[논문리뷰] 3D Reconstruction with Spatial Memory
3DV 2025. [Paper] [Page] [Github]
Hengyi Wang, Lourdes Agapito
University College London
28 Aug 2024

Introduction
이미지에서 dense한 형상을 재구성하는 것은 컴퓨터 비전의 근본적인 문제 중 하나이다. 3D 구조를 해석하는 데 내재된 모호성으로 인해 기존 방법들은 다양한 휴리스틱을 사용하여 문제의 다양한 측면을 다루며, 이를 완전한 dense reconstruction 파이프라인에 통합하려면 상당한 노력이 필요하다.
최근 주목은 휴리스틱으로 만든 feature들을 대규모 데이터셋에서 학습된 구조적 prior로 대체하는 방향으로 옮겨갔다. 이러한 현대적인 접근 방식은 일반적으로 학습 기반 모델을 기존 파이프라인의 각 단계에 통합하였다. 따라서 매칭, triangulation, sparse reconstruction, 카메라 파라미터 추정, dense reconstruction을 포함하는 기존 파이프라인의 순차적 구조가 대부분 유지된다. 이러한 방법은 학습된 prior로 상당한 진전을 이루었지만 이 복잡한 파이프라인의 고유한 한계는 여전히 남아 있어 각 단계에서 노이즈에 민감하고 통합을 위해 여전히 상당한 노력이 필요하다.

이러한 문제를 해결하기 위해 DUSt3R는 새로운 패러다임 전환을 도입하였다. 즉, 포인트맵을 사전 장면 정보가 없는 한 쌍의 이미지에서 직접 회귀시켰다. 포인트맵은 이미지 쌍의 로컬 좌표계로 표현되므로 셋 이상의 이미지들을 재구성하기 위해 global alignment가 도입된다. 여기에는 예측된 포인트맵을 dense pairwise graph에 맞추기 위한 장면별 최적화가 포함된다. 깊이 및 카메라 파라미터에 대한 GT가 있는 수백만 개의 이미지 쌍에서 학습된 DUSt3R는 다양한 카메라 센서를 사용하는 다양한 실제 시나리오에서 전례 없는 성능과 일반화를 보여주었다. 그러나 한 쌍의 이미지에서 작동하고 장면별 최적화 기반 global alignment가 필요하기 때문에 많은 이미지에 대한 실시간 재구성 및 확장성에 대한 기능이 제한된다.
본 논문에서는 3D 재구성을 위해 공간 메모리를 채택한 프레임워크인 Spann3R을 제시하였다. DUSt3R의 패러다임을 기반으로, 장면별 최적화 기반 정렬의 필요성을 제거한다. 즉, Spann3R는 transformer 기반 아키텍처에서 간단한 forward pass로 공통 좌표계에서 각 이미지의 포인트맵을 예측하여 incremental reconstruction을 가능하게 한다. 핵심 아이디어는 이전 상태를 추적하고 이 메모리에서 다음 프레임을 예측하기 위해 모든 관련 정보를 쿼리하는 방법을 학습하는 외부 메모리를 유지하는 것이다. 이 개념은 종종 메모리 네트워크라고 한다.
이전 예측을 메모리 값으로 인코딩하기 위해 가벼운 transformer 기반 메모리 인코더를 사용한다. 이 메모리에서 정보를 검색하기 위해 두 개의 MLP head를 사용하여 두 개의 디코더에서 geometric feature를 query feature와 memory key로 projection한다. Spann3R는 동영상에서 무작위로 샘플링한 5개 프레임 시퀀스에서 학습되었으며, 학습 프로세스 전반에 걸쳐 샘플링하는 window size를 조정하는 curriculum training 전략을 사용하였다. 이를 통해 Spann3R은 프레임 전체에서 단기 및 장기 종속성을 모두 학습할 수 있다.
Inference하는 동안 XMem에서 영감을 받은 메모리 관리 전략을 적용하여 컴팩트한 메모리 표현을 유지한다. DUSt3R과 비교할 때, Spann3R는 신경망에만 기반하여 즉석에서 포인트를 정렬하여 test-time 최적화 없이 50 FPS 이상의 실시간 온라인 재구성을 가능하게 한다.
