[논문리뷰] Semi-DETR: Semi-Supervised Object Detection with Detection Transformers
CVPR 2023. [Paper] [Github]
Jiacheng Zhang, Xiangru Lin, Wei Zhang, Kuo Wang, Xiao Tan, Junyu Han, Errui Ding, Jingdong Wang, Guanbin Li
Sun Yat-sen University | Baidu Inc.
16 Jul 2023
Introduction
Semi-supervised object detection (SSOD)는 레이블이 지정되지 않은 대량의 데이터를 활용하여 fully-supervised object detector의 성능을 향상시키는 것을 목표로 한다. 현재의 SOTA SSOD 방법은 주로 규칙 기반 label assigner와 Non-Maximum Suppression (NMS) 후처리와 같이 많은 hand-crafted 구성 요소가 포함된 object detector에 기반을 두고 있다. 이러한 유형의 object detector를 전통적인 object detector라고 부른다. 최근에는 간단한 transformer 기반의 end-to-end object detector인 DETR이 주목을 받고 있다. 일반적으로 DETR 기반 프레임워크는 transformer 인코더-디코더 아키텍처를 기반으로 구축되며 학습 중 이분 매칭 (bipartite matching)을 통해 집합 기반 글로벌 loss를 적용하여 고유한 예측을 생성한다. 다양한 hadn-crafted 구성 요소가 필요하지 않으며 fully-supervised object detection에서 SOTA 성능을 달성하였다. 성능은 바람직하지만 실행 가능한 DETR 기반 SSOD 프레임워크를 설계하는 방법은 아직 충분히 연구되지 않은 상태이다.
DETR 기반 detector를 위한 SSOD 프레임워크를 설계하는 것은 쉽지 않다. 구체적으로, DETR 기반 detector는 이분 매칭 알고리즘이 각 ground-truth (GT) bounding box가 후보 proposal을 positive로 일치시키고 나머지는 negative들로 처리하도록 하는 일대일 할당 전략을 사용한다. GT bounding box가 정확하면 잘 작동한다. 그러나 DETR 기반 프레임워크를 SSOD와 직접 통합하는 것은 문제가 있ㄴ다.
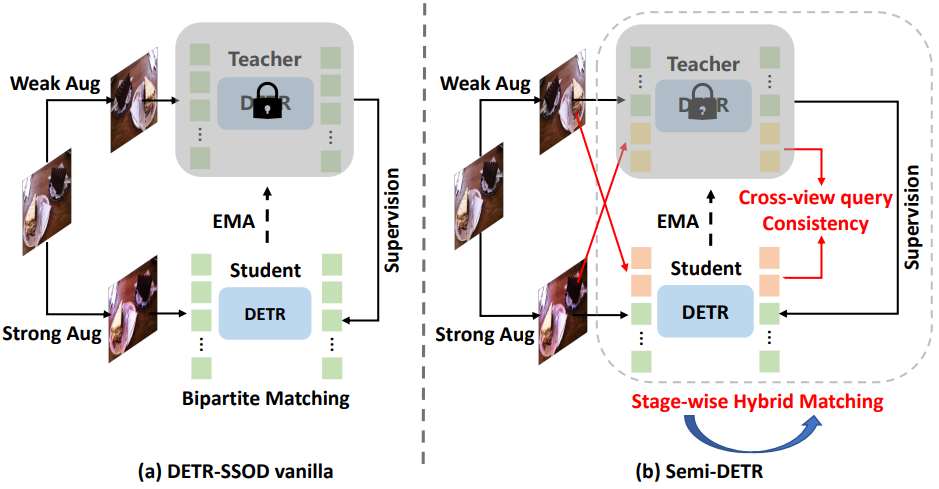
위 그림의 (a)에서 볼 수 있듯이 DETR-SSOD vanilla 프레임워크는 DETR 기반 detector를 활용하여 레이블이 지정되지 않은 이미지에 pseudo labeling을 수행한다. Teacher-Student 아키텍처에서 teacher 모델은 일반적으로 레이블이 지정되지 않은 이미지에 잡음이 있는 pseudo bounding box를 생성한다. Pseudo bounding box가 정확하지 않으면 일대일 할당 전략은 하나의 부정확한 proposal을 positive로 일치시키고 다른 모든 잠재적인 올바른 proposal은 negative로 남겨 학습 비효율성을 초래하게 된다. 이에 비해 전통적인 object detector에서 채택한 일대다 할당 전략은 일련의 positive proposal을 유지하므로 올바른 positive proposal을 포함할 가능성이 더 높다.
