[논문리뷰] SimpSON: Simplifying Photo Cleanup with Single-Click Distracting Object Segmentation Network
CVPR 2023. [Paper] [Page] [Github]
Chuong Huynh, Yuqian Zhou, Zhe Lin, Connelly Barnes, Eli Shechtman, Sohrab Amirghodsi, Abhinav Shrivastava
University of Maryland, College Park | Adobe Research
28 May 2023

Introduction
이미지 품질을 향상시키기 위해 효율적인 사진 수정이 필요한 경우, 필수적인 측면 중 하나는 사진에서 시각적 방해 요소를 제거하는 것이다. 이러한 방해 요소는 예상치 못한 보행자, 사진 가장자리에서 잘려진 물체, 바닥의 더러운 부분, 벽에 반복적으로 나타나는 콘센트, 다채롭고 흐릿한 렌즈 플레어 등 다양한 형태로 나타날 수 있다. 이러한 방해 요소는 모양이 다양하기 때문에 분류하기가 어려울 수 있다. 이로 인해 사용자들은 이를 선택해 완전히 마스크 처리한 뒤 포토샵 등 사진 편집 소프트웨어를 이용해 제거하는 경향이 있다.
대략적인 마스크가 모든 시나리오에 적합하지 않을 수 있으므로 segmentation이 필요하다. 방해 요소가 주요 전경 피사체에 닿거나 작지만 이미지에서 밀도가 높은 상황에서는 정확한 마스크가 필요하다. 사용자가 그린 러프한 마스크는 배경 텍스처가 너무 많이 삭제될 수 있다. 또한 전체 개체를 덮지만 배경을 너무 많이 변경하지 않는 마스크를 가질 수도 있다. 모든 시나리오에서 인페인팅의 경우 매우 정확한 마스크의 작은 팽창이 배경 보존을 향상시키고 방해 요소의 남은 픽셀 수를 줄인다. 이 발견은 대부분의 기존 인페인팅 모델과 일치한다.
사진에서 방해가 되는 요소를 수동으로 마스킹하는 과정은 지루하고 시간이 많이 걸리는 작업이 될 수 있다. 사용자는 모든 방해 요소를 효율적으로 선택하고 분류할 수 있는 자동화된 도구를 찾는 경우가 많다. 한 가지 접근 방식은 Mask-RCNN과 같은 instance segmentation 모델을 학습시켜 supervised 방식으로 방해 요소를 감지하고 분할하는 것이다. 그러나 선택 항목을 식별하는 것은 주관적일 수 있으며 데이터셋을 수집하려면 대부분의 사용자가 동의하는지 확인하기 위해 선택 항목 주석에 대한 과학적 검증이 필요하다. 방해 요소를 감지하는 모델이 있더라도 사용자의 선호도를 항상 만족시키지 못할 수도 있다. 따라서 이와 같은 작업은 사용자가 자신의 선호도에 따라 사진을 수정할 위치를 클릭하고 결정할 수 있도록 하는 등 사용자 상호 작용에 크게 의존해야 한다.
본 논문의 목표는 한 번의 클릭으로 방해 요소를 분할하는 모델을 제안하는 것이다. PanopticFCN과 Mask2Former와 같은 panoptic segmentation SOTA 모델을 활용하여 panoptic segmentation 결과를 클릭하여 방해 마스크를 검색할 수 있을까? 아쉽게도 대부분의 선택 항목은 알 수 없는 카테고리에 속하고 일부는 작기 때문에 카테고리가 closed set인 COCO, ADE20K, Cityscapes와 같은 데이터셋에서 학습된 모델을 사용하여 분할하기가 어렵다. 롱테일 문제를 해결하기 위해 클래스에 구애받지 않는 방식으로 panoptic segmentation을 학습시키기 위해서 entity segmentation이 제안되었지만 여전히 사진의 모든 영역을 분리한다고 보장할 수는 없다.
