[논문리뷰] Shap·E: Generating Conditional 3D Implicit Functions
arXiv 2023. [Paper] [Github]
Heewoo Jun, Alex Nichol
OpenAI
3 May 2023

Introduction
최근 생성 이미지 모델이 폭발적으로 증가함에 따라 오디오, 동영상, 3D 에셋과 같은 다른 modality에 대해 유사한 생성 모델을 학습하는 데 대한 관심이 높아지고 있다. 이러한 modality의 대부분은 이미지의 픽셀 그리드나 오디오의 샘플 배열과 같이 직접 생성할 수 있는 자연스럽고 고정된 크기의 텐서 표현에 적합하다. 그러나 효율적으로 생성하고 하위 애플리케이션에서 사용하기 쉬운 방식으로 3D 에셋을 표현하는 방법은 명확하지 않다.
최근 implicit neural representation (INR)은 3D 에셋을 인코딩하는 데 널리 사용된다. 3D 에셋을 나타내기 위해 INR은 일반적으로 3D 좌표를 밀도 및 색상과 같은 위치별 정보에 매핑한다. 일반적으로 INR은 고정 그리드 또는 시퀀스로 정보를 인코딩하는 대신 임의의 입력 지점에서 쿼리할 수 있기 때문에 해상도에 독립적이라고 생각할 수 있다. End-to-end로 미분 가능하기 때문에 INR은 style transfer 및 미분 가능한 모양 편집과 같은 다양한 하위 애플리케이션도 가능하게 한다. 본 논문에서는 3D 표현을 위한 두 가지 유형의 INR에 중점을 둔다.
- Neural Radiance Field (NeRF)는 밀도 및 RGB 색상에 좌표와 view 방향을 매핑하는 함수로 3D 장면을 나타내는 INR이다. NeRF는 카메라 광선을 따라 밀도와 색상을 쿼리하여 임의의 view에서 렌더링할 수 있으며 3D 장면의 실제 렌더링과 일치하도록 학습된다.
- DMTet와 확장된 버전인 GET3D는 질감이 있는 3D mesh를 색상, 부호 있는 거리 및 정점 오프셋에 좌표를 매핑하는 함수로 나타낸다. 이 INR은 미분 가능한 방식으로 3D 삼각형 mesh를 구성하는 데 사용할 수 있으며 결과 mesh는 미분 가능한 rasterization 라이브러리를 사용하여 효율적으로 렌더링할 수 있다.
INR은 유연하고 표현력이 뛰어나지만 데이터셋의 각 샘플에 대해 INR을 획득하는 프로세스는 비용이 많이 들 수 있다. 또한 각 INR에는 많은 수치적 파라미터가 있을 수 있으므로 하위 생성 모델을 학습할 때 잠재적으로 문제가 될 수 있다. 일부 연구들은 기존 생성 기술로 직접 모델링할 수 있는 더 작은 latent representation을 얻기 위해 implicit decoder와 함께 autoencoder를 사용하여 이러한 문제에 접근한다. From data to functa 논문은 meta-learning을 사용하여 대부분의 파라미터를 공유하는 INR 데이터셋을 생성한 다음 이러한 INR의 자유 파라미터에 대해 diffusion model 또는 normalizing flow를 학습시키는 대체 접근 방식을 제시한다. Transformers as Meta-Learners for Implicit Neural Representations 논문은 기울기 기반 meta-learning이 전혀 필요하지 않을 수 있으며 대신 Transformer 인코더를 직접 학습하여 3D 개체의 여러 view로 컨디셔닝된 NeRF 파라미터를 생성할 수 있다고 제안한다.
본 논문은 다양하고 복잡한 3D implicit representation을 위한 조건부 생성 모델인 Shap·E에 도달하기 위해 위의 여러 접근 방식을 결합하고 확장한다. 먼저 3D 에셋에 대한 INR 파라미터를 생성하도록 Transformer 기반 인코더를 학습시킨다. 다음으로 인코더의 출력에 대해 diffusion model을 학습한다. 이전 접근 방식과 달리 NeRF와 mesh를 동시에 나타내는 INR을 생성하여 여러 방식으로 렌더링하거나 하위 3D 애플리케이션으로 가져올 수 있다.
