[논문리뷰] SimMIM: a Simple Framework for Masked Image Modeling
CVPR 2022. [Paper] [Github]
Zhenda Xie, Zheng Zhang, Yue Cao, Yutong Lin, Jianmin Bao, Zhuliang Yao, Qi Dai, Han Hu
Tsinghua University | Microsoft Research Asia | Xi’an Jiaotong University
18 Nov 2021
Introduction
“Masked signal modeling”은 입력 신호의 일부를 마스킹하고 이러한 마스킹된 신호를 예측하는 방법을 배우는 task 중 하나이다. NLP에서 이 철학에 따라 masked language modeling task를 기반으로 구축된 self-supervised learning 접근 방식은 이 분야를 크게 다시 그렸다. 즉, 레이블이 지정되지 않은 엄청난 양의 데이터를 사용하여 대규모 언어 모델을 학습하는 분야는 광범위한 NLP 애플리케이션에 잘 일반화되는 것으로 나타났다.
컴퓨터 비전에서는 self-supervised 표현 학습에 이 철학을 활용하는 선구자들이 있지만, 이전에는 이 방법이 contrastive learning 접근 방식에 의해 거의 묻혔다. 이 task을 언어 및 비전 도메인에 적용하는 데 따른 다양한 어려움은 두 modality 간의 차이로 설명할 수 있다.
- 이미지가 더 강한 locality를 나타낸다. 서로 가까운 픽셀은 높은 상관 관계가 있는 경향이 있으므로 의미론적 추론이 아닌 가까운 픽셀을 복제하여 작업을 수행할 수 있다.
- 시각적 신호는 원시적이고 낮은 수준인 반면 텍스트 토큰은 사람이 생성한 높은 수준의 개념이다. 이것은 낮은 수준의 신호 예측이 높은 수준의 시각적 인식 작업에 유용한지에 대한 질문을 제기한다.
- 시각적 신호가 연속적이고 텍스트 토큰이 불연속적이다. 연속적인 시각적 신호를 잘 처리하기 위해 분류 기반 masked language modeling 접근 방식을 어떻게 적용할 수 있는지는 알 수 없다.
최근까지 연속적인 신호를 색상 클러스터로 변환하거나 추가 네트워크를 사용한 패치 토큰화 또는 단거리 연결을 끊기 위한 블록별 마스킹 전략과 같은 몇 가지 특수 설계를 도입하여 modality 격차를 해소하고 장애물을 해결하려는 시도가 있었다. 이러한 특수 설계를 통해 학습된 표현은 여러 비전 인식 task로 잘 전환될 수 있음이 입증되었다.
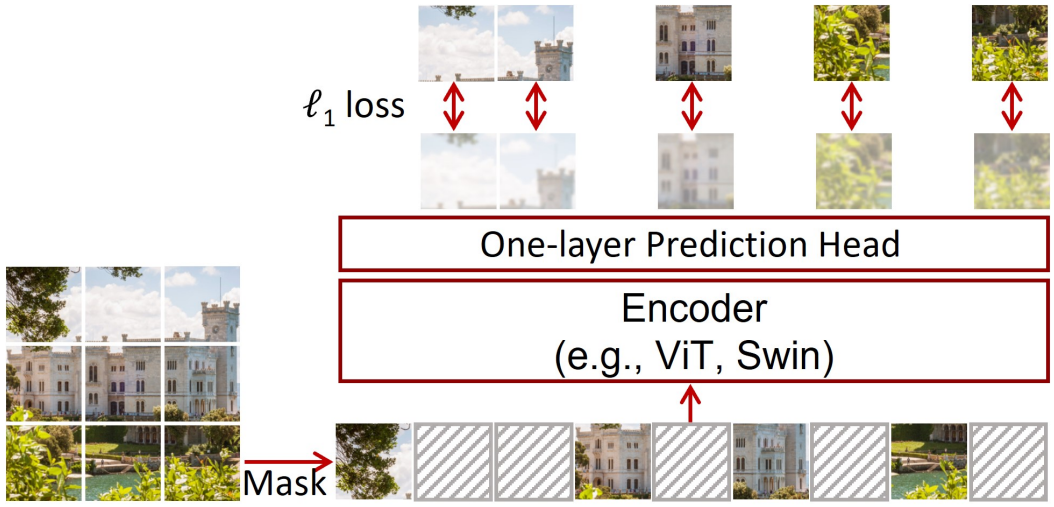
특별한 복잡한 디자인을 요구하는 것과는 대조적으로, 본 논문에서는 위 그림과 같이 시각적 신호의 특성과 잘 일치하고 이전의 더 복잡한 접근 방식보다 유사하거나 더 나은 표현을 학습할 수 있는 간단한 프레임워크를 제시한다.
