[논문리뷰] SharpDepth: Sharpening Metric Depth Predictions Using Diffusion Distillation
CVPR 2025. [Paper] [Page] [Github]
Duc-Hai Pham, Tung Do, Phong Nguyen, Binh-Son Hua, Khoi Nguyen, Rang Nguyen
Qualcomm AI Research | Trinity College Dublin | VinAI
27 Nov 2024

Introduction
최근 여러 생성적 깊이 추정 모델들은 diffusion 기반 text-to-image 모델을 활용하여 높은 공간적 세부 묘사와 선명한 경계를 가진 depth map을 생성한다. 이러한 개선은 대규모 text-to-image 모델에서 물려받은 풍부한 이미지 prior에 기인한다. 그러나 latent diffusion model에 내재된 한계로 인해 이러한 깊이 모델의 fine-tuning은 dense depth map을 사용할 수 있는 합성 데이터에서만 가능하며, 실제 이미지에 적용할 경우 도메인 갭이 발생한다. 또한 이러한 모델들은 정확한 metric depth가 아닌 affine-invariant depth만 제공한다.
본 논문에서는 고주파 디테일을 포함하는 정확한 zero-shot metric depth를 생성하도록 설계된 diffusion 기반 모델인 SharpDepth를 소개한다. Affine-invariant depth estimator를 기반으로 하는 본 방법은 기존 metric depth 모델의 초기 예측을 개선하여 정확한 metric 예측을 유지하면서 깊이 디테일을 향상시킨다. 이를 위해, affine-invariant 모델과 metric depth 모델의 깊이 예측값을 공통 스케일로 정규화하여 일치도를 측정하고, difference map을 생성한다. 이러한 difference map을 통해 신뢰할 수 있는 깊이 예측을 보이는 이미지 영역뿐만 아니라, 추가적인 선명화 및 세부화가 필요한 영역도 식별할 수 있다.
저자들은 difference map에서 불확실하다고 식별된 영역에 깊이 diffusion model이 더욱 정확하게 초점을 맞추도록 가이드하는 Noise-aware Gating 메커니즘을 제안하였다. 이러한 불확실한 영역에서 선명도와 정확한 metric depth를 더욱 보장하기 위해 두 가지 loss function을 사용한다. 먼저, Score Distillation Sampling (SDS) loss를 활용하여 깊이 디테일을 향상시켜 diffusion 기반 깊이 추정 방법과 유사한 선명도를 가진 결과를 얻는다. 그런 다음, diffusion 기반 모델의 스케일 인식 부족을 개선하기 위해 Noise-aware Reconstruction loss를 적용한다. 이 loss는 정규화 도구 역할을 하여 최종 예측이 초기 깊이 추정값에 가깝게 유지되도록 하고, 원래 깊이 스케일에서 벗어나지 않으면서 metric 정확도를 유지한다.
이러한 테크닉을 통해 SharpDepth는 다양한 장면에서 정확하고 높은 디테일의 metric depth 추정을 제공할 수 있다. 위의 학습 loss의 또 다른 이점은 학습을 위한 추가적인 GT 없이 사전 학습된 깊이 모델만을 사용하여 실제 데이터에 대한 개선을 학습시킬 수 있다는 것이다.