수백만 개의 3D 에셋으로 구성된 데이터셋에서 학습할 때 Shap·E는 텍스트 프롬프트에 따라 다양하고 인식 가능한 샘플을 생성할 수 있다. 최근에 제안된 explicit 3D 생성 모델인 Point·E와 비교할 때, Shap·E는 더 빠르게 수렴하고 동일한 모델 아키텍처, 데이터셋, 컨디셔닝 메커니즘을 공유하면서 유사하거나 우수한 결과를 얻는다.
놀랍게도 Shap·E와 Point·E가 이미지를 조건으로 할 때 성공 사례와 실패 사례를 공유하는 경향이 있다고 한다. 이는 매우 다른 출력 표현 선택이 여전히 유사한 모델 동작으로 이어질 수 있음을 시사한다. Point·E와 마찬가지로 Shap·E의 샘플 품질은 여전히 텍스트 조건부 3D 생성을 위한 최적화 기반 접근 방식에 미치지 못한다. 그러나 이러한 접근 방식보다 inference 시간이 훨씬 빠르므로 잠재적으로 유리한 trade-off가 가능하다.
Method
먼저 implicit representation을 생성하도록 인코더를 학습한 다음 인코더에 의해 생성된 latent representation에 대한 diffusion model을 학습한다. 본 논문의 방법은 두 단계로 진행된다.
- 알려진 3D 에셋의 dense한 explicit representation이 주어진 implicit function의 파라미터를 생성하도록 인코더를 학습시킨다. 특히, 인코더는 MLP의 가중치를 얻기 위해 선형으로 project되는 3D 에셋의 latent representation을 생성한다.
- 인코더를 데이터셋에 적용하여 얻은 latent 데이터셋에서 diffusion prior를 학습시킨다. 이 모델은 이미지 또는 텍스트 설명으로 컨디셔닝된다.
렌더링, point cloud, 텍스트 캡션이 있는 3D 에셋의 대규모 데이터셋에서 모든 모델을 학습시킨다.
1. Dataset
대부분의 실험에서 Point·E와 동일한 기본 3D 에셋 데이터셋을 사용하여 더 공정한 비교를 가능하게 한다. 그러나 후처리를 다음과 같이 약간 확장한다.
- Point cloud 컴퓨팅을 위해 각 객체의 20개 대신 60개 view를 렌더링한다. 20개의 view만 사용하면 때때로 추론된 point cloud에 작은 균열(맹점으로 인해)이 발생한다.
- 4K 대신 16K개의 점으로 point cloud를 생성한다.
- 인코더 학습을 위해 view를 렌더링할 때 조명과 재료를 단순화한다. 특히 모든 모델은 diffusion과 주변 음영만 지원하는 고정된 조명 설정으로 렌더링된다. 이렇게 하면 differentiable renderer와 조명 설정을 더 쉽게 일치시킬 수 있다.
텍스트 조건부 모델 및 해당 Point·E basline에 대해 기본 3D 에셋 및 텍스트 캡션의 확장된 데이터셋을 사용한다. 이 데이터셋의 경우 고품질 데이터 소스에서 약 100만 개의 3D 에셋을 추가로 수집했다. 또한 데이터셋의 고품질 하위 집합을 위해 인간 레이블러로부터 120,000개의 캡션을 수집했다. Text-to-3D 모델을 학습하는 동안 인간이 제공한 레이블과 원래 텍스트 캡션이 모두 사용 가능한 경우 랜덤하게 선택한다.