Method
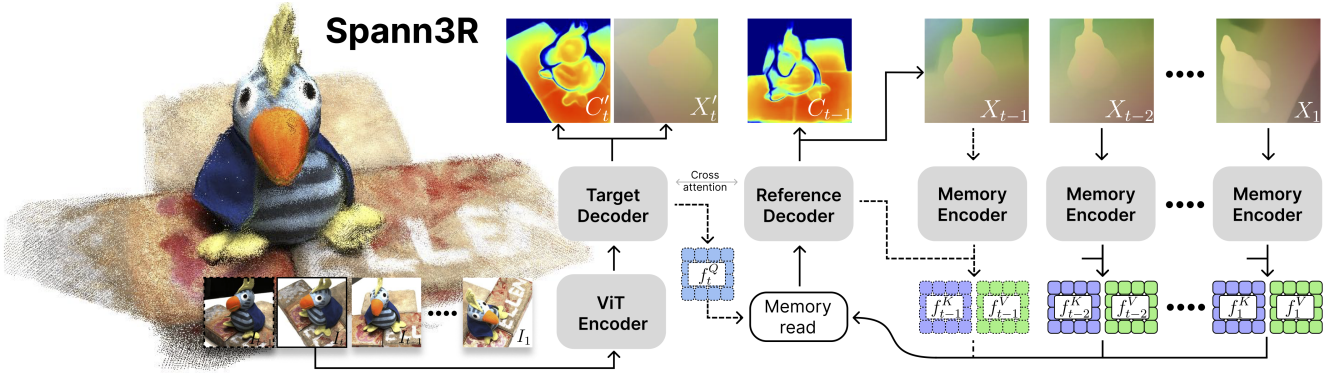
본 논문의 목표는 DUSt3R를 공통 좌표계에서 포인트맵을 직접 회귀시키는 end-to-end incremental reconstruction 프레임워크로 재활용하는 것이다. 구체적으로, 이미지 시퀀스 \(\{I_t\}_{t=1}^N\)이 주어졌을 때, 각 $I_t$를 초기 프레임의 좌표계로 표현된 포인트맵 $X_t$에 매핑하는 네트워크 $\mathcal{F}$를 학습시키는 것이다. 이를 가능하게 하기 위해, 다음 프레임을 추론하기 위해 이전 예측을 인코딩하는 공간 메모리를 도입하였다.
1. Network architecture
Feature 인코딩
각 forward pass에서 모델은 프레임 $I_t$와 이전 쿼리 $f_{t−1}^Q$를 입력으로 받는다. ViT는 프레임 $I_t$를 visual feature $f_t^I$로 인코딩하는 데 사용된다.
\[\begin{equation} f_t^I = \textrm{Encoder}^I (I_t) \end{equation}\]Query feature $f_{t−1}^Q$은 memory bank에서 feature를 검색하여 융합된 feature $f_{t-1}^G$를 출력하는 데 사용된다.
\[\begin{equation} f_{t-1}^G = \textrm{Memory_read}(f_{t-1}^Q, f^K, f^V) \end{equation}\]$f^K$는 memory key이고 $f^V$는 value feature이다.
Feature 디코딩
융합된 feature $f_{t−1}^G$와 visual feature $f_t^I$는 cross-attention을 통해 이를 공동으로 처리하는 두 개의 얽혀있는 디코더에 입력된다. 이를 통해 모델은 두 feature 간의 공간적 관계를 추론할 수 있다.
\[\begin{equation} f_t^{H^\prime}, f_{t-1}^H = \textrm{Decoder}(f_t^I, f_{t-1}^G) \end{equation}\]Target decoder에 의해 디코딩된 feature \(f_t^{H^\prime}\)는 다음 단계에 대한 query feature를 생성하기 위해 MLP head로 입력된다.
\[\begin{equation} f_t^Q = \textrm{head}_\textrm{query}^\textrm{target} (f_t^{H^\prime}, f_t^I) \end{equation}\]Reference decoder에 의해 디코딩된 feature $f_{t-1}^H$는 포인트맵 $X_{t-1}$과 신뢰도 $C_{t-1}$를 생성하기 위해 MLP head에 입력된다.
\[\begin{equation} X_{t-1}, C_{t-1} = \textrm{head}_\textrm{out}^\textrm{ref} (f_{t-1}^H) \end{equation}\]또한, supervision을 위해서 $f_t^{H^\prime}$로부터 포인트맵과 신뢰도를 생성한다.
