[논문리뷰] Self-correcting LLM-controlled Diffusion Models
CVPR 2024. [Paper] [Page] [Github]
Tsung-Han Wu, Long Lian, Joseph E. Gonzalez, Boyi Li, Trevor Darrell
UC Berkeley
27 Nov 2023

Introduction
Text-to-Image (T2I) 생성은 diffusion model의 출현으로 놀라운 발전을 이루었다. 그러나 이러한 모델은 복잡한 입력 텍스트 프롬프트 (ex. 물체의 개수, 위치 관계)를 해석하는 데 어려움을 겪는 경우가 많다. 모델 크기와 학습 데이터의 놀라운 확장에도 불구하고 이러한 어려움은 여전히 SOTA diffusion model에 존재한다.
여러 연구들은 이러한 한계를 극복하는 것을 목표로 하였다. 예를 들어 DALL-E 3는 학습 프로세스에 중점을 두고 고품질 캡션을 대규모로 학습 데이터에 통합하였다. 그러나 이 접근 방식은 상당한 비용이 발생할 뿐만 아니라 복잡한 사용자 프롬프트에서 정확한 이미지를 생성하는 데 종종 부족하다. 다른 연구들에서는 inference 프로세스에서 프롬프트를 더 잘 이해하기 위해 외부 모델의 힘을 활용하였다. 예를 들어, LLM을 활용하여 텍스트 프롬프트를 구조화된 이미지 레이아웃으로 전처리하여 예비 디자인이 사용자의 지시에 일치하도록 한다. 그러나 이러한 통합은 다운스트림 diffusion model에서 생성된 부정확성을 해결하지 못한다.
저자들은 인간이 그림을 그리는 과정과 diffusion model의 주요 차이점을 관찰하였다. 두 마리의 고양이가 등장하는 장면을 그리는 임무를 맡은 인간 아티스트를 생각해 보자. 아티스트는 요구 사항을 인식하고 작업이 완료되었다고 생각하기 전에 고양이 두 마리가 실제로 존재하는지 확인한다. 아티스트가 고양이 한 마리만 묘사한 경우 프롬프트를 충족하기 위해 고양이 한 마리를 추가할 것이다. 이는 open-loop 기반으로 작동하는 현재의 T2I diffusion model과 크게 대조된다. Diffusion model은 미리 결정된 수의 diffusion step을 통해 이미지를 생성하고 초기 사용자 프롬프트와의 정렬에 관계없이 출력을 사용자에게 제공한다. 학습 데이터 확장이나 LLM 컨디셔닝과 관계없이 이러한 프로세스에는 최종 이미지가 사용자의 기대에 부합하는지 확인하는 강력한 메커니즘이 부족하다.
본 논문은 프롬프트와 생성된 이미지 간의 정렬을 사용자에게 자신있게 제공하기 위해 자체 검사를 수행하는 Self-correcting LLM-controlled Diffusion (SLD)을 제안하였다. SLD는 diffusion model에 오차를 반복적으로 식별하고 수정할 수 있는 능력을 갖춘 새로운 closed-loop 접근 방식이다. SLD 프레임워크에는 LLM 기반 object detection과 LLM 제어 평가 및 수정이라는 두 가지 주요 구성 요소가 포함되어 있다.
먼저 원하는 이미지를 설명하는 텍스트 프롬프트가 주어지면 이미지 생성 모듈을 호출한다. 그런 다음 SLD는 open-vocabulary detector가 확인할 수 있도록 LLM이 파싱한 핵심 문구를 사용하여 이미지를 철저히 평가한다. 그 후, LLM 컨트롤러는 감지된 bounding box와 초기 프롬프트를 입력으로 사용하고 감지 결과와 프롬프트 사이의 잠재적인 불일치를 확인하여 물체 추가, 이동, 제거와 같은 적절한 자체 수정 작업을 제안한다. 마지막으로 SLD는 기본 diffusion model (ex. Stable Diffusion)을 활용하여 latent space 합성을 통해 이러한 수정을 구현함으로써 최종 이미지가 사용자의 텍스트 프롬프트를 정확하게 반영하도록 한다.
본 논문의 파이프라인은 초기 생성 소스에 제한을 두지 않으므로 API를 통해 독점 모델에서 생성된 이미지에도 적용 가능하다. 기본 diffusion model에 대한 추가 학습이 필요 없으므로 외부 주석이나 학습 비용을 들이지 않고도 다양한 diffusion model에 쉽게 적용할 수 있다.