Segmentation을 위한 입력 guidance로 클릭을 사용하면 어떻게 될까? Interactive segmentation 모델은 본 논문의 task와 밀접하게 관련되어 있으며 FocalClick, RiTM과 같은 최근 연구들은 실용적이고 정밀한 segmentation 성능을 달성했다. 그러나 interactive segmentation은 positive click과 negative click을 포함한 여러 번의 클릭을 사용하여 더 큰 전경 개체, 특히 경계 영역을 정확하게 분할하는 것을 목표로 한다. 본 논문에서는 중소형의 방해 요소에 더 초점을 맞추고 인페인팅 목적으로 정밀한 마스크를 선택하려면 단 한 번의 positive click만 필요하다. 목표의 차이로 인해 interactive segmentation의 문제 정의를 따르는 것이 어렵다. 또한 이전의 interactive segmentation 모델은 그룹으로 개체를 선택할 수 없는 반면, 대부분의 방해 요소는 반복적이고 밀도가 높으며 사진 전체에 고르게 분포되어 있다.
본 논문은 정확한 원클릭 segmentation과 효율적인 유사도 선택이라는 2가지 과제를 해결한다. 본 논문이 제안한 방법은 조밀하고 작은 방해 요소를 제거할 때 사진 리터칭 프로세스를 몇 시간 (ex. 100회 이상의 클릭)에서 몇 분(ex. 1-2 클릭)으로 크게 줄일 수 있다. 먼저, 클릭 기반 segmentation 모델을 최적화하여 원클릭으로 방해 요소와 유사한 개체를 정확하게 분할한다. 이는 entity segmentation 방법을 활용하여 카테고리 레이블을 삭제하고 single-click 임베딩을 사용하여 단일 개체의 segmentation을 가이드함으로써 달성된다. 그런 다음 동일한 이미지 내에서 유사한 방해 요소와 유사한 개체를 마이닝하고 이에 대한 클릭 위치를 회귀하는 transformer 기반 Click Proposal Network (CPN)를 디자인한다. 마지막으로 제안된 클릭을 사용하여 single-click segmentation 모듈을 다시 실행하여 마스크를 생성하고 Proposal Verification Module (PVM)을 통해 선택한 개체 간의 유사도를 확인한다. 또한 더 많은 유사한 개체가 완전히 선택되었는지 확인하기 위해 프로세스를 반복적으로 실행한다.
Methodology: SimpSON
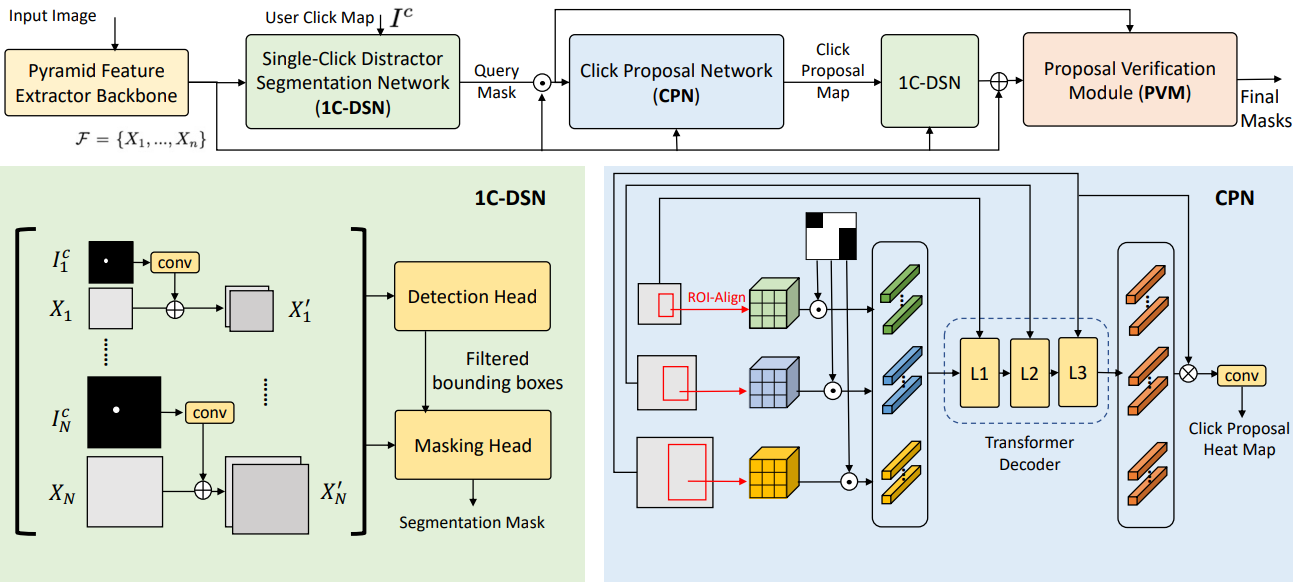
위 그림은 SimpSON의 전체 파이프라인을 보여준다. Feature 추출 backbone, 모든 유사한 클릭을 마이닝하는 Single-Click Distractor Segmentation Network (1CDSN), Click Proposal Network (CPN), 유사성을 확인하는 Proposal Verification Module (PVM)으로 구성된다. 프로세스는 반복적으로 실행될 수 있다.