메모리 인코딩
$f_{t-1}^H$와 $X_{t-1}$은 memory key $f_{t-1}^K$와 value feature $f_{t-1}^V$를 인코딩하는 데 사용된다.
\[\begin{aligned} f_{t-1}^K &= \textrm{head}_\textrm{key}^\textrm{ref} (f_{t-1}^H, f_{t-1}^I) \\ f_{t-1}^V &= \textrm{Encoder}^V (X_{t-1}) + f_{t-1}^K \end{aligned}\]Memory key와 value feature는 geometric feature와 visual feature 모두로부터 정보를 얻으므로 외형과 거리 모두를 기반으로 한 메모리 판독이 가능하다.
Discussion
DUSt3R와 비교했을 때, Spann3R는 가벼운 메모리 인코더 하나와 query, memory key, value feature를 인코딩하기 위한 두 개의 MLP head를 가지고 있다. 디코더의 경우, DUSt3R는 표준 좌표계에서 첫 번째 이미지를 재구성하는 reference decoder와 첫 번째 이미지의 좌표계에서 두 번째 이미지를 재구성하는 target decoder로 구성된다. 반면, Spann3R는 DUSt3R의 두 디코더를 다른 목적으로 사용한다. Target decoder는 주로 메모리를 쿼리하기 위한 feature를 생성하는 데 사용되는 반면, reference decoder는 재구성을 위해 메모리에서 융합된 feature를 가져온다. 초기화 측면에서, 두 개의 visual feature를 직접 사용한다.
2. Spatial memory
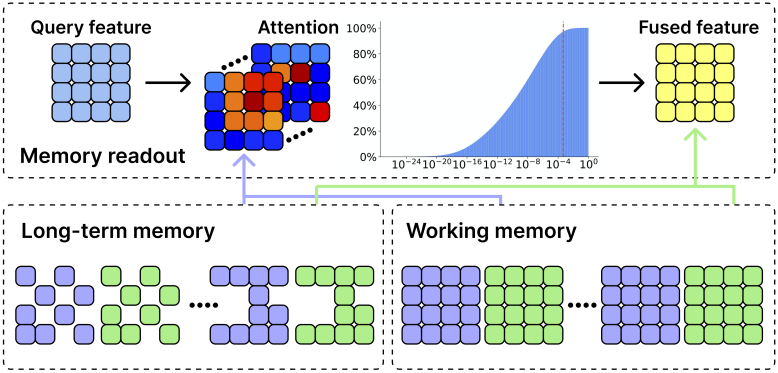
Memory query
공간 메모리는 모든 key feature $f^K \in \mathbb{R}^{Bs \times (T \cdot P) \cdot C}$와 value feature $f^V \in \mathbb{R}^{Bs \times (T \cdot P) \cdot C}$를 저장한다. 융합된 feature $f_{t−1}^G$을 계산하기 위해 query feature $f_{t−1}^Q \in \mathbb{R}^{Bs \times P \times C}$를 사용하여 cross-attention을 적용한다.
\[\begin{equation} f_{t-1}^G = A_{t-1} f^V + f_{t-1}^Q \end{equation}\]여기서 \(A_{t−1} \in \mathbb{R}^{Bs \times P \times (T \cdot P)}\)는 attention map이다.
\[\begin{equation} A_{t-1} = \textrm{Softmax} (\frac{f_{t-1}^Q (f^K)^\top}{\sqrt{C}}) \end{equation}\]이 attention map은 memory key의 모든 토큰과 관련하여 현재 query의 각 토큰에 대한 attention 가중치를 포함한다. 모델이 메모리 값의 일부로부터 형상을 추론하도록 장려하기 위해 학습 중에 0.15의 attention dropout을 적용한다.
실제로, 저자들은 inference에서 대부분의 attention 가중치가 비교적 작다는 것을 관찰하였다. 그러나 가중치가 작음에도 불구하고 해당 패치는 query 패치 또는 outlier와 상당히 떨어져 있을 수 있다. 결국, 메모리 값은 여전히 융합된 feature에 무시할 수 없는 영향을 미칠 수 있다. 이러한 outlier feature의 영향을 완화하기 위해 $5 \times 10^{−4}$의 hard clipping threshold를 적용하고 attention 가중치를 다시 정규화한다.