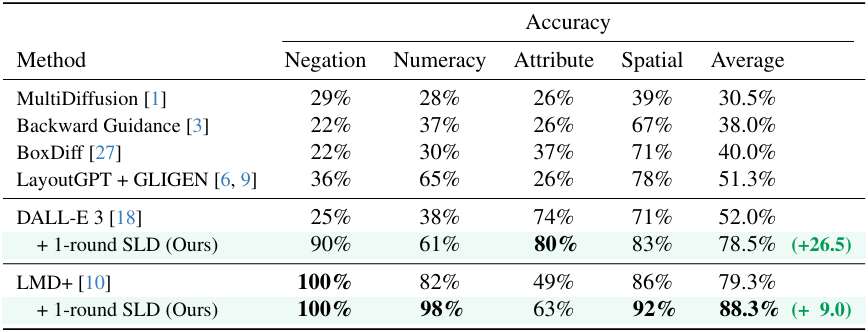
SLD 프레임워크는 이미지 프로세스 생성에서 LLM을 활용하는 LMD+를 9.0% 능가한다. 또한 초기 생성에 DALL-E 3를 사용하면 SLD로 생성된 이미지가 자체 수정 전 이미지에 비해 26.5%의 성능이 향상된다. SLD 파이프라인은 처음 생성된 이미지에 구애받지 않기 때문에 프롬프트를 LLM으로 변경하기만 하면 쉽게 이미지 편집 파이프라인으로 변환할 수 있다. T2I 생성과 이미지 편집은 별개의 task로 처리되는 경우가 많지만 SLD는 통합 파이프라인을 사용하여 이 두 가지 task를 수행할 수 있다.
Method
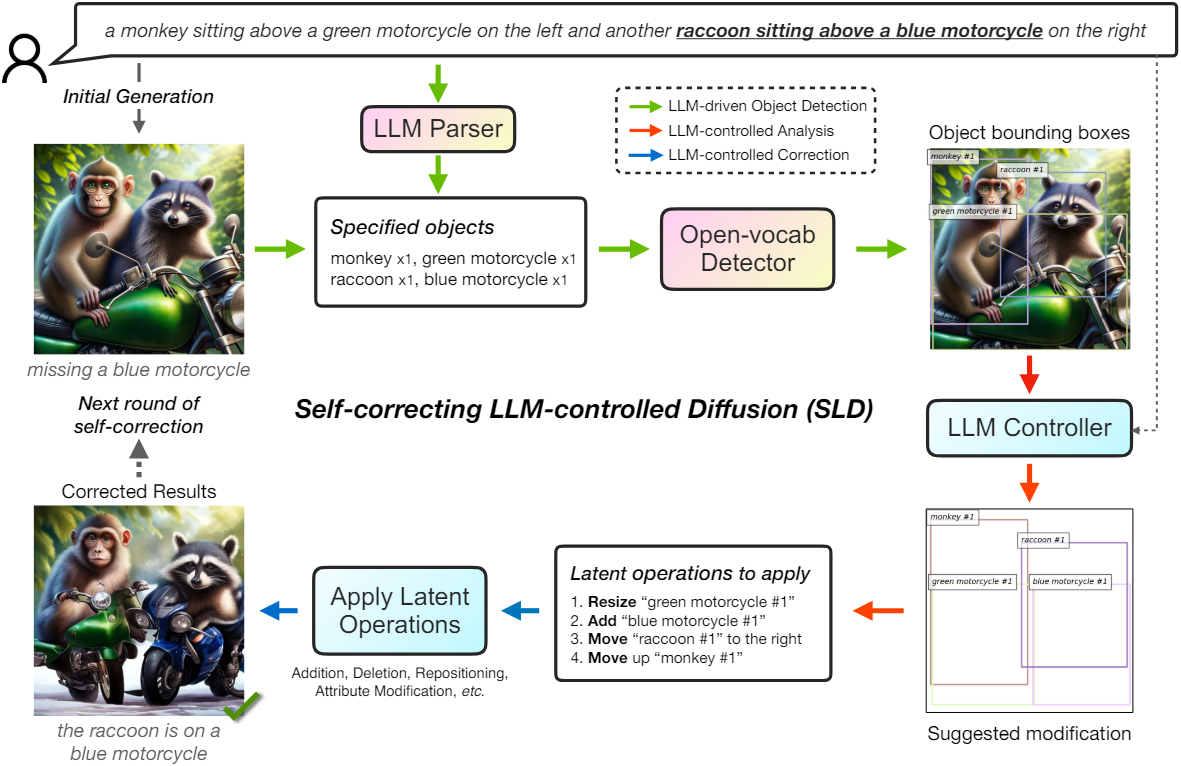

1. LLM-driven Object Detection

SLD 프레임워크는 평가 및 수정에 필요한 정보를 추출하는 LLM 기반 object detection으로 시작된다. LLM 기반 object detection에는 두 단계가 포함된다.
