[논문리뷰] SmartEdit: Exploring Complex Instruction-based Image Editing with Multimodal Large Language Models
CVPR 2024. [Paper] [Page] [Github]
Yuzhou Huang, Liangbin Xie, Xintao Wang, Ziyang Yuan, Xiaodong Cun, Yixiao Ge, Jiantao Zhou, Chao Dong, Rui Huang, Ruimao Zhang, Ying Shan
Tencent ARC Lab | The Chinese University of Hong Kong | University of Macau | Tencent AI Lab | Shenzhen Institute of Advanced Technology | Shanghai Artificial Intelligence Laboratory | Tsinghua University
11 Dec 2023

Introduction
Text-to-Image (T2I) 합성은 diffusion model 덕분에 최근 몇 년간 상당한 발전을 이루었다. 이러한 방법을 통해 자연어 설명과 일치할 뿐만 아니라 인간의 선호도에도 부합하는 이미지 생성이 가능해지며 이 분야에서 상당한 도약을 이루었다. InstructPix2Pix로 대표되는 명령 기반 이미지 편집 방법은 사전 학습된 T2I diffusion model을 prior로 활용한다. 이를 통해 자연어 명령을 통해 편리하고 손쉽게 이미지를 수정할 수 있다.

기존 명령 기반 이미지 편집 방법은 간단한 명령을 효과적으로 처리할 수 있지만 모델에 보다 강력한 이해 및 추론 능력이 필요한 복잡한 시나리오를 처리할 때는 종종 부족하다. 복잡한 시나리오에는 두 가지 일반적인 유형이 있다. 첫 번째는 원본 이미지에 여러 물체가 있고 명령이 특정 속성 (ex. 위치, 크기, 색상, 거울 안/밖)을 통해 이러한 물체 중 하나만 수정하는 경우이다. 다른 하나는 편집 대상을 식별하기 위해 세상에 대한 지식이 필요한 경우이다.
저자들은 이 두 가지 유형을 각각 복잡한 이해 시나리오와 복잡한 추론 시나리오로 정의하였다. 본 논문에서는 이러한 시나리오에서 기존 방법이 실패하는 이유를 식별하고 이러한 시나리오의 문제를 해결하려고 시도하였다.
이러한 시나리오에서 기존 방법이 실패하는 첫 번째 이유는 일반적으로 명령을 처리하기 위해 diffusion model (ex. Stable Diffusion)의 간단한 CLIP 텍스트 인코더에 의존하기 때문이다. 이러한 상황에서 모델은 명령을 이해 및 추론하고 명령을 이해하기 위해 이미지를 통합하는 데 어려움을 겪는다. 이러한 제한 사항을 해결하기 위해 본 논문은 Large Multimodal Model (LMM) (ex. LLaVA)을 명령 기반 편집 모델에 도입했다. 본 논문의 방법인 SmartEdit은 LMM과 diffusion model을 공동으로 최적화하여 LMM의 강력한 추론 능력을 활용하여 명령 기반 이미지 편집 작업을 용이하게 한다.
Diffusion model에서 CLIP 인코더를 LMM으로 대체하면 일부 문제를 완화할 수 있지만 복잡한 추론이 필요한 경우 이 접근 방식은 여전히 부족하다. 이는 편집할 원본 이미지가 간단한 concatenation을 통해 Stable Diffusion의 UNet에 통합되고 cross-attention 연산을 통해 LMM 출력과 추가로 상호 작용하기 때문이다. 이 설정에서는 이미지 feature가 query 역할을 하고 LMM 출력이 key와 value 역할을 한다. 이는 LMM 출력이 일방적으로 변조되고 이미지 feature와 상호 작용하여 결과에 영향을 미친다는 것을 의미한다. 이러한 문제를 완화하기 위해 본 논문은 Bidirectional Interaction Module (BIM)을 추가로 제안하였다. 이 모듈은 입력 이미지에서 LLaVA의 비전 인코더로 추출된 이미지 정보를 재사용한다. 또한 이 이미지와 LMM 출력 간의 포괄적인 양방향 정보 상호 작용을 촉진하여 모델이 복잡한 시나리오에서 더 나은 성능을 발휘할 수 있도록 한다.
기존 명령 기반 편집 방식이 실패하는 두 번째 이유는 전용 데이터가 없다는 점이다. InstructPix2Pix와 MagicBrush에서 사용되는 데이터셋과 같은 편집 데이터셋에 대해서만 학습시킬 때 SmartEdit은 복잡한 추론과 이해가 필요한 시나리오를 처리하는 데 어려움을 겪는다. 이는 SmartEdit이 이러한 시나리오의 데이터에 노출되지 않았기 때문이다. 한 가지 간단한 접근 방식은 해당 시나리오와 유사한 상당한 양의 쌍을 이루는 데이터를 생성하는 것이다. 그러나 이 방법은 데이터 생성 비용이 높기 때문에 비용이 지나치게 많이 든다.