1. One-click Distractor Segmentation Network (1C-DSN)
동기
사진의 시각적 방해 요소는 다양한 모양과 크기로 나타나는 경우가 많다. 우리는 이러한 물체가 무엇인지, 얼마나 크거나 작을지 항상 알 수 없다. 이 과제를 해결하려면 특히 익숙하지 않은 클래스나 중소 규모 개체를 처리할 때 적응성이 뛰어난 interactive segmentation 모델이 필요하다. 담배꽁초, 웅덩이, 땅에 떨어진 새 배설물 등 희귀하거나 예상치 못한 물체가 클릭되더라도 어느 위치에서나 클릭에 반응할 수 있어야 한다. 이를 달성하려면 사용자가 단 한 번의 클릭으로 원치 않는 개체를 제거할 수 있도록 모델이 높은 recall에 최적화되어 있는지 확인해야 한다.
이전 interactive segmentation과 차이점
저자들은 파이프라인을 설계할 때 사용자가 방해 요소를 많이 제거하고 싶어할 수도 있다고 생각했다. 해당 시나리오의 경우 반복적인 제거 과정에서 positive click만 사용하는 것이 더 직관적이고 효율적이다. 이는 특히 모바일 앱에 적합할 수 있다. 최근의 interactive segmentation 연구들은 여러 번의 positive 및 negative 클릭을 통한 정확한 segmentation을 위해 설계되었다. SOTA 도구들은 몇 번의 positive click만으로는 중소형 개체의 segmentation에 적합하지 않다. 그러나 방해 요소 선택 작업의 경우 작은 크기의 많은 개체를 한 번의 클릭으로 선택하는 것이 더 쉬워야 한다. 몇 번의 positive click만으로 더 크고 중간 규모의 방해 요소를 신속하게 선택하는 것이 더 좋다. 따라서 본 논문의 segmentation 모델과 이전 연구들의 주요 차이점은 negative click을 사용하지 않고 더 적은 positive click으로 모델을 완전히 최적화한다는 것이다.
네트워크 구조
이미지 $I \in \mathbb{R}^{H \times W \times 3}$이 주어지면 feature 추출 네트워크는 pyramid feature map \(\mathcal{F} = \{X_1, \ldots, X_N\}\)을 제공한다. 여기서 $X_i \in \mathbb{R}^{h^i \times w^i \times d}$이고 $H > h^1 > \ldots > h^N$, $W > w^1 > \ldots > w^N$이다. 각 feature level에 대해 바이너리 클릭 맵 \(I_i^c \in \{0, 1\}^{h^i \times w^i}\)와 쌍을 이룬다. 여기서 $I_{i,x,y}^c = 1$은 $I_i^c$의 $(x, y)$에서의 클릭을 나타낸다. Click-embedded feature map $X_i^\prime \in \mathbb{R}^{h^i \times w^i \times (d+c)}$는 \(X_i^\prime = X_i \oplus \textrm{conv}_i (I_i^c)\)로 계산된다. 여기서 $\oplus$는 feature 차원에 대한 concatenation을 나타내고 \(\textrm{conv}_i\)는 $I_i^c$를 $\mathbb{R}^{h^i \times w^i \times c}$로 project하는 매핑 함수이다.
