[논문리뷰] SnapFusion: Text-to-Image Diffusion Model on Mobile Devices within Two Seconds
NeurIPS 2023. [Paper] [Page]
Yanyu Li, Huan Wang, Qing Jin, Ju Hu, Pavlo Chemerys, Yun Fu, Yanzhi Wang, Sergey Tulyakov, Jian Ren
Snap Inc. | Northeastern University
1 Jun 2023

Introduction
Diffusion 기반 text-to-image 모델은 텍스트 프롬프트를 사용하여 사실적인 콘텐츠를 합성하는 데 놀라운 발전을 보여준다. 예를 들면 콘텐츠 제작, 이미지 편집, inpainting, super-resolution, 동영상 합성, 3D 에셋 생성에 큰 영향을 미친다. 이러한 영향으로 인해 그러한 모델들을 실행하기 위한 계산 요구 사항이 상당히 증가하였다. 결과적으로 필요한 대기 시간 제약 조건을 대규모로 충족하기 위해 종종 고급 GPU가 있는 클라우드 기반 inference 플랫폼이 필요하다. 이것은 높은 비용을 발생시키고 개인 이미지, 동영상, 프롬프트를 제3자 서비스에 전송한다는 사실 때문에 잠재적인 개인 정보 보호 문제를 야기한다.
당연하게도 모바일 장치에서 text-to-image diffusion model의 inference 속도를 높이려는 노력이 떠오르고 있다. 최근 연구들은 실행 시간을 줄이기 위해 양자화 또는 GPU 관련 최적화를 사용한다. 즉, Samsung Galaxy S23 Ultra에서 diffusion 파이프라인을 11.5초로 가속화하였다. 이러한 방법은 모바일 플랫폼에서 특정 속도 향상을 효과적으로 달성하지만 얻은 대기 시간은 원활한 사용자 경험을 방해한다. 또한 정량적 분석을 통해 on-device 모델의 생성 품질을 체계적으로 조사한 기존 연구는 없었다.
본 논문에서는 모바일 장치에서 2초 이내에 이미지를 생성하는 최초의 text-to-image diffusion model을 제시한다. 이를 달성하기 위해 주로 UNet의 느린 inference 속도를 개선하고 필요한 denoising step의 수를 줄이는 데 중점을 둔다. 첫째, 조건부 diffusion model의 주요 병목 지점인 UNet의 아키텍처는 거의 최적화되지 않았다. 기존 연구들은 주로 사후 학습 최적화에 중점을 둔다. 기존의 압축 기술 (ex. 모델 pruning, 아키텍처 검색)은 강력한 fine-tuning 없이는 복구하기 어려운 사전 학습된 diffusion model의 성능을 저하시킨다. 결과적으로 아키텍처 중복성이 완전히 활용되지 않아 가속 비율이 제한된다. 둘째, denoising diffusion process의 유연성은 on-device 모델에 대해 잘 탐색되지 않았다. Denoising step의 수를 직접 줄이는 것은 생성 성능에 영향을 미치며 step을 점진적으로 증류하면 영향을 완화할 수 있다. 그러나 step distillation의 목적 함수와 on-device 모델 학습 전략은 특히 대규모 데이터셋을 사용하여 학습된 모델의 경우 아직 철저히 연구되지 않았다.
Model Analysis of Stable Diffusion
저자들은 SD-v1.5의 파라미터와 계산 강도를 종합적으로 연구하였다. 심층 분석은 네트워크 아키텍처와 알고리즘 패러다임의 범위에서 모바일 장치에 text-to-image diffusion model을 배포하는 데 병목 현상을 이해하는 데 도움이 된다. 한편, 네트워크의 미시적 수준의 분해는 아키텍처 재설계와 검색의 기초 역할을 한다.
