $N$개의 이미지 집합 $I = {\textbf{I}^i}_{i=1}^N$이 주어졌을 때 픽셀 정렬된 3D Gaussian들을 예측한다. 특히, 각 픽셀 $\textbf{u} = (u_x, u_y, 1)$에 대해, 불투명도 $\alpha$, 깊이 $d$, offset $\Delta$, rotation과 scale로 표현된 공분산 $\Sigma$, 색상 모델의 파라미터 $S$를 사용하여 parameterize된 Gaussian이 예측된다. 각 Gaussian의 위치는 intrinsic이 $K$일 때 \(\boldsymbol{\mu} = K^{-1} \textbf{u} d + \Delta\)로 주어진다. 그러나 이러한 parameterization은 calibration되지 않은 이미지의 3DGS 예측에 직접 적용할 수 없다. 대신, GT 포인트 클라우드를 사용하여 픽셀별 Gaussian들의 위치를 직접 학습시킨다. 이를 통해 각 픽셀에 해당하는 Gaussian은 학습 과정에서 정확한 위치로 이동할 수 있다.
2. Adapting MASt3R for Novel View Synthesis
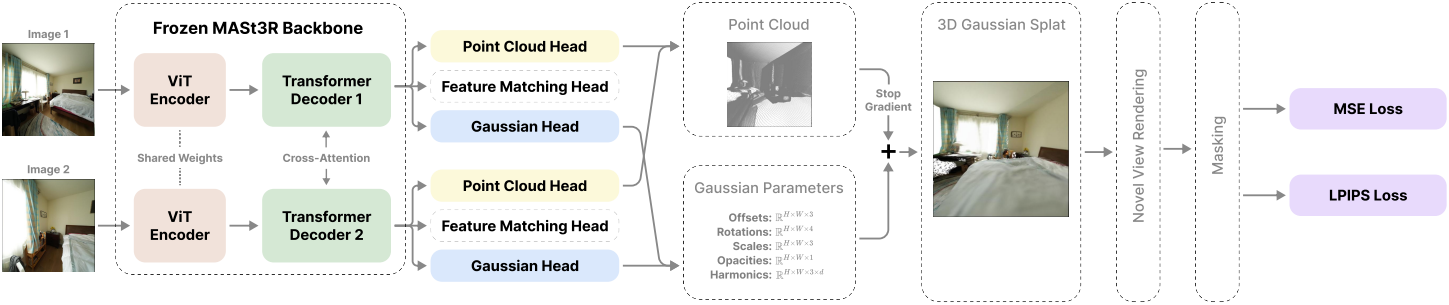
본 논문은 calibration되지 않은 이미지 쌍으로부터 3D Gaussian을 예측하는 feed-forward 모델인 Splatt3R을 제시하였다. 본 연구의 핵심 동기는 MASt3R와 generalizable 3DGS 모델 간의 개념적 유사성에서 비롯된다.
- 모두 feed-forward cross-attention 네트워크 아키텍처를 사용하여 입력 뷰 간의 정보를 추출한다.
- MASt3R는 각 이미지에 대해 픽셀 정렬된 3D pointmap과 신뢰도를 예측하는 반면, generalizable 3DGS 모델은 각 이미지에 대해 픽셀 정렬된 3D Gaussian을 예측한다.
따라서 본 논문에서는 MASt3R의 기본 원리를 따르며, 잘 선택된 학습 loss와 함께 아키텍처의 간단한 수정만으로도 새로운 뷰 합성 결과를 얻을 수 있다.
Calibration되지 않은 이미지 집합 $\mathcal{I}$가 주어지면 MASt3R는 ViT 인코더를 사용하여 각 이미지를 동시에 인코딩한 다음, 각 이미지 간에 cross-attention을 수행하는 transformer 디코더로 전달한다. 일반적으로 MASt3R에는 두 개의 예측 head가 있다. 하나는 각 픽셀에 대한 3D pointmap과 신뢰도를 예측하고, 나머지는 feature matching에 사용된다.
기존의 두 head와 병렬로 실행되는 Gaussian head라고 하는 세 번째 head를 도입한다. 이 head는 각 포인트에 대한 공분산(rotation quaternion $q \in \mathbb{R}^4$와 scale $s \in \mathbb{R}^3$로 계산), SH $S \in \mathbb{R}^{3 \times d}$, 불투명도 $\alpha \in \mathbb{R}$를 예측한다. 또한, 각 포인트에 대한 offset $\Delta \in \mathbb{R}^3$을 예측하여 Gaussian의 중심을 $\mu = x + \Delta$로 계산한다. 이를 통해 각 픽셀에 대한 완전한 Gaussian을 구성하고, 이를 렌더링하여 새로운 뷰를 합성할 수 있다.