- 프롬프트를 파싱하고 이미지 평가와 잠재적으로 관련이 있는 핵심 문구를 출력하는 parser로 LLM을 활용한다.
- 그런 다음 해당 문구는 open-vocabulary detector로 전달된다. 감지된 bounding box에는 이미지가 프롬프트와 일치하는지 여부를 평가하는 데 도움이 되는 정보가 포함되어 있어야 한다.
첫 번째 단계에서는 LLM parser가 텍스트 프롬프트 $P$에서 주요 물체 디테일의 목록 $S$를 추출한다. LLM parser는 텍스트 명령과 상황에 맞는 예제의 도움을 받아 이를 쉽게 수행할 수 있다. “녹색 오토바이”와 같은 문구가 포함된 사용자 프롬프트의 경우 LLM은 “녹색”을 “오토바이”와 관련된 속성으로 식별하고 출력할 것으로 예상된다. 프롬프트가 “원숭이” 및 “너구리”와 같이 특정 수량이나 속성이 없는 물체를 참조하는 경우 이러한 설명은 적절하게 공백으로 남겨진다. 중요한 점은 LLM의 역할이 단순히 물체 명사를 식별하는 데만 국한되지 않으며, 관련 수량이나 속성을 식별하는 것도 수반된다는 것이다.
두 번째 단계에서는 open-vocabulary detector가 첫 번째 단계에서 파싱한 $S$를 처리하여 이미지 내의 물체를 탐지하고 위치를 파악한다. Open-vocabulary detector에 프롬프트로
image of a/an [attribute] [object name]
를 입력한다. 그런 다음 결과 bounding box인 \(B_\textrm{curr}\)는 추가 처리를 위해
[(“[attribute] [object name] [#object ID]”, [x, y, w, h])]
와 같은 형식으로 구성된다.
특별한 경우는 프롬프트가 물체 수량에 제약을 가하는 경우이다. 속성이 있는 물체가 있는 경우 필요한 수량에 비해 부족한 경우 속성이 지정되지 않은 물체의 추가 개수가 제공되어 속성이 있는 물체를 더 추가할지 아니면 단순히 기존 물체의 속성을 변경할지 여부를 결정하는 후속 LLM 컨트롤러에 대한 컨텍스트를 제공한다.
2. LLM-controlled Analysis and Correction

이미지 분석 및 후속 수정을 위해 LLM 컨트롤러를 사용한다. 프롬프트 $P$와 bounding box \(B_\textrm{curr}\)가 주어지면 컨트롤러는 bounding box의 이미지가 사용자 프롬프트의 설명과 일치하는지 분석하고 수정된 bounding box 목록 \(B_\textrm{next}\)를 제공하도록 요청받는다.
그런 다음 SLD는 개선된 bounding box와 원본 bounding box 간의 불일치를 프로그래밍 방식으로 분석하여 추가, 삭제, 재배치, 속성 수정을 포함하는 일련의 편집 연산 $\textrm{Ops}$를 출력한다. 그러나 단순한 박스 세트 표현은 대응 정보를 전달하지 않으므로 여러 박스가 동일한 물체 이름을 공유하는 경우 LLM 컨트롤러의 입력 및 출력 레이아웃을 쉽게 비교할 수 없다. 대응 관계를 추측하기 위해 각 bounding box에 물체 ID를 부여하고 물체 뒤에 접미사를 추가하여 각 물체 유형 내에서 숫자를 증가시킨다. In-context 예제에서는 제안된 수정 전후에 물체가 동일한 이름과 객체 ID를 가져야 함을 LLM에 보여준다.