Working memory
Working memory는 가장 최근의 5개 프레임의 메모리 feature로 구성된다. 들어오는 각 메모리 feature에 대해 먼저 해당 key feature와 working memory의 각 key feature 사이의 유사도를 계산한다. 최대 유사도가 0.95 미만인 경우에만 새로운 key feature와 value feature를 working memory에 삽입한다. Working memory가 가득 차면 가장 오래된 memory feature가 long-term memory로 배출된다.
Long-term memory
Inference하는 동안 long-term memory feature는 시간이 지남에 따라 누적되어 GPU 메모리 사용량이 증가하고 속도가 느려질 수 있다. 저자들은 XMem에서 영감을 받아 long-term memory를 sparsify하는 유사한 전략을 설계하였다. 구체적으로 long-term memory key의 각 토큰에 대해 누적된 attention 가중치를 추적한다. Long-term memory가 미리 정의된 threshold에 도달하면 상위 $k$개의 토큰만 유지하여 메모리 sparsification을 수행한다.
3. Training and Inference
목적 함수
Dust3R를 따라 간단한 confidence-aware regression loss로 모델을 학습시킨다. 또한 예측된 포인트 클라우드의 평균 거리가 실제보다 작아지도록 장려하기 위해 scale loss를 포함한다. 전체 loss는 다음과 같다.
\[\begin{aligned} \mathcal{L} &= \mathcal{L}_\textrm{conf} + \mathcal{L}_\textrm{scale} \\ \mathcal{L}_\textrm{conf} &= \sum_t \sum_{i \in \mathcal{V}} C_t^i \mathcal{L}_\textrm{reg} (i) - \alpha \log C_t^i \\ \mathcal{L}_\textrm{scale} &= \max (0, \bar{X} - \bar{X}_\textrm{gt}) \end{aligned}\]($\mathcal{V}$는 모든 유효 픽셀, $\bar{X}$는 원점으로부터 모든 포인트의 평균 거리)
\(\mathcal{L}_\textrm{conf}\)를 계산하기 위해 예측된 포인트맵과 실제 포인트맵은 모두 평균 거리로 정규화된다.
Curriculum training
GPU 메모리 제약으로 인해 동영상 시퀀스당 5개의 프레임을 무작위로 샘플링하여 모델을 학습시킨다. 따라서 memory bank는 학습하는 동안 최대 4개의 프레임 메모리만 포함한다. 모델이 다양한 카메라 동작과 long-term feature matching에 적응하도록 하기 위해 학습하는 동안 샘플링하는 window size를 점진적으로 늘린다. 마지막 25% epoch에서는 학습 프레임 간격이 inference 프레임 간격과 일치하도록 window size를 점진적으로 줄인다.
Inference
모델은 자연스럽게 순차적 데이터, 즉 동영상 시퀀스에 적합하다. 순서 없는 이미지 컬렉션의 경우 DUSt3R에서와 같이 dense pairwise graph를 구축할 수 있다. 가장 높은 신뢰도를 가진 쌍이 초기화에 사용된다. 그런 다음 각 쌍의 신뢰도를 기반으로 minimum spanning tree를 구축하여 순서를 결정하거나 나머지 이미지를 모델에 직접 제공하여 예측 신뢰도를 기반으로 다음으로 좋은 이미지를 식별할 수 있다.
DUSt3R의 confidence map에는 지수 함수가 포함되어 있으며 이는 신뢰도가 높은 패치에 지나친 가중치를 부여하는 경향이 있다. 따라서 sigmoid 함수로 다시 매핑하여 재구성의 robustness를 개선할 수 있다.