거시적 관점
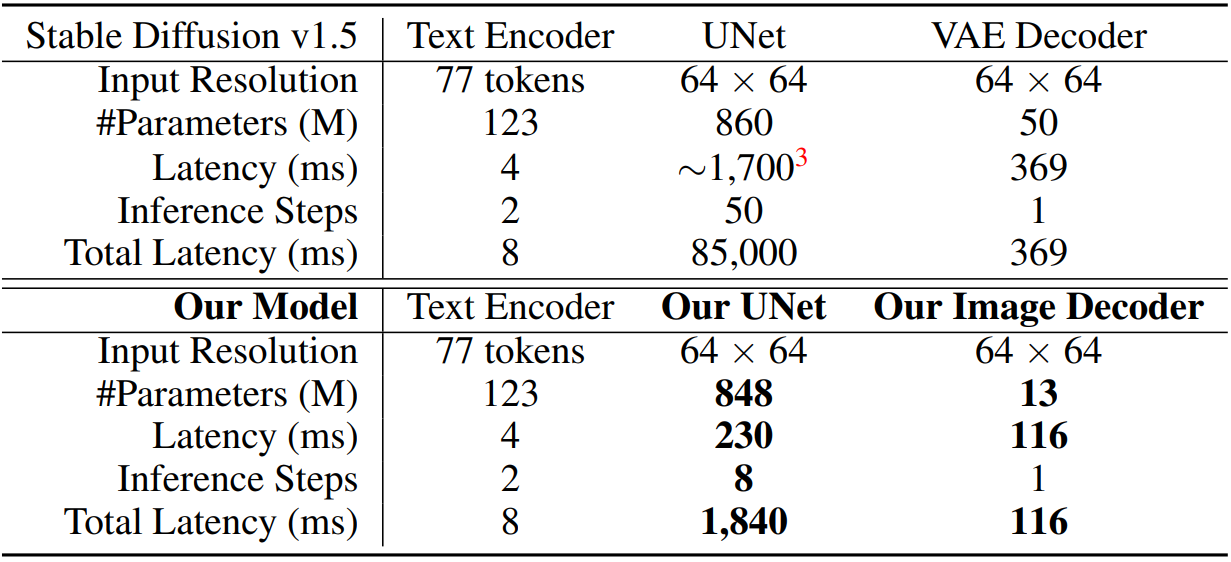
위 표와 그래프에서 볼 수 있듯이 stable diffusion의 네트워크는 세 가지 주요 구성 요소로 구성된다.
- 텍스트 인코더: 입력 텍스트 프롬프트를 임베딩으로 변환하기 위해 ViT-H 모델을 사용하며 각 이미지 생성 프로세스에 대해 두 단계 (CFG용 1개 포함)로 실행되어 inference 대기 시간의 아주 작은 부분 (8ms)만 구성한다.
- VAE 디코더: Latent feature를 사용하여 이미지를 생성한다 (369ms).
- Denoising UNet: 계산에 집중적일 뿐만 아니라 (1.7초) 생성 품질을 보장하기 위해 반복적인 전달 step을 요구한다. 예를 들어 SD-v1.5에서 총 denoising timestep은 inference를 위해 50으로 설정되어 기기 내 생성 프로세스가 분 단위로 크게 느려진다.
UNet 분석
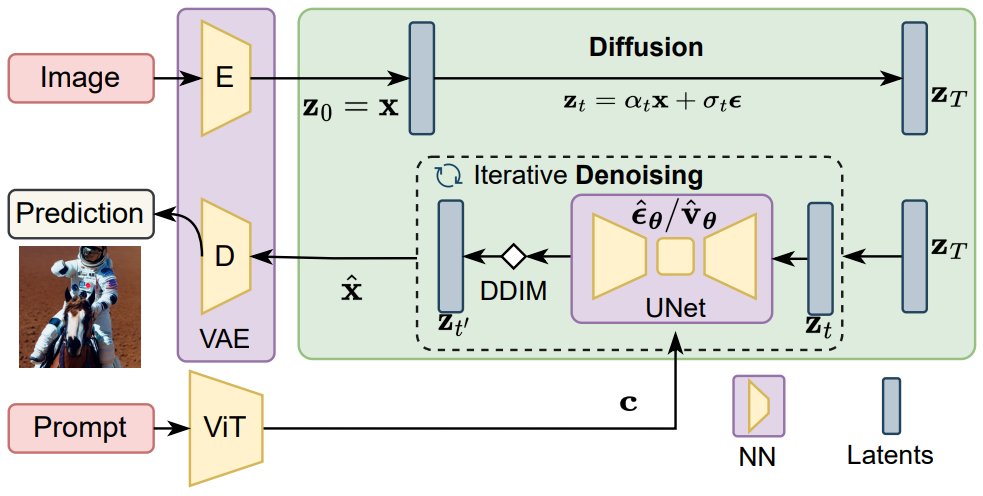
시간 조건부 ($t$) UNet은 cross-attention과 ResNet 블록으로 구성된다. 구체적으로, 텍스트 임베딩 $c$를 공간 feature에 통합하기 위해 각 step에서 cross-attention 메커니즘이 사용된다.