Click-embedded feature map의 그룹 $X_i^\prime$을 얻은 후 이를 detection head와 segmentation head에 공급한다. 클릭 위치와 겹치는 박스만 유지하는 것을 고려하여 bounding box 필터링 전략을 수정한다. 본 논문에서는 entity segmentation을 따라 detection head와 segmentation head를 설계하였다. Segmentation 모듈은 최종적으로 사용자 클릭 위치에 해당하는 여러 개의 바이너리 segmentation mask \(M_j \in \{0, 1\}^{H \times W}\)를 출력한다. 1C-DSN은 FCOS의 detection loss와 Entity Segmentation의 DICE loss를 결합한 loss function으로 학습된다. Detection 및 segmentation 부분의 디자인은 2단계 segmentation 프레임워크로 대체될 수 있다.
2. Click Proposal Network (CPN)
방해 요소의 인스턴스가 하나만 있는 상황에서는 1C-DSN 모델이 이를 정확하게 분할하는 데 충분할 수 있다. 그러나 많은 경우 유사한 카테고리와 모양을 공유하는 여러 가지 방해 요소를 접할 수 있다. 이러한 시나리오에서 사용자는 단 한 번의 클릭으로 이러한 인스턴스를 모두 선택할 수 있기를 원한다. 이 문제를 해결하기 위해 저자들은 사용자의 클릭과 유사한 모든 방해 요소를 효과적으로 식별하여 한 번에 모두 제거할 수 있는 self-similarity mining 모듈을 디자인했다.
저자들은 cross-scale feature matching을 사용하여 유사한 영역을 마이닝하고 신뢰도가 높은 영역에서 클릭 위치를 회귀하기 위해 Click Proposal Network (CPN)을 제안하였다. 그런 다음 모든 유사한 방해 요소의 마스크를 얻기 위해 해당 클릭 좌표를 1CDSN에 다시 공급할 수 있다. CPN에 대한 입력은 사용자의 단일 클릭에 해당하는 이전 1C-DSN에서 예측된 단일 쿼리 마스크이다. 공간 해상도가 입력 이미지 크기의 $1/4$, $1/8$, $1/16$인 세 가지 레벨의 feature map을 활용한다. 주어진 쿼리 마스크 영역에 대해 ROI-Align을 적용하여 맵의 세 가지 레벨에서 feature를 추출하고 $k \times k \times d$로 크기를 조정한다. 여기서 $k = 3$은 쿼리 크기에 대한 hyperparameter이고 $d$는 맵의 차원이다. 그런 다음 바이너리 쿼리 마스크를 마스킹되지 않은 feature 영역에 적용한다. 그런 다음 원래 feature map과의 유사성 비교를 위해 $3 \times k^2$개의 feature 벡터를 얻는다. 쿼리 벡터를 일련의 transformer 디코더 레이어 L1, L2, L3에 공급한다. 여기서 각 레이어는 다양한 레벨의 feature map에서 key와 value를 가져온다. 마지막으로 집계된 feature 벡터를 사용하여 가장 큰 feature map과 spatial convolution을 수행하여 예측 클릭 위치 히트맵을 얻는다.
학습 중에 CenterNet을 따라 클릭 맵의 가우시안 필터링을 사용하여 ground-truth 히트맵을 생성한다. 가우시안 필터의 커널 크기는 각 마스크의 높이와 너비 중 작은 값으로 설정된다. 그런 다음 모듈은 CenterNet에서와 같이 focal loss를 사용하여 penalty-reduced pixel-wise logistic regression을 사용하여 학습된다. Inference 중에 Non-Maximum Suppression (NMS)를 히트맵에 적용하여 $s \times s$ window 내 최대값만 유지하고 $\tau_c$보다 큰 신뢰도를 갖는 모든 클릭을 선택한다. 저자들은 경험적으로 $s = 32$, $\tau_c = 0.2$로 설정했다.
3. Proposal Verification Module (PVM)
히트맵과 클릭 맵에서 잘못된 positive proposal을 방지하기 위해 Proposal Verification Module (PVM)을 사용하여 선택된 클릭 위치가 사용자의 클릭과 매우 유사한지 확인한다. 이 모듈은 생성된 마스크와 초기 클릭 간의 쌍별 비교를 수행하고 임계값을 사용하여 초기 쿼리 마스크와 크게 다른 마스크를 생성하는 모든 click proposal을 제거한다.
