[논문리뷰] Fast Inference from Transformers via Speculative Decoding
ICML 2023 (Oral). [Paper]
Yaniv Leviathan, Matan Kalman, Yossi Matias
Google Research
30 Nov 2022

Introduction
본 논문의 목표는 LLM의 inference 속도를 빠르게 만드는 것이다. 일부 inference step은 큰 모델만 잘 할 수 있는 반면, 일부는 작은 모델도 잘 할 수 있다는 것이 핵심 아이디어이다. 또한 대규모 모델의 inference는 산술 연산보다는 메모리 대역폭과 통신에서 주로 병목 현상이 발생하므로 추가적인 컴퓨팅 자원을 활용할 수 있다. 따라서 본 논문은 적응형 컴퓨팅 사용에 대한 보완적인 접근 방식으로 동시성을 높이는 것을 제안하였다. 구체적으로, speculative execution을 통해 모델 아키텍처, 학습 절차, 모델 재학습, 모델 출력 분포를 변경하지 않고도 inference 속도를 향상시킬 수 있다.
Speculative execution은 프로세서에서 흔히 사용되는 최적화 기법으로, 실제로 필요한지 여부를 검증하는 작업을 병렬로 수행하여 동시성을 향상시키는 방식이다. 본 논문에서는 speculative execution을 확률적 환경으로 일반화하여, 특정 작업이 특정 확률로 필요할 수 있는 상황을 제시하였다. 이를 Transformer와 같은 autoregressive 모델의 디코딩에 적용하였으며, 더 효율적인 근사 모델의 생성을 샘플링하여 속도가 느린 타겟 모델로 검증 및 보정한다. 결과적으로 speculative decoding의 출력이 타겟 모델 단독의 출력과 동일한 분포를 갖도록 보장한다.
Speculative decoding은 실제 운영 환경에서 쉽게 적용할 수 있으며, 새로운 모델을 학습할 필요가 없고, 출력에도 영향을 주지 않는다. 따라서 메모리 대역폭이 병목 현상이고 컴퓨팅 리소스는 충분한 상황에서 Transformer와 같은 autoregressive 모델의 샘플링을 가속화하는 데 있어 좋은 기본 선택이 될 수 있다.
Method

Inference 속도를 높이려는 타겟 모델 $M_p$에서 얻은 분포를 \(p(x_t \vert x_{<t})\), 동일한 task에 대해 $M_p$보다 효율적인 근사 모델 $M_q$에서 얻은 분포를 \(q(x_t \vert x_{<t})\)라 하자. 핵심 아이디어는 다음과 같다.
- 근사 모델 $M_q$를 사용하여 $\gamma \in \mathbb{Z}^{+}$개의 토큰을 autoregressive하게 생성한다.
- 타겟 모델 $M_p$를 사용하여 $M_q$에서 얻은 모든 추측과 해당 확률 $p(x)$을 병렬로 평가한다.
- $q(x) \le p(x)$이면 해당 추측을 유지하고, $q(x) > p(x)$이면 $1 − \frac{p(x)}{q(x)}$의 확률로 해당 추측을 거부한다.
- 거부된 첫 번째 토큰에 대해 조정된 분포 $p^\prime (x) = \textrm{norm}(\max(0, p(x) − q(x)))$에서 추가 토큰을 샘플링하거나, 모든 토큰이 수용된 경우 추가 토큰을 추가한다.
이렇게 하면 $M_p$의 각 병렬 실행은 적어도 하나의 새로운 토큰을 생성한다. 따라서 타겟 모델의 실행 횟수는 최악의 경우에도 단순 autoregressive 방법보다 클 수 없다. 하지만 $M_q$가 $M_p$를 얼마나 잘 근사하는지에 따라 최대 $\gamma + 1$까지 많은 새로운 토큰을 생성할 수 있다. 또한 임의의 분포 $p(x)$와 $q(x)$, 그리고 이와 같이 샘플링된 $x$에 대해 $x \sim p(x)$임을 보일 수 있다.
전체 알고리즘은 다음과 같다.