\[\begin{equation} \textrm{Cross-Attention} (Q_{z_t}, K_c, V_c) = \textrm{Softmax}( \frac{Q_{z_t} \cdot K_c^\top}{\sqrt{d}} ) \cdot V_c, \end{equation}\]여기서 $Q$는 noisy한 데이터 $z_t$에서 project되고, $K$와 $V$는 텍스트 조건에서 project되며, $d$는 feature 차원이다. UNet은 또한 ResNet 블록을 사용하여 locality를 캡처하며 UNet의 forward를 다음과 같이 공식화할 수 있다.
\[\begin{equation} \hat{\epsilon}_\theta (t, z_t) = \prod \{ \textrm{Cross-Attention} (z_t, c), \textrm{ResNet} (z_t, t) \} \end{equation}\]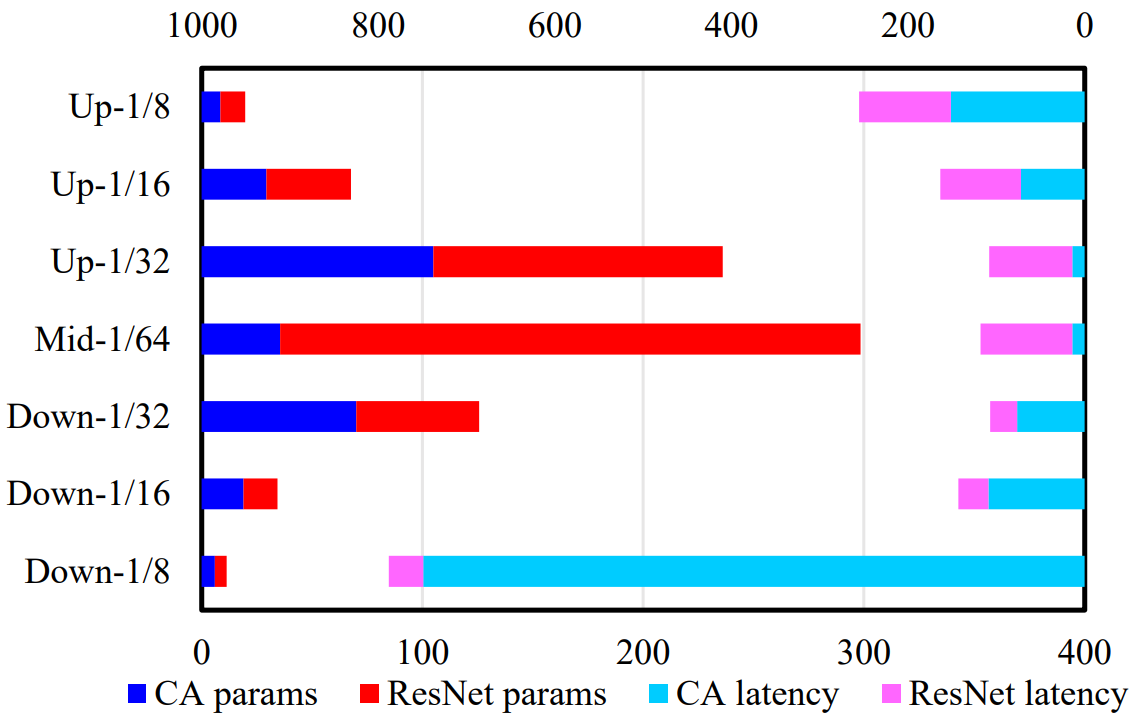
파라미터의 분포와 UNet의 계산량은 위 그림에 나와 있으며, 확장된 채널 크기로 인해 파라미터가 중간 (다운샘플링된) 단계에 집중되어 있음을 보여준다. 그 중 ResNet 블록이 대부분을 구성한다. 대조적으로 공간적 cross-attention이 feature 크기 (토큰)에 대해 2차 계산 복잡도를 갖기 때문에 UNet의 가장 느린 부분은 가장 큰 feature 해상도를 가진 입력 및 출력 단계이다.