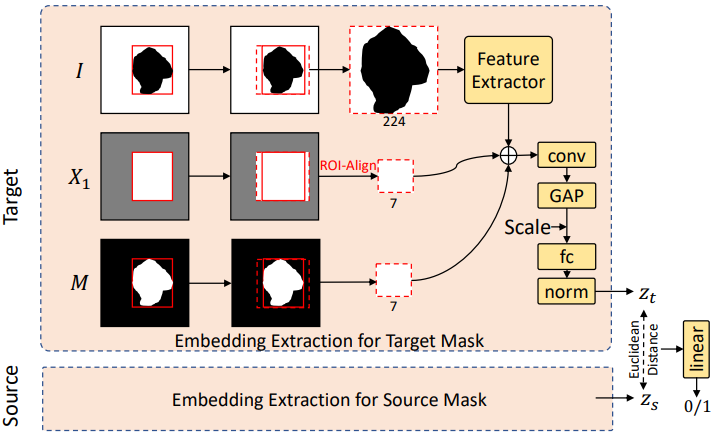
구체적으로, 먼저 모든 click proposal을 1C-DSN에 공급하여 각 클릭 위치에 대해 별도의 인스턴스 마스크를 생성한다. 초기 사용자 클릭의 마스크를 타겟 마스크라고 하고 다른 모든 제안된 마스크를 소스 마스크라고 부른다. 위 그림은 PVM의 모듈 구조와 두 개의 방해 요소를 비교하는 과정을 보여준다. 원본 이미지 $I$가 주어지면 1C-DSN의 사전 학습된 feature backbone에서 추출된 $1/4$ 크기의 feature $X_1$과 segmentation mask $M$을 고려하여 관심 영역을 추출한다. 개체들의 종횡비를 유지하기 위해 bounding box를 정사각형으로 확장하고 ROI-Align을 사용하여 픽셀이나 feature를 추출한다. 본 논문에서는 자른 이미지 패치의 크기를 224$\times$224로 조정하고 이를 ResNet18에 공급하였다. 그런 다음 $I$에서 얻은 이미지 feature, $X_1$에서 얻은 backbone feature, $M$에서 얻은 크기 조정된 마스크를 함께 concatenation하고 이를 신경망에 공급하여 1D feature 임베딩 (타겟의 경우 $z_t$, 소스의 경우 $z_s$)을 얻는다. 또한 임베딩 학습을 가이드하기 위해 scaling factor $w_b / 224$를 추가한다. 여기서 $w_b$는 bounding box의 크기이다. $z_s$와 $z_t$ 사이의 유클리드 거리는 sigmoid activation을 사용하는 다음 fully-connected layer에 입력되어 유사도 점수를 0에서 1까지 출력한다.
학습 시에서는 동일한 이미지에서 무작위로 쌍을 샘플링한다. 동일한 복사본에서 가져온 쌍은 positive로 간주된다. 그렇지 않으면 negative 쌍이 된다. Binary cross entropy \(\mathcal{L}_\textrm{BCE}\)는 쌍 레이블이 있는 마지막 출력에서 계산되며, max-margin contrastive loss \(\mathcal{L}_\textrm{con}\)은 feature 임베딩 $z_t$, $z_s$에 통합되어 모델 학습 능력을 향상시킨다. 최종 학습 loss는 선형 결합 \(\mathcal{L} = \mathcal{L}_\textrm{con} + \mathcal{L}_\textrm{BCE}\)이다. 테스트 시에는 PVM은 유사도 점수를 임계값으로 설정하여 각 mask proposal를 분류한다. 실험에서는 임계값으로 0.5를 선택했다.
4. Iterative Distractor Selection (IDS)

초기 클릭과 유사한 모든 선택 항목을 완전히 선택하기 위해 더 유사한 선택 항목을 샘플링하는 반복 프로세스를 실행한다. 디테일한 pseudo-code는 Algorithm 1과 같다. 각 iteration에 대해 올바른 마스크로 $M_e$를 업데이트하고 높은 신뢰도 클릭을 점진적으로 결과에 더한다. $M_e$를 업데이트하면 불완전한 초기 마스크로 인해 발생하는 잘못된 유사도 결과를 피할 수 있다. CPN의 false positive 비율을 줄이려면 top-$k$ 클릭과 PVM 모듈을 선택하는 것이 필수적이다. 실험에서는 NMS에 대해 커널 크기 5, $N = 5$, $k = 10$, $m = 3$을 선택했다.