2. 3D Encoder
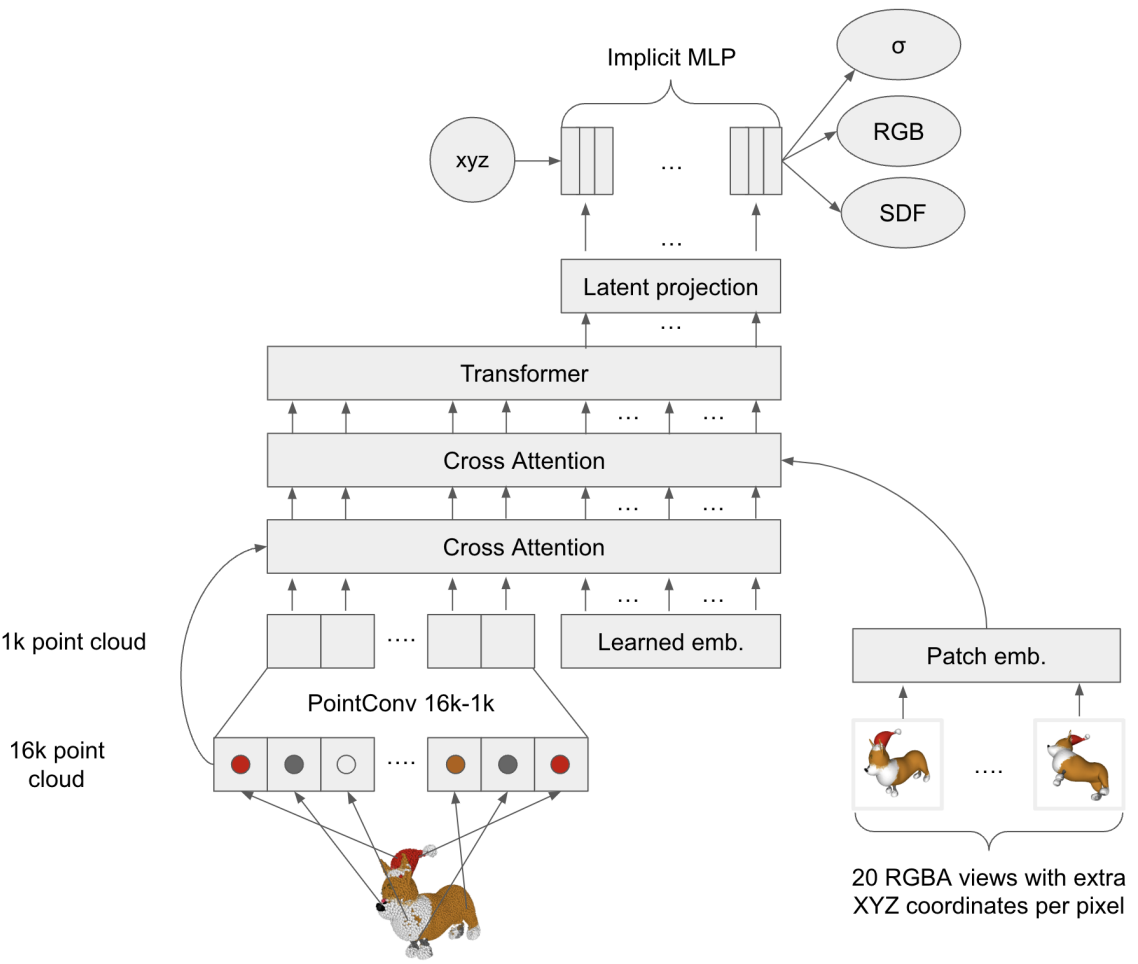
인코더 아키텍처는 위 그림에 시각화되어 있다. Point cloud와 3D 에셋의 렌더링된 view를 모두 인코더에 제공하고 에셋을 implicit function으로 나타내는 MLP의 파라미터를 출력한다. Point cloud와 입력 view는 모두 cross-attention을 통해 처리되며, 그 뒤에 latent representation을 벡터 시퀀스로 생성하는 Transformer backbone이 뒤따른다. 이 시퀀스의 각 벡터는 출력이 MLP 가중치 행렬의 단일 행으로 처리되는 latent bottleneck과 projection layer를 통과한다. 학습 중에 MLP가 쿼리되고 출력이 이미지 reconstruction loss 또는 distillation loss에 사용된다.
NeRF 렌더링 목적 함수만 사용하여 인코더를 사전 학습하며, 이것이 mesh 기반 목적 함수보다 최적화하기에 더 안정적이기 때문이다. NeRF 사전 학습 후 SDF 및 텍스처 색상 예측을 위한 추가 output head를 추가하고 2단계 프로세스를 사용하여 이러한 head를 학습시킨다.
