[논문리뷰] SinFusion: Training Diffusion Models on a Single Image or Video
ICML 2023. [Paper] [Page] [Github]
JYaniv Nikankin, Niv Haim, Michal Irani
Weizmann Institute of Science, Rehovot, Israel
21 Nov 2022

Introduction
최근까지 GAN은 StyleGAN, BigGAN 등과 같은 주요 연구로 생성 모델 분야를 지배했다. Diffusion model (DM)은 지난 몇 년 동안 이미지 품질과 다양성 면에서 GAN을 능가하고 text-to-image 생성, super-resolution 등과 같은 많은 vision task에서 선도적인 방법이다. 또한 최근 연구들은 동영상 생성과 text-to-video 생성을 위한 DM의 효과를 보여주었다.
DM은 대규모 데이터셋에서 학습하기 때문에 이러한 모델은 매우 크고 리소스가 많이 필요하다. DM의 능력을 적용하여 사용자가 제공한 특정 입력을 편집하거나 조작하는 것은 사소한 일이 아니며 신중한 조작과 fine-tuning이 필요하다.
본 논문은 단일 입력 이미지 또는 동영성에서 diffusion model을 학습시키기 위한 프레임워크인 SinFusion을 제안한다. 이미지 합성에서 DM의 성공과 고품질을 단일 이미지/동영상 task에 활용한다. 학습을 마치면 SinFusion은 원래 입력과 유사한 모양과 역동성을 가진 새로운 이미지/동영상 샘플을 생성하고 다양한 편집 및 조작 task를 수행할 수 있다. 동영상의 경우 SinFusion은 입력 동영상을 먼 미래(또는 과거)로 일관되게 extrapolate하여 인상적인 일반화 기능을 보여준다. 이것은 매우 적은 수의 프레임(대부분 24~36개, 그러나 더 적은 수의 프레임에서 이미 명백함)에서 학습된다.
다음을 포함하여 다양한 단일 동영상 task에 SinFusion을 적용할 수 있다.
- 단일 입력 동영상에서 다양한 새로운 동영상 생성 (기존 방법보다 우수함)
- 동영상 extrapolation (외삽)
- 동영상 upsampling
또한 대규모 동영상 데이터셋에서 학습된 동영상 생성을 위한 대규모 diffusion model은 실제 입력 동영상을 조작하도록 설계되지 않았다. 단일 입력 이미지에 적용할 경우 SinFusion은 다양한 이미지 생성 및 조작 작업을 수행할 수 있다. 그러나 본 논문은 단일 동영상 생성/조작 task에 주로 집중하였으며, 이는 더 어렵고 덜 탐구된 영역이기 때문이다.
본 논문의 프레임워크는 일반적으로 사용되는 DDPM 아키텍처 위에 구축되지만 단일 이미지/동영상에서 학습할 수 있도록 하는 데 필수적인 몇 가지 중요한 수정 사항을 도입한다. Backbone DDPM 네트워크는 fully convolutional이므로 원하는 출력 크기의 noise 이미지에서 시작하여 모든 크기의 이미지를 생성하는 데 사용할 수 있다. 본 논문의 단일 동영상 DDPM은 3개의 단일 이미지 DDPM으로 구성되며, 각각은 unconditional하게 또는 입력 동영상의 다른 프레임에 따라 이미지의 large crop(동영상 프레임)에 noise를 매핑하도록 학습되었다.
Single Image DDPM
단일 입력 이미지가 주어지면 모델이 입력 이미지와 모양 및 구조가 유사하지만 의미론적으로 일관된 변형을 허용하는 새로운 다양한 샘플을 생성하는 것이 목표이다. 일반적인 DDPM 프레임워크를 기반으로 하고 학습 절차와 DDPM의 핵심 네트워크에 몇 가지 수정 사항을 도입한다.
Training on Large Crops

대규모 이미지 컬렉션에 대한 학습 대신 위 그림과 같이 입력 이미지 (일반적으로 원본 이미지 크기의 약 95%)에서 대규모의 random crop에 대해 단일 diffusion model을 학습한다. 저자들은 이미지의 원래 해상도에 대한 학습이 multi-scale pyramid를 사용하지 않고도 다양한 이미지 샘플을 생성하기에 충분하다는 것을 발견했다. Large crop에 대한 학습을 통해 생성된 출력은 입력 이미지의 글로벌한 구조를 유지한다.
