[논문리뷰] Show-o: One Single Transformer to Unify Multimodal Understanding and Generation
ICLR 2025. [Paper] [Page] [Github]
Jinheng Xie, Weijia Mao, Zechen Bai, David Junhao Zhang, Weihao Wang, Kevin Qinghong Lin, Yuchao Gu, Zhijie Chen, Zhenheng Yang, Mike Zheng Shou
Show Lab, National University of Singapore | ByteDance
22 Aug 2024
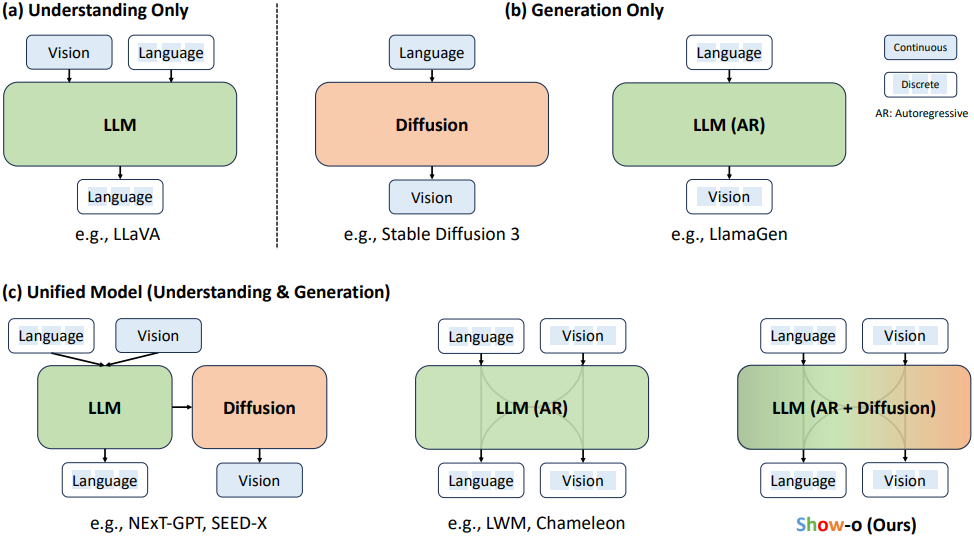
Introduction
지난 몇 년 동안 멀티모달 이해와 이미지/동영상 생성에서 상당한 발전이 이루어졌다. 최근 연구에서는 이 두 가지 다른 도메인에서 전문가 모델을 조립하여 멀티모달 이해와 생성을 모두 처리할 수 있는 통합 시스템을 형성하려고 시도했다. 그러나 기존의 시도는 주로 각 도메인을 독립적으로 처리하고 종종 이해와 생성을 담당하는 개별 모델을 별도로 포함하였다. 하지만, LLaVA와 같은 이해 모델과 Stable Diffusion 3 (SD3)과 같은 생성 모델은 모두 transformer 아키텍처이다.
하나의 transformer가 멀티모달 이해와 생성을 모두 처리할 수 있을까?
아주 최근에 Chameleon은 이것이 가능하다는 것을 보여주었다. 구체적으로, Chameleon은 동일한 방식의 autoregressive 모델링을 통해 텍스트와 이미지 토큰을 모두 생성할 수 있도록 하였다. 텍스트 토큰을 autoregressive하게 모델링하는 것이 합리적이지만, 이미지/동영상 패치(또는 픽셀)도 autoregressive하게 모델링하는 것이 더 나은지는 덜 명확하다. 이미지를 autoregressive하게 예측하는 데 있어 명백하고 중요한 한계점은 특히 고해상도의 이미지/동영상을 처리할 때 causal attention으로 인해 필요한 샘플링 step 수가 많다는 것이다. 또한 diffusion model은 autoregressive model보다 시각적 생성에서 뛰어난 능력을 보여주었고 full attention을 사용한다.
