[논문리뷰] SoundStream: An End-to-End Neural Audio Codec
arXiv 2021. [Paper]
Neil Zeghidour, Alejandro Luebs, Ahmed Omran, Jan Skoglund, Marco Tagliasacchi
Google Research
17 July 2021
Introduction
오디오 코덱은 크게 파형 코덱과 parametric 코덱의 두 가지 카테고리로 나눌 수 있다. 파형 코덱은 디코더 측에서 입력 오디오 샘플의 충실한 재구성을 생성하는 것을 목표로 한다. 대부분의 경우 이러한 코덱은 변환 코딩 기술에 의존한다. 변환은 시간 도메인의 입력 파형을 시간 주파수 도메인에 매핑하는 데 사용된다. 그런 다음 변환 계수가 quantize되고 엔트로피 코딩된다. 디코더 측에서 변환이 반전되어 시간 도메인 파형을 재구성한다. 종종 인코더에서의 비트 할당은 quantization 프로세스를 결정하는 perceptual model에 의해 구동된다. 일반적으로 파형 코덱은 오디오 콘텐츠 유형에 대해 거의 또는 전혀 가정하지 않으므로 일반 오디오에서 작동할 수 있다. 그 결과 중간에서 높은 비트레이트로 매우 높은 품질의 오디오를 생성하지만 낮은 비트레이트로 작동할 때 아티팩트가 발생하는 경향이 있다.
Parametric 코덱은 인코딩할 소스 오디오 (대부분의 경우 음성)에 대한 특정 가정을 만들고 오디오 합성 프로세스를 설명하는 parametric model의 형태로 강력한 prior를 도입하여 이 문제를 극복하는 것을 목표로 한다. 인코더는 모델의 파라미터를 추정한 다음 quantize한다. 디코더는 quantize된 파라미터로 구동되는 합성 모델을 사용하여 시간 도메인 파형을 생성한다. 파형 코덱과 달리 샘플별로 충실한 재구성을 얻는 것이 아니라 지각적으로 원본과 유사한 오디오를 생성하는 것이 목표이다.
기존의 파형 코덱과 parametric 코덱은 신호 처리 파이프라인과 신중하게 엔지니어링된 디자인 선택에 의존하며, 이는 코딩 효율성을 개선하기 위해 심리 음향과 음성 합성에 대한 도메인 내 지식을 활용한다. 최근에는 기계 학습 모델이 오디오 압축 분야에 성공적으로 적용되어 데이터 기반 솔루션이 제공하는 추가 가치를 보여주었다. 예를 들어 기존 코덱의 품질을 개선하기 위한 후처리 단계로 적용할 수 있다. 이는 오디오 super-resolution, 즉 주파수 대역폭 확장, 오디오 denoising, 즉 손실 아티팩트 제거 또는 패킷 손실 은닉을 통해 달성할 수 있다.
다른 솔루션은 ML 기반 모델을 오디오 코덱 아키텍처의 통합 부분으로 채택하는 것이다. 이러한 영역에서 최근 TTS 기술의 발전이 핵심 요소임이 입증되었다. 예를 들어 원래 텍스트에서 음성을 생성하는 데 적용된 강력한 생성 모델인 WaveNet은 뉴럴 코덱에서 디코더로 채택되었다. 다른 뉴럴 오디오 코덱은 LPCNet의 WaveRNN과 Lyra의 WaveGRU와 같은 다른 모델 아키텍처를 채택하며 모두 낮은 비트레이트에서 음성을 대상으로 한다.
본 논문에서는 음성, 음악 및 일반 오디오를 보다 효율적으로 압축할 수 있는 새로운 오디오 코덱인 SoundStream을 제안한다. SoundStream은 뉴럴 오디오 합성 분야에서 SOTA 솔루션을 활용하여, 새로운 학습 가능한 quantization 모듈을 도입하여 중저 비트레이트에서 작동하면서 높은 지각 품질로 오디오를 제공한다. Fully convolutional decoder는 시간 도메인 파형을 입력으로 받고 더 낮은 샘플링 속도로 임베딩 시퀀스를 생성하며, 이는 residual vector quantizer에 의해 quantize된다. Fully convolutional decoder는 quantize된 임베딩을 받고 원래 파형의 근사치를 재구성한다. 이 모델은 reconstruction loss와 adversarial loss를 모두 사용하여 end-to-end로 학습된다. 이를 위해 디코딩된 오디오를 원래 오디오와 구별하고 feature 기반 reconstruction loss를 계산할 수 있는 공간을 제공하는 것을 목표로 하나(또는 그 이상)의 discriminator가 공동으로 학습된다. 인코더와 디코더 모두 causal convolution만 사용하므로 모델의 전체 대기 시간은 원래 시간 도메인 파형과 임베딩 간의 시간적 리샘플링 비율에 의해서만 결정된다.