Method
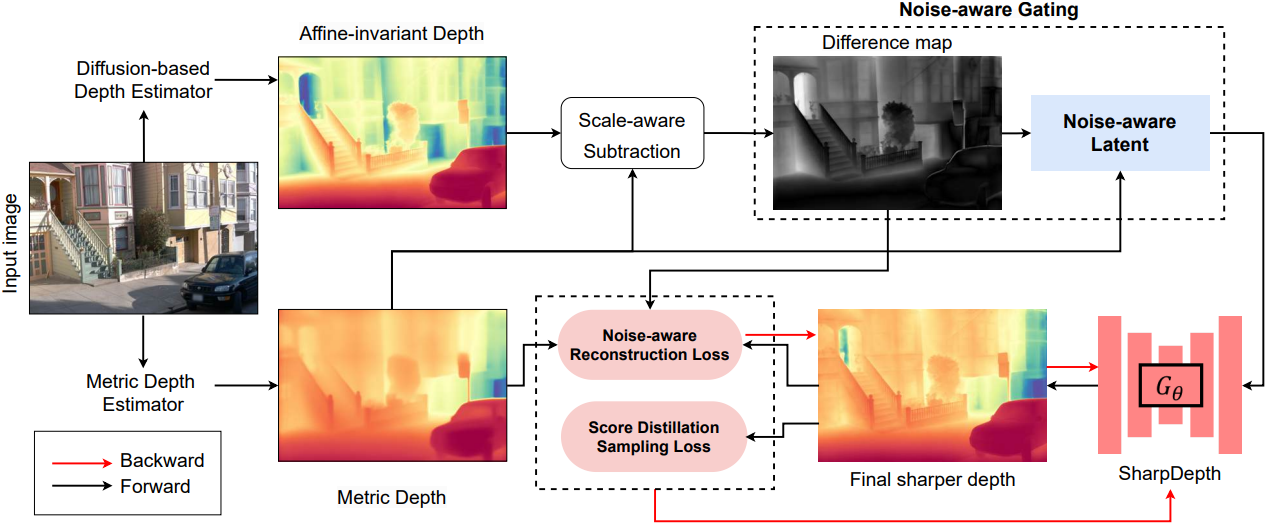
입력 이미지 $\mathcal{I}$가 주어지면, 먼저 사전 학습된 metric depth 모델 $f_D$와 diffusion 기반 깊이 모델 $f_G$를 사용하여 metric depth $d$와 affine-invariant depth $\tilde{d}$를 각각 생성한다. 본 논문의 목표는 제안된 sharpening 모델 \(\textbf{G}_\theta\)를 사용하여 디테일이 향상된 metric depth map $\hat{d}$를 생성하는 것이다. 이 모델 아키텍처는 사전 학습된 깊이 diffusion model을 기반으로 한다.
Diffusion model의 forward process에 단순하게 의존하는 대신, 불확실한 영역에서 sharpening 모델 \(\textbf{G}_\theta\)에 명시적인 guidance를 제공하는 Noise-aware Gating 메커니즘을 도입하였다. GT에 구애받지 않는 fine-tuning을 위해, 사전 학습된 $f_G$에서 SDS loss를 사용하여 세밀한 디테일을 추출하고, Noise-aware Reconstruction loss를 사용하여 정확한 metric 예측을 보장한다.
1. Noise-aware Gating
본 논문의 목표는 네트워크가 선명도가 필요한 영역을 식별할 수 있도록 하는 메커니즘을 개발하는 것이다. 전반적으로 선명한 디테일을 유지하면서 픽셀당 GT metric depth를 얻기 어렵기 때문에, diffusion 기반 깊이 모델과 metric depth 추정 모델 모두에서 얻은 통찰력을 결합하는 접근 방식을 채택하였다. 직관적으로, 이러한 모델 간의 차이가 최소인 영역은 더 신뢰할 수 있는 반면, 차이가 큰 영역은 추가 학습이 필요하다고 가정한다.
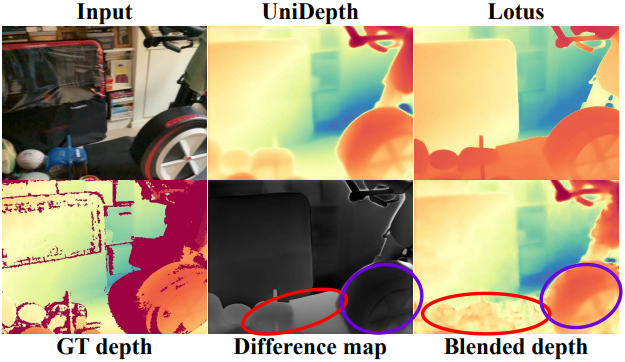
구체적으로, metric depth 추정 모델로 UniDepth를, diffusion 기반 깊이 추정 모델로 Lotus를 사용한다. UniDepth는 Lotus 보다 선명한 디테일이 부족하지만 상당히 정확한 깊이 예측을 제공한다. 위 그림에서 볼 수 있듯이, 먼저 이러한 예측을 정규화한 다음 두 개의 depth map 간의 difference map을 계산한다. Difference map에서 더 밝은 영역은 상당한 불일치가 있는 영역을 강조하여 추가 디테일이 필요한 영역을 나타낸다. 반대로, 어두운 영역은 두 깊이 추정 모델 간에 상호 동의가 있는 영역을 나타낸다. 이러한 영역도 깊이 개선의 이점을 얻을 수 있지만, 선명화 과정에서는 우선순위가 낮다.