하나의 transformer가 autoregressive와 diffusion 모델링을 모두 포함할 수 있을까?
저자들은 텍스트가 discrete한 토큰으로 표현되고 LLM과 동일하게 autoregressive하게 모델링되고 continuous한 이미지 픽셀이 diffusion을 사용하여 모델링되는 새로운 패러다임을 구상하였다. 그러나 discrete한 텍스트 토큰과 continuous한 이미지 표현 간의 상당한 차이로 인해 이 두 가지 별개의 기술을 하나의 단일 네트워크로 통합하는 것은 어려운 일이다. 또 다른 문제는 기존의 SOTA diffusion model이 일반적으로 두 가지 별개의 모델, 즉 텍스트 조건 정보를 인코딩하는 텍스트 인코더와 noise를 예측하는 denoising network에 의존한다는 것이다.
이를 위해, 본 논문은 autoregressive와 diffusion 모델링을 혼합하여 멀티모달 이해 및 생성 task를 동시에 처리할 수 있는 새로운 통합 모델인 Show-o를 제시하였다. 구체적으로, Show-o는 사전 학습된 LLM을 기반으로 하며, 텍스트 기반 추론을 위한 autoregressive 모델링 기능을 상속한다. 기존 방법들에서 사용되는 continuous diffusion 대신 discrete diffusion을 사용하여 discrete한 이미지 토큰을 모델링한다.
Show-o는 본질적으로 텍스트 조건부 정보를 인코딩하여 추가 텍스트 인코더를 제거한다. 다양한 입력 데이터와 task를 수용하기 위해 텍스트 tokenizer와 이미지 tokenizer를 사용하여 discrete한 토큰으로 인코딩하고, 이러한 토큰을 입력으로 시퀀스로 처리하기 위한 통합 프롬프팅 전략을 사용하였다. 결과적으로, 질문과 함께 이미지가 주어지면 Show-o는 autoregressive하게 답변을 제공한다. 텍스트 토큰만 제공되면 Show-o는 discrete diffusion 스타일로 이미지를 생성한다.
Show-o는 더 많은 수의 파라미터를 사용하는 모델과 비교할 수 있을 만큼 더 나은 성능을 보여준다. 이미지를 autoregressive하게 생성하는 방법들과 달리 Show-o는 약 20배 더 적은 샘플링 step이 필요하다. 또한, fine-tuning 없이 인페인팅, extrapolation, 동영상 키프레임 생성 등 다양한 다운스트림 애플리케이션을 자연스럽게 지원한다.
Method
궁극적인 목표는 멀티모달 이해 및 생성을 위한 autoregressive 및 diffusion 모델링을 포함하는 통합 모델을 개발하는 것이다. 이러한 통합 모델을 개발하는 것의 핵심 문제는 다음과 같다.
- 모델의 입력/출력 공간을 정의하는 방법
- 다양한 모달리티의 다양한 종류의 입력 데이터를 통합하는 방법
- Autoregressive 및 diffusion 모델링을 하나의 transformer에 포함하는 방법
- 이러한 통합 모델을 효과적으로 학습하는 방법
1. Tokenization
Show-o가 사전 학습된 LLM에 기반을 두고 있다는 점을 감안할 때, discrete space에서 통합 학습을 수행하는 것이 자연스럽다. 저자들은 텍스트 토큰과 이미지 토큰을 포함하는 통합 vocabulary를 유지하여 통합 모델이 동일하게 discrete한 토큰을 예측하도록 하였다. 텍스트 tokenization의 경우, 어떠한 수정 없이 LLM과 동일한 tokenizer를 사용한다.