Model
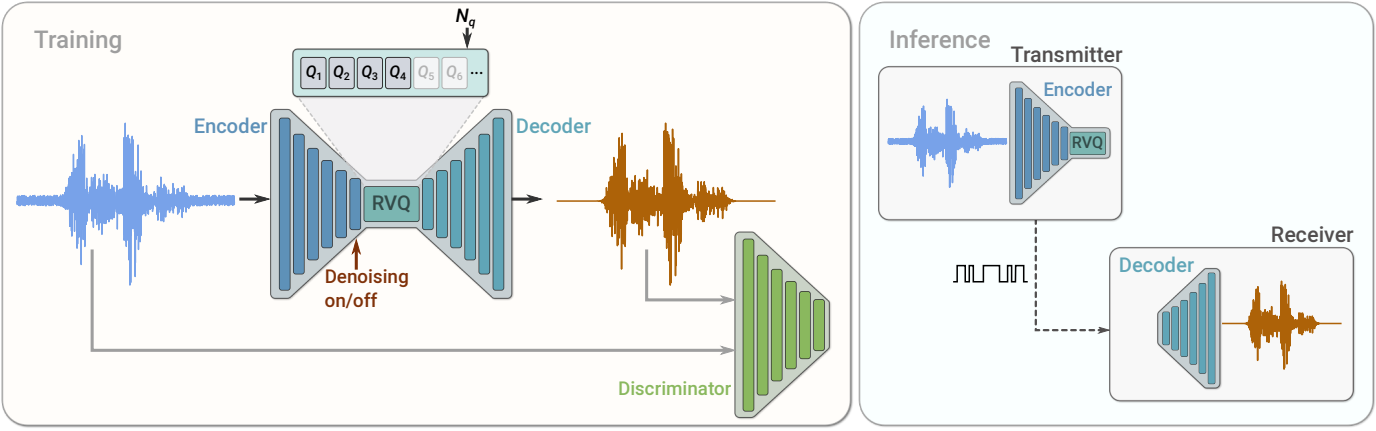
$f_s$에서 샘플링된 $x \in \mathbb{R}^T$를 기록하는 단일 채널을 고려한다. SoundStream 모델은 위 그림과 같이 일련의 세 가지 빌딩 블록으로 구성된다.
- $x$를 임베딩들의 시퀀스로 매핑하는 인코더
- 각 임베딩을 유한한 코드북 집합의 벡터 합으로 대체하여 타겟 비트 수로 표현을 압축하는 residual vector quantizer
- Quantize된 임베딩에서 손실 재구성 $\hat{x} \in \mathbb{R}^T$를 생성하는 디코더
이 모델은 adversarial loss와 reconstruction loss의 혼합을 사용하여 discriminator와 함께 end-to-end로 학습된다. 선택적으로 컨디셔닝 신호를 추가할 수 있으며, 이는 denoising이 인코더 측에 적용되는지 디코더 측에 적용되는지를 결정한다.
1. Encoder architecture
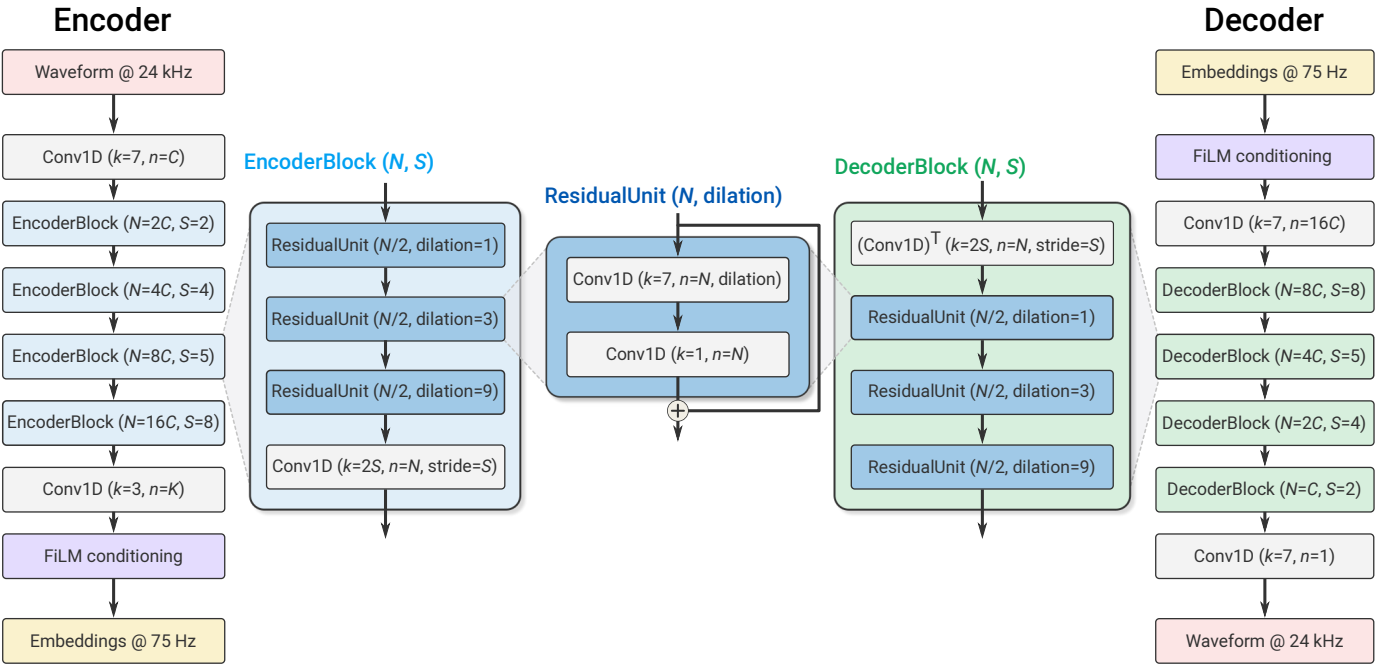
인코더 아키텍처는 위 그림에 나와 있으며 streaming SEANet 인코더와 동일한 구조를 따르지만 skip connection은 없다. 채널이 $C_\textrm{enc}$개인 1D convolution layer와 $B_\textrm{enc}$개의 convolution block으로 구성된다. 각각의 블록은 각각 1, 3, 9의 dilation rate의 dilated convolution을 포함하는 3개의 residual unit으로 구성되며, strided convolution 형태의 다운샘플링 레이어가 뒤따른다. 채널 수는 $C_\textrm{enc}$부터 시작하여 다운샘플링할 때마다 두 배가 된다. 커널 길이가 3이고 stride가 1인 최종 1D convolution layer는 임베딩의 차원을 $D$로 설정하는 데 사용된다. 실시간 inference를 보장하기 위해 모든 convolution은 causal이다. 즉, 패딩은 학습과 오프라인 inference 모두에서 과거에만 적용되고 미래에는 적용되지 않는 반면, streaming inference에서는 패딩이 사용되지 않는다. ELU activation을 사용하고 정규화를 적용하지 않는다. convolution block의 수 $B_\textrm{enc}$와 해당 striding 시퀀스는 입력 파형과 임베딩 사이의 시간적 리샘플링 비율을 결정한다. 예를 들어 $B_\textrm{enc} = 4$이고 (2, 4, 5, 8)을 stride로 사용하는 경우 $M = 2 \times 4 \times 5 \times 8 = 320$개의 입력 샘플마다 하나의 임베딩이 계산된다. 따라서 인코더는 $\textrm{enc}(x) \in \mathbb{R}^{S \times D}$를 출력한다 ($S = T / M$).