Experiments
- 데이터셋: Habitat, MegaDepth, ARKitScenes, Static Scenes 3D, BlendedMVS, ScanNet++, Co3D-v2, Waymo
- 구현 디테일
- ViT-large 인코더, ViT-base 디코더, DPT head를 사용하는 Dust3R의 가중치로 모델을 초기화
- 메모리 인코더: 가벼운 ViT 사용 (self-attention block 6개, 임베딩 차원 1024)
- 학습 이미지 해상도: 224$\times$224
- epochs: 120
- optimizer: AdamW
- learning rate: $5 \times 10^{-5}$
- batch size: 16 (GPU당 2)
- 학습은 8개의 V100 GPU (32GB)에서 10일 소요
1. Evaluation
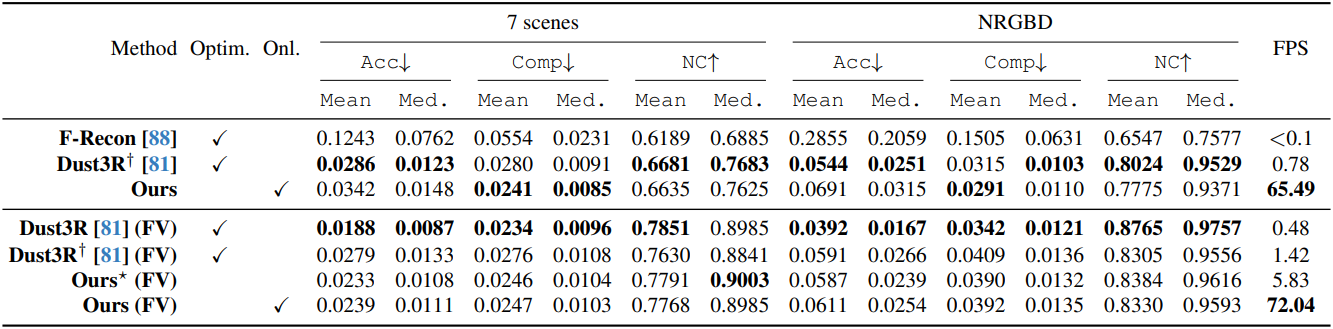
다음은 7Scenes와 NRGBD 데이터셋에서의 정량적 평가 결과이다. (DUSt3R†는 224$\times$224 이미지로 학습한 Dust3R, FV는 few-view)
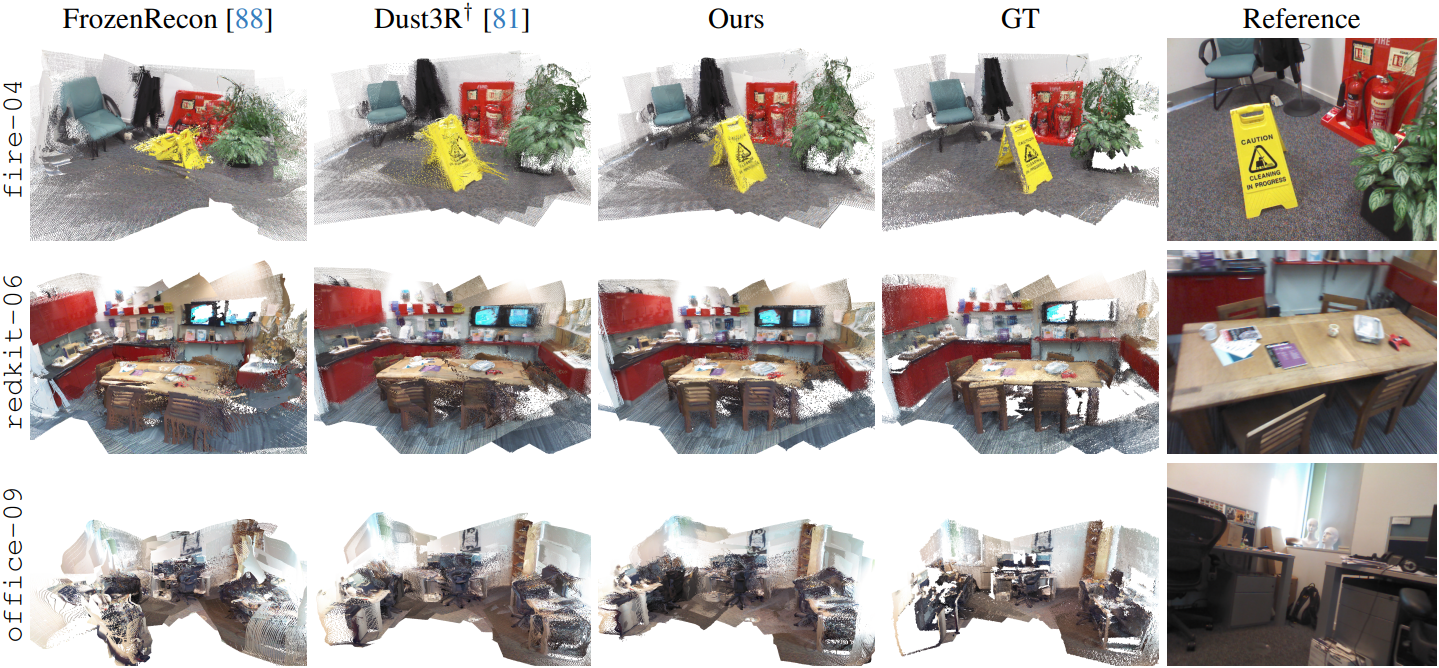
다음은 7Scenes에 대한 재구성 결과를 비교한 것이다.