한편, 일대일 할당 전략은 NMS가 없는 end-to-end detection의 장점을 누리지만 self-supervised 시나리오에서는 학습 비효율성이 있다. 반면에 일대다 할당 전략은 더 나은 품질의 후보 proposal 집합을 획득하여 detector를 더 효율적으로 최적화하지만 필연적으로 중복 예측이 발생한다. 이 두 가지 장점을 수용하는 DETR 기반 SSOD 프레임워크를 설계하면 성능을 한 단계 더 높일 수 있다.
또한 현재 SSOD 방법에서 일반적으로 사용되는 일관성 기반 정규화는 DETR 기반 SSOD에서는 실행 불가능하다. 특히, 현재 SSOD 방법은 일관성 기반 정규화를 활용하여 쌍별 입력의 출력에 일관성 제약 조건을 부과함으로써 object detector가 잠재적인 feature 불변성을 학습할 수 있도록 돕는다. 전통적인 object detector에서는 입력 feature가 결정적이므로 입력과 출력 사이에 일대일 대응이 있어 일관성 제약 조건을 구현하기 편리하다. 그러나 DETR 기반 detector에서는 그렇지 않다. DETR 기반 detector는 무작위로 초기화된 학습 가능한 object query를 입력으로 사용하고 attention 메커니즘을 통해 query feature를 지속적으로 업데이트한다. Query feature가 업데이트됨에 따라 해당 예측 결과가 지속적으로 변경된다. 즉, 입력 object query와 해당 출력 예측 결과 사이에 결정론적 대응이 없으므로 DETR 기반 detector에 일관성 정규화가 적용되지 않는다.
이 위의 분석에 따라 본 논문은 Teacher-Student 아키텍처를 기반으로 하는 새로운 DETR 기반 SSOD 프레임워크를 제안한다. 이를 위 그림의 (b)에 제시된 Semi-DETR이라고 한다. 구체적으로 일대다 할당과 일대일 할당을 사용하여 각각 두 단계의 학습을 적용하는 Stage-wise Hybrid Matching 모듈을 제안한다. 첫 번째 단계에서는 일대다 할당 전략을 통해 학습 효율성을 향상시키고 이를 통해 일대일 할당 학습의 두 번째 단계에 고품질 pseudo label을 제공하는 것을 목표로 한다.
또한, cross-view object query를 구성하여 object query의 결정론적 대응을 찾는 요구 사항을 제거하고 detector가 두 개의 증강된 view 사이에서 object query의 의미론적 불변 특성을 학습하는 데 도움을 주는 Cross-view Query Consistency 모듈을 도입한다. 또한 매칭 비용 분포에 따라 일관성 학습을 위해 신뢰할 수 있는 pseudo box를 동적으로 마이닝하는 Gaussian Mixture Model (GMM)을 기반으로 하는 Cost-based Pseudo Label Mining 모듈을 고안하였다. Semi-DETR은 DETR 기반 프레임워크에 맞춰져 이전 최고의 SSOD 방법과 비교하여 새로운 SOTA 성능을 달성하였다.
Semi-DETR
1. Preliminary
레이블이 지정된 이미지 세트 \(D_s = \{x_i^s, y_i^s\}_{i=1}^{N_s}\)와 레이블이 지정되지 않은 이미지 세트 \(D_u = \{x_i^u\}_{i=1}^{N_u}\)를 학습 중에 사용할 수 있는 self-supervised DETR 기반 object detection 문제를 해결하는 것을 목표로 한다. $N_s$와 $N_u$는 레이블이 지정된 이미지와 레이블이 지정되지 않은 이미지의 양을 나타낸다. 레이블이 지정된 이미지 $x^s$의 경우 주석 $y^s$에는 모든 bounding box의 좌표와 객체 카테고리가 포함된다.
