[논문리뷰] SoundStorm: Efficient Parallel Audio Generation
arXiv 2023. [Paper] [Page]
Zalán Borsos, Matt Sharifi, Damien Vincent, Eugene Kharitonov, Neil Zeghidour, Marco Tagliasacchi
Google Research
16 May 2023
Introduction
뉴럴 코덱에 의해 생성된 오디오의 이산 표현을 모델링하면 오디오 생성 task가 강력한 transformer 기반 sequence-to-sequence 모델링 접근 방식을 따를 수 있다. Unconditional 및 조건부 오디오 생성을 sequence-to-sequence 모델링으로 캐스팅하여 speech continuation, TTS, 일반 오디오 및 음악 생성에서 급속한 발전을 이루었다.
뉴럴 코덱의 토큰을 모델링하여 고품질 오디오를 생성하려면 이산 표현 속도를 높여 코드북 크기나 긴 토큰 시퀀스를 기하급수적으로 증가시켜야 한다. 코드북의 기하급수적 증가는 메모리 제한으로 인해 금지되며, 긴 토큰 시퀀스는 autoregressive model에 대한 계산 문제를 나타낸다.
특히 본 논문의 주안점인 attention 기반 모델은 self-attention을 계산하기 위한 시퀀스 길이에 대해 2차 런타임 복잡도가 발생할 것이다. 따라서 지각 품질과 런타임 사이의 trade-off를 해결하는 것은 오디오 생성의 핵심 과제 중 하나이다.
긴 오디오 토큰 시퀀스를 생성하는 문제는 적어도 세 가지 직교 접근법 또는 이들의 조합으로 해결할 수 있다.
- 효율적인 attention 메커니즘
- non-autoregressive한 병렬 디코딩 체계
- 뉴럴 오디오 코덱에서 생성된 토큰의 특수 구조에 맞게 조정된 맞춤형 아키텍처
그러나 unconditional하게 또는 텍스트와 같은 약한 조건에 기반하여 뉴럴 오디오 코덱의 토큰 시퀀스를 모델링하는 맥락에서 길고 고품질의 오디오 세그먼트를 효율적으로 생성하는 것은 열린 문제로 남아 있다.
저자들은 오디오 토큰 시퀀스의 특수 구조가 긴 시퀀스 오디오 모델링의 미래 발전에 가장 유망하다고 믿는다. 구체적으로 SoundStream과 EnCodec은 Residual Vector Quantization (RVQ)에 의존한다. 각 압축 오디오 프레임은 일련의 quantizer에 의해 양자화된다. 각 quantizer는 이전 quantizer의 residual에서 작동하고 quantizer의 수는 전체 비트레이트를 제어한다. 이것은 더 미세한 RVQ level의 토큰이 지각 품질에 덜 기여하는 계층적 토큰 구조를 유도하여 토큰 시퀀스의 공동 분포에 대한 효율적인 분해 및 근사를 허용한다. 따라서 모델과 디코딩 체계는 효율적인 학습과 inference를 위해 입력의 특수한 구조를 고려해야 한다.
본 논문에서는 효율적이고 고품질의 오디오 생성을 위한 방법인 SoundStorm을 제시한다. SoundStorm은 다음을 기반으로 긴 오디오 토큰 시퀀스를 생성하는 문제를 해결한다.
- 오디오 토큰의 계층 구조에 맞게 조정된 아키텍처
- RVQ 토큰 시퀀스에 대해 MaskGIT에서 영감을 받은 병렬, non-autoregressive, 신뢰도 기반 디코딩 체계
SoundStorm은 AudioLM의 semantic 토큰과 같은 컨디셔닝 신호가 주어지면 SoundStream이 생성하는 마스킹된 오디오 토큰을 예측하도록 학습된 양방향 attention 기반 Conformer에 의존한다. 입력 측에서 self-attention의 내부 시퀀스 길이가 SoundStream 프레임의 수와 동일하고 RVQ의 quantizer의 수와 무관하도록 동일한 SoundStream 프레임에 해당하는 토큰의 임베딩을 합산한다. 그런 다음 RVQ level마다 별도의 head에서 출력 임베딩을 처리하여 마스킹된 타겟 토큰을 예측한다. Inference 시 컨디셔닝 신호가 주어지면 SoundStorm은 마스킹된 모든 오디오 토큰으로 시작하고 마스킹된 토큰 RVQ를 여러 iteration에 걸쳐 level별로 채우고 level 내에서 단일 iteration 동안 병렬로 여러 토큰을 예측한다. 이 inference 체계를 지원하기 위해 inference 절차를 모방하는 학습용 마스킹 체계를 제안한다.