2. Decoder architecture
디코더 아키텍처는 인코더과 같이 유사한 디자인을 따른다. 1D convolution layer 다음에는 일련의 $B_\textrm{dec}$개의 convolution block이 온다. 디코더 블록은 인코더 블록을 미러링하고 동일한 3개의 residual unit이 뒤따르는 업샘플링을 위한 transposed convolution으로 구성된다. 인코더와 동일한 stride를 사용하지만 입력 파형과 동일한 해상도로 파형을 재구성하기 위해 역순으로 사용한다. 업샘플링할 때마다 채널 수가 절반으로 줄어들어 마지막 디코더 블록이 $C_\textrm{dec}$개의 채널을 출력한다. 필터가 하나이고 커널 크기가 7, stride가 1인 최종 1D convolution layer는 임베딩을 파형 도메인으로 다시 project하여 $\hat{x}$를 생성한다. 인코더와 디코더 모두에서 동일한 수의 채널이 동일한 파라미터에 의해 제어된다 (즉, $C_\textrm{enc} = C_\textrm{dec} = C$).
3. Residual Vector Quantizer
Quantizer의 목표는 인코더 $\textrm{enc}(x)$의 출력을 비트/초 (bps)로 표현되는 타겟 비트레이트 $R$로 압축하는 것이다. End-to-end 방식으로 SoundStream을 학습하려면 역전파를 통해 quantizer를 인코더와 디코더와 공동으로 학습시켜야 한다. VQ-VAE-2에서 제안된 vector quantizer (VQ)는 이 요구 사항을 충족한다. 이 VQ는 $\textrm{enc}(x)$의 각 $D$차원 프레임을 인코딩하기 위해 $N$개의 벡터의 코드북을 학습한다. 인코딩된 오디오 $\textrm{enc} (x) \in \mathbb{R}^{S \times D}$는 $S \log_2 N$개의 비트를 사용하여 표현할 수 있는 $S \times N$ 모양의 one-hot 벡터 시퀀스에 매핑된다.
Vector Quantization의 한계
구체적인 예로 비트레이트 $R$ = 6000bps를 대상으로 하는 코덱을 고려해 보자. Striding factor $M$ = 320을 사용하는 경우 샘플링 속도 $f_s$ = 24000Hz에서 오디오의 각 1초는 인코더 출력에서 $S$ = 75 프레임으로 표시된다. 이것은 각 프레임에 할당된 $r = 6000/75 = 80$ 비트에 해당한다. 일반 vector quantizer를 사용하면 $N = 2^80$개의 벡터로 코드북을 저장해야 하는데 이는 명백히 실현 불가능하다.
Residual Vector Quantizer

이 문제를 해결하기 위해 다음과 같이 VQ의 $N_q$개의 레이어를 캐스케이드하는 Residual Vector Quantizer를 채택한다. Quantize되지 않은 입력 벡터는 첫 번째 VQ를 통과하고 quantization residual이 계산된다. 그런 다음 residual은 Algorithm 1에 설명된 대로 일련의 추가 $N_q - 1$개의 VQ에 의해 반복적으로 qunatize된다. 총 비트는 각 VQ에 균일하게 할당된다. 즉, $r_i = r / N_q = \log_2 N$이다. 예를 들어 $N_q = 8$을 사용할 때, 각 quantizer는 크기 $N = 2*{r / N_q} = 2^{80/8} = 1024$의 코드북을 사용한다. 타겟 비트 $r$의 경우 파라미터 $N_q$는 계산 복잡도와 코딩 효율성 간의 균형을 제어한다.
각 quantizer의 코드북은 VQ-VAE-2에서 제안한 방법에 따라 exponential moving average (EMA) 업데이트로 학습된다. 코드북 사용을 개선하기 위해 두 가지 추가 방법을 사용한다. 첫째, 코드북 벡터에 대해 랜덤 초기화를 사용하는 대신 첫 번째 학습 배치에서 k-mean 알고리즘을 실행하고 학습된 중심을 초기화로 사용한다. 이렇게 하면 코드북이 입력 분포에 가까워지고 사용이 향상된다. 둘째, Jukebox에서 제안한 것처럼 코드북 벡터에 여러 배치에 대한 입력 프레임이 지정되지 않은 경우 현재 배치 내에서 임의로 샘플링된 입력 프레임으로 대체한다. 보다 정확하게는 각 벡터에 대한 EMA (decay factor = 0.99)를 추적하고 이 통계가 2 미만으로 떨어지는 벡터를 대체한다.