2. Overview
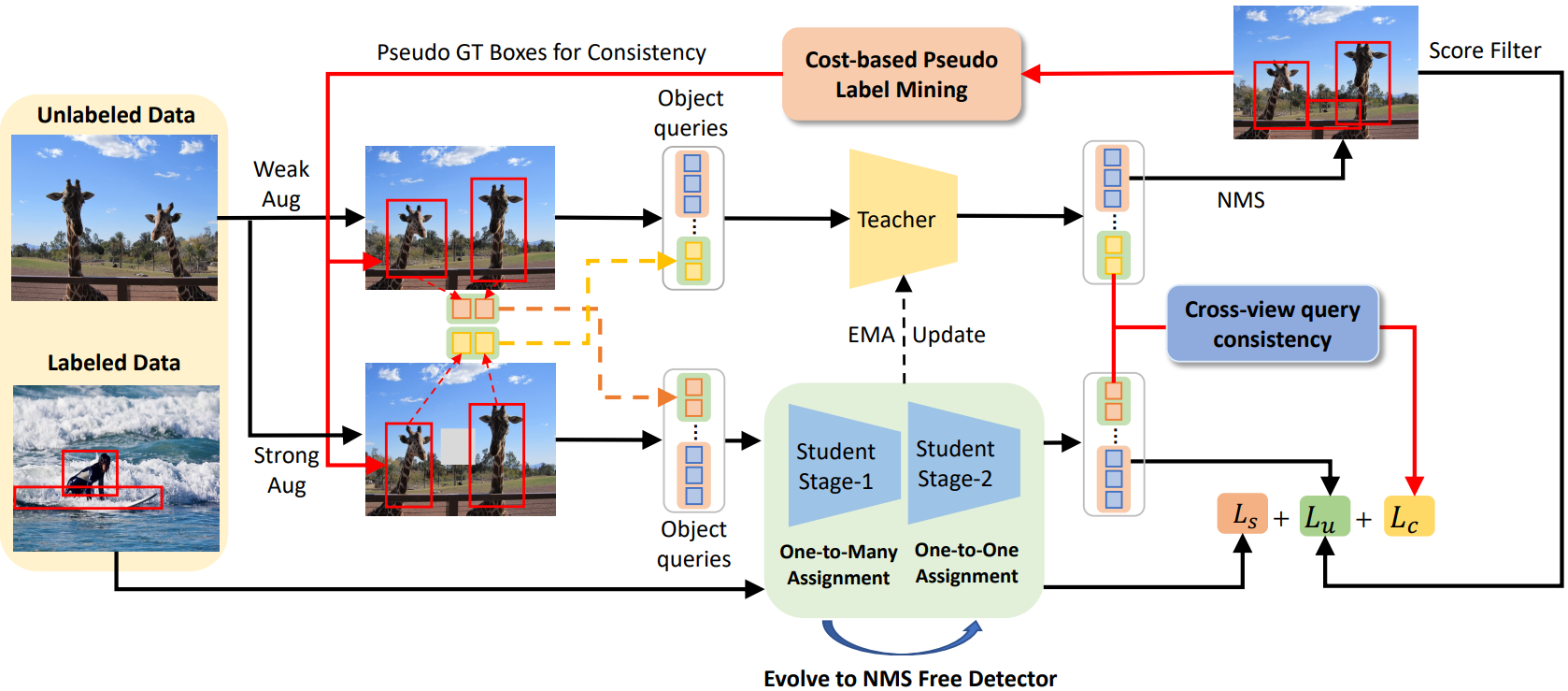
Semi-DETR의 전체 프레임워크는 위 그림에 설명되어 있다. SSOD에 대한 인기 있는 Teacher-Student 패러다임에 따라 제안된 Semi-DETR은 정확히 동일한 네트워크 아키텍처를 가진 한 쌍의 teacher 모델과 student 모델을 채택한다. 본 논문에서는 DINO를 예로 들며, Semi-DETR의 전체 프레임워크가 다른 DETR 기반 detector와 호환된다. 구체적으로, 각 학습 iteration에서 약하게 증강된 이미지와 레이블이 없는 강하게 증강된 이미지가 각각 teacher와 student에게 제공된다. 그런 다음 $\tau_s$보다 큰 신뢰도 점수를 가진 teacher 모델이 생성한 pseudo-label은 teacher 모델 학습을 위한 supervision 역할을 했다. Student 모델의 파라미터는 역전파에 의해 업데이트되는 반면, teacher 모델의 파라미터는 student 모델의 exponential moving average (EMA)이다.