Linear layer를 사용하여 $\ell_1$ loss로 마스크된 영역의 픽셀 값을 회귀시키는 입력 이미지 패치의 랜덤 마스킹
이 간단한 프레임워크의 핵심 설계와 통찰력은 다음과 같다.
- 이미지 패치에 랜덤 마스킹을 적용하여 ViT에 간편하고 편리하다. 마스킹된 픽셀의 경우 더 큰 패치 크기 또는 더 높은 마스킹 비율로 인해 가까이 보이는 픽셀을 찾을 가능성이 낮아질 수 있다. 32개의 큰 마스킹 패치 크기의 경우 접근 방식은 광범위한 마스킹 비율(10%-70%)에서 경쟁력 있는 성능을 달성할 수 있다. 8의 작은 마스크 패치 크기의 경우, 잘 수행하려면 마스킹 비율이 80%만큼 높아야 한다. 선호되는 마스킹 비율은 0.15의 작은 마스킹 비율이 기본값으로 채택되는 언어 도메인의 것과 매우 다르다. 저자들은 두 가지 modality에서 서로 다른 수준의 정보 중복이 서로 다른 행동으로 이어질 수 있다고 가정하였다.
- 픽셀 회귀 task가 사용된다. 회귀 task는 순서를 갖는 시각적 신호의 연속적인 특성과 잘 일치한다. 이 간단한 task는 토큰화, 클러스터링 또는 discretization에 의해 특별히 정의된 클래스를 사용하는 classification 접근 방식보다 나쁘지 않다.
- 매우 가벼운 prediction head (ex. linear layer)를 채택하여 더 무거운 prediction head (ex. inverse Swin-B)와 유사하거나 약간 더 나은 transferring 성능을 달성한다. 초경량 prediction head를 사용하면 사전 학습 속도가 현저하게 향상된다. 또한 광범위한 타겟 해상도 (ex. $12^2$ ~ $96^2$)가 가장 높은 $192^2$와 경쟁적으로 수행된다는 점에 주목한다. Head가 무겁거나 해상도가 높을수록 일반적으로 생성 능력이 향상되지만 이 능력이 다운스트림 fine-tuning task에 반드시 도움이 되는 것은 아니다.
제안된 SimMIM 접근 방식은 간단하지만 표현 학습에 매우 효과적이다.
Approach
1. A Masked Image Modeling Framework
SimMIM은 입력 이미지 신호의 일부를 마스킹하고 마스킹된 영역에서 원래 신호를 예측하는 masked image modeling을 통해 표현을 학습한다. 프레임워크는 4개의 주요 구성 요소로 구성된다.
- Masking strategy: 입력 이미지가 주어지면 이 컴포넌트는 마스킹할 영역을 선택하는 방법과 선택한 영역의 마스킹을 구현하는 방법을 설계한다. 마스킹 후 변환된 이미지가 입력으로 사용된다.
- Encoder architecture: 마스킹된 이미지에 대한 latent feature 표현을 추출한 다음 마스킹된 영역에서 원래 신호를 예측하는 데 사용된다. 학습된 인코더는 다양한 비전 task에 활용될 수 있을 것으로 기대된다. 본 논문에서는 주로 바닐라 ViT와 Swin Transformer의 두 가지 일반적인 ViT 아키텍처를 고려한다.
- Prediction head: Prediction head는 latent feature 표현에 적용되어 마스킹된 영역에서 원래 신호의 한 형태를 생성한다.
- Prediction target: 이 구성 요소는 예측할 원래 신호의 형태를 정의한다. 픽셀 값이거나 픽셀의 변환일 수 있다. 이 구성 요소는 또한 cross-entropy classification loss와 $\ell_1$ 또는 $\ell_2$ regression loss를 포함한 일반적인 옵션으로 loss 유형을 정의한다.