Enabling bitrate scalability with quantizer dropout
Residual vector quantization는 비트레이트를 제어하기 위한 편리한 프레임워크를 제공한다. 각 코드북의 고정 크기 $N$에 대해 VQ 레이어 수 $N_q$가 비트레이트를 결정한다. VQ는 인코더/디코더와 함께 학습되기 때문에 원칙적으로 각 타겟 비트레이트에 대해 다른 SoundStream 모델을 학습해야 한다. 대신 여러 타겟 비트레이트에서 작동할 수 있는 단일 비트레이트 확장 가능 모델을 갖는 것이 인코더와 디코더 측 모두에서 모델 파라미터를 저장하는 데 필요한 메모리 공간을 줄이기 때문에 훨씬 더 실용적이다.
이러한 모델을 학습하기 위해 Algorithm 1을 다음과 같은 방식으로 수정한다. 각 입력 예에 대해 $[1, N_q]$에서 무작위로 $n_q$를 균일하게 샘플링하고 $i = 1, \ldots, n_q$에 대해 quantizer $Q_i$만 사용한다. 이는 quantization 레이어에 적용된 구조화된 dropout의 형태로 볼 수 있다. 결과적으로 모델은 $n_q = 1, \ldots, N_q$ 범위에 해당하는 모든 타겟 비트레이트에 대해 오디오를 인코딩 및 디코딩하도록 학습된다. Inference 시 원하는 비트레이트에 따라 $n_q$ 값이 선택된다. Residual vector quantizer의 주요 장점은 임베딩의 차원이 비트레이트에 따라 변경되지 않는다는 것이다. 실제로, 각 VQ 레이어 출력을 더하는 것은 동일한 모양을 유지하면서 quantize된 임베딩을 점진적으로 개선한다. 따라서 서로 다른 비트레이트를 수용하기 위해 인코더나 디코더에서 아키텍처 변경이 필요하지 않다.
4. Discriminator architecture
Adversarial loss를 계산하기 위해 두 가지 다른 discriminator를 정의한다.
- 단일 파형을 입력으로 수신하는 파형 기반 discriminator
- 실수부와 허수부로 표현되는 입력 파형의 복소수 STFT를 입력으로 수신하는 STFT 기반 discriminator
두 discriminator가 fully convolutional이기 때문에 출력의 logit의 수는 입력 오디오의 길이에 비례한다.
파형 기반 discriminator의 경우 MelGAN에서 제안하고 채택한 것과 동일한 다중 해상도 convolution discriminator를 사용한다. 3개의 구조적으로 동일한 모델이 서로 다른 해상도에서 입력 오디오에 적용된다: 원본, 2배 다운샘플링, 4배 다운샘플링. 각 단일 스케일 discriminator는 초기 일반 convolution과 그 뒤에 4개의 grouped convolution으로 구성되며, 각 convolution은 그룹 크기 4, 다운샘플링 계수 4, 채널 multiplier 4, 최대 1024개의 출력 채널을 가진다. 그 다음에는 최종 출력, 즉 logit을 생성하기 위해 두 개의 일반 convolution layer가 더 뒤따른다.
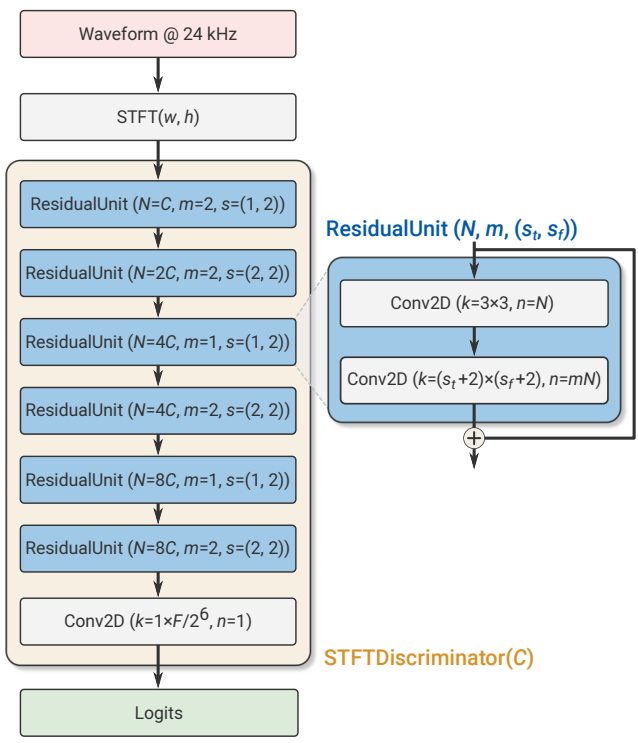
STFT 기반 discriminator는 위 그림에 나와 있으며 단일 스케일에서 작동하며 윈도우 길이 $W = 1024$ 샘플, hop 길이 $H = 256$ 샘플로 STFT를 계산한다. 2D convolution (커널 크기 7$\times$7, 32 채널) 다음에는 residual block 시퀀스가 온다. 각 블록은 3$\times$3 convolution으로 시작하여 3$\times$4 또는 4$\times$4 컨볼루션이 이어지며, 스트라이드는 (1, 2) 또는 (2, 2)와 같다. 여기서 $(s_t, s_f)$는 시간축과 주파수축의 다운샘플링 계수를 나타낸다. 총 6개의 residual block에 대해 (1, 2)와 (2, 2) stride를 번갈아 가며 진행한다. 채널 수는 네트워크 깊이에 따라 점진적으로 증가한다. 마지막 residual block의 출력에서 활성화는 $T / (H \cdot 2^3) \times F / 2^6$ 모양을 갖는다. 여기서 $T$는 시간 도메인의 샘플 수이고 $F = W/2$는 주파수 bin의 수이다. 마지막 레이어는 다운샘플링된 시간 도메인에서 1차원 신호를 얻기 위해 FC layer ($1 \times F/2^6 convolution으로 구현됨)를 사용하여 다운샘플링된 주파수 bin에서 logit을 집계한다.