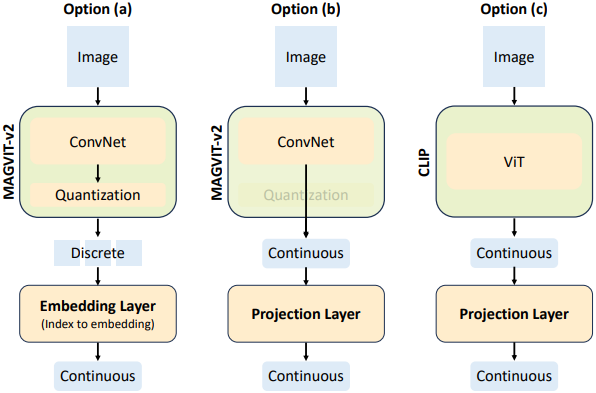
이미지 tokenization의 경우, 3가지 옵션이 존재한다.
옵션 (a)는 quantizer를 학습시키는 것이다. MAGVIT-v2를 따라, 약 3,500만 개의 이미지 데이터를 사용하여 lookup-free quantizer를 학습시킨다. Quantizer는 $K = 8192$ 크기의 codebook을 유지하고 256$\times$256 해상도의 이미지를 16$\times$16의 discrete한 토큰으로 인코딩한다. MAGVIT-v2를 사용하는 이유는 시간 압축 기능을 갖춘 동영상 tokenizer로 fine-tuning하기 쉽기 때문이다.
옵션 (b)와 (c)는 이해와 생성을 위해 각각 다른 tokenizer를 사용하는 것이며, 각각 사전 학습된 MAGVIT-v2와 CLIP-ViT 인코더에서 continuous한 이미지 표현을 추출하여 입력으로 사용한다.
2. Architecture
Show-o는 각 attention layer에 QK-Norm 연산을 추가하는 것을 제외하고는 아키텍처 수정 없이 기존 LLM의 아키텍처를 상속한다. 사전 학습된 LLM의 가중치로 Show-o를 초기화하고 discrete한 이미지 토큰에 대한 8,192개의 새로운 학습 가능한 임베딩을 통합하여 임베딩 레이어의 크기를 확장한다. 추가 텍스트 인코더가 필요한 SOTA diffusion model과 달리 Show-o는 text-to-image 생성을 위해 텍스트 조건 정보를 자체적으로 인코딩한다.
통합 프롬프팅
멀티모달 이해 및 생성에 대한 통합 학습을 위해, 저자들은 다양한 종류의 입력 데이터를 다루기 위한 통합 프롬프팅 전략을 설계하였다. 이미지-텍스트 쌍 $(\textbf{x}, \textbf{y})$가 주어지면, 먼저 각각을 $M$개의 이미지 토큰 \(\textbf{u} = \{u_i\}_{i=1}^M\)와 $N$개의 텍스트 토큰 \(\textbf{v} = \{v_i\}_{i=1}^M\)로 tokenize한다.

이를 위 그림과 같이 task 유형에 따라 입력 시퀀스로 형성한다. 구체적으로, [MMU]와 [T2I]는 입력 시퀀스에 대한 task를 나타내는 미리 정의된 task 토큰이다. [SOT]와 [EOT]는 각각 텍스트 토큰의 시작과 끝을 나타내는 특수 토큰이다. 마찬가지로 [SOI]와 [EOI]는 이미지 토큰의 시작과 끝을 나타내는 특수 토큰이다. 이 프롬프트 디자인을 채택함으로써, 다양한 task를 위한 다양한 입력 데이터를 순차적 데이터로 효과적으로 인코딩할 수 있다.
Omni-Attention Mechanism
저자들은 Show-o가 다양한 유형의 신호를 서로 다른 방식으로 모델링할 수 있도록 하는 omni-attention mechanism을 제안하였다. 이는 causal attention과 full attention을 갖춘 포괄적인 attention 메커니즘으로, 입력 시퀀스의 형식에 따라 적응적으로 혼합되고 변경된다.