저자들은 초기 metric depth $d$의 정보를 \(\textbf{G}_\theta\) 모델에 입력으로 통합하는 Noise-aware Gating 메커니즘을 제안하였다. 기존의 여러 논문들에서 관심 영역에 초점을 맞추도록 diffusion model을 유도하기 위해 명시적 마스크를 사용해 왔다. 저자들은 여기에 영감을 받아, 깨끗한 latent depth의 모든 픽셀에 Gaussian noise를 추가하는 것을 피하였다. 대신, 차이가 큰 영역에는 noise를 선택적으로 적용하고, 차이가 작은 영역에는 noise를 덜 적용한다. 이 전략은 \(\textbf{G}_\theta\)가 차이가 큰 영역에 초점을 맞추고, 차이가 작은 영역은 대부분 영향을 받지 않도록 효과적으로 제어한다.
$\tilde{d}$와 $d$의 깊이 범위를 정렬하기 위해, difference map을 계산하기 전에 먼저 $\tilde{d}$를 $d$의 범위로 scale 및 shift한다. 그런 다음 difference map $e$는 조정된 $\tilde{d}$와 $d$의 차이로 계산된다. 학습이 진행됨에 따라, \(\textbf{G}_\theta\)가 diffusion 기반 모델 $f_G$보다 우수한 depth map을 생성하기 시작한다. 결과적으로, $f_G$를 \(\textbf{G}_\theta\)의 exponential moving average (EMA) $\textbf{G}_{\bar{\theta}}$로 대체한다. 이는 $\tilde{d}$에 대한 정제된 초기화 역할을 하며 여러 단계로 반복적인 정제를 가능하게 한다.
Difference map $e$를 구하면, 이를 이용하여 $d$의 latent인 $z_d$의 각 영역에 적용되는 noise 강도를 제어한다. 구체적으로, Gaussian noise $\epsilon$과 $z_d$ 사이에 다음과 같은 가중 블렌딩을 수행한다.
\[\begin{equation} z_d^\prime = \hat{e} \odot \epsilon + (1 - \hat{e}) \odot z_d \end{equation}\]($\hat{e}$는 $e$를 $z_d$와 동일한 해상도로 다운샘플링된 버전, $\odot$은 element-wise multiplication)
이 혼합된 latent $z_d^\prime$은 두 깊이 예측 간의 차이가 큰 영역과 작은 영역을 효과적으로 구분하여 선명도 향상을 위한 강력한 prior 역할을 한다. 이러한 영역을 분리함으로써 최적화 프로세스는 차이가 적은 영역의 수정을 최소화하면서 차이가 큰 영역에 집중하여 선명도가 유지되는 동시에 디테일을 세밀하게 재구성할 수 있다.
2. Training Objectives
Diffusion Depth Prior Distillation
저자들은 SwiftBrush와 DreamFusion에서 영감을 받아 \(\textbf{G}_\theta\)를 처음부터 학습시키지 않고 $f_G$와 같은 사전 학습된 diffusion 기반 깊이 추정 모델에 score distillation을 수행하였다. 제안된 모델의 예측 latent 출력 $\hat{z}$는 다음과 같이 계산된다.
\[\begin{equation} \hat{z} = \textbf{G}_\theta (z_d^\prime, z_i) \end{equation}\]($z_i$는 이미지의 latent)
저자들은 $f_G$의 $x_0$-prediction에 맞도록 $\epsilon$-prediction을 사용하는 원래 SDS 공식을 약간 수정하였다.