Semi-DETR에는 DETR 기반 SSOD의 핵심 문제를 해결하는 stage-wise hybrid matching, cross-view query consistency, cost-based pseudo-label mining이라는 세 가지 새로운 구성 요소가 포함되어 있다.
3. Stage-wise Hybrid Matching
DETR 기반 프레임워크는 end-to-end object detection을 위해 일대일 할당에 의존한다. DETR 기반 SSOD 프레임워크의 경우 student 모델의 예측과 teacher 모델이 생성한 pseudo-label 사이에 Hungarian algorithm을 수행하여 최적의 일대일 할당 \(\hat{\sigma}_{o2o}\)를 얻을 수 있다.
\[\begin{equation} \hat{\sigma}_{o2o} = \underset{\sigma \in \xi_N}{\arg \min} \sum_{i=1}^N \mathcal{C}_\textrm{match} (\hat{y}_i^t, \hat{y}_{\sigma (i)}^s) \end{equation}\]여기서 $\xi_N$은 $N$개의 요소들의 순열 집합이고, \(\mathcal{C}_\textrm{match} (\hat{y}_i^t, \hat{y}_{\sigma (i)}^s)\)는 pseudo-label \(\hat{y}^t\)와 인덱스 $\sigma(i)$를 사용한 student 모델의 예측 사이의 매칭 비용이다.
그러나 SSOD 학습 초기 단계에서 teacher 모델이 생성한 pseudo-label은 일반적으로 부정확하고 신뢰할 수 없으므로 일대일 할당 전략에 따라 희박하고 품질이 낮은 proposal이 생성될 위험이 높다. 본 논문은 효율적인 self-supervised learning을 실현하기 위해 여러 positive query들을 활용하기 위해 일대일 할당을 일대다 할당으로 대체할 것을 제안한다.
\[\begin{equation} \hat{\sigma}_{o2m} = \bigg\{ \underset{\sigma_i \in C_N^M}{\arg \min} \sum_{j=1}^M \mathcal{C}_\textrm{match} (\hat{y}_i^t, \hat{y}_{\sigma_i (j)}^s) \bigg\}_{i=1}^{\vert \hat{y}^t \vert} \end{equation}\]여기서 $C_N^M$은 $M$과 $N$의 조합이며, 이는 $M$개의 proposal의 부분 집합이 각 pseudo box \(\hat{y}_i^t\)에 할당됨을 나타낸다. TOOD와 OTA를 따라, 분류 점수 $s$와 IoU 값 $u$의 고차 조합을 매칭 비용 측정 기준으로 활용한다.
\[\begin{equation} m = s^\alpha \cdot u^\beta \end{equation}\]여기서 $\alpha$와 $\beta$는 할당 중 분류 점수와 IoU의 영향을 제어하고 default로 $\alpha = 1$, $\beta = 6$으로 설정한다. 일대다 할당을 사용하면 $m$ 값이 가장 큰 $M$개의 proposal이 positive 샘플로 선택되고 나머지 proposal은 negative 샘플로 간주된다.
Self-supervised learning의 초기 단계에서 $T1$ 반복에 대한 일대다 할당으로 모델을 학습한다. TOOD와 Generalized Focal Loss를 따라 classification loss와 regression loss도 이 단계에서 수정된다.
\[\begin{equation} \mathcal{L}_\textrm{cls}^\textrm{o2m} = \sum_{i=1}^{N_\textrm{pos}} \vert \hat{m}_i - s_i \vert^\gamma \textrm{BCE} (s_i, \hat{m}_i) + \sum_{j=1}^{N_\textrm{neg}} s_j^\gamma \textrm{BCE} (s_j, 0) \\ \mathcal{L}_\textrm{reg}^\textrm{o2m} = \sum_{i=1}^{N_\textrm{pos}} \hat{m}_i \mathcal{L}_\textrm{GIoU} (b_i, \hat{b}_i) + \sum_{j=1}^{N_\textrm{neg}} \hat{m}_i \mathcal{L}_{L_1} (b_i, \hat{b}_i) \\ \mathcal{L}^\textrm{o2m} = \mathcal{L}_\textrm{cls}^\textrm{o2m} + \mathcal{L}_\textrm{reg}^\textrm{o2m} \end{equation}\]여기서 $\gamma$는 default로 2로 설정된다. 각 pseudo-label에 대해 여러 할당된 positive proposal을 사용하면 잠재적으로 고품질의 positive proposal도 최적화될 수 있는 기회를 얻게 되며, 이는 수렴 속도를 크게 향상시키고 결과적으로 더 나은 품질의 pseudo-label을 얻는다. 그러나 각 pseudo-label에 대한 여러 개의 positive proposal로 인해 중복된 예측이 발생한다. 이 문제를 완화하기 위해 두 번째 단계에서 일대일 할당 학습으로 다시 전환한다. 이를 통해 첫 번째 단계 학습 후에 고품질 pseudo label을 사용하고, 두 번째 단계에서 일대일 할당 학습을 통해 NMS 없는 detector를 위해 중복 예측을 점차적으로 줄인다. 이 단계의 loss function은 DINO와 같다.
