[논문리뷰] SparseDiT: Token Sparsification for Efficient Diffusion Transformer
NeurIPS 2025. [Paper] [Github]
Shuning Chang, Pichao Wang, Jiasheng Tang, Fan Wang, Yi Yang
Zhejiang University | Alibaba Group | Hupan Lab
8 Dec 2024
Introduction
저자들은 DiT의 효율적인 토큰 관리를 위해 DiT의 layer와 샘플링 step 전반에 걸친 attention 분포를 분석하여 구조적 패턴을 밝히고자 했다. 토큰은 layer별로 서로 다른 수준의 세분성을 포착한다. Bottom layer에서는 attention map이 거의 균일하게 분포되어 있어, average pooling과 유사하게 광범위하고 글로벌한 feature에 초점을 맞추고 있다. 반면, middle layer에서는 attention이 교대로 나타나는데, 특정 layer는 로컬 디테일을 포착하는 반면, 다른 layer는 글로벌 구조를 강조한다.
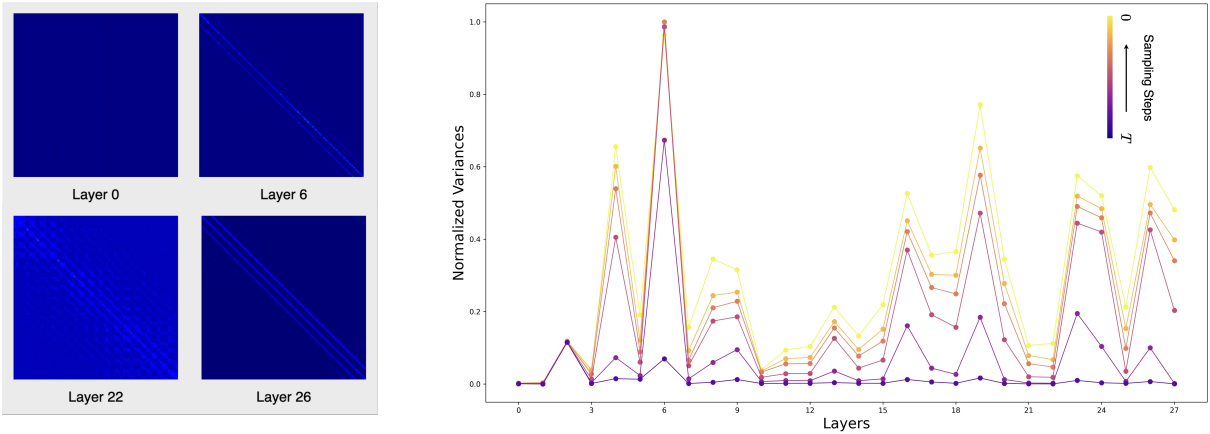
저자들은 샘플링 step에 따른 attention map 분석도 하였다. 교대 패턴은 안정적으로 유지되지만, denoising process가 진행됨에 따라 attention 분산이 증가하는 것을 관찰할 수 있는데, 이는 noise가 적은 step에서 로컬 정보에 대한 강조가 커짐을 나타낸다. 이 분석은 세 가지 핵심 통찰력을 제공한다.
- 초기 self-attention layer는 최소한의 분산을 나타내어 토큰 간 feature 추출의 불일치가 적다.
- DiT의 아키텍처는 layer 간에 글로벌 feature 초점과 로컬 feature 초점 사이를 본질적으로 번갈아 수행하며, 이 패턴은 모든 샘플링 step에서 일관적이다.
- Denoising이 진행됨에 따라 모델은 로컬 디테일을 점점 더 우선시하며, 후반 step에서 디테일에 대한 요구가 높아짐에 따라 동적으로 적응한다.