5. Training objective
$\mathcal{G}(x) = \textrm{dec}(Q(\textrm{enc}(x)))$는 입력 파형 $x$를 인코더, quantizer, 디코더를 통해 처리하는 SoundStream generator를 나타내고 $\hat{x} = G(x)$는 디코딩된 파형이라고 하자. SoundStream을 loss들의 혼합으로 학습하여 perception-distortion trade-off에 따라 신호 재구성 충실도와 지각 품질을 모두 달성한다.
Adversarial loss는 지각 품질을 향상시키는 데 사용되며 discriminator의 logit에 대한 hinge loss로 정의되며 여러 discriminator와 시간에 따라 평균화된다. \(k ∈ \{0, \ldots, K\}\)를 각 discriminator에 대한 인덱스라 하자. 여기서 $k = 0$은 STFT 기반 discriminator를 나타내고 \(k \in \{1, \ldots, K\}\)는 서로 다른 해상도의 파형 기반 discriminator이다 (본 논문의 경우 $K = 3$). $T_k$를 시간 차원을 따라 $k$번째 discriminator의 출력에서의 logit의 수라 하자. Discriminator는 다음을 최소화하여 원본과 디코딩된 오디오를 분류하도록 학습된다.
\[\begin{equation} \mathcal{L}_\mathcal{D} = \mathbb{E}_x \bigg[ \frac{1}{K} \sum_k \frac{1}{T_k} \sum_t \max (0, 1 - \mathcal{D}_{k,t} (x)) \bigg] + \mathbb{E}_x \bigg[ \frac{1}{K} \sum_k \frac{1}{T_k} \sum_t \max (0, 1 + \mathcal{D}_{k,t} (\mathcal{G}(x))) \bigg] \end{equation}\]Generator의 adversarial loss는 다음과 같다.
\[\begin{equation} \mathcal{L}_\mathcal{G}^\textrm{adv} = \mathbb{E}_x \bigg[ \frac{1}{K} \sum_{k,t} \frac{1}{T_k} \max (0, 1 - \mathcal{D}_{k,t} (\mathcal{G} (x))) \bigg] \end{equation}\]원본 $x$에 대한 디코딩된 신호 $\hat{x}$의 충실도를 향상시키기 위해 두 가지 추가 loss를 채택한다.
- Discriminator에 의해 정의된 feature space에서 계산된 feature loss \(\mathcal{L}_\mathcal{G}^\textrm{feat}\)
- 멀티스케일 spectral reconstruction loss \(\mathcal{L}_\mathcal{G}^\textrm{rec}\)
보다 구체적으로, feature loss는 생성된 오디오에 대한 discriminator의 내부 레이어 출력과 해당 타겟 오디오에 대한 discriminator의 내부 레이어 출력 간의 평균 절대 차이를 취하여 계산된다.
\[\begin{equation} \mathcal{L}_\mathcal{G}^\textrm{feat} = \mathbb{E}_x \bigg[ \frac{1}{KL} \sum_{k,l} \frac{1}{T_{k,l}} \sum_t \vert \mathcal{D}_{k,t}^{(l)} (x) - \mathcal{D}_{k,t}^{(l)} (\mathcal{G} (x)) \vert \bigg] \end{equation}\]여기서 $L$은 내부 레이어의 개수이고, \(\mathcal{D}_{k,t}^{(l)}\)는 discriminator $k$의 레이어 $l$의 $t$번째 출력이고, $T_{k,l}$은 시간 차원의 레이어의 길이를 나타낸다.
멀티스케일 spectral reconstruction loss는 Spectral Energy Distance의 사양을 따른다.
\[\begin{equation} \mathcal{L}_\mathcal{G}^\textrm{rec} = \sum_{s \in 2^6, \ldots, 2^{11}} \sum_t \| \mathcal{S}_t^s (x) - \mathcal{S}_t^s (\mathcal{G} (x)) \|_1 + \alpha_s \sum_t \| \log \mathcal{S}_t^s (x) - \log \mathcal{S}_t^s (\mathcal{G} (x)) \|_2 \end{equation}\]여기서 \(\mathcal{S}_t^s (x)\)는 윈도우 길이가 $s$이고 hop 길이가 $s/4$로 계산된 64-bin mel-spectrogram의 $t$번째 프레임을 나타낸다. 저자들은 $\alpha_s = \sqrt{s/2}$로 설정하였다.
전체 generator loss는 다양한 loss 구성 요소의 가중 합이다.
\[\begin{equation} \mathcal{L}_G = \lambda_\textrm{adv} \mathcal{L}_G^\textrm{adv} + \lambda_\textrm{feat} \mathcal{L}_\textrm{G}^\textrm{feat} + \lambda_\textrm{rec} \mathcal{L}_G^\textrm{rec} \end{equation}\]본 논문에서는 모든 실험에서 $\lambda_\textrm{adv} = 1$, $\lambda_\textrm{feat} = 100$, $\lambda_\textrm{rec} = 1$로 설정했다.