\[\begin{equation} \mathcal{L}^\textrm{o2o} = \mathcal{L}_\textrm{cls}^\textrm{o2o} + \mathcal{L}_\textrm{reg}^\textrm{o2o} \end{equation}\]4. Cross-view Query Consistency
전통적으로 DETR 기반이 아닌 SSOD 프레임워크에서는 서로 다른 확률적 augmentation을 통해 동일한 입력 $x$가 주어지면 teacher $f_\theta$와 student $f_\theta^\prime$의 출력 간의 차이를 최소화하여 일관성 정규화를 편리하게 사용할 수 있다.
\[\begin{equation} \mathcal{L}_c = \sum_{x \in \mathcal{D}_u} \textrm{MSE} (f_\theta (x), f_\theta^\prime (x)) \end{equation}\]그러나 DETR 기반 프레임워크의 경우 입력 object query와 출력 예측 결과 간에 명확한 (또는 결정론적) 대응이 없기 때문에 일관성 정규화를 수행하는 것이 불가능해진다. 이 문제를 극복하기 위해 본 논문은 DETR 기반 프레임워크가 서로 다른 증강 view 간의 object query의 의미론적 불변 특성을 학습할 수 있도록 하는 Cross-view Query Consistency 모듈을 제안한다.
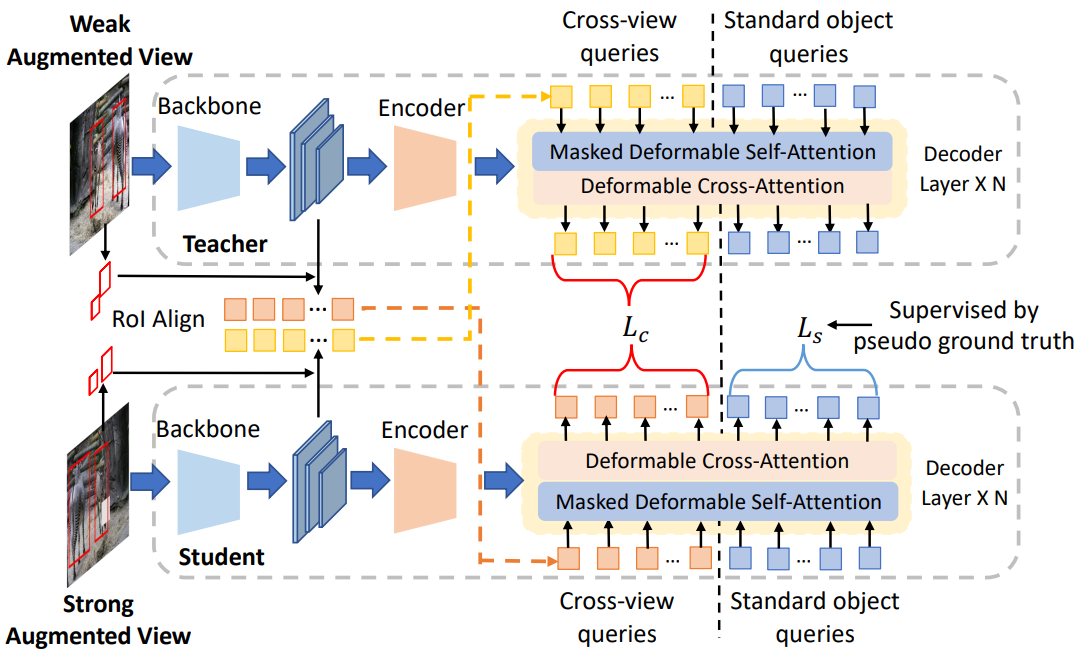
위 그림은 제안된 cross-view query consistency 모듈을 보여준다. 레이블이 지정되지 않은 각 이미지에 대해 pseudo bounding box 집합 $b$가 주어지면 RoIAlign을 통해 추출된 RoI feature를 여러 MLP로 처리한다.