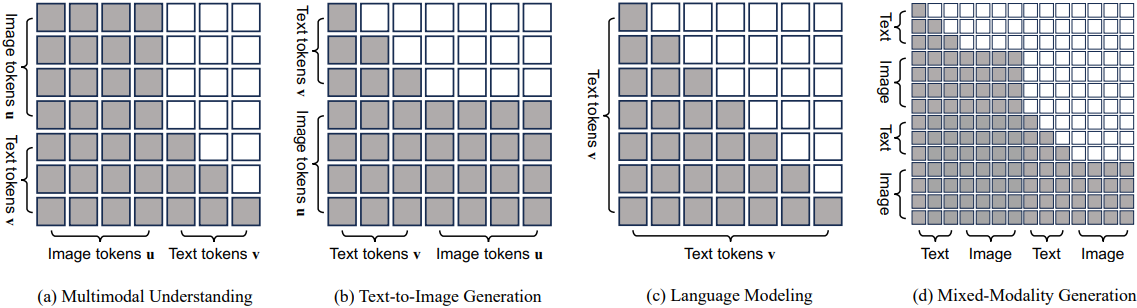
구체적으로, 텍스트 토큰 $\textbf{v}$는 causal attention을 통해 처리되고, 이미지 토큰 $\textbf{u}$는 full attention을 통해 처리하여 각 토큰이 다른 모든 토큰과 포괄적으로 상호 작용할 수 있도록 한다. 텍스트 토큰은 이전의 모든 이미지 토큰과 상호 작용할 수 있고, 이미지 토큰은 이전의 모든 텍스트 토큰과 상호 작용할 수 있다.
Omni-attention은 사전 학습된 LLM의 텍스트 추론 지식을 유지하고 샘플링 step을 줄여 이미지 생성의 효율성을 향상시킨다. 또한, fine-tuning 없이 인페인팅과 같은 다양한 다운스트림 애플리케이션을 자연스럽게 지원한다.
Training Objectives
Autoregressive 및 diffusion 모델링을 모두 수행하기 위해 두 가지 학습 loss를 채택한다.
- Next Token Prediction (NTP)
- Mask Token Prediction (MTP)
멀티모달 이해를 위해 $M$개의 이미지 토큰 \(\textbf{u} = \{u_i\}_{i=1}^M\)와 $N$개의 텍스트 토큰 \(\textbf{v} = \{v_i\}_{i=1}^M\)가 있는 시퀀스가 주어지면 표준 언어 모델링 loss를 채택하여 텍스트 토큰의 likelihood를 최대화한다.
\[\begin{equation} \mathcal{L}_\textrm{NTP} = \sum_i \log p_\theta (v_i \vert v_1, \cdots, v_{i-1}, u_1, \cdots, u_M) \end{equation}\]입력 시퀀스에 텍스트 토큰만 포함된 경우, 이미지 토큰 \(\textbf{u} = \{u_i\}_{i=1}^M\)에 대한 조건 항이 없다.
Mask token prediction을 학습 loss로 채택하여 Show-o 내에서 discrete diffusion 모델링을 원활하게 통합한다. 입력 시퀀스 내에서 이미지 토큰 \(\textbf{u} = \{u_1, u_2, \ldots, u_M\}\)을 모델링하기 위해, 먼저 이미지 토큰을 랜덤한 비율(timestep으로 조절)로 [MASK] 토큰 $u_\ast∗로 대체하여 마스킹된 시퀀스 \(\textbf{u}_\ast = \{u_\ast, u_2, \ldots, u_\ast, u_M\}\)을 생성한다.
그런 다음, 마스킹되지 않은 영역과 이전 텍스트 토큰을 조건으로 다음과 같은 likelihood를 최대화하여 마스킹된 토큰에서 원래 이미지 토큰을 재구성하는 것을 목표로 한다.
\[\begin{equation} \mathcal{L}_\textrm{MTP} = \sum_j \log p_\theta (u_j \vert u_\ast, u_2, \cdots, u_\ast, u_M, v_1, \cdots, v_N) \end{equation}\]Loss는 마스킹된 토큰에만 적용된다. 구체적으로, MaskGIT와 Muse가 사용한 샘플링 전략을 따라 이미지 토큰을 마스킹하고 입력 시퀀스 내의 모든 텍스트와 마스킹되지 않은 이미지 토큰의 정보를 통해 이를 재구성한다. Classifier-free guidance를 따라, 조건부 텍스트 토큰을 확률적으로 빈 텍스트 ““로 무작위로 대체한다.