학습 과정에서는 Gaussian 예측 head만 학습시키고, 나머지 파라미터는 사전 학습된 MASt3R 모델을 사용한다. MASt3R의 pointmap 예측 head를 따라 Gaussian head에는 DPT 아키텍처를 사용한다. 각 Gaussian 파라미터 유형에 대해 서로 다른 activation function을 사용하며, 구체적으로 quaternion에는 정규화, scale과 offset에는 exponential, 불투명도에는 sigmoid를 사용한다. 또한, 고주파 색상 학습을 돕기 위해 각 픽셀의 색상과 해당 픽셀의 Gaussian에 적용한 색상 사이의 residual를 예측한다.
MAST3R에서 첫 번째 이미지의 카메라 프레임에 있는 모든 점의 3D 위치를 예측하는 방식을 따르면, 예측된 공분산과 SH는 첫 번째 이미지의 카메라 프레임에 있는 것으로 간주된다. 이렇게 하면 기존 방식처럼 레퍼런스 프레임 간에 이러한 파라미터를 변환하기 위해 GT 변환을 사용할 필요가 없다. 최종 Gaussian 집합은 두 이미지에서 예측된 Gaussian의 합집합이다.
3. Training Procedure and Loss Calculation
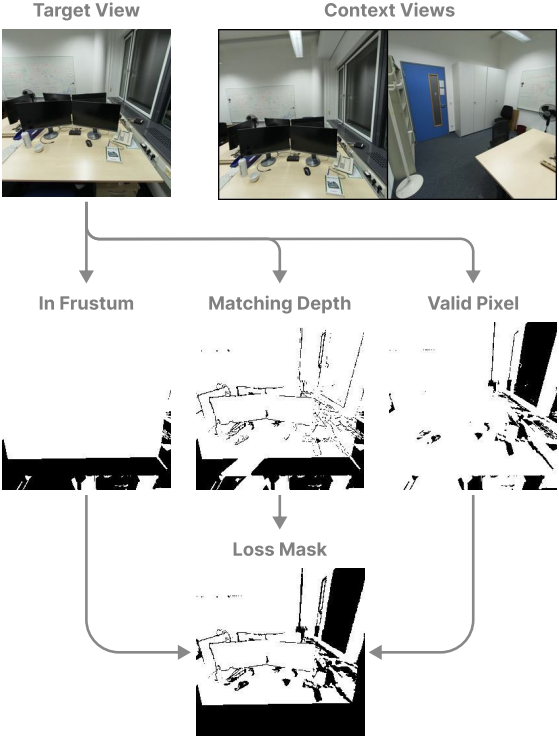
Gaussian 파라미터 예측을 최적화하기 위해 예측된 장면의 새로운 뷰를 렌더링한다. 학습 과정에서 각 샘플은 장면을 재구성하는 데 사용하는 두 개의 입력 ‘컨텍스트’ 이미지와 렌더링 loss를 계산하는 데 사용하는 여러 개의 ‘타겟’ 이미지로 구성된다.
이러한 타겟 이미지 중 일부는 가려져 두 컨텍스트 뷰에서 보이지 않거나 컨텍스트 view frustum에서 완전히 벗어나 있는 장면 영역을 포함할 수 있다. 이러한 픽셀에 렌더링 loss를 적용하는 것은 역효과를 낳을 수 있으며, 모델 성능에 악영향을 미칠 수 있다. 저자들은 두 입력 이미지 사이의 interpolation이 아닌 더 먼 시점까지 extrapolation하도록 학습시키고자 하였다.
저자들은 이를 해결하기 위해 loss 마스킹 전략을 도입하였다. 각 타겟 이미지에 대해 적어도 하나의 컨텍스트 이미지에서 어떤 픽셀이 보이는지 계산한다. 타겟 이미지의 각 포인트를 각 컨텍스트 이미지에 reprojection하고, 렌더링된 깊이가 실제 깊이와 일치하는지 확인한다.
기존의 generalizable 3DGS와 마찬가지로, MSE loss와 perceptual loss의 가중 합을 사용하여 학습시킨다. 마스킹된 재구성 loss는 다음과 같다.
\[\begin{equation} L = \lambda_\textrm{MSE} L_\textrm{MSE} (M \odot \hat{\textbf{I}}, M \odot \textbf{I}) + \lambda_\textrm{LPIPS} L_\textrm{LPIPS} (M \odot \hat{\textbf{I}}, M \odot \textbf{I}) \end{equation}\]($\hat{\textbf{I}}$는 렌더링된 이미지, $\textbf{I}$는 GT 이미지, $M$은 loss 마스크)
기존 방법들은 학습 과정에서 각 장면의 이미지가 동영상 시퀀스에 있다고 가정한다. 이러한 방법들은 선택된 컨텍스트 이미지들 사이의 프레임 수로 이미지들 사이의 거리와 중첩을 판단하고, 타겟 프레임으로 중간 프레임을 선택한다. 본 논문에서는 이러한 접근 방식을 선형 시퀀스 형태가 아닌 데이터셋에 적용하고, 컨텍스트 이미지들 사이에 있지 않은 시점에 대한 학습을 허용하도록 일반화하고자 하였다.