이러한 통찰력을 바탕으로, 저자들은 토큰 밀도 관리를 공간적 layer와 시간적 timestep 모두에 걸쳐 적응하는 동적 프로세스로 재해석한 SparseDiT를 제안하였다. 공간적으로, 얕은 layer는 부드럽고 글로벌한 feature를 포착하므로 복잡한 self-attention의 효율성이 떨어진다. 이후 layer들은 고주파의 로컬 디테일과 저주파의 글로벌 정보를 번갈아 처리하며, sprase token들은 글로벌 feature를 효율적으로 포착하고, dense token들은 로컬 디테일을 정교하게 다듬는다. 시간적으로, denoising이 진행됨에 따라 로컬 디테일에 대한 필요성이 증가하므로 동적인 토큰 조정 전략이 필요하다. 이 이중 layer 적응은 각 샘플링 step 내에서 효율성과 디테일의 균형을 맞추는 layer별 토큰 변조와 토큰 밀도를 동적으로 조정하는 timestep-wise pruning rate 전략을 통합한다. 이러한 공간적 및 시간적 적응을 통해 SparseDiT는 높은 수준의 디테일을 희생하지 않고도 계산 효율성을 달성할 수 있다.
SparseDiT의 아키텍처는 각 layer가 포착하는 feature에 맞춰 토큰 밀도를 조정하는 3단계 디자인을 채택하였다. Bottom layer에서는 self-attention을 poolingformer 구조로 대체하여 average pooling을 통해 광범위한 글로벌 feature를 포착하여 계산량을 줄이고 필수적인 구조를 보존한다. Middle layer에서는 Sparse-Dense Token Module (SDTM)을 도입하여 글로벌 구조를 위한 sparse token들과 로컬 디테일을 위한 dense token을 결합한다. Top layer에서는 모든 토큰을 dense하게 처리하여 고주파 디테일에 집중함으로써 더욱 정교한 출력 품질을 구현한다.
SparseDiT의 timestep-wise pruning rate 전략은 공간적 조정과 더불어 denoising step 전반에 걸쳐 토큰 밀도를 조절한다. 초기 step에서는 넓고 저주파 구조가 지배적이므로 SparseDiT는 높은 pruning 비을 적용하여 리소스를 절약한다. 프로세스가 진행됨에 따라 복잡한 디테일이 드러나면 pruning 비을 낮추어 토큰 밀도를 점진적으로 높인다. 이러한 조정은 각 step의 복잡성에 맞춰 계산 노력을 조절하고 효율성과 디테일의 균형을 동적으로 유지하여 고품질 출력을 위한 리소스를 최적화한다.
Method
1. SparseDiT
전체 아키텍처
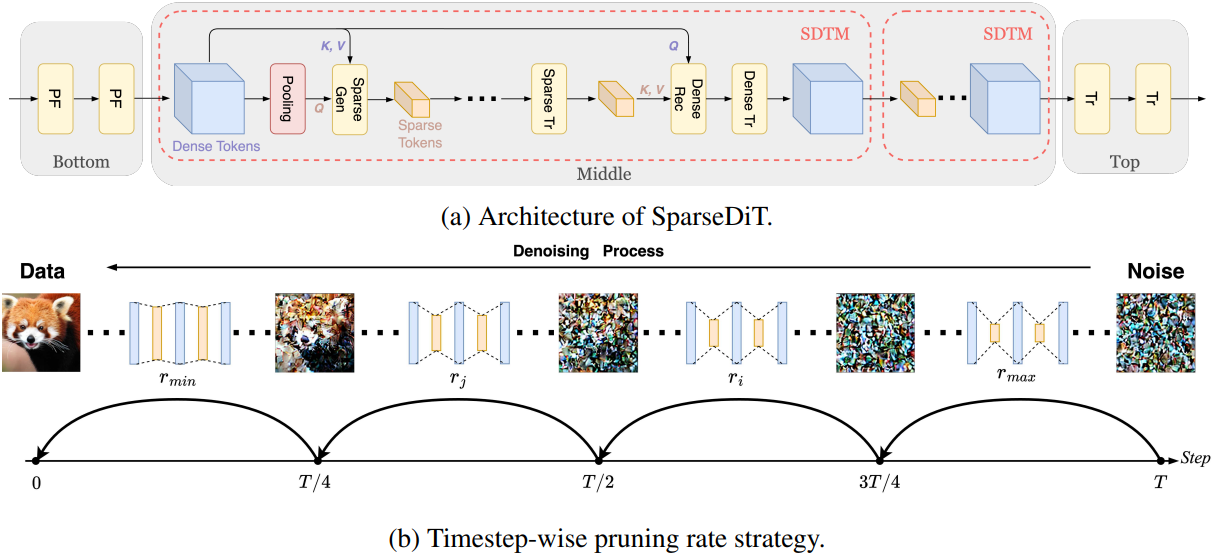