\[\begin{equation} \nabla_\theta \mathcal{L}_\textrm{SDS} = \mathbb{E}_{t, \epsilon} \left[ w^t \left( \hat{z} - f_G (\hat{z}^t; z_i, t) \right) \right] \end{equation}\]($\hat{z}^t$는 timestep $t$에서 $\hat{z}$의 noisy 버전)
Noise-aware Reconstruction Loss
본 논문의 distillation 목적은 \(\textbf{G}_\theta\)의 출력이 diffusion model $f_G$의 분포와 더욱 밀접하게 일치하도록 유도하여 매우 상세한 depth map을 생성하는 것이다. 그러나 이로 인해 네트워크는 $f_G$의 한계를 그대로 물려받게 되어 궁극적으로 metric depth 추정의 정확도가 저하된다. 이 문제를 해결하기 위해, 저자들은 \(\textbf{G}_\theta\)의 출력과 $f_D$의 출력 사이의 거리를 측정하여 metric depth 모델의 정확도를 유지하는 추가적인 reconstruction loss를 도입하였다.
구체적으로, $d$와 $\hat{d}$가 유의미한 차이를 보이는 영역에 더 큰 gradient를 적용하기 위해 difference map $e$를 사용한다. 이는 명시적인 정규화 메커니즘으로 작용하여 \(\textbf{G}_\theta\) 이러한 픽셀에 더 집중하도록 한다. Difference map은 차이가 거의 없는 영역은 거의 변하지 않도록 보장하지만, $\hat{d}$로 over-smoothing 아티팩트가 전파될 위험이 있다. Reconstruction loss는 다음과 같다.
\[\begin{equation} \mathcal{L}_\textrm{recons} = \| e \odot (\hat{d} - d) \| \end{equation}\]위의 두 loss는 서로 다른 목적을 가지고 있다. \(\mathcal{L}_\textrm{SDS}\)는 깊이 디테일을 향상시키고 \(\mathcal{L}_\textrm{recons}\)는 정확한 깊이 값을 보장하는 것이다. 