Architecture Optimizations
저자들은 효율적인 신경망을 얻기 위해 SD-v1.5의 아키텍처 중복성을 조사하였다. 그러나 SD의 막대한 학습 비용을 고려할 때 기존 pruning 또는 아키텍처 검색 기술을 적용하는 것은 쉽지 않다. 아키텍처의 모든 순열은 수백 또는 수천 개의 GPU로 fine-tuning해야 하는 성능 저하로 이어질 수 있다. 따라서 본 논문은 사전 학습된 UNet 모델의 성능을 유지하면서 점진적으로 효율성을 향상시키는 아키텍처 진화 방법을 제안한다. Deterministic한 이미지 디코더의 경우 맞춤형 압축 전략과 간단하면서도 효과적인 프롬프트 기반 distillation 방식을 적용한다.
1. Efficient UNet
저자들의 실증적 관찰에 따르면 네트워크 pruning 또는 검색으로 인한 연산자 변경으로 인해 합성 이미지가 저하되어 성능을 복구하기 위해 상당한 학습 비용이 필요하다. 따라서 문제를 완화하기 위해 robust한 학습과 평가 및 진화하는 파이프라인을 제안한다.
Robust한 학습
Elastic depth의 아이디어에서 영감을 받아 각 cross-attention과 ResNet 블록을 확률 $p(\cdot, I)$로 실행하기 위해 확률적 순방향 전파를 적용한다. 여기서 $I$는 해당 블록을 건너뛰는 identity mapping을 나타낸다. 따라서 다음과 같이 된다.
\[\begin{equation} \hat{\epsilon}_\theta (t, z_t) = \prod \{ p(\textrm{Cross-Attention} (z_t, c), I), p(\textrm{ResNet} (z_t, t), I) \} \end{equation}\]이 학습 강화를 통해 네트워크는 아키텍처 순열에 robust해 각 블록의 정확한 평가와 안정적인 아키텍처 진화가 가능하다.
평가 및 아키텍처 진화
구축된 진화 action 집합으로 robust한 학습을 통해 얻은 모델을 이용하여 UNet의 온라인 네트워크 변화를 수행한다.
\[\begin{equation} A \in \{ A_{\textrm{Cross-Attention} [i,j]}^{+,-}, A_{\textrm{ResNet} [i,j]}^{+,-} \} \end{equation}\]여기서 $A^{+,-}$는 해당 위치 (단계 $i$, 블록 $j$)에서 cross-attention 또는 ResNet 블록을 제거(-) 또는 추가(+)하는 action을 나타낸다. 각 action은 실행 대기 시간과 생성 성능에 미치는 영향으로 평가된다. 대기 시간의 경우 cross-attention과 ResNet 블록의 가능한 각 구성에 대해 구축된 lookup table을 사용한다. On-device 속도를 위해 UNet을 개선한다. 생성 성능을 위해 CLIP 점수를 선택하여 생성된 이미지와 텍스트 조건 간의 상관 관계를 측정한다. MS-COCO validation set의 작은 부분 집합 (이미지 2천 개), 고정 step (50), CFG scale 7.5를 사용하여 점수를 벤치마킹하고, 각 action을 테스트하는 데 약 2.5 A100 GPU hour가 걸린다. 단순화를 위해 각 action의 value 점수는
\[\begin{equation} \frac{\Delta \textrm{CLIP}}{\Delta \textrm{Latency}} \end{equation}\]로 정의된다. 여기서 대기 시간이 짧고 CLIP에 대한 기여도가 높은 블록은 보존되는 경향이 있으며 반대는 아키텍처 진화에서 제거된다 (자세한 내용은 Algorithm 1 참조).

네트워크 최적화 비용을 더욱 줄이기 위해 한 번에 일련의 action을 실행하여 중복 블록을 제거하거나 중요한 위치에 추가 블록을 추가하는 아키텍처 진화를 수행한다. 본 논문의 학습 패러다임은 대규모 네트워크 순열을 허용하면서 사전 학습된 UNet의 성능을 성공적으로 보존한다.