Network Architecture
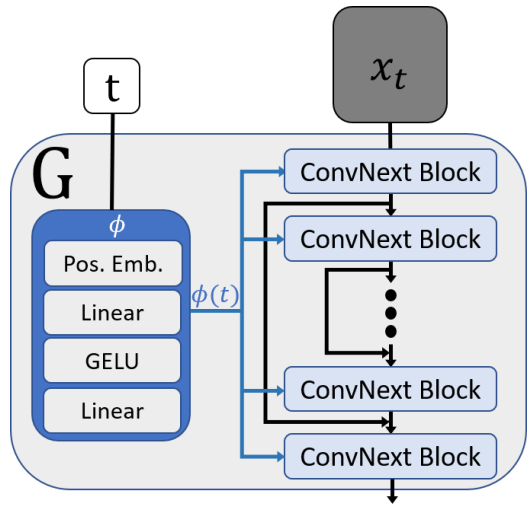
단일 이미지 또는 large crop에서 표준 DDPM을 직접 학습시키면 “overfitting”이 발생한다. 즉, 모델은 동일한 이미지 crop만 생성한다. 저자들은 DDPM에서 핵심 backbone network의 receptive field가 전체 입력 이미지이기 때문에 이러한 현상이 발생한다고 가정한다. 이를 위해 receptive field의 크기를 줄이기 위해 DDPM의 backbone UNet network를 수정한다. 글로벌한 receptive field가 있으므로 attention layer를 제거한다. 또한 receptive field가 너무 빠르게 커지는 downsampling 및 upsampling layer를 제거한다.
Attention layer를 제거하면 원치 않는 부작용이 발생하여 diffusion model의 성능이 저하된다. ConvNext 논문은 많은 vision task에서 attention mechanism과 일치하는 fully convolutional network를 제안했다. 이 아이디어에 영감을 받아 네트워크의 ResNet 블록을 ConvNext block으로 대체한다. 이 아키텍처 선택은 non-global receptive field를 유지하면서 attention layer의 기능을 대체하기 위한 것이다. 계산 시간을 단축할 수 있는 장점도 있다. 그런 다음 네트워크의 전체 receptive field는 네트워크의 ConvNext 블록 수에 따라 결정된다. ConvNext block의 수를 변경하면 출력 샘플의 다양성을 제어할 수 있다. Diffusion timestep $t$를 모델에 통합하는 데 사용되는 임베딩 네트워크($\phi$)를 포함한 backbone network의 나머지 부분은 DDPM과 유사하다.
Loss
각 학습 step에서 noisy한 이미지 crop $x_t$가 모델에 주어진다. 한편, 추가된 noise를 예측하는 DDPM과 다르게 본 논문의 모델은 깨끗한 이미지 crop \(\tilde{x}_{0, \theta}\)을 예측한다. 단일 이미지 DDPM의 loss는 다음과 같다.
\[\begin{equation} L (\theta) = \mathbb{E}_{x_0, \epsilon} [\| x_0 - \tilde{x}_{0, \theta} (x_t, t) \|^2] \end{equation}\]저자들은 noise 대신 이미지를 예측하는 것이 단일 이미지로 학습할 때 품질과 학습 시간 모두에서 더 나은 결과를 가져온다는 것을 발견했다. 저자들은 이 차이가 큰 이미지 데이터셋의 데이터 분포와 비교하여 단일 이미지의 데이터 분포가 단순하기 때문이라고 생각한다. 전체 학습 알고리즘은 다음과 같다.

본 논문의 단일 이미지 DDPM은 다양한 생성, 스케치에서 생성, 이미지 편집과 같은 다양한 이미지 합성 task에 사용할 수 있다.