DiT 기반 모델의 transformer layer는 bottom, middle, top의 세 그룹으로 나뉜다. Bottom layer는 poolingformer를 활용하여 글로벌 feature를 효율적으로 포착한다. Middle layer는 여러 개의 sparse-dense token modules (SDTM)을 포함하며, sprase token과 dense token을 각각 사용하여 표현 과정을 글로벌 구조 포착과 로컬 디테일 강화로 분리한다. Top layer는 표준 transformer를 유지하며, 각 샘플링 step에서 최종 예측을 생성하기 위해 dense token을 처리한다. 주요 계산 효율성 향상은 sparse token을 통해 달성되므로 효율성을 극대화하기 위해 대부분의 transformer layer가 중간 부분에 위치한다.
Bottom layer에서의 Poolingformer
Bottom layer의 attention score는 거의 균일한 분포를 보이며, 각 토큰은 global average pooling처럼 글로벌 feature를 고르게 추출한다.

이를 더 자세히 조사하기 위해, 저자들은 fine-tuning 없이 첫 번째와 두 번째 transformer layer의 attention map을 상수 값으로 채워진 행렬로 대체하는 간단한 실험을 수행했다. 위 그림에서 볼 수 있듯이, 동일한 초기 noise와 랜덤 시드를 사용했을 때, 원래 DiT-XL과 수정된 DiT-XL에서 생성된 이미지가 거의 동일하다. 이는 복잡한 self-attention 계산이 제공하는 추가 정보가 제한적임을 시사한다. 저자들은 bottom layer에서 sparse token을 사용할 수 있는지에 대한 의문을 제기했지만, 실험 결과 bottom layer에 sparse token을 적용하면 학습이 불안정해졌다.
저자들은 위 분석을 바탕으로 기존 transformer를 poolingformer로 대체하였다. Poolingformer에서는 attention map을 계산하지 않으므로 query와 key를 제거한다. 대신, value $V \in \mathbb{R}^{N \times C}$에 대해 global average pooling을 수행하고 이를 입력 토큰 $X$에 통합한다.
\[\begin{equation} X = X + \bar{V} \end{equation}\]$\bar{V}$는 $N$ 차원을 따라 평균을 나타낸 $\bar{v} = \frac{1}{N} \sum V \in \mathbb{R}^{1 \times C}$를 $N$번 반복하여 $N \times C$로 만든 것이다 (식에서 adaLN block은 생략).
Sparse-dense token module
본 논문에서는 해당 transformer layer에서 처리되는 sparse token과 dense token을 생성하는 sparse-dense token module (SDTM)을 제시하였다. 핵심 아이디어는 글로벌 구조 추출과 로컬 디테일 추출을 분리하는 것이다. Sparse token은 글로벌 구조 정보를 포착하고 계산 비용을 줄이는 반면, dense token은 로컬 디테일을 강화하고 학습을 안정화한다. Sparse token과 dense token은 SDTM 내에서 서로 변환된다.