하지만 두 함수 모두 차이가 큰 영역에 초점을 맞춘다. \(\mathcal{L}_\textrm{SDS}\)는 차이가 큰 영역을 강조하여 암시적인 마스킹 최적화로 기능한다. 이와 대조적으로, \(\mathcal{L}_\textrm{recons}\)는 최적화 과정에서 difference map을 직접 사용하며, 이는 명시적 마스킹 최적화 방식과 유사하다.
전체 학습 loss는 \(\mathcal{L}_\textrm{SDS}\)와 \(\mathcal{L}_\textrm{recons}\)로 구성된다.
\[\begin{equation} \mathcal{L}_\textrm{total} = \lambda_\textrm{SDS} \mathcal{L}_\textrm{SDS} + \lambda_\textrm{recons} \mathcal{L}_\textrm{recons} \end{equation}\]Experiments
- 데이터셋: Pandaset, Waymo, ArgoVerse2, ARKit, Taskonomy, ScanNetv2
- 각 데이터셋의 약 1%를 사용하여 총 9만 장의 이미지를 학습에 사용
- 구현 디테일
- optimizer: Adam
- learning rate: $10^{-6}$
- \(\lambda_\textrm{SDS} = 1.0\), \(\lambda_\textrm{recons} = 0.3\)
- iteration: 13,000
- batch size: 1
- gradient accumulation step: 16
- GPU: A100 40GB 2개로 약 1.5일 소요
- $f_D$의 metric depth는 VAE 인코더에 들어가지 전 $[-1, 1]$로 정규화, 디코딩 후 복원
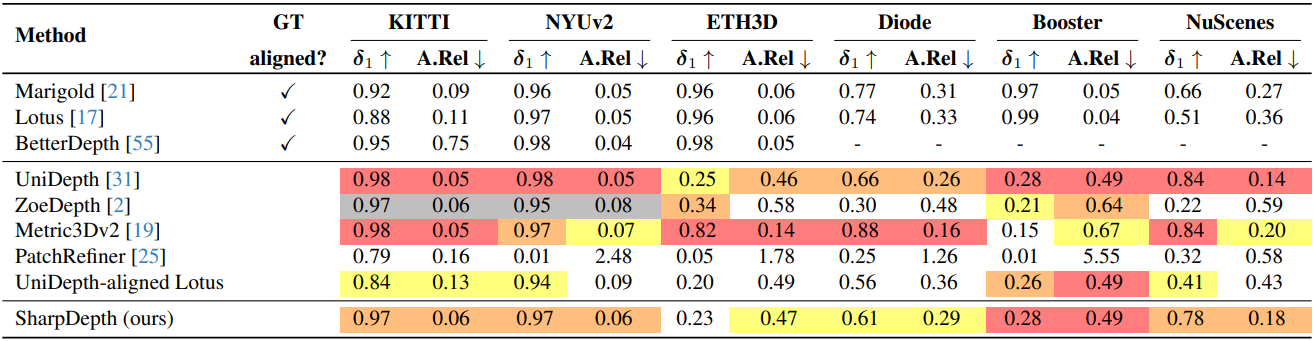
1. Comparison with the State of the Art
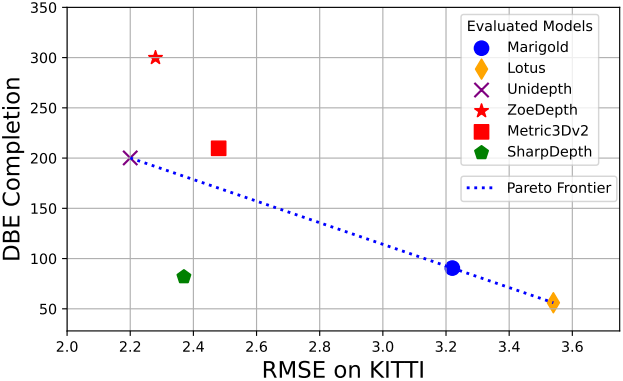
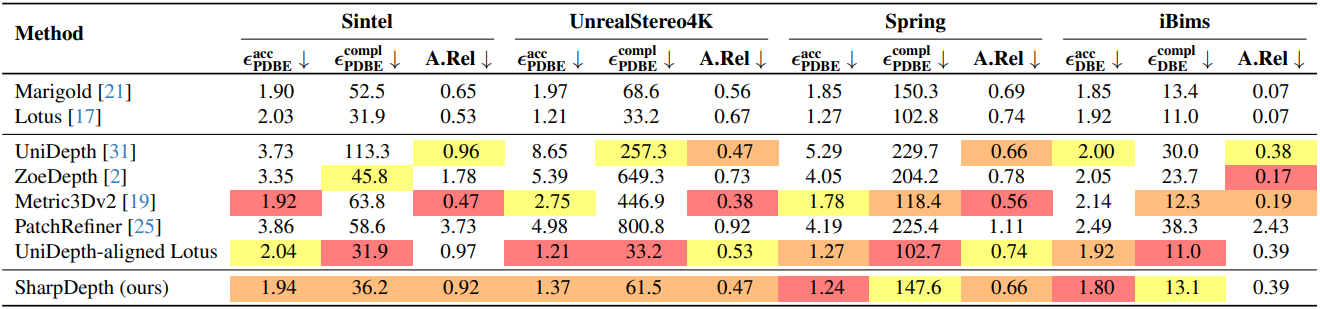
다음은 깊이 정확도를 비교한 결과이다.