Single Video DDPM
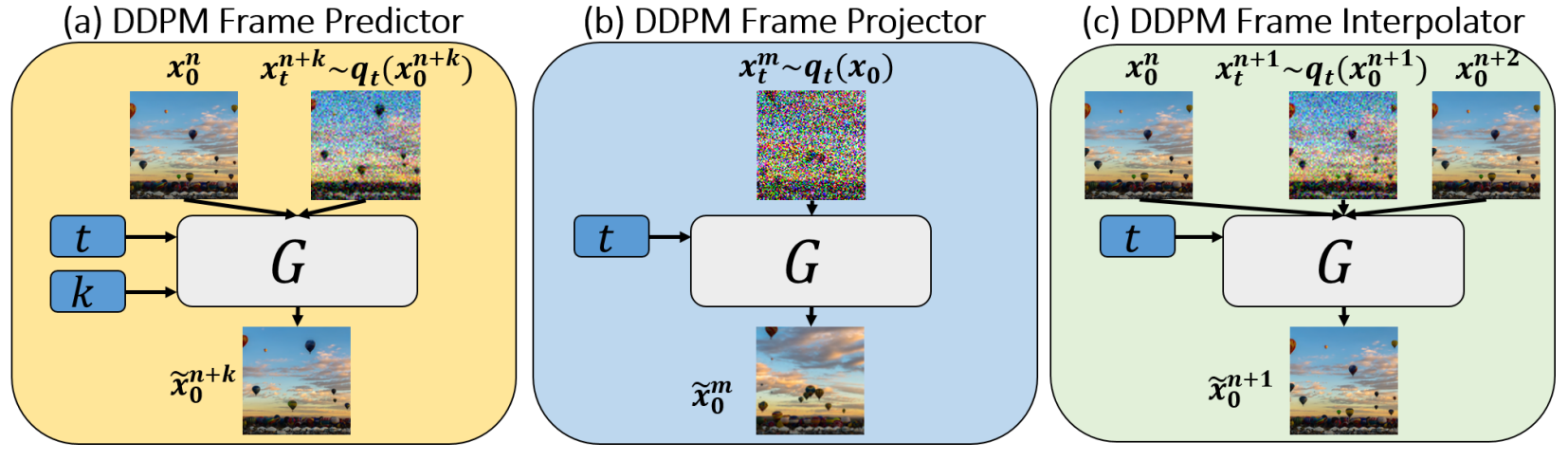
위 그림과 같이 동영상 생성 프레임워크는 3개의 단일 이미지 DDPM 모델로 구성되며, 이 모델의 조합은 다양한 동영상 관련 애플리케이션을 생성한다. 이 프레임워크는 기본적으로 autoregressive 동영상 generator이다.
프레임이 \(\{x_0^1, x_0^2, \cdots, x_0^N\}\)인 입력 동영상이 주어지면 프레임이 \(\{\tilde{x}_0^1, \tilde{x}_0^2, \cdots, \tilde{x}_0^M\}\)인 새로운 동영상을 생성하며, 각 새로운 생성된 프레임 \(\tilde{x}_0^{n+1}\)은 이전 프레임 \(\tilde{x}_0^n\)을 조건으로 한다. 프레임워크를 구성하는 세 가지 모델은 모두 앞서 설명한 것과 동일한 네트워크 아키텍처를 사용하는 단일 이미지 DDPM 모델이다. 모델은 개별적으로 학습되며 주어진 입력 유형과 전체 생성 프레임워크에서의 역할에 따라 다르다. Inference는 응용 프로그램에 따라 다르다.
(a) DDPM Frame Predictor
Predictor model의 역할은 이전 프레임을 조건으로 새로운 프레임을 생성하는 것이다. 각 학습 iteration에서는 동영상 $x_0^n$의 조건 프레임과 $(n+k)$번째 프레임 $(x_t^{n+k})$의 noisy한 버전을 샘플링하여 denoise한다. 두 프레임은 모델에 전달되기 전에 채널 축을 따라 concat된다.
모델에는 두 프레임 사이의 시간적 차이 (즉, 프레임 인덱스 차이)의 임베딩 $\phi (k)$도 제공된다. 이 임베딩은 DDPM의 timestep 임베딩 $\phi(t)$에 concat된다. 학습 초기에는 $k = 1$이고 다음 iteration에서는 $k \in [-3, 3]$에서 랜덤하게 샘플링되도록 점진적으로 증가한다. 저자들은 이 커리큘럼 학습 방식이 출력 품질을 향상시킨다는 것을 발견했다 (inference $k = 1$인 경우에도).
(b) DDPM Frame Projector
Projector model의 역할은 Predictor에서 생성된 프레임을 수정하는 것이다. Projector는 간단한 단일 이미지 DDPM이며 동영상의 모든 프레임에서 이미지 crop에 대해서만 학습된다. 동영상 프레임의 이미지 구조와 모양을 학습한 후 생성된 프레임의 작은 아티팩트를 수정하는 데 사용되며, 그렇지 않으면 작은 아티팩트들이 축적되어 동영상 생성 프로세스를 파괴할 수 있다. 직관적으로, 생성된 프레임에서 원래 패치 분포로 다시 패치를 “project”하므로 projector라 부른다. Projector는 첫번째 프레임을 생성하는 데에도 사용된다. Inference에서 프레임 수정은 예측된 프레임에서의 truncated diffusion process를 통해 수행된다.