본 논문에서는 복잡한 시나리오를 처리하는 SmartEdit의 능력을 향상시키는 두 가지 열쇠가 있다는 것을 발견했다. 첫 번째는 UNet의 인식 능력을 향상시키는 것이고, 두 번째는 몇 가지 고품질 예제를 통해 해당 시나리오에서 모델 용량을 자극하는 것이다. 이에 따라 인식 관련 데이터(ex. segmentation)를 모델 학습에 통합하고, fine-tuning하기 위해 복잡한 명령과 함께 몇 가지 고품질 쌍 데이터를 합성한다. 이러한 방식으로 SmartEdit은 복잡한 시나리오에서 쌍을 이루는 데이터에 대한 의존도를 줄일 뿐만 아니라 이러한 시나리오를 처리하는 능력을 효과적으로 자극한다.
SmartEdit은 기존 명령 기반 편집 방법의 범위를 뛰어넘어 복잡한 명령도 이해할 수 있다. 저자들은 명령 기반 이미지 편집 방법의 이해 및 추론 능력을 더 잘 평가하기 위해 총 219개의 이미지-텍스트 쌍이 포함된 Reason-Edit 데이터셋을 수집하였다. Reason-Edit 데이터셋과 합성된 학습 데이터 쌍 사이에는 겹치는 부분이 없다. SmartEdit은 Reason-Edit 데이터셋에서 기존 방법들보다 훨씬 뛰어난 성능을 발휘한다.
Method
1. The Framework of SmartEdit
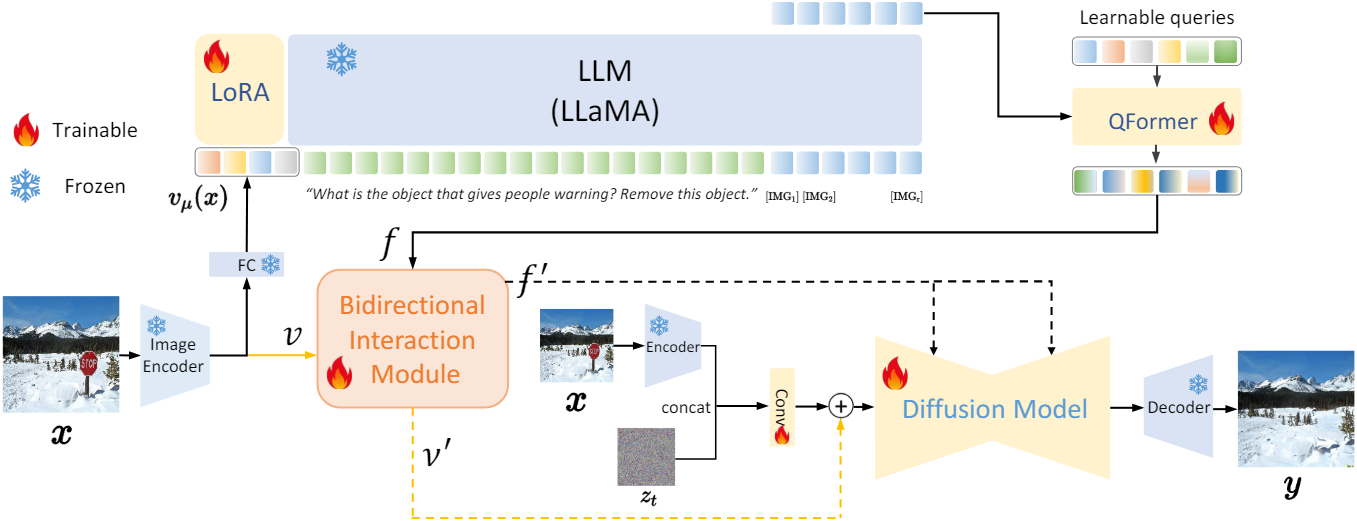
본 논문의 목표는 이미지 $x$와 $(s_1, \ldots, s_T)$로 tokenize된 명령 $c$가 주어지면 $c$를 기반으로 타겟 이미지 $y$를 얻는 것다. 이미지 $x$는 먼저 이미지 인코더와 FC layer에 의해 처리되어 $v_\mu (x)$가 생성된다. 그런 다음 $v_\mu (x)$는 토큰 임베딩 $(s_1, \ldots, s_T)$과 함께 LLM으로 전송된다. LLM의 출력은 discrete한 토큰이므로 후속 모듈의 입력으로 사용할 수 없다. 따라서 discrete한 토큰에 해당하는 hidden state를 다음 모듈의 입력으로 사용한다.