SoundStorm은 AudioLM의 acoustic generator 역할을 하여 AudioLM의 2단계 (coarse acoustic model)와 3단계 (fine acoustic model)를 모두 대체할 수 있다. SoundStorm은 AudioLM의 계층적 autoregressive acoustic generator보다 2배 더 빠르게 오디오를 생성하며 speaker identity와 acoustic 조건 측면에서 일치하는 품질과 향상된 일관성을 제공한다. 또한 SPEAR-TTS의 text-to-semantic 모델링 단계와 결합된 SoundStorm은 고품질의 자연스러운 대화를 합성하여 대화 내용, 화자 음성, 화자 전환을 제어할 수 있다. 30초의 대화를 합성할 때 단일 TPU-v4에서 2초가 소요된다.
Method
SoundStorm은 컨디셔닝 신호를 나타내는 이산 토큰 시퀀스를 입력으로 받고 오디오 파형으로 다시 디코딩할 수 있는 SoundStream 토큰 시퀀스를 출력으로 생성한다. 컨디셔닝 신호가 SoundStream 프레임과 시간 정렬되거나 동일한 속도로 업샘플링될 수 있다고 가정한다. 그러한 컨디셔닝 신호는 예를 들어 AudioLM, SPEAR-TTS, MusicLM에서 사용되는 semantic 토큰 시퀀스이며, 이는 본 논문의 방법을 이러한 모델의 acoustic generator에 대한 drop-in replacement로 만든다. 다른 유형의 컨디셔닝 신호에 대한 확장은 남겨두고 AudioLM의 coarse acoustic modeling 단계와 fine acoustic modeling 단계를 모두 대체하는 AudioLM 내의 acoustic generator로서 SoundStorm에 중점을 둔다.
1. Architecture
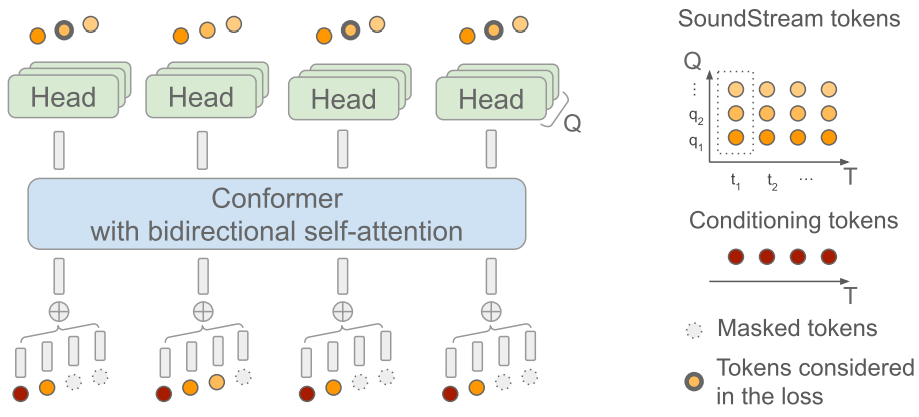
모델의 아키텍처는 위 그림에 설명되어 있다 ($T = 4$, $Q = 3$, $t = 0$, $q = 2$). 입력 측에서 프레임 수준에서 시간 정렬된 컨디셔닝 토큰을 SoundStream 토큰과 인터리브하고, 결과 시퀀스를 임베딩하고, 컨디셔닝 토큰의 임베딩을 포함하여 동일한 프레임에 해당하는 임베딩을 합산한다. 컨디셔닝 토큰의 결과로 나온 연속 임베딩을 Conformer에 전달한다. 결과적으로 Conformer에서 양방향 self-attention을 위한 시퀀스 길이는 SoundStream 프레임 수 (일반적으로 초당 50개)에 의해 결정되므로 RVQ level의 수 $Q$와 무관하므로 몇 분 정도의 길이로 오디오를 처리할 수 있다. 출력 측에서는 $Q$개의 dense layer를 head로 사용하여 타겟 SoundStream 토큰을 생성한다.