Analysis
1. Correctness of Speculative Sampling
샘플을 유지할 확률, 즉 acceptance rate를 $\beta$라 하자. 그러면 다음 식이 성립한다.
\[\begin{equation} \beta = E_{x \sim q(x)} \begin{cases} 1 & q(x) \le p(x) \\ \frac{p(x)}{q(x)} & q(x) > p(x) \end{cases} = \mathbb{E}_{x \sim q(x)} \min (1, \frac{p(x)}{q(x)}) = \sum_x \min (p(x), q(x)) \end{equation}\]조정된 분포 $p^\prime (x)$에 대한 식은 다음과 같이 정리된다.
\[\begin{aligned} p^\prime (x) &= \textrm{norm} (\max (0, p(x) - q(x))) = \textrm{norm}(p(x) - \min (q(x), p(x)))\\ &= \frac{p(x) - \min (q(x), p(x))}{\sum_{x^\prime} (p(x^\prime) - \min (q(x^\prime), p(x^\prime)))} = \frac{p(x) - \min (q(x), p(x))}{1 - \beta} \end{aligned}\]이를 이용하면 $P(x = x^\prime) = p(x^\prime)$임을 보일 수 있다.
\[\begin{aligned} P(x = x^\prime) &= P(\textrm{guess accepted}, x = x^\prime) + P(\textrm{guess rejected}, x = x^\prime) \\ &= q(x^\prime) \min (1, \frac{p(x^\prime)}{q(x^\prime)}) + (1 - \beta) p^\prime (x^\prime) \\ &= \min (q(x^\prime), p(x^\prime)) + p(x^\prime) - \min (q(x^\prime), p(x^\prime)) \\ &= p(x^\prime) \end{aligned}\]2. Number of Generated Tokens
모든 $\beta$들이 독립적이고 동일하게 분포되어 있다는 가정을 하고, $\alpha = E(\beta)$라 하자. 그러면, 평균 생성된 토큰의 수는 다음과 같다.
\[\begin{equation} E(\textrm{# generated tokens}) = 1 + \alpha + \alpha^2 + \ldots + \alpha^\gamma = \frac{1 - \alpha^{\gamma+1}}{1 - \alpha} \end{equation}\]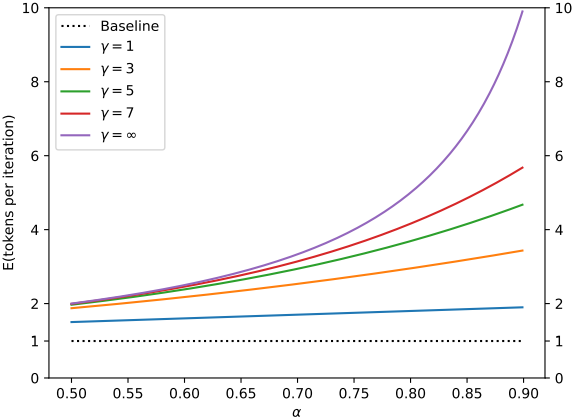
3. Walltime Improvement
Cost coefficient $c$를 $M_q$ 한 번 실행에 걸리는 시간과 $M_p$ 한 번 실행에 걸리는 시간의 비율이라고 하자. Algorithm 1을 한 번 실행하는데, 즉 평균 $\frac{1 - \alpha^{\gamma+1}}{1 - \alpha}$개의 토큰을 생성하는데 $M_p$ 한 번 실행에 걸리는 시간의 $(\gamma c + 1)$배의 시간이 소요된다. 따라서 전체 실행 시간은 $M_p$ 대비 $\frac{1 - \alpha^{\gamma+1}}{(1 - \alpha) (\gamma c + 1)}$배 향상된다.
$\gamma = 1$이면 이 값은 $\frac{1 - \alpha^2}{(1 - \alpha)(c+1)} = \frac{1 + \alpha}{1 + c}$이기 때문에, $\alpha > c$이면 실행 시간이 개선되는 $\gamma$가 항상 존재하며, 이 때 개선 비율은 적어도 $\frac{1 + \alpha}{1 + c}$이다.