(c) DDPM Frame Interpolator
본 논문의 동영상 전용 DDPM 프레임워크는 생성된 동영상의 시간적 해상도를 높이기 위해 추가로 학습될 수 있으며, 이를 “동영상 upsampling” 또는 “프레임 보간”이라고도 한다. DDPM Frame Interpolator는 컨디셔닝으로 한 쌍의 깨끗한 프레임 $(x_0^n, x_0^{n+1})과 그 사이에 있는 프레임의 noisy한 버전 $(x_t^{n+1})$을 입력으로 받는다. 프레임은 채널 축을 따라 concat되고 모델은 보간된 프레임의 깨끗한 버전 \((\tilde{x}_0^{n+1})\)을 예측하도록 학습된다. 저자들은 이 보간이 동영상의 작은 움직임에 잘 일반화되고 두 개의 연속 프레임 사이에 보간하는 데 사용할 수 있으므로 생성된 동영상과 입력 동영상의 시간 해상도를 증가시키는 데 사용할 수 있음을 발견했다.
Losses
저자들은 일부 모델이 다른 loss에서 더 잘 작동한다는 것을 발견했다. Projector와 Interpolator는 깨끗한 이미지를 예측하는 loss로 학습되고, Predictor는 noise를 예측하는 loss로 학습된다.
Applications
Diverse Video Generation
출력 샘플이 원본 입력 동영상과 유사한 모양, 구조, 동작을 갖도록 단일 입력 동영상에서 길이에 관계없이 다양한 동영상을 생성할 수 있다. 이는 Predictor와 Projector 모델을 결합하여 수행된다. 첫 번째 프레임은 원본 동영상의 일부 프레임이거나 unconditional Projector에서 생성된 출력 이미지다. 그런 다음 Predictor는 이전에 생성된 프레임에 따라 다음 프레임을 생성하는 데 사용된다. 다음으로, 예측된 프레임이 프로젝터에 의해 수정된다. 이는 생성되었을 수 있는 작은 아티팩트를 제거하여 시간이 지남에 따라 오차가 누적되는 것을 방지하기 위함이다. 이 프로세스는 원하는 수의 프레임이 생성될 때까지 반복된다. 이 autoregressive 생성 프로세스를 반복하면 임의 길이의 새로운 동영상이 생성된다. 프로세스는 본질적으로 확률적이다. 초기 프레임이 동일하더라도 서로 다른 생성된 출력이 빠르게 분기되어 서로 다른 동영상을 생성한다.
Video Extrapolation
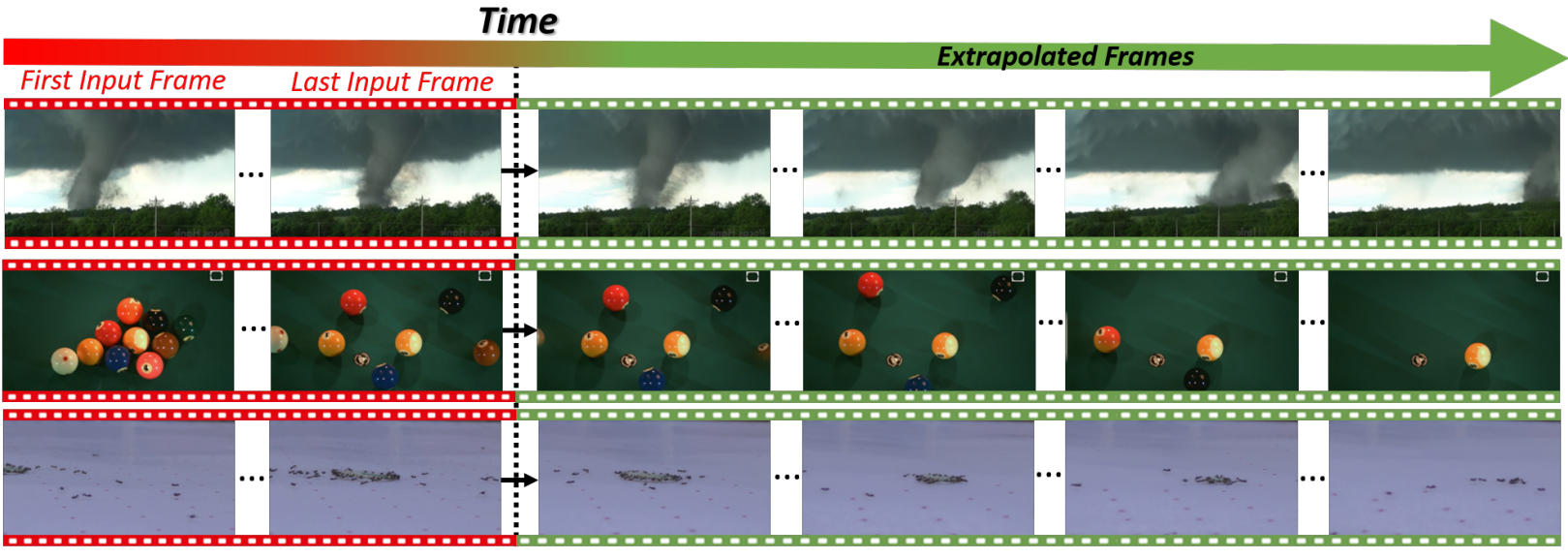