2. Masking Strategy

마스킹된 영역의 입력 변환을 위해 NLP 커뮤니티와 BEiT를 따라 각 마스킹된 패치를 대체하기 위해 학습 가능한 마스크 토큰 벡터를 사용한다. 토큰 벡터 차원은 패치 임베딩 후 다른 보이는 패치 표현과 동일하게 설정된다. 마스킹 영역 선택을 위해 저자들은 다음 마스킹 전략을 연구하였다 (위 그림 참조).
Patch-aligned random masking
이미지 패치는 ViT의 기본 처리 단위로, 패치가 완전히 보이거나 완전히 마스킹되는 패치 레벨에서 마스킹을 작동하는 것이 편리하다. Swin Transformer의 경우 서로 다른 해상도 단계의 등가 패치 크기인 4$\times$4 ~ 32$\times$32를 고려하고 기본적으로 마지막 단계의 패치 크기인 32$\times$32를 채택한다. ViT의 경우 기본 마스크 패치 크기로 32$\times$32를 채택한다.
Other masking strategies
또한 이전 연구들의 다른 마스킹 전략을 시도하였다.
- 중앙 영역 마스킹 전략: 이미지에서 랜덤으로 움직일 수 있도록 완화
- 복잡한 블록별 마스킹 전략: 16$\times$16와 32$\times$32의 두 마스크 패치 크기에서 이 마스크 전략을 시도
3. Prediction Head
Prediction head는 입력이 인코더 출력과 일치하고 출력이 예측 타겟을 달성하는 한 임의의 형식과 용량을 가질 수 있다. 일부 초기 연구들은 무거운 prediction head (디코더)를 사용하기 위해 오토인코더를 사용한다. 본 논문에서는 prediction head가 linear layer만큼 가벼울 정도로 매우 가벼워질 수 있음을 보여주었다. 또한 저자들은 2-layer MLP, inverse Swin-T, inverse Swin-B와 같은 더 무거운 head를 시도하였다.
4. Prediction Targets
Raw pixel value regression
픽셀 값은 색상 공간에서 연속적이다. 간단한 옵션은 회귀를 통해 마스킹된 영역의 픽셀을 예측하는 것이다. 일반적으로 비전 아키텍처는 ViT에서 16배, 대부분의 다른 아키텍처에서 32배와 같이 다운샘플링된 해상도의 feature map을 생성한다. 입력 이미지의 전체 해상도에서 모든 픽셀 값을 예측하기 위해 feature map의 각 feature 벡터를 원래 해상도로 다시 매핑하고 이 벡터가 해당 픽셀의 예측을 담당하도록 한다.
예를 들어, Swin Transformer 인코더에 의해 생성된 $32 \times$ 다운샘플링된 feature map에서 출력 차원이 $3072 = 32 \times 32 \times 3$인 $1 \times 1$ convolution (linear) layer를 적용하여 $32 \times 32$ 픽셀의 RGB 값을 나타낸다. 또한 원본 이미지를 각각 \(\{32 \times, 16 \times, 8 \times, 4 \times, 2 \times\}\)로 다운샘플링하여 저해상도 타겟을 고려한다.
마스킹된 픽셀에 $\ell_1$-loss가 적용된다.
\[\begin{equation} L = \frac{1}{\Omega (x_M)} \| y_M - x_M \|_1 \end{equation}\]여기서 $x, y \in \mathbb{R}^{3HW \times 1}$은 각각 입력 RGB 값과 예측 값이다. $M$은 마스킹된 픽셀 집합을 나타낸다. $\Omega (\cdot)$은 element의 수이다. 또한 $\ell_2$와 smooth-$\ell_1$ loss를 고려하고 기본적으로 $\ell_1$ loss를 채택한다.
Other prediction targets
이전 접근 방식은 대부분 마스킹된 신호를 클러스터 또는 클래스로 변환한 다음 마스킹된 이미지 예측을 위한 classification task를 수행하였다.
- Color clustering: iGPT에서 RGB 값은 많은 양의 자연 이미지를 사용하여 $k$-means로 512개의 클러스터로 그룹화된다. 그런 다음 각 픽셀은 가장 가까운 클러스터 센터에 할당된다. 이 방법을 사용하려면 9비트 색상 팔레트를 생성하기 위한 추가 클러스터링 단계가 필요하다. 실험에서는 iGPT에서 학습한 512개의 클러스터 센터를 사용한다.