2. Efficient Image Decoder
이미지 디코더의 경우 합성 데이터를 사용하여 채널 축소를 통해 얻은 효율적인 이미지 디코더를 학습하는 distillation 파이프라인을 제안한다. 여기서는 이미지 인코더도 학습하는 VAE 학습을 따르는 대신 효율적인 디코더만 학습한다. 텍스트 프롬프트를 사용하여 50개의 denoising step후에 SD-v1.5의 UNet에서 latent 표현을 가져와 효율적인 이미지 디코더와 SD-v1.5 중 하나에 전달하여 두 개의 이미지를 생성한다. 그런 다음 두 이미지 사이의 평균 제곱 오차를 최소화하여 디코더를 최적화한다. Distillation을 위해 합성 데이터를 사용하면 다양한 noise를 샘플링하여 무제한 이미지를 얻기 위해 각 프롬프트를 사용하는 즉시 데이터셋을 보강할 수 있는 이점이 있다.
Step Distillation
Diffusion model의 효율적인 아키텍처를 제안하는 것 외에도 더 많은 속도 향상을 달성하기 위해 UNet의 반복적인 denoising step 수를 줄이는 것을 고려한다. Teacher를 예를 들어 32 step으로 증류하여 더 적은 step (ex. 16 step)에서 실행하는 student로 inference step이 감소되는 step distillation의 연구 방향을 따른다. 이런 식으로 student는 teacher에 비해 2배의 속도가 향상된다.
1. Overview of Distillation Pipeline
이전 연구들을 보면 step distillation은 $v$-prediction 유형에서 가장 잘 작동한다. 즉, UNet은 noise $\epsilon$ 대신 속도 $v$를 출력한다. 따라서 SD-v1.5를 다음과 같은 원래 loss \(\mathcal{L}_\textrm{ori}\)를 따라 $v$-prediction으로 fine-tuning한다.
\[\begin{equation} \mathcal{L}_\textrm{ori} = \mathbb{E}_{t \sim U [0,1], x \sim p_\textrm{data}, \epsilon \sim \mathcal{N}(0, I)} \| \hat{v}_\theta (t, z_t, c) - v \|_2^2 \end{equation}\]여기서 $v$는 timestep $t$에서 깨끗한 latent $x$와 noise $\epsilon$에서 파생될 수 있는 ground-truth 타겟 속도이다.
\[\begin{equation} v = \alpha_t \epsilon - \sigma_t x \end{equation}\]본 논문의 distillation 파이프라인에는 세 단계가 포함된다.
- SD-v1.5에서 step distillation을 수행하여 50 step 모델의 성능에 도달하는 16 step의 UNet을 얻는다. 여기에서 32 step에서 점진적으로 수행하는 대신 바로 16 step으로 distillation을 수행한다.
- 동일한 전략을 사용하여 16 step의 efficient UNet을 얻는다.
- 16 step SD-v1.5를 teacher로 사용하여 16 step UNet에서 초기화된 efficient UNet에서 step distillation을 수행한다. 이것은 최종 UNet 모델인 8 step efficient UNet이 된다.
2. CFG-Aware Step Distillation

Vanilla Step Distillation
UNet 입력, timestep $t$, noisy latent $z_t$, 텍스트 임베딩 $c$가 주어지면 teacher UNet은 시간 $t$에서 $t’$까지 그리고 $t’‘$까지 두 가지 DDIM denoising step을 수행한다 ($0 \le t’’ < t’ < t \le 1$). 이 프로세스는 다음과 같이 공식화될 수 있다.
\[\begin{aligned} \hat{v}_t = \hat{v}_\theta (t, z_t, c) & \Rightarrow z_{t'} = \alpha_{t'} (\alpha_t z_t - \sigma_t \hat{v}_t) + \sigma_{t'} (\sigma_t z_t + \alpha_t \hat{v}_t) \\ \hat{v}_{t'} = \hat{v}_\theta (t', z_{t'}, c) & \Rightarrow z_{t''} = \alpha_{t''} (\alpha_{t'} z_{t'} - \sigma_{t'} \hat{v}_{t'}) + \sigma_{t''} (\sigma_{t'} z_{t'} + \alpha_{t'} \hat{v}_{t'}) \end{aligned}\]$\eta$로 parameterize된 student UNet은 단 하나의 DDIM denoising step만 수행한다.
\[\begin{equation} \hat{v}_t^{(s)} = \hat{v}_\eta (t, z_t, c) = \Rightarrow \hat{x}_t^{(s)} = \alpha_t z_t - \sigma_t \hat{v}_t^{(s)} \end{equation}\]여기서 위첨자 $(s)$는 student UNet을 위한 변수임을 나타낸다. Student UNet은 단 한 번의 denoising step으로 $z_t$에서 teacher의 noisy latent $z_{t’’}$를 예측해야 한다. 이 목적 함수는 $x$-space에서 계산된 다음과 같은 vanilla step distillation 목적 함수로 변환된다.