Decoding with NeRF Rendering
Coarse model과 fine model 간에 파라미터를 공유한다는 점을 제외하고는 대부분 원래 NeRF 공식을 따른다. 각 학습 예제에 대해 4096개의 광선을 무작위로 샘플링하고 실제 색상 $C(r)$과 NeRF에 의해 예측된 색상 사이의 $L_1$ loss를 최소화한다.
\[\begin{equation} L_\textrm{RGB} = \mathbb{E}_{r} [\| \hat{C}_c (r) - C(r) \|_1 + \| \hat{C}_f (r) - C (r) \|_1] \end{equation}\]또한 각 광선의 투과율에 대한 loss를 추가한다. 특히, 광선의 통합 밀도로 coarse 렌더링과 fine 렌더링 각각에 대한 투과율 추정치 \(\hat{T}_c (r)\)와 \(\hat{T}_f (r)\)를 얻는다. Ground-truth 렌더링의 알파 채널을 사용하여 투과율 타겟 $T(r)$를 얻고 두 번째 loss를 얻는다.
\[\begin{equation} L_T = \mathbb{E}_{r} [\| \hat{T}_c (r) - T(r) \|_1 + \| \hat{T}_f (r) - T (r) \|_1] \end{equation}\]전체 목적 함수는 다음과 같다.
\[\begin{equation} L_\textrm{NeRF} = L_\textrm{RGB} + L_T \end{equation}\]Decoding with STF Rendering
NeRF 전용 사전 학습 후 SDF 값과 텍스처 색상을 예측하는 MLP에 추가 STF output head를 추가한다. 삼각형 mesh를 구성하기 위해 $128^3$ 그리드를 따라 정점에서 SDF를 쿼리하고 Marching Cubes 33의 미분 가능한 구현을 적용한다. 그런 다음 결과 mesh의 각 정점에서 텍스처 색상 head를 쿼리한다. PyTorch3D를 사용하여 결과 텍스처 mesh를 렌더링한다. 항상 데이터 셋를 전처리하는 데 사용되는 조명 설정과 동일한 조명 설정으로 렌더링한다.
저자들은 예비 실험에서 랜덤하게 초기화된 STF output head가 불안정하고 렌더링 기반 목적 함수로 학습하기 어렵다는 것을 발견했다. 이 문제를 완화하기 위해 먼저 differentiable rendering으로 직접 학습하기 전에 SDF 및 텍스처 색상의 근사치를 output head로 추출한다. 특히 Point·E SDF 회귀 모델을 사용하여 입력 좌표를 임의로 샘플링하고 SDF distillation 타겟을 얻고 에셋의 RGB point cloud에서 nearest neighbor의 색상을 사용하여 RGB 타겟을 얻는다. Distillation 학습 중에 distillation loss와 사전 학습 NeRF loss의 합을 사용한다.
\[\begin{equation} L_\textrm{distill} = L_\textrm{NeRF} + \mathbb{E}_{x \sim U[-1, 1]^3} [\| \textrm{SDF}_\theta (x) - \textrm{SDF}_\textrm{regression} (x) \|_1 + \| \textrm{RGB}_\theta (x) - \textrm{RGB}_\textrm{NN}(x) \|_1] \end{equation}\]STF output head가 distillation을 통해 합리적인 값으로 초기화되면 NeRF와 STF 렌더링 end-to-end 모두에 대해 인코더를 fine-tuning한다. STF 렌더링에 $L_1$ loss를 사용하는 것이 불안정하기 때문에 대신 이 렌더링 방법에만 $L_2$ loss를 사용한다. 특히 STF 렌더링을 위해 다음과 같은 loss를 최적화한다.
\[\begin{equation} L_\textrm{SFT} = \frac{1}{N \cdot s^2} \sum_{i=1}^N \| \textrm{Render} (\textrm{Mesh}_i) - \textrm{Image}_i \|_2^2 \end{equation}\]여기서 $N$은 이미지의 개수, $s$는 이미지 해상도이다. $\textrm{Mesh}_i$는 샘플 $i$에 대하여 구성된 mesh이고 $\textrm{Image}_i$는 이미지 $i$에 대한 타겟 RGBA 렌더링이다. $\textrm{Render}(x)$는 differentiable renderer를 사용하여 mesh를 렌더링한다. 이미 이미지의 알파 채널에 의해 투과율이 캡처되었기 때문에 별도의 투과율 loss는 포함하지 않는다.