2. Masking
마스킹과 디코딩을 설계하기 위해 MaskGIT의 마스킹 및 신뢰도 기반 병렬 디코딩 체계를 RVQ에서 생성된 토큰 시퀀스로 확장한다. 높은 수준에서 본 논문의 접근 방식은 coarse-to-fine 순서에서 RVQ level별 MaskGIT의 전략을 따르는 것으로 볼 수 있다. Coarse-to-fine 순서로 정렬하는 것은 RVQ 계층 구조 level 간의 조건부 의존성을 존중할 뿐만 아니라 coarser level의 모든 토큰이 주어지면 finer level의 토큰의 조건부 독립성을 활용하기 때문에 특히 중요하다. Finer level의 토큰은 로컬의 세밀한 음향 디테일을 담당하므로 오디오 품질의 손실 없이 병렬로 샘플링할 수 있다.
이에 따라 학습을 위한 마스킹 체계를 설계한다. 음성 프롬프팅을 활성화하기 위해 timestep \(t \in \{1, \ldots, T\}\)를 랜덤하게 샘플링한다. 여기서 $T$는 최대 시퀀스 길이를 나타내며 이 timestep 이전에는 토큰을 마스킹하지 않는다. 컨디셔닝 토큰은 절대 마스킹되지 않는다. \(Y \in \{1, \ldots, C\}^{T \times Q}\)는 SoundStream 토큰을 나타내며, 여기서 $C$는 $Q$개의 level 중 각 RVQ level에서 사용되는 코드북 크기를 나타낸다. 마스킹 체계는 다음과 같이 진행된다.
- 프롬프트 구분 기호 timestep $t \sim \mathcal{U}{0, T-1}$를 샘플링
- 현재 RVQ level $q \sim \mathcal{U} {1, Q}$를 샘플링
- $q$에 대한 cosine schedule에 따라 마스크 \(M \in \{0, 1\}^T\)를 샘플링
(즉, $u \sim \mathcal{U}[0, \pi/2]$, $p = \cos (u)$, $M_i \sim \textrm{Bernoulli}(p)$) - $q$에서 선택된 비 프롬프트 토큰 ($M_{t’} = 1$이고 $t’ > t$이면 $Y${t’,q}를 마스킹)과 finer RVQ level의 모든 비 프롬프트 토큰 ($Y{> t, > q}$)을 마스킹
마스킹된 토큰 시퀀스가 주어지면 ground-truth 토큰을 타겟으로 하는 cross-entropy loss로 모델을 학습한다. 여기서 loss는 $q$번째 RVQ level 내에서 마스킹된 토큰에 대해서만 계산된다.
3. Iterative Parallel Decoding
컨디셔닝 신호가 주어지면 디코딩 체계는 프롬프트를 제외한 모든 SoundStream 토큰을 마스킹하여 시작한다. 그런 다음 level $1, \ldots, q$에 대한 모든 토큰이 샘플링된 경우에만 level $q+1$로 진행하면서 coarse -to-fine 방식으로 level별로 RVQ 토큰 샘플링을 진행한다. RVQ level 내에서 MaskGIT의 신뢰도 기반 샘플링 체계를 사용한다. 즉, 여러 forward pass를 수행하고 각 iteration $i$에서 마스킹된 위치에 대한 후보를 샘플링하고 신뢰도 점수를 기반으로 이들의 $p_i$를 유지한다. 여기서 $p_i$는 cosine schedule을 따른다. MaskGIT와 다르게 각 RVQ level 내의 마지막 iteration에 대한 신뢰도 기반 샘플링 대신 greedy 디코딩을 사용하면 인지된 오디오 품질이 개선된다.
RVQ 디코딩을 level별로 수행하면 finer level에서 조건부 독립 가정을 활용할 수 있다. 즉, 로컬의 세밀한 음향 디테일을 나타내기 때문에 여러 개의 finer 토큰을 병렬로 샘플링할 수 있다. 이는 디코딩 중에 finer RVQ level로 진행함에 따라 forward pass 수를 크게 줄일 수 있음을 의미한다.