6. Joint compression and enhancement
기존의 오디오 처리 파이프라인에서 압축 및 향상은 일반적으로 서로 다른 모듈에서 수행된다. 예를 들어 오디오가 압축되기 전인 송신측에서 오디오가 디코딩된 후 수신측에서 오디오 향상 알고리즘을 적용할 수 있다. 이 설정에서 각 처리 단계는 예를 들어 채택된 특정 알고리즘에 의해 결정된 예상 프레임 길이로 입력 오디오를 버퍼링하기 때문에 end-to-end 대기 시간에 기여한다. 반대로 전체 대기 시간을 늘리지 않고 동일한 모델에서 공동으로 압축 및 향상을 수행할 수 있는 방식으로 SoundStream을 설계한다.
향상의 특성은 학습 데이터의 선택에 따라 결정될 수 있다. 구체적인 예로서 본 논문에서는 배경 잡음 억제와 압축을 결합하는 것이 가능함을 보여준다. 보다 구체적으로, 두 가지 모드 (denoising 활성화 또는 비활성화)를 나타내는 컨디셔닝 신호를 공급하여 inference 시 유연하게 denoising을 활성화 또는 비활성화할 수 있는 방식으로 모델을 학습한다. 이를 위해 (input, target, denoise) 형식의 튜플로 구성되는 학습 데이터를 준비한다. denoise = false인 경우 target = input아고 denoise = true인 경우 target에는 해당 input의 깨끗한 음성 성분이 포함된다. 따라서 네트워크는 컨디셔닝 신호가 비활성화된 경우 잡음이 있는 음성을 재구성하고 활성화된 경우 잡음이 있는 입력의 깨끗한 버전을 생성하도록 학습된다. 입력이 깨끗한 오디오 (음성 또는 음악)로 구성된 경우 target = input와 denoise는 true 또는 false일 수 있다. 이는 denoising이 활성화되었을 때 SoundStream이 깨끗한 오디오에 악영향을 미치지 않도록 하기 위한 것이다.
컨디셔닝 신호를 처리하기 위해 residual unit 사이에 FiLM (Feature-wise Linear Modulation) 레이어를 사용한다.
\[\begin{equation} \tilde{a}_{n,c} = \gamma_{n,c} a_{n,c} + \beta_{n,c} \end{equation}\]여기서 $a_{n,c}$는 $c$번째 채널의 $n$번째 activation이다. 계수 $\gamma_{n,c}$와 $\beta_{n,c}$는 denoising 모드를 결정하는 2차원 one-hot 인코딩을 입력으로 취하는 linear layer에 의해 계산된다. 이를 통해 시간 경과에 따라 denoising 수준을 조정할 수 있다.
원칙적으로 FiLM 레이어는 인코더 및 디코더 아키텍처 전체에서 어디에서나 사용할 수 있다. 그러나 저자들은 인코더 또는 디코더 측의 bottleneck 지점에 컨디셔닝을 적용하는 것이 효과적이며 서로 다른 깊이에서 FiLM 레이어를 적용해도 더 이상의 개선이 관찰되지 않는다는 것을 발견했다.
Results
- 데이터셋: LibriTTS (+ Freesound의 noise), MagnaTagATune
1. Comparison with other codecs
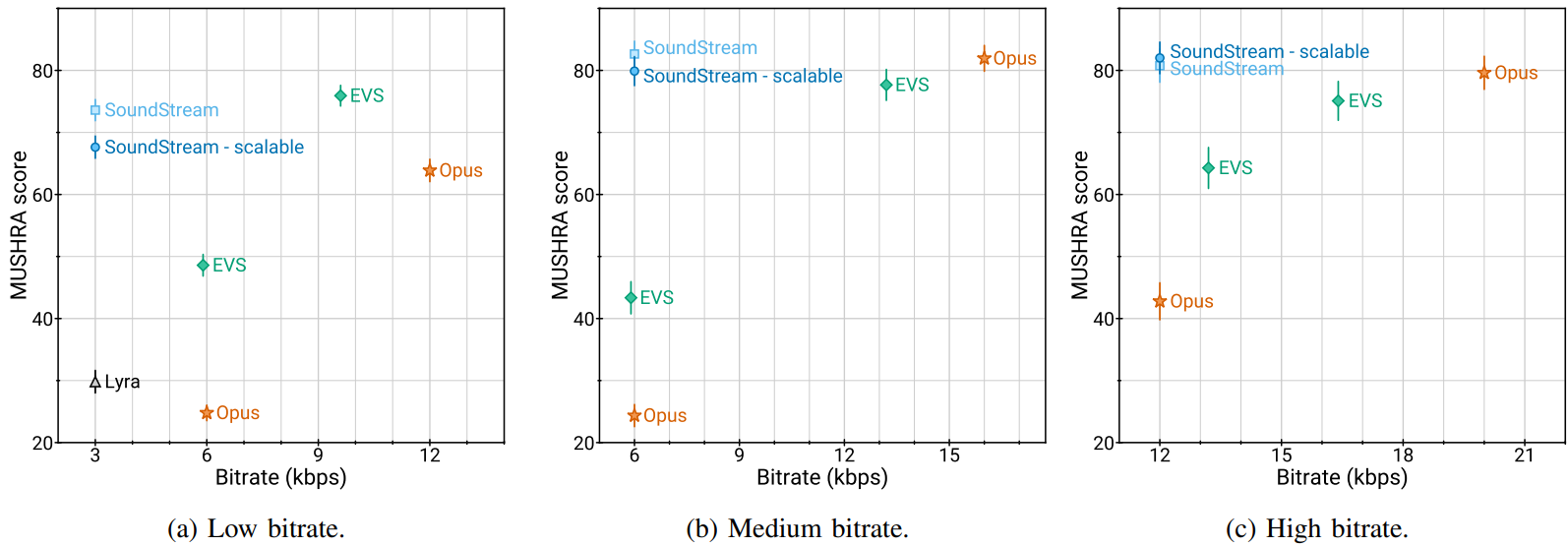
다음은 주관적 평가 결과이다.