입력 동영상이 주어지면 위에서 설명한 생성 프로세스를 입력 동영상의 마지막 프레임으로 초기화하여 미래 프레임을 예측할 수 있다. 위 그림은 그러한 몇 가지 예를 보여준다. 기존의 단일 동영상 생성 방법은 시간에 따라 동영상을 추정할 수 없다. 또한 Predictor는 시간적으로 역방향으로 학습되기 때문에 (음의 $k$를 사용하여 이전 프레임을 예측) 동영상의 첫 번째 프레임에서 시작하여 동영상을 역방향으로 추정할 수도 있다 (과거 예측). 예를 들어 날아가는 풍선이 착륙하는 동영상을 생성할 수 있으며, 이는 원래 동영상에서는 관찰되지 않은 동작이다. 이는 프레임워크의 일반화 능력을 직접적으로 보여준다.
Temporal Upsampling
SinFusion은 입력 동영상을 추정할 수 있을 뿐만 아니라 원본 동영상 사이에 새 프레임을 생성하여 보간할 수도 있다. 이것은 DDPM Frame Interpolator를 학습시켜 2개의 인접 프레임에서 각 프레임을 예측하고 inference에서 이를 적용하여 연속 프레임 사이를 보간함으로써 수행된다. 보간된 프레임의 모양은 DDPM Frame Projector에 의해 수정된다.
Single-Image Applications
단일 입력 이미지에서 단일 이미지 DDPM을 학습시킬 때 프레임워크는 다양한 이미지 생성, 스케치 기반 이미지 생성, 이미지 편집 등의 표준 단일 이미지 생성과 조작 task로 축소된다. 다양한 이미지 생성은 noisy한 이미지 $x_T \sim \mathcal{N}(0,I)$를 샘플링하고 $x_{t−1} = G(x_t)$와 같은 학습된 모델을 사용하여 반복적으로 denoise함으로써 수행된다. Backbone DDPM network는 fully convolutional이기 때문에 원하는 크기의 noisy한 이미지에서 시작하여 모든 크기의 이미지를 생성하는 데 사용할 수 있다.
또한 SinFusion은 이미지의 위치 간에 crop을 coarse하게 이동하여 입력 이미지를 편집한 다음 모델이 이미지를 수정하도록 할 수 있다. 유사하게 스케치를 그리고 모델이 입력 이미지의 유사한 디테일로 스케치를 채우도록 할 수 있다. 모델은 이미지에 noise를 추가한 다음 일관된 이미지를 얻을 때까지 입력 이미지의 noise를 제거하여 편집된 이미지/스케치에 적용된다.
아래 그림은 이러한 결과들을 보여준다.

Evaluations & Comparisons
1. Future-Frame Prediction from a Single Video
$N$ 프레임의 동영상이 주어지면 $n < N$ 프레임을 사용하여 모델을 학습시킨다. Inference에서는 나머지 $N-n$ 프레임에서 100 프레임을 샘플링하고, 각 프레임에 대해 학습된 모델로 다음 프레임 예측하도록 하였다. 예측된 프레임과 실제 프레임을 비교하기 위해 저자들은 PSNR을 사용하였으며, 각 프레임에 대한 PSNR에 평균을 취하여 전체 점수로 사용하였다.