Experiments
- 구현 디테일
- SoundStream
- 초당 50 프레임 생성
- RVQ: $Q$ = 12, 코드북 크기 = 1024
- 비트레이트 = $50 \times 12 \times \log_2 1024 = 6000$ bps
- AudioLM의 semantic 토큰을 컨디셔닝으로 사용
- Conformer (파라미터 3.5억 개)
- 레이어 수: 12
- attention head 수: 16
- 임베딩 크기: 1024
- 모델 차원: 1024
- feedforward 차원: 4096
- convolution kernel size: 5
- rotary positional embedding 사용
- 디코딩
- iteration 수: $(16, 1, 1, \ldots, 1)$ $\rightarrow$ forward pass 27번
- 즉, 두 번째 level부터는 level별로 가장 높은 확률로 greedy하게 토큰을 선택
- SoundStream
1. Speech Intelligibility, Audio Quality, Voice Preservation and Acoustic Consistency
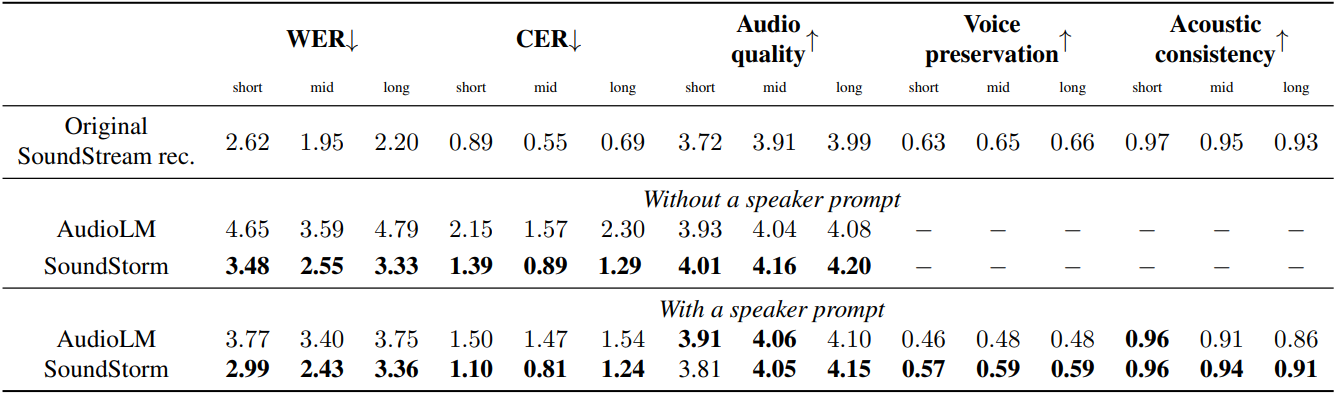
다음은 AudioLM의 acoustic generator와 SoundStorm의 명료도, 품질, 음성 보존, 음향 일관성을 비교한 표이다.
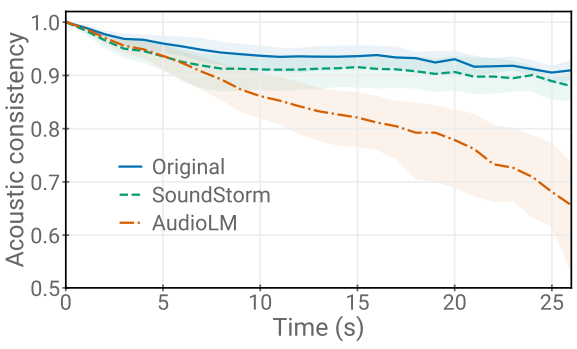
다음은 LibriSpeech test-clean ‘long’ split의 샘플에 대한 프롬프트와 생성된 오디오 간의 음향 일관성을 비교한 그래프이다.
2. Runtime and Ablations
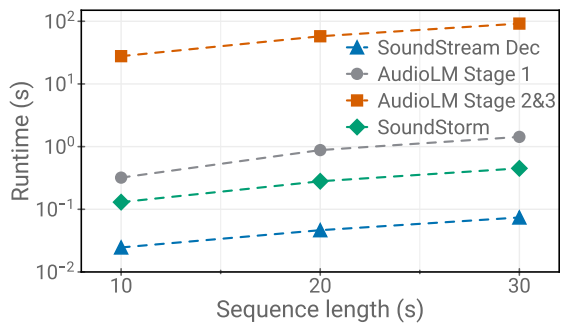
다음은 시퀀스 길이에 따른 런타임을 비교한 그래프이다.
다음은 첫번째 RVQ level의 iteration 수에 따른 오디오 품질을 나타낸 그래프이다.