전체 학습 loss는 \(\mathcal{L}_\textrm{MTP}\)와 \(\mathcal{L}_\textrm{NTP}\)의 조합이다.
\[\begin{equation} \mathcal{L} = \mathcal{L}_\textrm{MTP} + \alpha \mathcal{L}_\textrm{NTP} \end{equation}\]3. Training Pipeline
이미지 토큰의 임베딩이 새롭게 초기화되었다는 점을 감안할 때, 멀티모달 이해 및 생성을 위해 정렬하기 위한 대규모 사전 학습이 필요하다. 게다가 Show-o는 텍스트 인코더를 제거하여 text-to-image 생성을 위한 텍스트 임베딩을 추출하는데, 이는 하나의 transformer 내에서 텍스트와 이미지 콘텐츠 간의 효과적인 정렬을 달성해야 함을 의미한다.
저자들은 Show-o를 점진적이고 효과적으로 학습하기 위해 3단계 접근 방식을 사용하였다.
- 이미지 토큰 임베딩 및 픽셀 의존성 학습: 언어 모델링 능력을 유지하기 위해 RefinedWeb 데이터셋을 사용한다. 동시에, ImageNet-1K 데이터셋과 RefinedWeb의 이미지-텍스트 쌍을 사용하여 각각 클래스 조건부 이미지 생성과 image captioning을 학습시킨다. 여기서 ImageNet-1K의 클래스 이름을 그대로 텍스트 입력으로 활용하여 클래스 조건부 이미지 생성을 학습시킨다. 이 단계에서는 주로 discrete한 이미지 토큰을 위한 새로운 학습 가능한 임베딩 학습, 이미지 생성을 위한 픽셀 간 의존성 학습, 그리고 image captioning을 위한 이미지와 텍스트 간 정렬 학습이 이루어진다.
- 멀티모달 이해 및 생성을 위한 이미지-텍스트 정렬: 사전 학습된 가중치를 기반으로 ImageNet-1K 대신 이미지-텍스트 데이터에서 text-to-image 생성 학습을 진행한다. 이 단계는 주로 image captioning과 text-to-image 생성을 위한 이미지-텍스트 정렬에 중점을 둔다.
- 고품질 데이터 fine-tuning: Text-to-image 생성을 위한 필터링된 고품질 이미지-텍스트 쌍과 멀티모달 이해 및 mixed-modality 생성을 위한 학습 데이터를 통합하여 사전 학습된 Show-o 모델을 더욱 개선한다.
4. Inference
Inference에서는 텍스트 토큰과 이미지 토큰의 두 가지 유형의 예측이 포함된다. 멀티모달 이해의 경우, 조건부 이미지와 질문이 주어지면 텍스트 토큰은 더 높은 신뢰도로 예측된 토큰에서 autoregressive하게 샘플링된다. 시각적 생성의 경우, 이미지를 생성하는 데 $T$ step이 걸린다.
처음에는 $N$개의 조건부 텍스트 토큰과 $M$개의 [MASK] 토큰을 입력으로 제공힌다. 그런 다음 Show-o는 각 [MASK] 토큰에 대한 logit $\ell^t$를 예측한다. 여기서 $t$는 timestep이다. Muse를 따라, 마스킹된 토큰에 대한 conditional logit $\ell_c^t$와 unconditional logit $\ell_u^t$를 모두 계산한다. 각 [MASK] 토큰의 최종 logit $\ell^t$는 guidance scale $w$를 사용하여 다음과 같이 얻는다.
\[\begin{equation} \ell^t = (1 + w) \ell_c^t - w \ell_u^t \end{equation}\]더 높은 신뢰도로 예측된 이미지 토큰을 보존하고, 낮은 신뢰도로 예측된 토큰을 [MASK] 토큰으로 대체한다. 이 토큰은 모두 다음 라운드 예측을 위해 Show-o로 다시 공급된다. 이 denoising process는 Stable Diffusion의 접근 방식과 유사하게 $T$ step을 거친다.