여기서 $F_t$와 $F_s$는 각각 student 모델과 teacher 모델의 backbone feature를 나타낸다. 그 후, $c_t$와 $c_s$는 cross-view query 임베딩으로 간주되고 다른 view의 원래 object query에 첨부되어 디코더의 입력 역할을 한다.
\[\begin{equation} \hat{o}_t, o_t = \textrm{Decoder}_t ([c_s, q_t], E_t \; \vert \; A) \\ \hat{o}_s, o_s = \textrm{Decoder}_s ([c_t, q_s], E_s \; \vert \; A) \end{equation}\]여기서 $q$와 $E$는 각각 원본 object query와 인코딩된 이미지 feature이다. $\hat{o}$와 $o$는 cross-view query와 원본 object query의 디코딩된 feature이다. 아래첨자 $t$와 $s$는 각각 teacher와 student를 나타낸다. DN-DETR을 따라 정보 유출을 방지하기 위해 attention 마스크 $A$도 사용된다.
입력 cross-view query 임베딩의 semantic 가이드를 통해 디코딩된 feature의 일치성을 자연스럽게 보장할 수 있으며 다음과 같이 consistency loss를 부과한다.
\[\begin{equation} \mathcal{L}_c = \textrm{MSE} (\hat{o}_s, \textrm{detach}(\hat{o}_t)) \end{equation}\]5. Cost-based Pseudo Label Mining
본 논문은 cross-view query consistency 학습에 필요한 유의미한 semantic 콘텐츠가 포함된 더 많은 pseudo box를 마이닝하기 위해 레이블이 지정되지 않은 데이터에서 신뢰할 수 있는 pseudo box를 동적으로 마이닝하는 cost-based pseudo label mining 모듈을 제안한다. 구체적으로, 초기 필터링된 pseudo box와 예측된 proposal 사이에 추가적인 이분 매칭을 수행하고 pseudo box의 신뢰성을 설명하기 위해 매칭 비용을 활용한다.
\[\begin{equation} C_{ij} = \lambda_1 C_\textrm{Cls} (p_i, \hat{p}_j) + \lambda_2 C_\textrm{GIoU} (b_i, \hat{b}_j) + \lambda_3 C_{L_1} (b_i, \hat{b}_j) \end{equation}\]여기서 $p_i$, $b_i$는 $i$번째 예측 proposal의 classification 결과와 regression 결과를 나타내고, \(\hat{p}_j\)와 \(\hat{b}_j\)는 $j$번째 pseudo-label의 클래스 레이블과 box 좌표를 나타낸다.
그 후, 각 학습 배치에서 매칭 비용 분포를 위해 Gaussian Mixture Model을 피팅하여 초기 pseudo box를 두 가지 상태로 클러스터링한다.