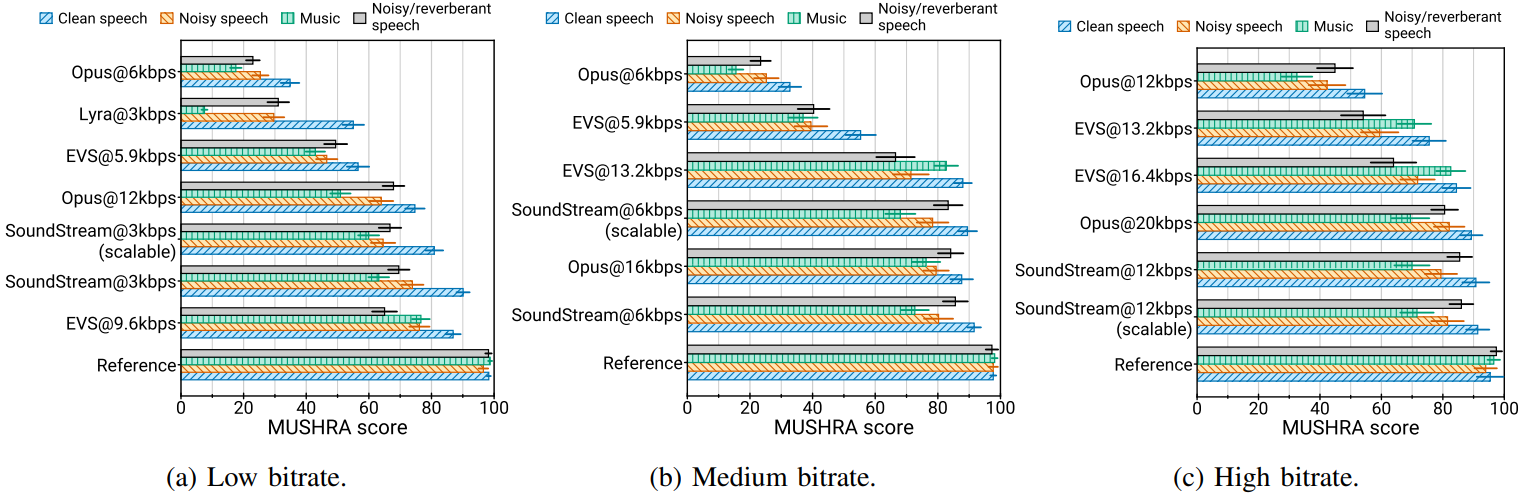
다음은 콘텐츠 유형별 주관적 평가 결과이다.
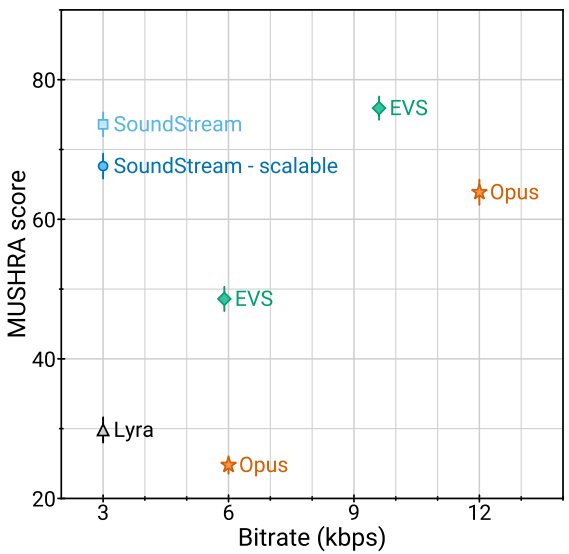
2. Objective quality metrics & Bitrate scalability
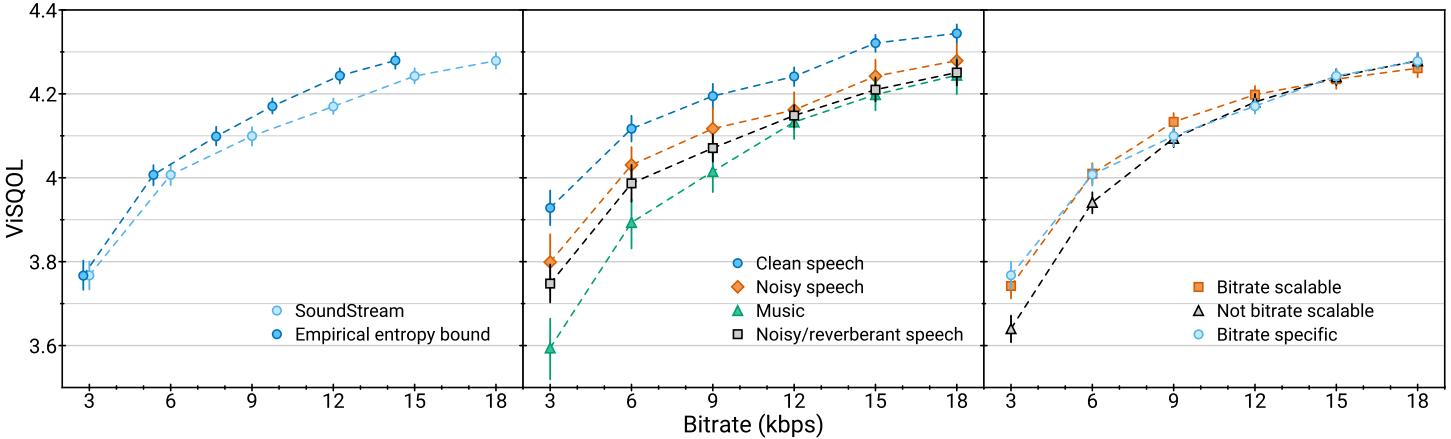
다음은 비트레이트에 따른 오디오 품질 (ViSQOL)을 나타낸 그래프이다.