LLaVA와 diffusion model을 공동으로 최적화하기 위해 GILL을 따라 원래 LLM vocabulary를 $r$개의 새 토큰 $[\textrm{IMG}_1], \ldots, [\textrm{IMG}_r]$으로 확장하고 $r$개의 토큰을 명령 $c$의 끝에 추가한다. 구체적으로 학습 가능한 행렬 $\textbf{E}$를 LLM의 임베딩 행렬에 통합하며, 이는 $r$개의 $[\textrm{IMG}]$ 토큰 임베딩을 나타낸다. 그 후, 이전에 생성된 토큰들을 조건으로 생성된 $r$개의 $[\textrm{IMG}]$ 토큰의 negative log-likelihood를 최소화한다.
\[\begin{equation} L_\textrm{LLM} (c) = -\sum_{i=1}^r \log p_{\theta \cup \mathbf{E}} ([\textrm{IMG}_i] \; \vert \; v_\mu (x), s_1, \ldots, s_T, [\textrm{IMG}_1], \ldots, [\textrm{IMG}_{i-1}]) \end{equation}\]LLM의 파라미터 $\theta$는 고정된 상태로 유지되며 LoRA를 활용하여 효율적인 fine-tuning을 수행한다. $r$개의 토큰에 해당하는 hidden state $h$를 다음 모듈의 입력으로 사용한다.
LLM의 hidden state의 feature space와 CLIP 텍스트 인코더 간의 불일치를 고려하여 hidden state $h$를 CLIP 텍스트 인코더 공간에 정렬해야 한다. 6-layer transformer와 $n$개의 학습 가능한 쿼리가 있는 QFormer $Q_\beta$를 채택하여 feature $f$를 얻는다. 그런 다음 이미지 인코더 $E_\phi$에 의해 출력된 이미지 feature $v$는 bidirectional interaction module (BIM)을 통해 $f$와 상호 작용하여 $f^\prime$과 $v^\prime$이 된다.
\[\begin{aligned} h &= \textrm{LLaVA} (x, c) \\ f &= Q_\beta (h) \\ v &= E_\phi (x) \\ f^\prime, v^\prime &= \textrm{BIM} (f, v) \end{aligned}\]Diffusion model의 경우 InstructPix2Pix을 따라 인코딩된 이미지 latent $\mathcal{E}(x)$와 noisy latent $z_t$를 concatentate한다. InstructPix2Pix와 달리 UNet에서 $f^\prime$을 key와 value로 사용하고 residual 방식으로 UNet에 들어가기 전에 $v^\prime$을 feature에 결합한다.
\[\begin{equation} L_\textrm{diffusion} = \mathbb{E}_{\mathcal{E}(y), \mathcal{E}(x), c_T, \epsilon \sim \mathcal{N}(0,1), t} [\| \epsilon - \epsilon_\delta (t, \textrm{Conv}(\textrm{concat} [z_t, \mathcal{E}(x),]) + v^\prime, f^\prime) \|_2^2] \end{equation}\]2. Bidirectional Interaction Module
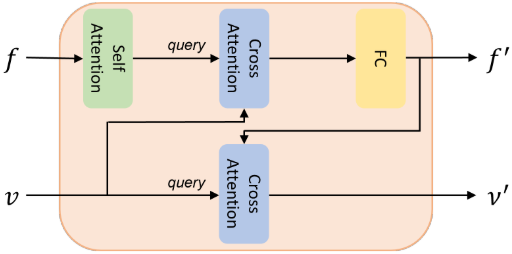
BIM의 디자인은 위 그림과 같다. 여기에는 self-attention block, 두 개의 cross-attention block, MLP layer가 포함된다. BIM의 입력은 QFormer의 출력 $f$와 이미지 인코더의 출력 $v$이다. $f$와 $v$ 사이의 양방향 상호작용 후에 BIM은 $f^\prime$와 $v^\prime$를 출력한다.
먼저 $f$가 self-attention block을 통과한다. 이후 $f$를 query로, 입력 $v$를 key와 value로 하여 cross-attention block을 통과시키고 pointwise MLP를 통해 $f^\prime$이 생성된다. 그런 다음 $v$를 query로, $f^\prime$을 key와 value로 하여 cross-attention block을 통과시켜 $v^\prime$을 생성한다.