Experiments
- 구현 디테일
- base model: Phi-1.5
- GPU: A100 (80GB) 48개
- 총 batch size: 1,152 (GPU당 24)
- optimizer: AdamW (weight decay 0.01, warm-up 5,000 step)
- learning rate: $1 \times 10^{-4}$ (cosine scheduling)
- step: 1단계 50만, 2단계 100만
- 사전 학습 후, 해상도를 512$\times$512로 올리기 위해 20억 개의 이미지-텍스트 쌍으로 추가 학습 (50만 step)
- 추가로, LLaVA-v1.5를 따라 instruction data tuning
1. Multimodal Understanding
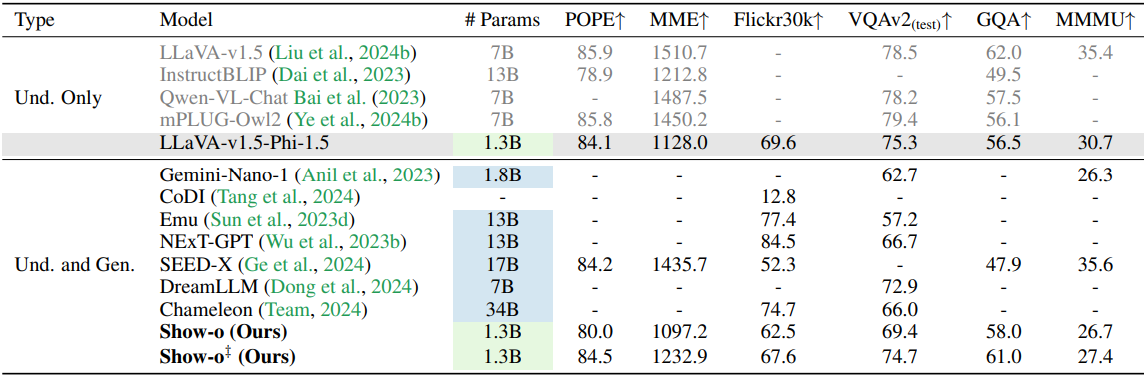
다음은 멀티모달 이해 벤치마크에서의 평가 결과이다.
다음은 다른 모델들과 VQA 능력을 비교한 예시들이다.

2. Visual Generation
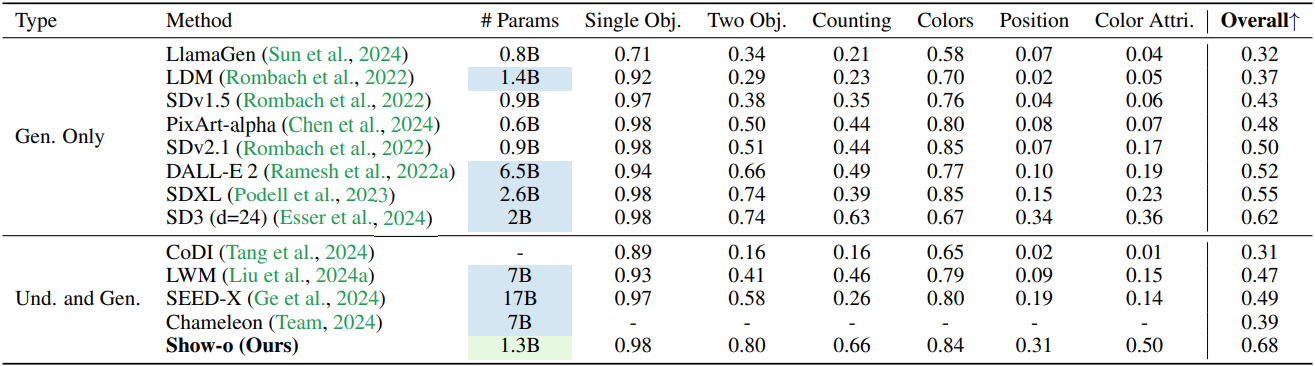
다음은 MSCOCO zero-shot FID를 다른 방법들과 비교한 결과이다.