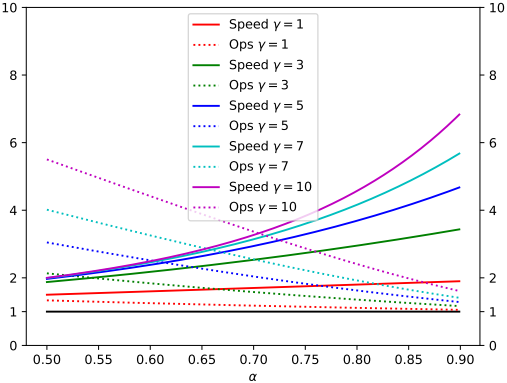
4. Number of Arithmetic Operations
$M_q$의 토큰당 산술 연산 횟수와 $M_p$의 토큰당 산술 연산 횟수의 비율을 $\hat{c}$라고 하자. Algorithm 1을 한 번 실행하는데 $M_p$의 토큰당 연산 횟수의 $(\gamma \hat{c} + \gamma + 1)$배의 연산이 수행된다. 따라서 전체 연산 횟수는 $M_p$ 대비 $\frac{(1 - \alpha)(\gamma \hat{c} + \gamma + 1)}{1 - \alpha^{\gamma + 1}}$배이다. $\alpha$ 값이 낮을수록, 즉 $M_q$의 성능이 좋지 않을수록 산술 연산 횟수 증가율이 높아진다.
산술 연산의 총 횟수와는 달리, speculative decoding을 사용하면 메모리 접근의 총 횟수가 줄어들 수 있다. 구체적으로, 타겟 모델의 가중치와 KV cache는 Algorithm 1의 실행당 한 번만 읽을 수 있으므로 이를 읽기 위한 메모리 접근 횟수는 \(\frac{1 - \alpha^{\gamma+1}}{1 - \alpha}\)만큼 줄어든다.
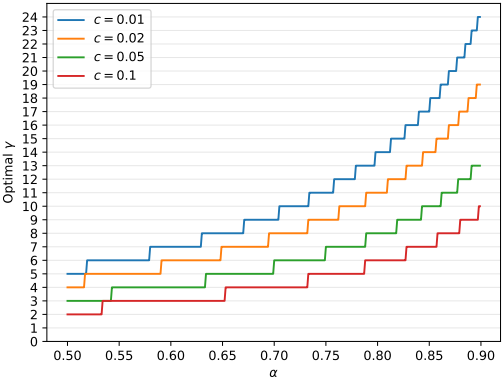
5. Choosing $\gamma$
$c$와 $\alpha$가 주어지고 컴퓨팅 자원이 충분하다고 가정할 때, 최적의 $\gamma$는 $\frac{1 - \alpha^{\gamma+1}}{(1 - \alpha) (\gamma c + 1)}$을 최대화하는 값이다. $\gamma$는 정수이므로 수치적으로 쉽게 구할 수 있다.
다음은 다양한 $c$와 $\alpha$에 대한 최적의 $\gamma$ 값을 나타낸 그래프이다.
다음은 $c = \hat{c} = 0$으로 가정했을 때, $\alpha$와 $\gamma$의 다양한 값에 대한 inference 속도와 총 산술 연산 횟수 사이의 trade-off를 보여준다.
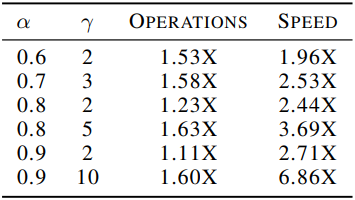
Experiments
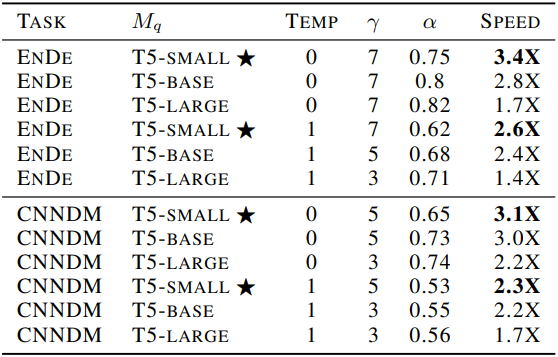
1. Empirical Walltime Improvement
다음은 T5-XXL 11B 모델에 대한 inference 속도를 비교한 표이다. (Temp는 샘플링 temperature)
2. Empirical $\alpha$ Values
다음은 다양한 $M_p$, $M_q$ 조합에 대한 최적의 $\alpha$ 값을 구한 결과이다. (Smpl은 샘플링 temperature)