\[\begin{equation} \mathcal{L}_\textrm{vani_dstl} = \varpi (\lambda_t) \| \hat{x}_t^{(s)} - \frac{z_{t''} - \frac{\sigma_{t''}}{\sigma_t} z_t}{\alpha_{t''} - \frac{\sigma_{t''}}{\sigma_t} \alpha_t} \|_2^2 \\ \varpi (\lambda_t) = \max (\frac{\alpha_t^2}{\sigma_t^2}, 1) \end{equation}\]여기서 $\varpi (\lambda_t)$는 truncated SNR weighting coefficient이다.
CFG-Aware Step Distillation
위의 vanilla step distillation은 FID가 손상되지 않은 (또는 약간만) 손상되지 않은 상태에서 inference 속도를 향상시킬 수 있다. 그러나 CLIP 점수가 분명히 악화된다. 해결 방법으로 CLIP 점수를 크게 향상시키는 classifier-free guidance-aware (CFG-aware) distillation loss 목적 함수를 도입한다.
저자들은 loss를 계산하기 전에 teacher와 student 모두에게 classifier-free guidance를 수행할 것을 제안하였다. 특히, UNet의 $v$-prediction 출력을 얻은 후 CFG 단계를 추가한다. \(\hat{v}_t^{(s)}\)는 다음 가이드 버전으로 대체된다.
\[\begin{equation} \tilde{v}_t^{(s)} = w \hat{v}_\eta (t, z_t, c) - (w - 1) \hat{v}_\eta (t, z_t, \emptyset) \end{equation}\]여기서 $w$는 CFG scale이다. 실험에서 $w$는 범위 $[2, 14]$에 걸쳐 균일한 분포에서 랜덤하게 샘플링된다. 이 범위는 CFG range라고 하며 학습 중에 FID와 CLIP 점수를 절충하는 방법을 제공하는 것으로 표시된다.
UNet 출력을 가이드 버전으로 교체한 후 다른 모든 절차는 teacher와 student 모두에게 동일하게 유지된다. 이는 \(\mathcal{L}_\textrm{vani_dstl}\)의 대응되는 버전을 제공한다. 이를 CFG distillation loss \(\mathcal{L}_\textrm{cfg_dstl}\)라고 한다.
Total Loss Function
경험적으로 \(\mathcal{L}_\textrm{vani_dstl}\)은 낮은 FID를 달성하는 데 도움이 되는 반면 \(\mathcal{L}_\textrm{cfg_dstl}\)은 높은 CLIP 점수를 달성하는 데 도움이 된다. 두 loss를 최대한 활용하기 위해 두 loss를 동시에 사용하는 loss 혼합 체계를 도입한다. 미리 정의된 CFG 확률 $p$가 도입되어 각 학습 iteration에서 CFG distillation loss를 사용할 확률을 나타낸다. 따라서 $1 - p$ 확률에서는 vanilla distillation loss가 사용된다. 이제 전체 loss를을 요약할 수 있다.
\[\begin{aligned} \mathcal{L} &= \mathcal{L}_\textrm{dstl} + \gamma \mathcal{L}_\textrm{ori} \\ \mathcal{L}_\textrm{dstl} &= \begin{cases} \mathcal{L}_\textrm{cfg_dstl} & \quad \textrm{if} \; P \sim U [0,1] < p \\ \mathcal{L}_\textrm{vani_dstl} & \quad \textrm{otherwise} \end{cases} \end{aligned}\]여기서 \(\mathcal{L}_\textrm{ori}\)는 원래 denoising loss를 나타내고 $\gamma$는 가중 계수이다. $U$는 범위 $(0, 1)$에 대한 균일 분포를 나타낸다.
Discussion
최근 연구에서는 guided diffusion model을 증류하는 방법을 연구했으며, CFG의 동작을 모방하기 위해 추가 파라미터 ($w$-조건이라고 함)가 있는 student 모델로 CFG를 증류할 것을 제안하였다. 따라서 이미지를 생성할 때 네트워크 평가 비용이 2배 감소한다. 여기서 본 논문이 제안한 솔루션은 적어도 네 가지 관점에서 $w$-조건 모델의 솔루션과 다르다.