3. Ablation studies
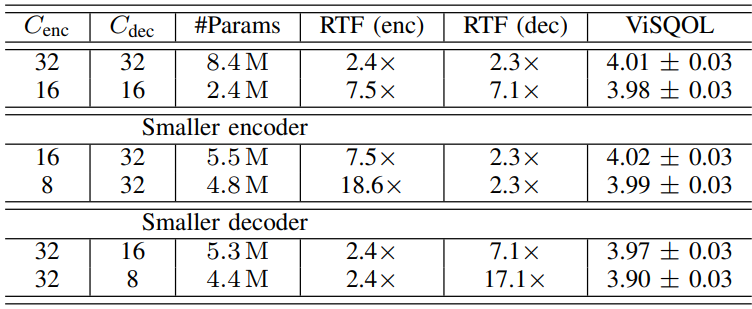
다음은 인코더와 디코더 간의 서로 다른 용량 trade-off에 대한 오디오 품질 (ViSQOL)과 모델 복잡도 (파라미터 수, real-time factor)이다. (6kbps)
다음은 residual vector quantizer 깊이와 코드북 크기 사이의 trade-off이다. (6kbps)

다음은 인코더/디코더의 총 striding factor로 정의되는 다양한 수준의 아키텍처 대기 시간에 대한 오디오 품질 (ViSQOL)과 real-time factor이다. (6kbps)

4. Joint compression and enhancement
다음은 공동으로 압축 및 배경 소음 억제를 수행할 때의 SoundStream 성능이다.
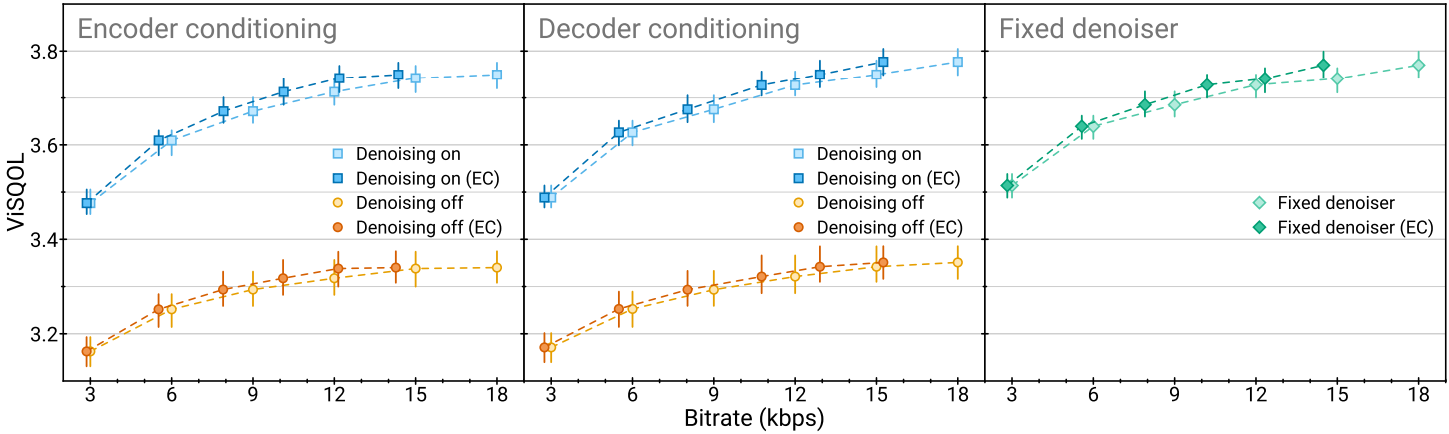
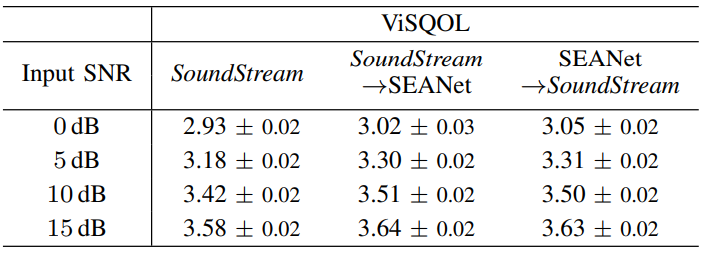
5. Joint vs. disjoint compression and enhancement
다음은 다양한 신호 대 잡음비 (SNR)에서 denoiser로서 SEANet과 비교한 표이다.