Latent Operations for Training-Free Image Correction
LLM 컨트롤러는 적용할 수정 연산의 목록을 출력한다. 각 연산마다 먼저 원본 이미지를 latent feature로 변환한다. 그런 다음 이러한 latent layer들에 적용되는 추가, 삭제, 재배치, 속성 수정과 같은 일련의 연산 $\textrm{Ops}$를 실행한다.
Addition. LLM-grounded Diffusion에서 영감을 받은 추가 연산은 물체를 사전 생성하고 물체의 latent 표현을 원본 이미지의 latent space에 통합하는 두 단계로 구성된다. 처음에는 diffusion model을 사용하여 지정된 bounding box 내에 물체를 만든 다음 SAM을 사용하여 정확한 segmentation을 수행한다. 그런 다음 이 물체는 기본 diffusion model을 사용하여 backward diffusion process를 통해 처리되어 물체에 해당하는 마스킹된 latent layer를 생성하고 나중에 원본 캔버스와 병합된다.
Deletion. 삭제 연산은 SAM이 bounding box 내에서 물체의 경계를 구체화하는 것으로 시작된다. 그런 다음 지정된 영역과 관련된 latent layer가 제거되고 Gaussian noise로 재설정된다. 이를 위해서는 다음 순방향 확산 과정에서 이러한 영역의 완전한 재생이 필요하다.
Repositioning. 재배치 연산에는 원본 이미지를 수정하여 물체를 새 bounding box에 정렬하고 원래 종횡비를 유지하도록 하는 연산이 포함된다. 먼저 이미지 공간의 bounding box를 이동하고 resizing한다. 그 후 SAM은 추가 연산의 접근 방식과 유사하게 관련 latent layer를 생성하기 위해 backward diffusion process을 통해 물체 경계를 개선한다. 삭제된 부분에 해당하는 latent layer는 Gaussian noise로 대체되고 새로 추가된 부분은 최종 이미지에 통합된다. 재배치 시 중요한 고려 사항은 고품질 결과를 유지하기 위해 latent space가 아닌 이미지 공간에서 물체 크기 조정을 수행하는 것이다.
Attribute modification. 먼저 SAM이 bounding box 내의 물체 경계를 구체화한 후 DiffEdit과 같은 속성 수정 방법을 적용한다. 그런 다음 기본 diffusion model은 이미지를 inversion시켜 최종 합성을 위한 일련의 마스킹된 latent layer를 생성한다.
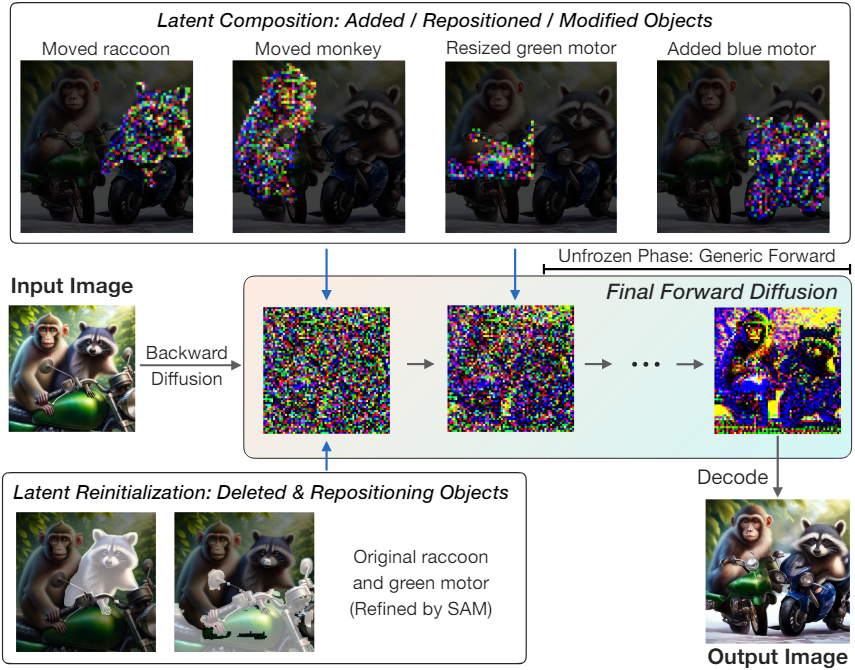
각 물체에 대한 편집 연산 후 위 그림과 같이 재구성 단계로 진행된다. 이 단계에서는 제거되거나 재배치된 영역에 대한 latent는 Gaussian noise로 다시 초기화되고 추가되거나 수정된 latent는 그에 따라 업데이트된다. 여러 개의 물체가 겹치는 영역의 경우 작은 물체의 가시성을 보장하기 위해 더 큰 마스크를 먼저 배치한다.