- 일반적인 동기가 다르다. $w$-조건 모델은 UNet의 네트워크 평가 횟수를 줄이는 것을 목표로 하는 반면, 본 논문은 distillation 중 이미지 품질을 개선하는 것을 목표로 한다.
- 제안된 기술이 다르다. $w$-조건 모델은 UNet에 대한 입력으로 CFG scale을 통합하여 더 많은 파라미터를 생성하지만 본 논문의 모델은 그렇지 않다.
- 경험적으로 $w$-조건 모델은 CFG scale이 클 때 높은 CLIP 점수를 얻을 수 없지만 본 논문의 방법은 특히 높은 CLIP 점수를 가진 샘플을 생성하는 데 좋다.
- $w$-조건 모델은 특히 다양성-품질의 trade off를 CFG scale을 조정하여 inference 중에만 가능했지만 본 논문은 학습 중에 이러한 trade-off를 실현할 수 있는 좋은 속성을 제공한다. 이는 모델 공급자가 품질 또는 다양성을 위해 다양한 모델을 학습하는 데 매우 유용할 수 있다.
Experiment
1. Text-to-Image Generation
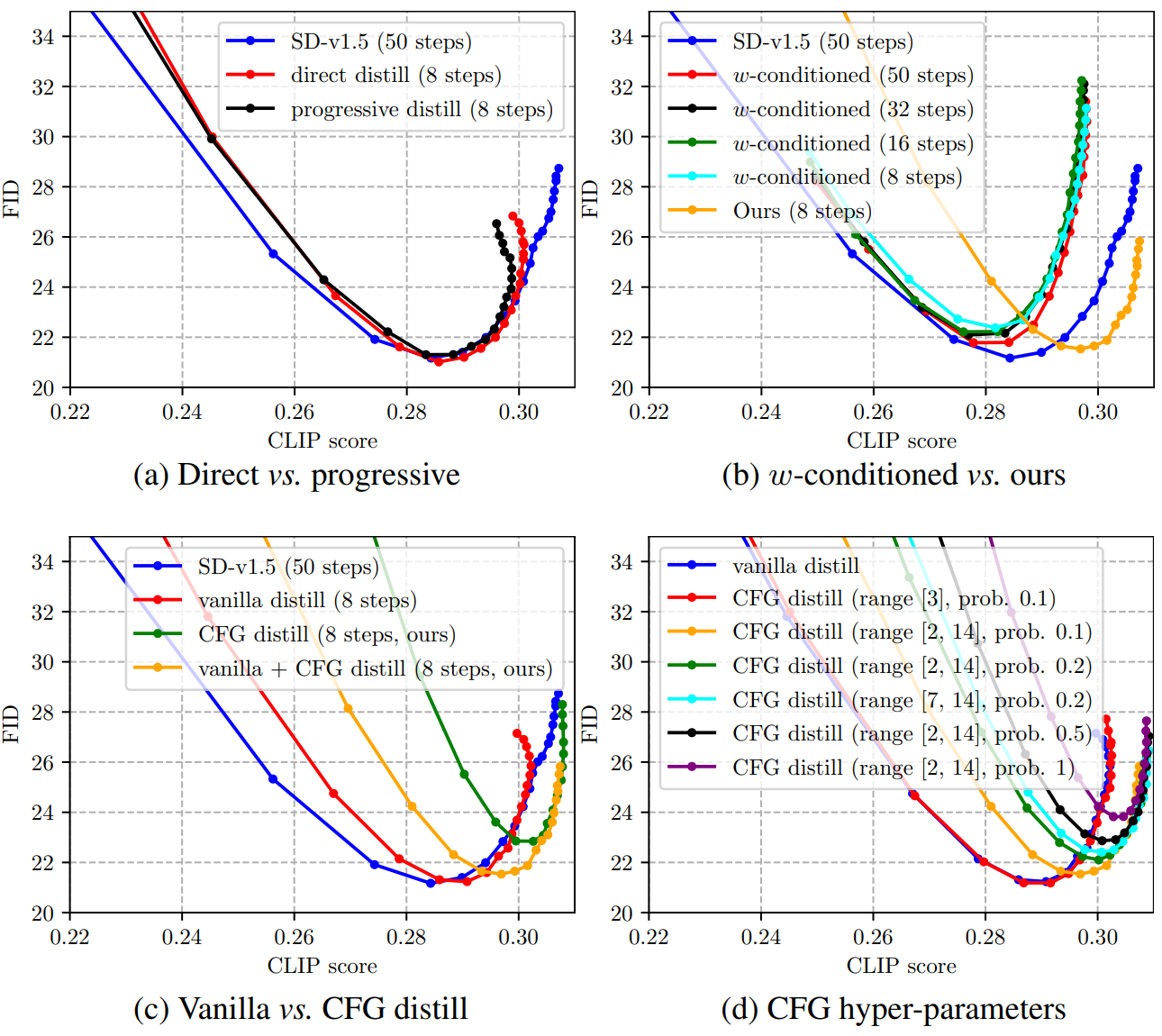
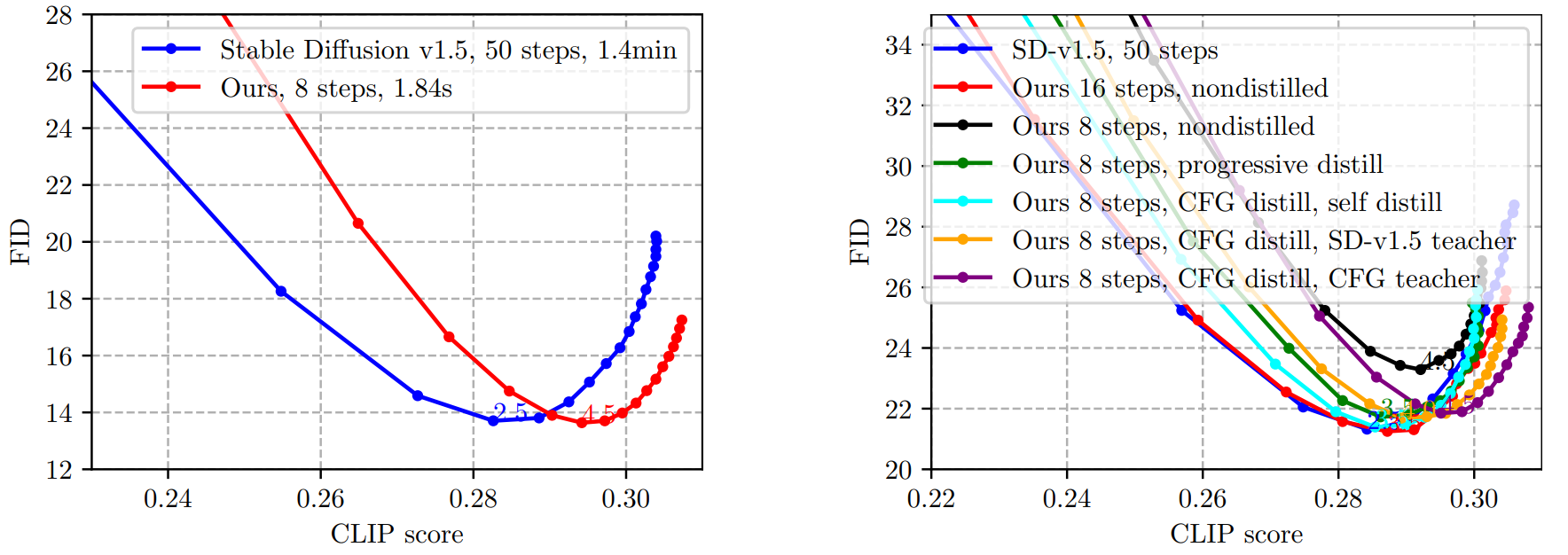
다음은 1.0에서 10.0까지의 CFG scale을 사용한 MS-COCO 2014 validation set에서의 FID vs. CLIP 그래프이다. 왼쪽은 전체 세트에서 SD-v1.5과 비교한 그래프이다. 오른쪽은 6천 개의 샘플에서 다양한 step과 다양한 teacher 모델 설정에 대하여 비교한 그래프이다.
다음은 MS-COCO 2017 5K subset에서의 zero-shot 평가 결과이다.

2. Ablation Analysis
Robust Training
다음은 몇몇 블록들을 제거하고 robust한 학습을 하였을 때의 동일한 프롬프트에 대한 이미지 샘플들이다. DS는 다운샘플링 블록, mid는 중간 블록, US는 업샘플링 블록을 뜻한다.

Step Distillation
다음은 step distillation에서의 ablation study 결과이다.