이 최종 fine-tuning 단계에서는 합산된 목적 함수를 최적화한다.
\[\begin{equation} L_\textrm{FT} = L_\textrm{NeRF} + L_\textrm{SFT} \end{equation}\]3. Latent Diffusion
생성 모델의 경우 Point·E의 Transformer 기반 diffusion 아키텍처를 채택하지만 point cloud를 latent 벡터 시퀀스로 대체한다. Latent는 1024$\times$1024 모양의 시퀀스이며 각 토큰이 MLP 가중치 행렬의 다른 행에 해당하는 1024 토큰 시퀀스로 Transformer에 공급한다. 결과적으로 모델은 입력 및 출력 채널의 증가로 인해 훨씬 더 높은 차원의 space에서 샘플을 생성하면서 base Point·E 모델과 대략적으로 계산 동등하다.
Point·E와 동일한 컨디셔닝 전략을 따른다. 이미지 조건부 생성을 위해 Transformer 컨텍스트 앞에 토큰이 256개인 CLIP 임베딩 시퀀스를 추가한다. 텍스트 조건부 생성을 위해 CLIP 텍스트 임베딩을 포함하는 단일 토큰을 추가한다. Classifier-free guidance를 지원하기 위해 학습하는 동안 확률 0.1로 컨디셔닝 정보를 0으로 설정한다.
Point·E와 달리 diffusion model 출력을 예측으로 parameterize하지 않고, 대신 $x_0$을 직접 예측한다. 이는 대수적으로는 예측과 동일하지만 초기 실험에서 더 일관된 샘플을 생성했다고 한다.
Results
1. Encoder Evaluation
다음은 학습의 각 stage 이후에 인코더를 평가한 표이다.

2. Comparison to Point·E
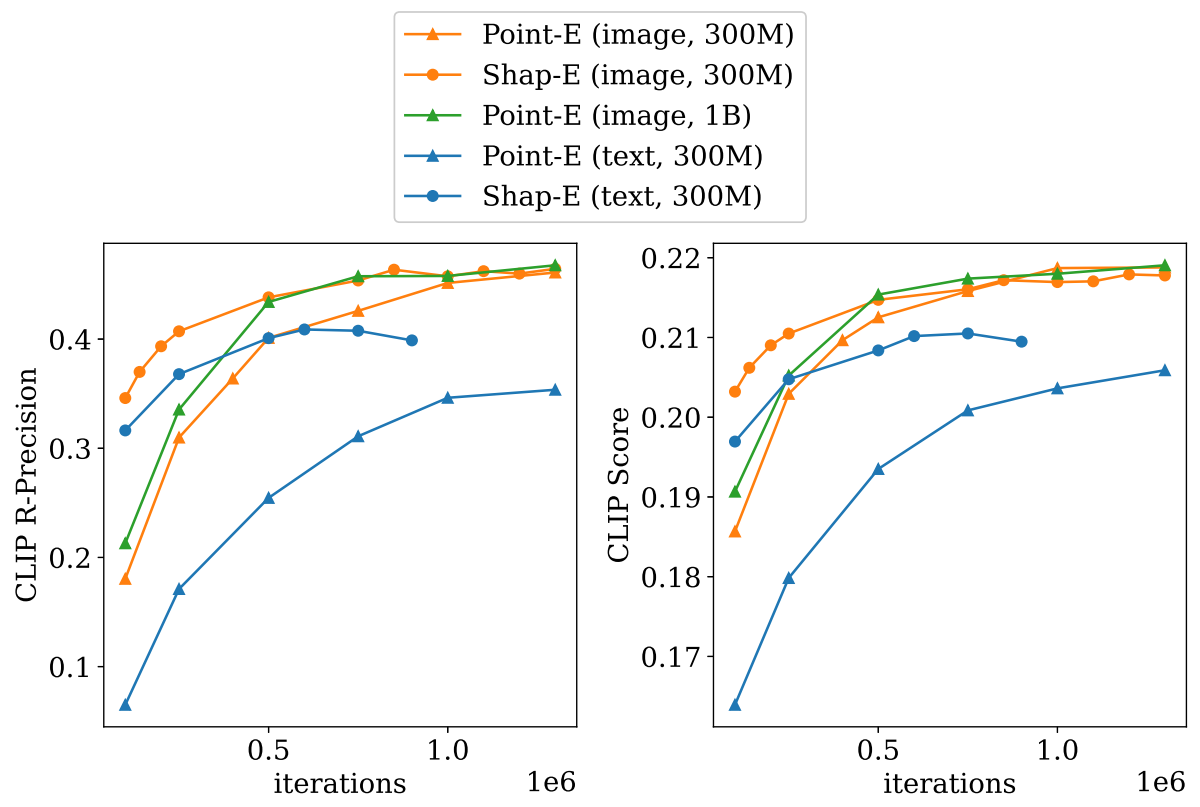
다음은 학습 중에 Shap·E와 Point·E를 평가한 그래프이다.