다음은 DTU 데이터셋에서의 정량적 평가 결과이다.
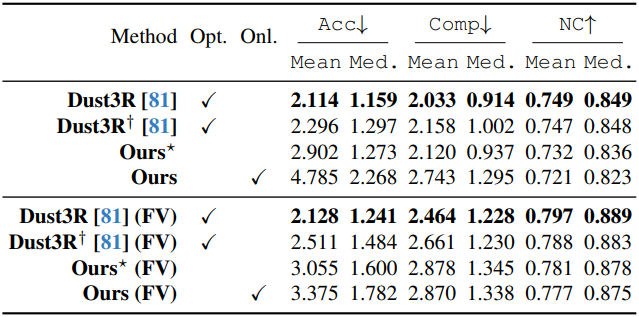
2. Analysis
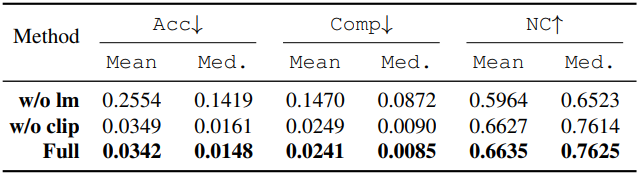
다음은 공간 메모리에 대한 ablation 결과이다.
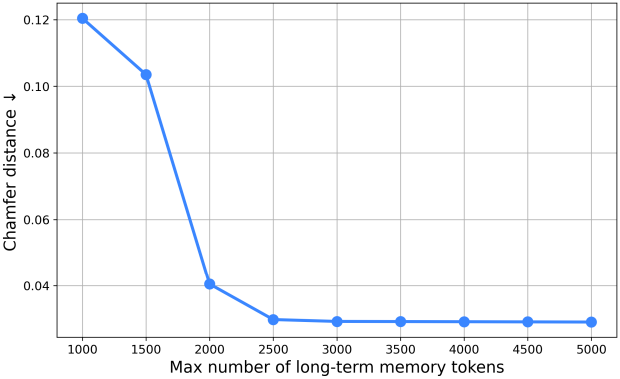
다음은 메모리 크기에 대한 ablation 결과이다.
다음은 온라인 재구성 결과를 시각화한 것이다.

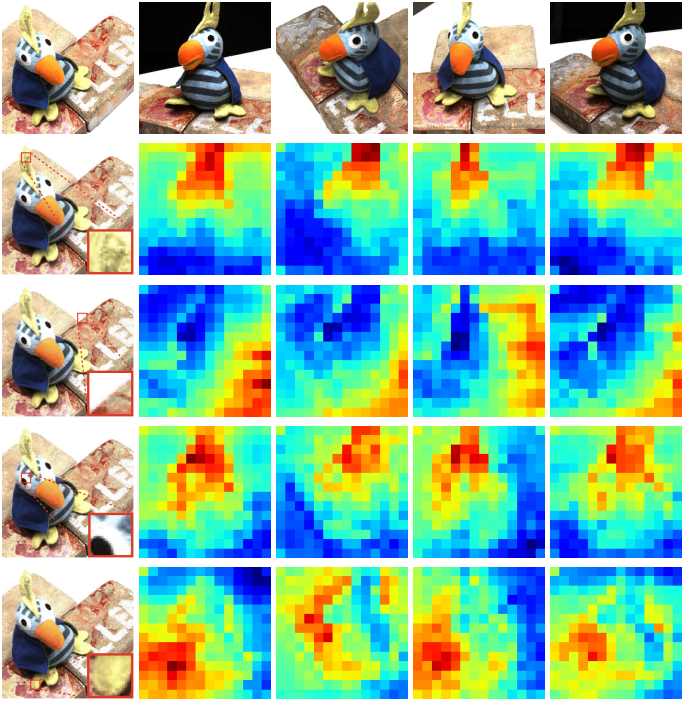
다음은 attention map을 시각화한 것이다.
다음은 다양한 현실 데이터셋에 대한 예시들이다. (데이터셋: Map-free Reloc, ETH3D, MipNeRF-360, NeRF, TUM-RGBD)