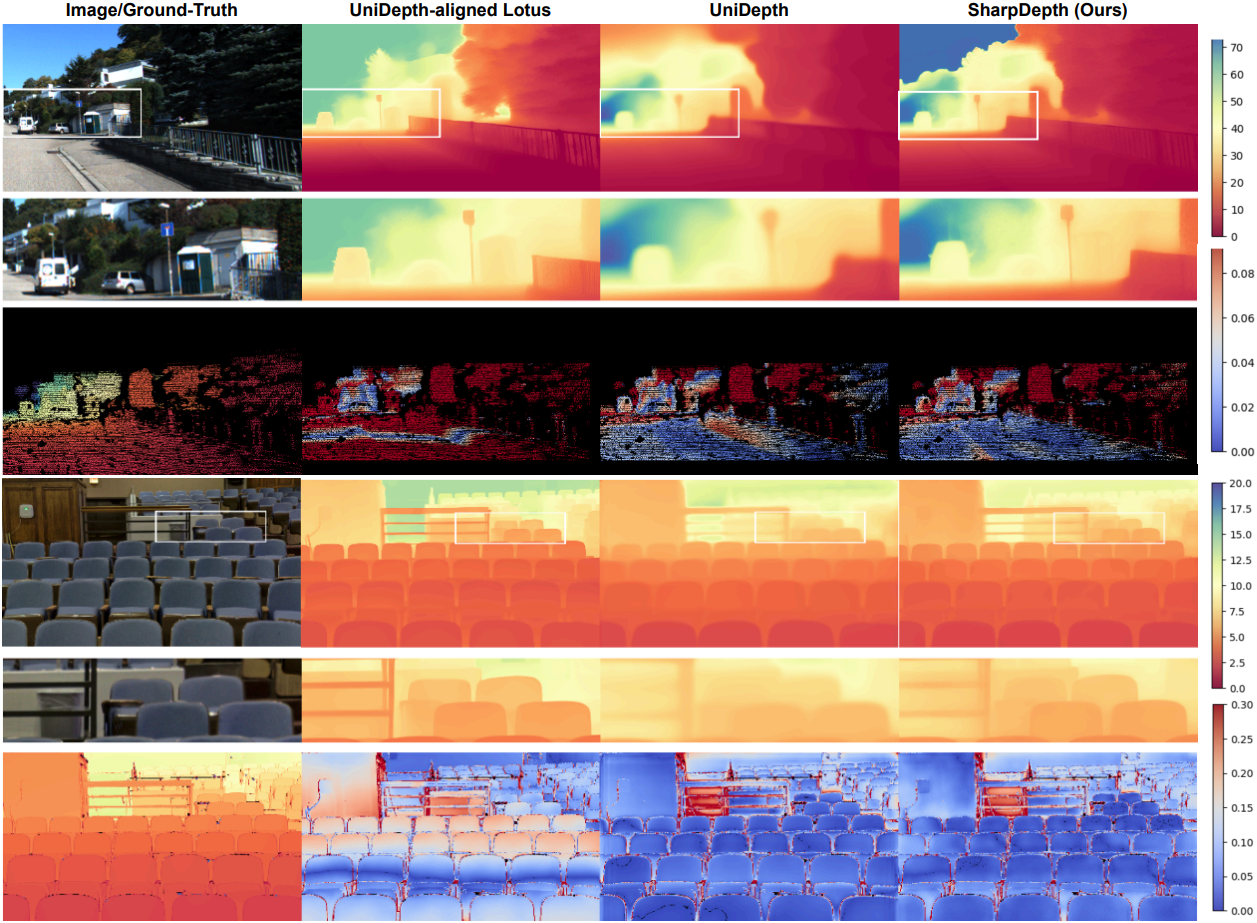
다음은 깊이 디테일을 비교한 결과이다.
다음은 실제 이미지에 대한 깊이 추정 결과를 unprojection하여 얻은 포인트 클라우드를 비교한 예시이다.

2. Ablation Study
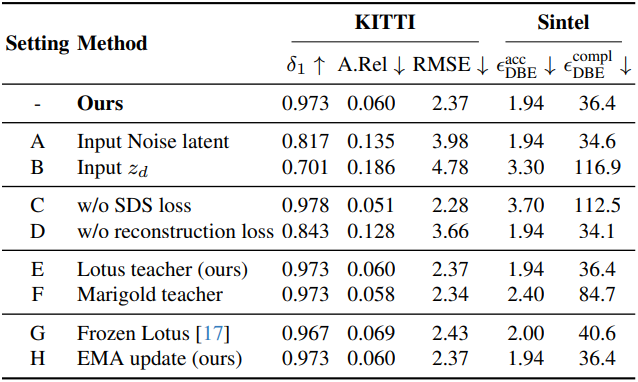
다음은 ablation study 결과이다.
다음은 사전 학습된 teacher 모델에 대한 효과를 비교한 예시이다.