다음은 텍스트 조건부 Shap·E 및 Point·E의 샘플들이다.

다음은 이미지 조건부 Shap·E 및 Point·E의 공유된 실패 케이스(왼쪽)와 공유된 성공 케이스(오른쪽)이다.

3. Comparison to Other Methods
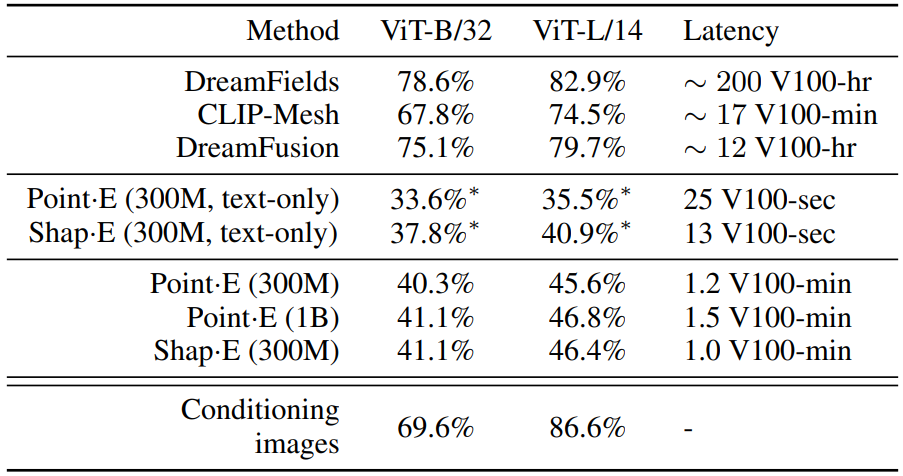
다음은 여러 3D 생성 기술들과 비교한 표이다.
Limitations
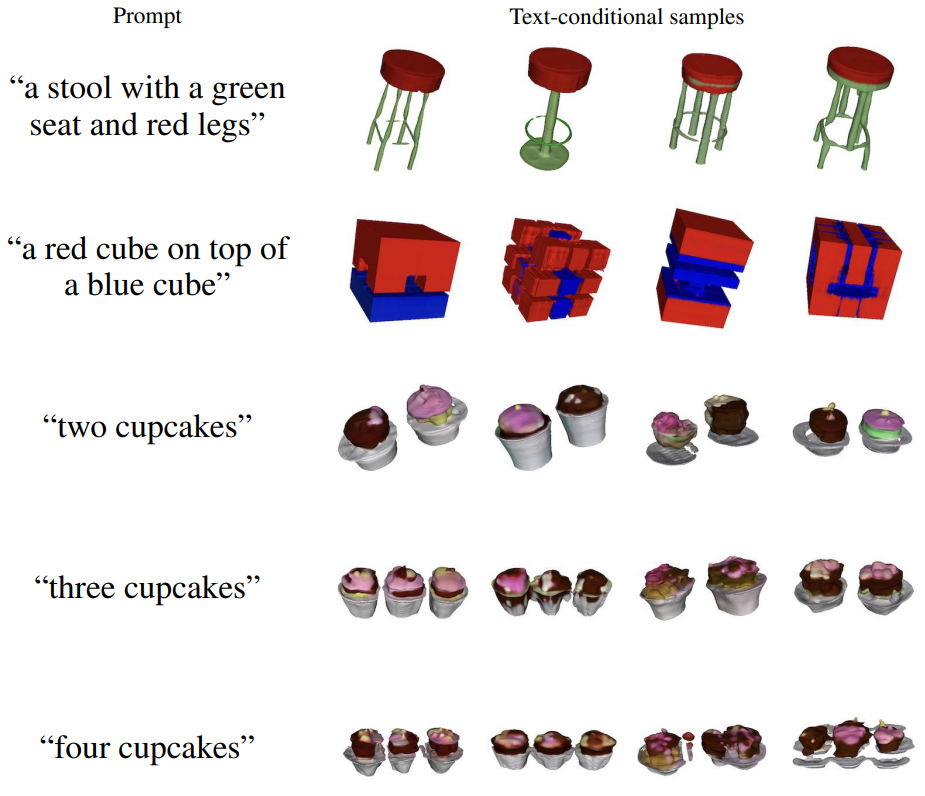
위 그림에서 Shap·E가 여러 속성을 서로 다른 개체에 바인딩하는 데 어려움을 겪고 있으며 세 개 이상을 요청할 때 정확한 수의 개체를 안정적으로 생성하지 못한다는 것을 알 수 있다.