Experiments
- 공개 데이터셋
- 사전 학습: COCO Panoptic (이미지 118,287개)
- Fine-tuning: LVIS (이미지 99,388개)
- 자체 수집 데이터셋: Distractor20K (이미지 21,821개)
- Flickr, Unsplash, Pixabay 등 다양한 공개 이미지 웹사이트에서 수집
- 3명의 사진 전문가가 방해 요소를 수동으로 선택 후 마스킹
- 합성 데이터셋: DistractorSyn14K (이미지 14,264개)
- LVIS 데이터셋의 인스턴스를 활용하여 합성
- Mask2Former로 이미지의 instance segmentation mask를 얻음
- 땅, 천장, 벽, 하늘, 바다, 강 등 동일한 semantic 영역 내의 선택 항목만 후보 영역으로 합성
- 먼저 해당 후보 영역 내에서 또는 LVIS 데이터셋에서 기존의 선택 항목인 개체를 복사
- 각 영역에 대해 최소 3개, 개체와 semantic 영역 간의 비율에 따라 최대 10개를 복사
- 그런 다음 semantic 영역의 거리 맵의 최대 위치에 배치 후 거리 맵을 다시 계산
1. Evaluation on 1C-DSN
다음은 validation set에서의 Precision-Recall (PR) 곡선을 비교한 그래프이다.
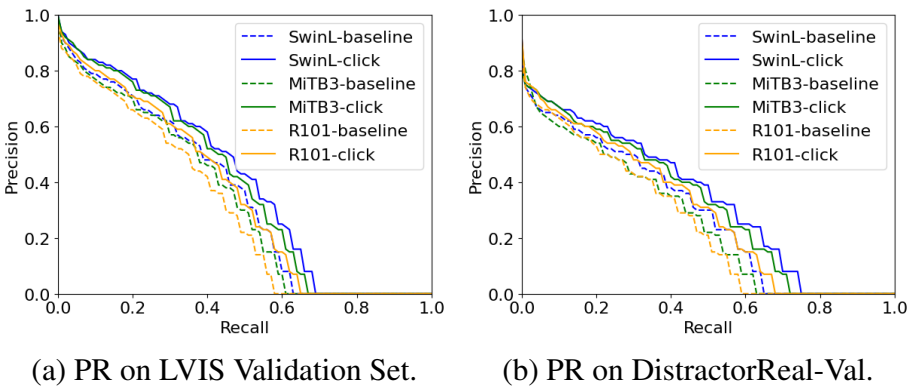
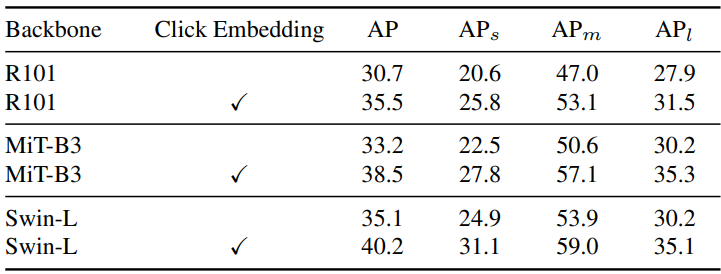
다음은 LVIS validation set에서의 single-click segmentation 결과이다. 모든 모델은 COCO Panoptic 2017에서 사전 학습되었다.
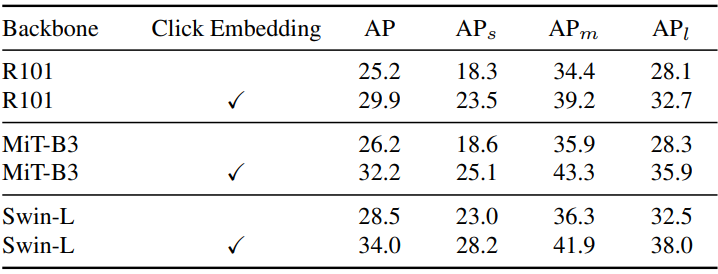
다음은 Distractor validation set에서의 single-click segmentation 결과이다.