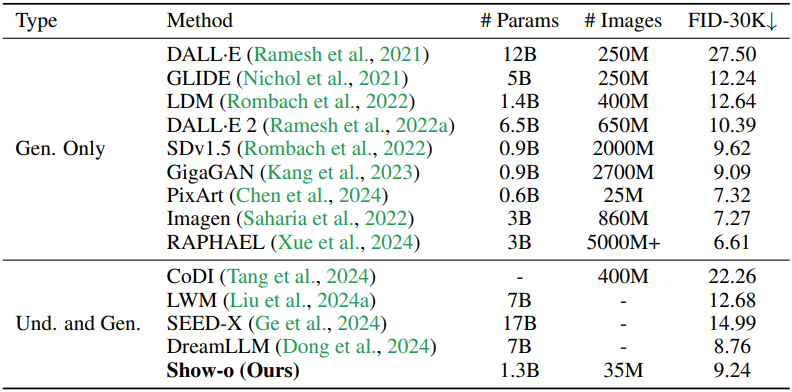
다음은 GenEval 벤치마크에서의 평가 결과이다.
다음은 (위) 다른 모델들과 정성적으로 비교한 결과와 (아래) Show-o로 생성된 512$\times$512 샘플들이다.

다음은 텍스트 기반 이미지 inpainting 및 extrapolation의 예시들이다.

3. Mixed-Modality Generation of Video Keyframes and Captions
다음은 mixed-modality 생성을 통한 (위) 동영상 키프레임 생성과 (아래) 동영상 캡션 생성 예시이다.

4. Ablation Studies
다음은 데이터셋 스케일과 이미지 해상도에 대한 ablation 결과이다.

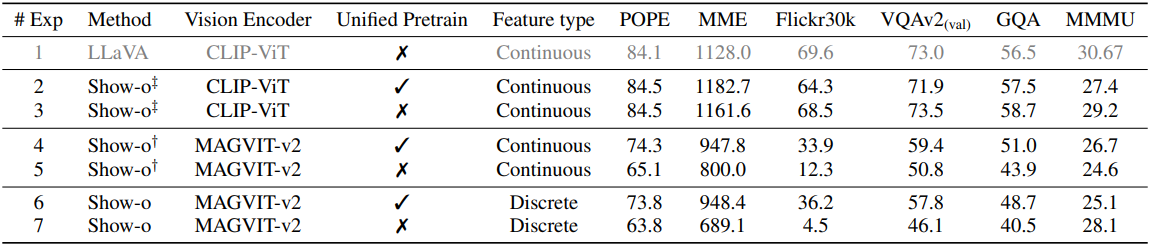
다음은 비전 인코더와 입력 표현에 대한 ablation 결과이다.
다음은 샘플링 step 수와 classifier-free guidance에 대한 영향을 나타낸 것이다.

5. Failure Cases

Show-o는 때때로 텍스트를 정확하게 인식하고 인스턴스 수를 계산하지 못하며 각 인스턴스의 소유물을 생성하는 데 어려움을 겪는다. 이러한 제한은 주로 이러한 시나리오에 맞게 조정된 특정 데이터가 부족하기 때문에 발생하는데, Show-o는 공개적으로 사용 가능한 데이터셋에서 얻은 제한된 이미지-텍스트 쌍에 의존하고 자동 생성된 캡션을 활용하기 때문이다.