- Vision tokenization: BEiT에서는 discrete VAE (dVAE) 네트워크를 사용하여 이미지 패치를 dVAE 토큰으로 변환한다. 토큰 ID는 classification 타겟으로 사용된다. 이 접근 방식에서는 추가 dVAE 네트워크를 사전 학습해야 한다.
- Channel-wise bin color discretization: R, G, B 채널은 개별적으로 분류되며 각 채널은 동일한 bin으로 discretize된다.
Experiments
1. Ablation Study
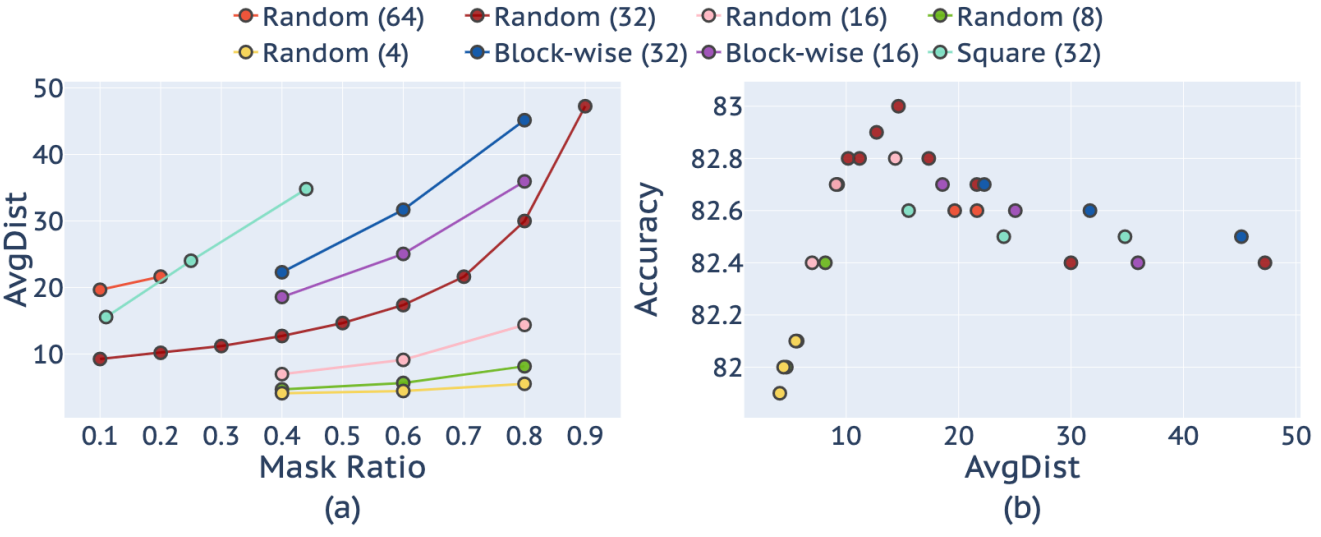
Masking Strategy
다음은 다양한 마스킹 전략에 대한 ablation 결과이다.
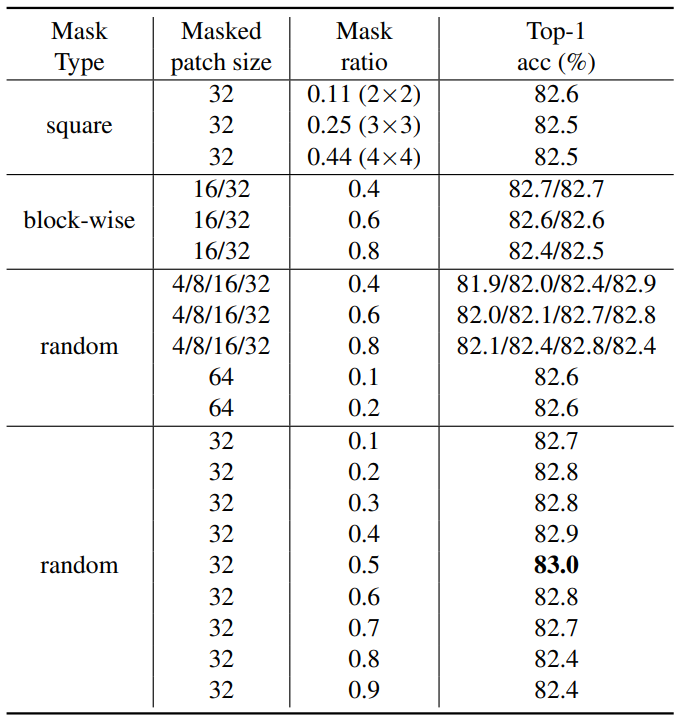
다음은 (a) 다양한 마스킹 비율에 따른 AvgDist (마스킹된 픽셀들의 가장 가까운 보이는 픽셀까지의 평균 거리)와 (b) AvgDist에 따른 fine-tuning 성능이다.