전처리 과정에서는 학습 세트의 각 장면에 대해 각 이미지 쌍의 중첩 마스크를 계산한다. 학습 과정에서는 두 번째 이미지의 픽셀 중 최소 $\phi$%가 첫 번째 이미지와 직접적으로 대응되도록 컨텍스트 이미지를 선택하고, 두 번째 이미지 중 적어도 하나에 픽셀의 최소 $\psi$%가 존재하도록 타겟 이미지를 선택한다.
Experiments
- 데이터셋: ScanNet++
- 구현 디테일
- \(\lambda_\textrm{MSE} = 1.0\), \(\lambda_\textrm{LPIPS} = 0.25\)
- $\phi = \psi = 0.3$
- 해상도: 512$\times$512
- epoch: 2,000 (약 50만 iteration)
- optimizer: Adam
- learning rate: $1 \times 10^{-5}$
- weight decay: 0.05
- gradient clip: 0.5
1. Results
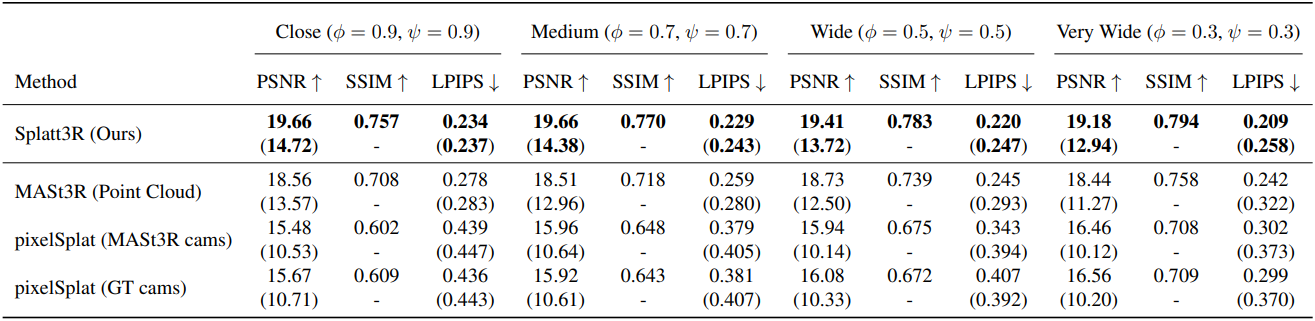
다음은 SOTA 방법들과의 비교 결과이다.

다음은 in-the-wild 예제들에 대한 일반화 예시들이다.

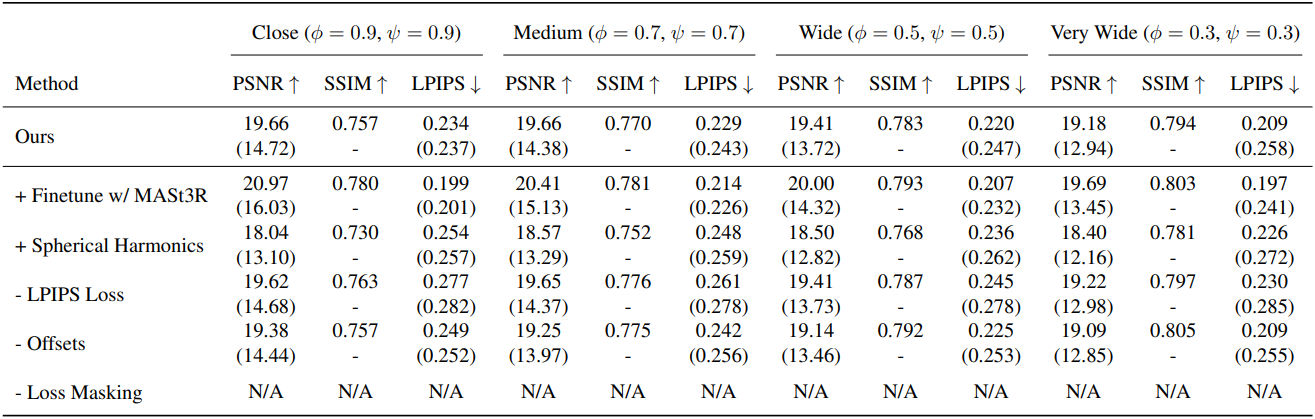
2. Ablation studies
다음은 ScanNet++에서의 ablation 결과이다.