단일 동영상에서의 프레임 예측을 위한 다른 방법이 없기 때문에 본 논문은 간단하지만 강력한 baseline을 사용하였다. 프레임 $f(i)$가 주어지면 다음 프레임을 동일하게 예측하는 것으로, 식으로 표현하면 $f(i+1) = f(i)$다. 대부분의 동영상이 정적인 배경을 가지고 있고 연속된 두 프레임 사이의 변화가 적기 때문에 강한 baseline이라고 할 수 있다.
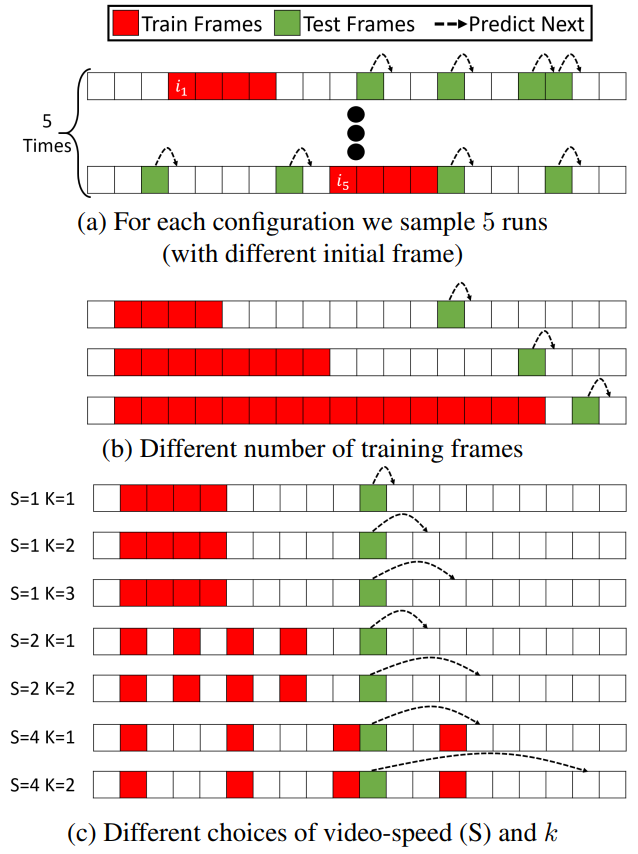
저자들은 다양한 학습 프레임 수 $n = 4, 8, 16, 32, 64$에 대한 실험을 진행하였다. 각 $n$에 대하여 동영상의 랜덤한 프레임으로부터 $n$개의 프레임으로 모델을 학습시켰다. 위 그림의 (a)에서 이를 묘사하고 있다. 학습 프레임은 빨간색이고 테스트 프레임은 초록색으로 표현되었다. 위 그림의 (b)는 다양한 $n$에 대한 실험을 묘사한 것이다.
저자들은 얼마나 본 논문의 프레임워크가 빠른 동작을 가진 동영상을 일반화할 수 있는지 평가하였다. 이를 위해 원본 동영상을 특정 간격으로 샘플링하여 학습하였으며, 이 방법으로 더 빠른 속도의 동영상으로 합성하여 실험할 수 있다. 이 실험에서는 $n$을 32로 고정하였다.
동영상의 속도가 $S$라는 것은 원본 동영상을 $S$만큼의 간격으로 샘플링하여 학습했다는 것이며, $i$번째 프레임을 선택하였다면 $i+S$번째 프레임을 선택하는 것을 의미한다. $k$는 현재 프레임과 예측된 프레임 사이의 차이이며, 본 논문의 모델은 $k = [-3, 3]$에서 학습되었다. 위 그림의 (c)에서 $S$와 $k$에 대한 다양한 예시가 묘사되어있다.
다음은 다음 프레임 예측에 대한 실험 결과를 나타낸 그래프이다.