BIM 모듈은 이미지 feature를 재사용하여 이를 보충 정보로 UNet에 입력한다. 두 개의 cross-attention block을 통해 이미지 feature와 텍스트 feature 간의 강력한 양방향 정보 상호 작용이 촉진된다.
3. Dataset Utilization Strategy
SmartEdit 학습 시에 InstructPix2Pix와 MagicBrush에서 수집한 데이터셋만 사용하는 경우 두 가지 주요 문제가 발생한다.
- SmartEdit의 위치와 개념에 대한 인식이 좋지 않다.
- LMM을 갖추고 있음에도 불구하고 추론이 필요한 시나리오에서는 SmartEdit의 능력이 여전히 제한적이다.
즉, 기존 편집 데이터셋으로만 학습된 경우 복잡한 시나리오를 처리하는 데 있어 SmartEdit의 효과는 제한된다. 첫 번째 문제는 diffusion model의 UNet에서 인식과 개념에 대한 이해가 부족하여 SmartEdit의 위치와 개념에 대한 잘못된 인식으로 인해 발생한다. 두 번째 문제는 SmartEdit이 추론 능력이 필요한 편집 데이터에 제한적으로 노출되어 발생한다.
첫 번째 문제를 해결하기 위해 segmentation 데이터를 학습 세트에 통합한다. 이러한 수정으로 인해 SmartEdit 모델의 인식 능력이 크게 향상되었다. 두 번째 문제에 관해서는 최소한의 reasoning segmentation 데이터가 LMM의 추론 능력을 효율적으로 활성화할 수 있다는 LISA에서 영감을 얻었다. 저자들은 LISA를 따라 데이터 생성 파이프라인을 구축하고 학습 데이터에 대한 보충 자료로 약 476개의 쌍을 이루는 데이터를 합성하였다. 이 합성 편집 데이터셋에는 복잡한 이해 시나리오와 복잡한 추론 시나리오라는 두 가지 주요 유형의 시나리오가 포함되어 있다. 복잡한 이해 시나리오의 경우 원본 이미지에는 여러 물체가 포함되어 있으며 해당 명령은 다양한 속성 (ex. 위치, 크기, 색상, 거울 안/밖)을 기반으로 특정 물체를 수정한다. 거울 속성은 장면에 대한 깊은 이해가 필요한 전형적인 예이기 때문에 특별히 고려한다. 복잡한 추론 시나리오의 경우 특정 물체를 식별하기 위해 세상에 대한 지식이 필요한 사례를 포함한다.
4. Reason-Edit for Better Evaluation
저자들은 복잡한 이해 및 추론 시나리오에서 기존 방법과 SmartEdit의 능력을 더 잘 평가하기 위해 평가 데이터셋인 Reason-Edit을 수집하였다. Reason-Edit은 219개의 이미지-텍스트 쌍으로 구성되며, 합성된 학습 데이터 쌍과 동일한 방식으로 분류된다. Reason-Edit의 데이터와 학습 세트 사이에는 겹치는 부분이 없다. Reason-Edit을 사용하면 시나리오 이해 및 추론 측면에서 명령 기반 이미지 편집 모델의 성능을 철저하게 테스트할 수 있다.
Experiments
- 데이터셋
- segmentation: COCOStuff, RefCOCO, GRefCOCO
- reasoning segmentation: LISA
- VQA: LLaVA-Instruct-150k
- 편집 데이터셋: InstructPix2Pix, MagicBrush
- 합성된 편집 데이터셋: LISA를 따라 새로 합성한 476개
- 학습 프로세스
- 1단계: QFormer를 사용하여 LMM과 CLIP 텍스트 인코더를 정렬
- 2단계: SmartEdit을 최적화
- 아키텍처
- LLM
- base model: LLaVA-1.1-7b, LLaVA-1.1-13b
- 새로운 토큰 수: 32
- LoRA: dim = 16, alpha = 27
- QFormer: transformer layer 6개, 학습 가능한 쿼리 토큰 77개
- LLM
- 구현 디테일
- optimizer: AdamW
- 1단계: learning rate = $2 \times 10^{-4}$, weight decay = 0
- 2단계: learning rate = $1 \times 10^{-5}$, weight decay = 0.001
- 2단계의 LLM loss와 diffusion loss의 비율은 1:1
- optimizer: AdamW
1. Comparison with State-of-the-Art Methods
다음은 Reason-Edit에서 기존 방법들과 비교한 결과들이다.


2. Ablation Study on BIM
다음은 BIM 모듈에 대한 ablation 결과들이다.


3. Ablation Study on Dataset Usage
다음은 여러 데이터셋을 사용한 공동 학습에 대한 ablation 결과들이다.