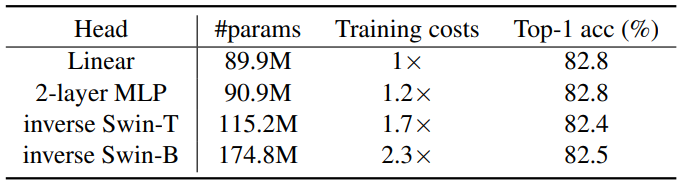
Prediction Head
다음은 다양한 prediction head에 대한 ablation 결과이다.
Prediction Resolution
다음은 다양한 예측 해상도에 대한 ablation 결과이다.

Prediction Target
다음은 다양한 예측 타겟에 대한 ablation 결과이다.
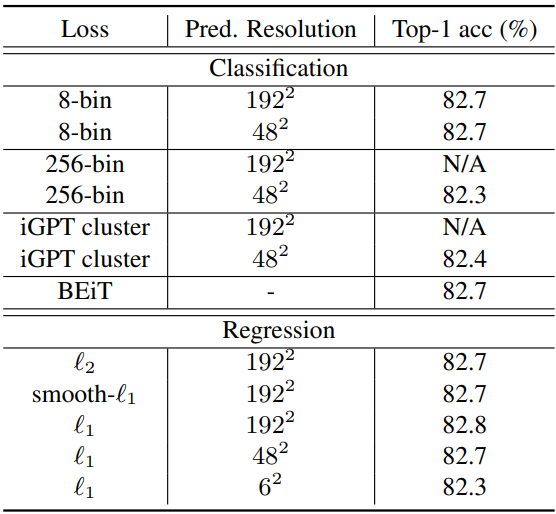
다음은 예측 loss를 사용하는 영역에 대한 ablation 결과이다.
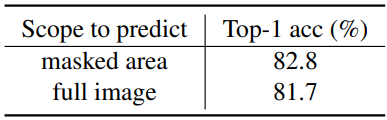
2. Comparison to Previous Approaches on ViT-B
다음은 ViT-B를 인코더로 사용할 때 시스템 수준의 비교 결과이다.
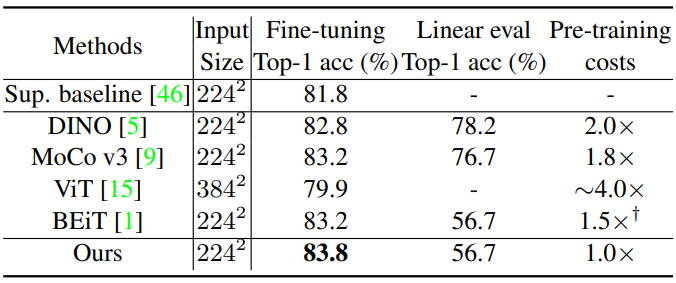
3. Scaling Experiments with Swin Transformer
다음은 Swin Transformer를 backbone으로 한 스케일링 실험 결과이다.
4. Visualization
다음은 3가지 마스크 종류에 따른 복구된 이미지이다.

다음은 2가지 loss 종류에 따른 복구된 이미지이다. 왼쪽부터 원본 이미지, 마스킹된 이미지, 마스킹한 영역만 예측하는 경우의 복구된 이미지, 전체 이미지를 재구성하는 경우의 복구된 이미지이다.

다음은 다양한 마스킹된 패치 크기에 따른 복구된 이미지이다. (마스킹 비율은 0.6으로 고정)