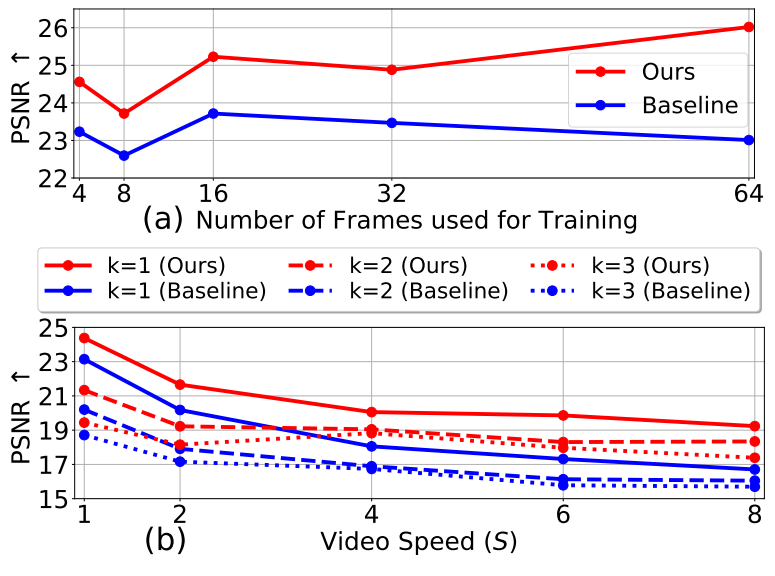
SinFusion은 일관되게 baseline의 성능을 뛰어넘는다.
2. A New Diversity Metric for Single-Video Methods
본 논문에서는 생성된 샘플들의 다양성을 정량적으로 측정하기 위해 nearest-neighbor-field (NNF)를 도입하였다.
NNF는 생성된 동영상에서 각 (3, 3, 3)의 시공간적 패치에 대하여 원본 동영상에서 nearest-neighbor 패치를 찾아 계산된다. 각 voxel은 해당 nearest-neighbor를 가리키는 벡터와 연결된다. 단순하게 생성된 동영상은 다소 일정한 NNF를 갖는 반면, 더 복잡하게 생성된 동영상은 복잡한 NNF를 갖는다. NNF에 대한 시각화된 예는 아래와 같다. (각 벡터는 color wheel을 사용하여 RGB로 변환)

VGPNN 출력의 NNF는 단순하지만 SinFusion으 경우 NNF가 복잡하다.
NNF의 복잡도를 정량화하기 위하여 ZLIB를 사용하여 NNF를 압축하고 압축 비율을 기록한다. 이를 NNFDIV라 부르며 다양성의 척도로 사용할 수 있다. 또한 생성된 패치들과 nearest-neighbor 사이의 MSE를 측정하고 평균을 취해 RGB 유사성을 측정하였으며, 이를 NNFDIST라고 부른다.
다음 표는 동영상 생성의 다양성을 비교한 표이다.
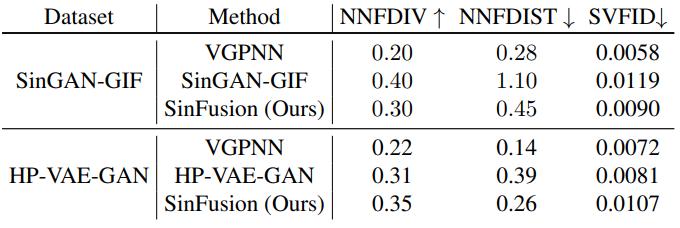
VGPNN은 원본 동영상에서 프레임들을 복사하기 때문에 더 나은 품질 (낮은 NNFDIST와 SVFID)이 기대된다. 반면 VGPNN의 다양성(NNFDIV)은 매우 낮다. HP-VAR-GAN 데이터셋에서는 HP-VAR-GAN보다 품질과 다양성 모두 우수하였다. SinGAN-GIF 데이터셋에서는 SinGAN-GIF의 다양성이 높았지만 품질이 매우 낮았다. 두 데이터셋 모두에서 SinFusion은 다양성과 품질에 대한 최고의 trade-off를 보여주었다.
Limitations
모든 단일 동영상 생성 방법과 마찬가지로 SinFusion도 상대적으로 카메라 움직임이 적은 동영상로 제한된다. 또한 움직임이 매우 강하지 않은 큰 개체 (ex. 움직이는 부분이 많음)가 포함된 동영상에서 SinFusion은 개체를 부수거나 일부를 제거할 수 있다. 이는 SinFusion에는 semantic 개념이 없기 때문이다. 이러한 제한 중 일부는 적절한 prior을 통합하여 완화할 수 있을 것으로 예상된다.