그런 다음 수정된 latent 스택은 최종 forward diffusion process를 거친다. 처음에는 Gaussian noise로 다시 초기화되지 않은 영역은 고정된다. 즉, 동일한 step에서 수정되지 않은 latent와 강제로 일치된다. 이는 업데이트된 물체를 정확하게 형성하는 동시에 배경 일관성을 유지하는 데 중요하다. 마지막 몇 step에서는 고정하지 않고 모두를 변경하여 시각적으로 일관되고 올바른 이미지를 만든다.
Termination of the Self-Correction Process
한 번의 생성 라운드는 종종 충분하지만, 추가 라운드는 여전히 정확성 측면에서 성능에 더 많은 이점을 제공하여 자체 수정을 반복 프로세스로 만들 수 있다.
최적의 자체 수정 라운드 수를 결정하는 것은 효율성과 정확성의 균형을 유지하는 데 중요하다. 합리적인 시간 내에 프로세스가 완료되도록 수정 라운드에 대한 최대 시도 횟수를 설정한다.
LLM 컨트롤러(\(B_\textrm{next}\))가 제안한 bounding box가 현재 감지된 bounding box(\(B_\textrm{curr}\))와 일치하는 경우, 또는 최대 생성 라운드에 도달하면 프로세스가 완료된다. 이 반복 프로세스는 detector와 LLM 컨트롤러의 정확성에 따라 이미지의 정확성에 대한 보장을 제공하며, 초기 텍스트 프롬프트와 긴밀하게 일치하도록 보장한다.
3. Unified text-to-image generation and editing
SLD 프레임워크는 자체 수정 이미지 생성 모델 외에도 최소한의 수정만으로 이미지 편집에 쉽게 적용할 수 있다. 주요 차이점은 입력 프롬프트 형식이다. 사용자가 장면 설명을 제공하는 이미지 생성과 달리, 이미지 편집에서는 사용자가 원본 이미지와 원하는 변경 사항을 모두 자세히 설명해야 한다.
편집 과정은 자체 수정 메커니즘과 유사하다. LLM parser는 사용자 프롬프트에서 주요 물체를 추출한다. 그런 다음 이러한 물체는 open-vocabulary detector에 의해 식별되어 현재 bounding box 목록을 설정한다. 편집 중심 LLM 컨트롤러는 이러한 입력을 분석한다. LLM 컨트롤러는 정확한 이미지 조작을 위해 업데이트된 bounding box와 해당 latent space 연산을 제안한다.
세부적인 물체 수준 편집을 수행하는 SLD는 주로 글로벌 이미지 스타일 변경을 다루는 기존 diffusion 기반 방법과 구별된다. 또한 SLD는 정확한 제어를 통해 포괄적인 물체 재배치, 추가, 삭제를 가능하게 함으로써 물체 교체 또는 속성 조정으로 제한되는 기존 도구보다 성능이 뛰어나다.
Experiments
1. Comparison with Image Generation Methods
다음은 SLD를 사용하여 다양한 diffusion 기반 생성 방법들의 T2I 정렬을 향상시킨 결과이다.

2. Application to Image Editing
다음은 명령을 통해 이미지를 편집하는 방법들과 편집 결과를 비교한 것이다.

다음은 다양한 이미지 편집 결과들이다.

3. Discussion
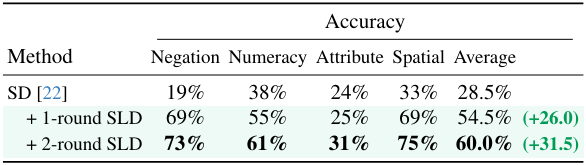
다음은 2번의 SLD로 수정한 결과를 한 번의 SLD로 수정한 결과와 비교한 표이다. 일반적으로 한 번의 SLD로도 대부분이 수정되지만 여러번 SLD를 사용하면 더 결과가 좋아진다.
Limitations

SLD는 SAM 모듈이 의도치 않게 인접한 부분을 분할할 수 있기 때문에 복잡한 모양의 물체를 처리하는 데 어려움을 겪는다.