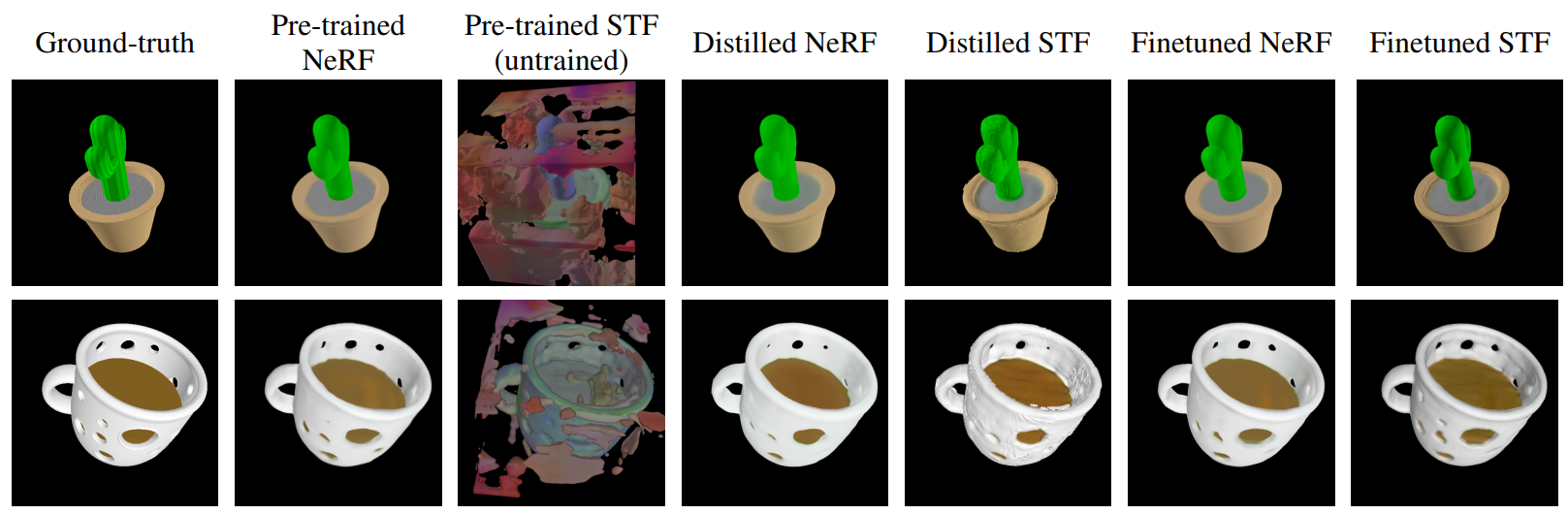
또한 Shap·E는 종종 인식 가능한 3D 에셋을 생성할 수 있지만 결과 샘플은 종종 거칠게 보이거나 세밀한 디테일이 부족하다. 특히, 위 그림은 인코더 자체가 때때로 상세한 텍스처(ex. 선인장의 줄무늬)를 잃는다는 것을 보여준다.