먼저 sparse token 집합 $X_s \in \mathbb{R}^{M \times C}$를 도입한다. 여기서 $M$은 sparse token의 개수이며, 일반적으로 $M \ll N$이다. 이러한 sparse token은 dense token X를 적응적으로 pooling하여 초기화할 수 있다. Sparsity 정도를 나타내기 위해 pruning rate $r = 1 − M/N$으로 정의한다. 구조 정보를 저장하기 위해 먼저 dense token $X \in \mathbb{R}^{N \times C}$를 latent shape으로 reshape한다. 예를 들어 입력이 이미지인 경우, 이를 $H \times W \times C$로 reshape한 다음 공간 차원에 걸쳐 pooling하여 $H^\prime \times W^\prime \times C$로 만든다. 여기서 $H^\prime \times W^\prime = M$이다.
공간적 pooling 초기화의 목적은 두 가지이다.
- 초기 sprase token을 공간에 균일하게 분포시킬 수 있고, 각 sparse token의 표현을 특정 공간적 위치와 연결할 수 있어 이미지 편집과 같은 후속 task에 유리하다.
- Semantic token이 후속 layer에서 한 점으로 수렴되는 것을 방지할 수 있다.
Sparse token은 attention layer를 통해 dense token과 상호 작용하여 글로벌 정보를 통합한다.
\[\begin{equation} X_s = X_s + \textrm{MHA}(X_s, X, X) \end{equation}\]($X_s$가 query, $X$가 key와 value)
생성된 sparse token은 sparse transformer라고 하는 후속 transformer layer에 입력된다. $M \ll N$이므로, SDTM은 계산 비용을 크게 줄일 수 있다.
이어서 sparse token으로부터 dense token을 복원한다. 먼저 sparse token $X_s \in \mathbb{R}^{M \times C}$를 $H^\prime \times W^\prime \times C$로 reshape하고, 이를 입력 dense token와 동일한 shape $H \times W \times C$로 업샘플링한다. Sparse token의 업샘플링과 dense token의 업샘플링을 결합하기 위해 두 개의 linear layer를 도입한다.
\[\begin{equation} X_\textrm{merged} = \textrm{UpSample}(X_s) \cdot W_1 + X \cdot W_2, \quad W_1, W_2 \in \mathbb{R}^{C \times C} \end{equation}\]($W_1$, $W_2$는 두 linear layer의 가중치)
다음으로, sparse token을 더욱 효과적으로 통합하기 위해 attention layer를 활용하여 sparse token 생성의 역연산을 수행함으로써 복원된 dense token을 생성한다.
\[\begin{equation} X = X_\textrm{merged} + \textrm{MHA}(X_\textrm{merged}, X_s, X_s) \end{equation}\]SDTM의 마지막 단계에서는 dense transformer라고 불리는 여러 transformer layer가 dense token을 처리하여 로컬 디테일을 강화한다.
본 논문에서는 네트워크에 여러 개의 SDTM을 계단식으로 구성했다. Sparse token과 dense token을 반복 처리함으로써 네트워크는 구조적 정보와 디테일을 효과적으로 보존하여 계산 비용을 크게 절감하면서도 고품질의 생성 결과를 유지한다.
2. Timestep-wise pruning rate
저자들은 토큰들이 샘플링 step에 따라 다양한 denoising 동작을 보인다는 것을 관찰했다. 토큰들은 초기 denoising step에서 저주파 글로벌 구조 정보를 생성하고, 나중 denoising step에서 고주파 디테일을 생성한다. 필요한 토큰 개수는 샘플링 step이 진행됨에 따라 점진적으로 증가한다. 이러한 특성을 활용하여 샘플링 step에 걸쳐 pruning rate $r$을 동적으로 조정하고, 샘플링이 진행됨에 따라 토큰 수를 증가시킨다.