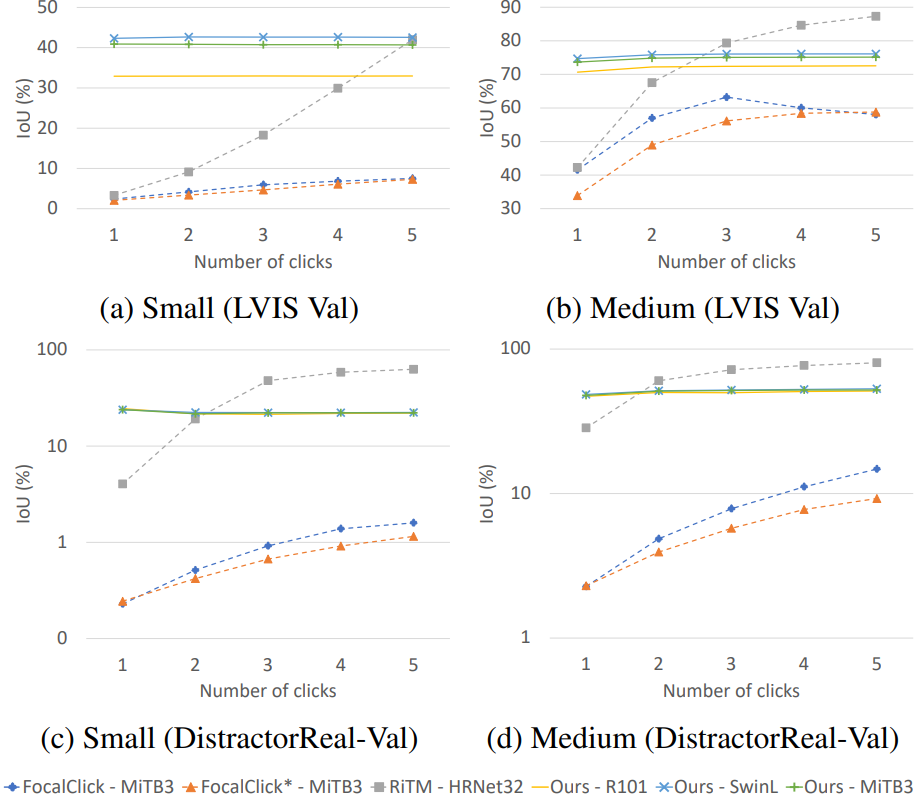
다음은 여러 SOTA interactive segmentation 연구들과 IoU를 비교한 그래프이다.
2. Group Distractor Selection
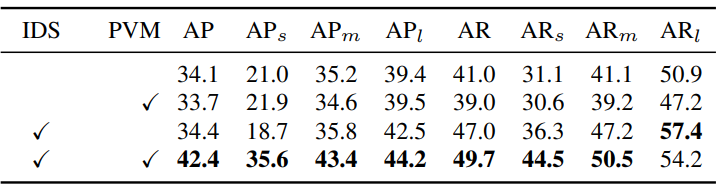
다음은 IDS와 PVM 모듈 사용에 따른 성능 이득을 비교한 표이다.
다음은 실제 이미지(위)와 합성 데이터(아래)에 대하여 다양한 segmentation 모델의 방해 요소 선택 결과를 비교한 것이다.

3. More Ablation Studies
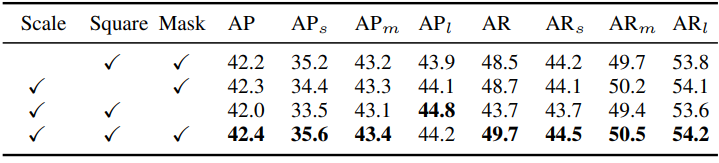
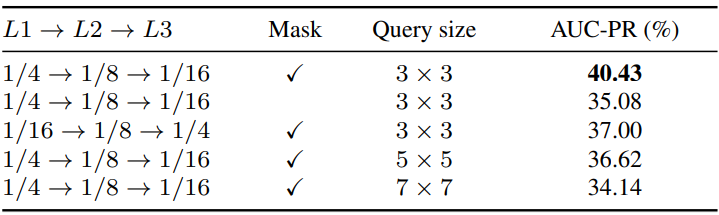
다음은 CPN에 대한 ablation study 결과이다. (DistractorSyn-Val)
다음은 다양한 입력 정보에 따른 PVM 성능을 비교한 표이다. (DistractorSyn-Val)