$T$개의 샘플링 step이 주어졌을 때, 본 논문에서는 샘플링 step별로 sparse token의 수를 제어하기 위해 pruning rate $r$을 동적으로 조정하는 샘플별 접근 방식을 제안하였다. 먼저 $r$의 범위를 \(r \in [r_\textrm{min}, r_\textrm{max}]\)로 정의한다. 생성 품질이 나중 denoising step과 매우 밀접한 관련이 있음을 고려하여, 처음 $T/4$개의 샘플링 step 동안은 \(r = r_\textrm{min}\)로 고정한다. 이후에는 현재 샘플링 step $t_i$에 따라 pruning rate $r$을 선형적으로 조정한다.
\[\begin{equation} r = \begin{cases} r_\textrm{min}, & t_i < T/4, \\ \frac{4T-4}{3T} r_\textrm{min} + \frac{4-T}{3T} r_\textrm{max}, & T/4 \le t_i < T \end{cases} \end{equation}\]학습 과정에서 step $t_i$를 샘플링하고 위 식에 따라 해당 $r$을 계산한다. 그러나 batch로 학습하기 위해서는 입력 토큰이 모두 동일해야 하며, $T$에서 샘플링하는 과정의 랜덤성 또한 유지되어야 한다. 이러한 모순을 해결하기 위해, $T/4 \le t_i < T$인 경우 위 식의 선형 함수를 piecewise function으로 수정한다. 일반적으로 모델은 여러 개의 GPU를 사용하여 학습된다. 각 GPU에서 $t_i$를 특정 구간으로 샘플링하도록 요청한다. 따라서 각 iteration에서 균일한 랜덤 샘플링과 batch 학습을 동시에 달성할 수 있다.
3. Initialization and fine-tuning
본 방법은 효율성을 향상시키기 위해 사전 학습된 DiT 모델을 fine-tuning하였다. Sparse token 생성 및 dense token 복원 과정은 기존 transformer를 활용하므로 추가 네트워크가 필요하지 않다. fine-tuning 과정에서 DiT 기반 모델의 transformer 파라미터는 다음 두 가지 예외를 제외하고 본 방법의 SparseDiT의 transformer에 로드된다.
- Poolingformer에는 query와 key가 없으므로 사전 학습된 모델의 관련 파라미터가 필요하지 않다.
- 초기화 시에 \(X_\textrm{merged} = X\)가 되도록 가중치 $W_1$과 $W_2$는 각각 영행렬과 단위 행렬로 초기화된다.
Experiments
1. Class-conditional image generation
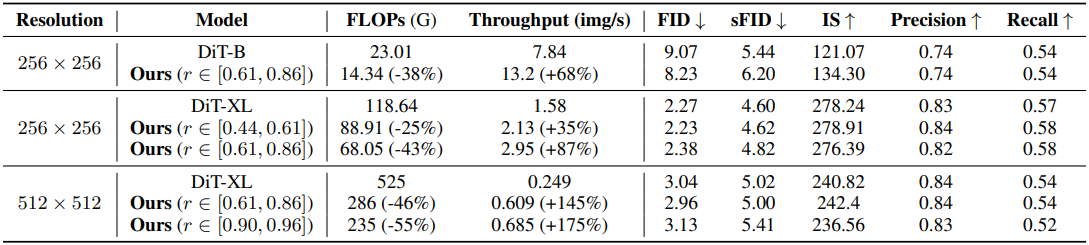
다음은 클래스 조건부 이미지 생성 결과이다.

2. Class-conditional video generation
다음은 클래스 조건부 동영상 생성 결과이다.

3. Text-to-image generation
다음은 text-to-image 생성 결과이다.


4. Ablation study
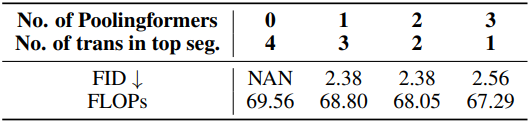
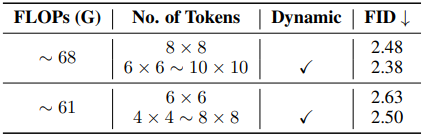
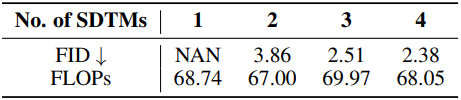
다음은 (왼쪽) SDTM 개수와 (오른쪽) sampler에 대한 ablation 결과이다.

다음은 (왼쪽) poolingformer 개수와 (오른쪽) timestep-wise pruning rate 전략에 대한 ablation 결과이다.