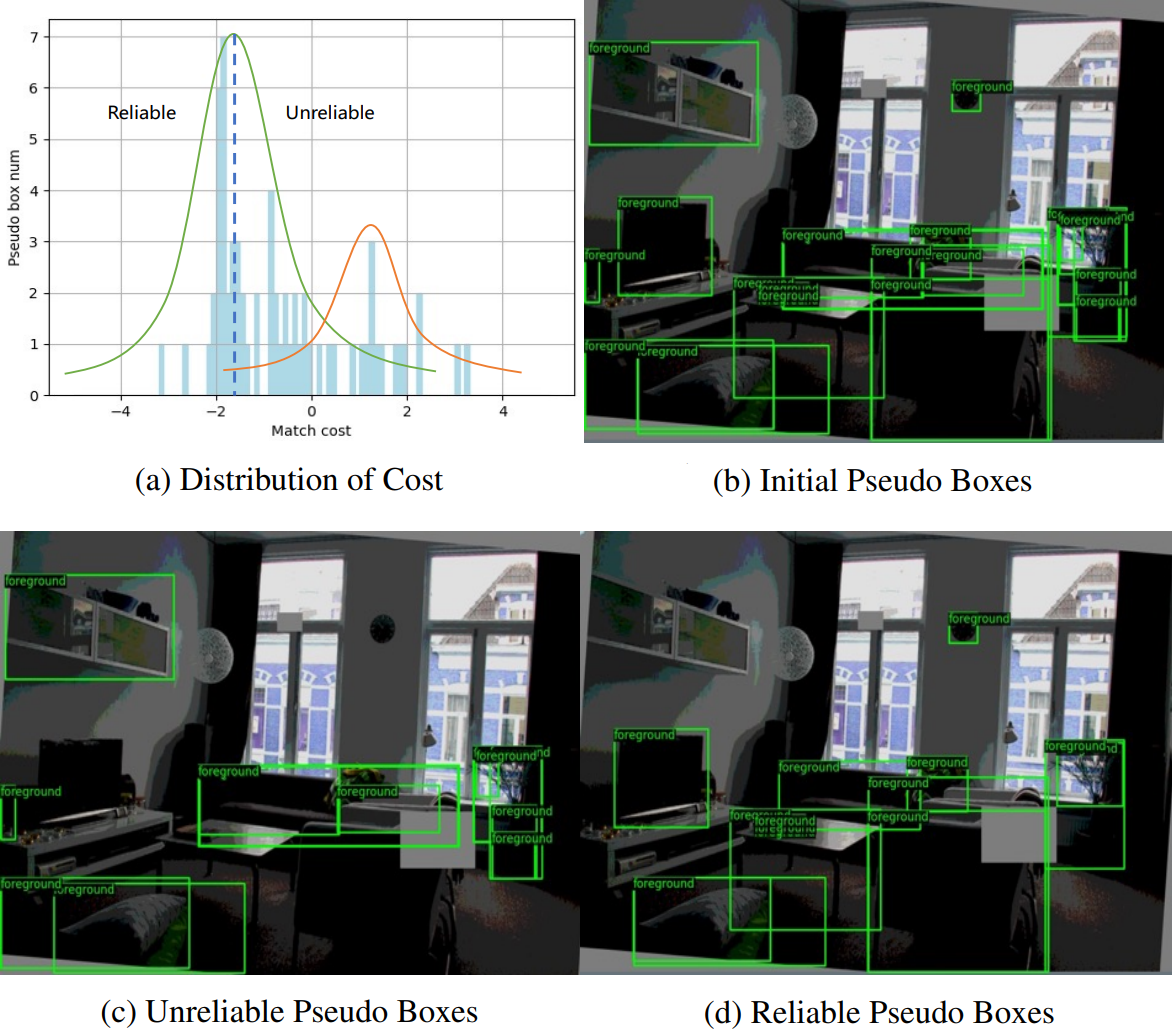
위 그림에서 볼 수 있듯이 매칭 비용은 pseudo box의 품질과 잘 일치한다. 또한 cross-view query consistency 계산을 위해 신뢰할 수 있는 클러스터링 센터의 비용 값을 임계값으로 설정하고 임계값보다 비용이 낮은 모든 pseudo box를 수집한다.
6. Loss Function
최종 loss $\mathcal{L}$은 다음과 같이 표현된다.
\[\begin{equation} \mathcal{L} = \mathbb{I} (t \le T_1) \cdot (\mathcal{L}_\textrm{sup}^\textrm{o2m} + w_u \cdot \mathcal{L}_\textrm{unsup}^\textrm{o2m}) + \mathbb{I} (t > T_1) \cdot (\mathcal{L}_\textrm{sup}^\textrm{o2o} + w_u \cdot \mathcal{L}_\textrm{unsup}^\textrm{o2o}) + w_c \cdot \mathcal{L}_c \end{equation}\]여기서 \(\mathcal{L}_\textrm{sup}\)과 \(\mathcal{L}_\textrm{unsup}\)은 각각 classification loss와 regression loss를 모두 포함하는 supervised loss와 unsupervised loss이다. \(\mathcal{L}_c\)는 cross-view consistency loss를 의미한다. $w_u$와 $w_c$는 unsupervised loss 가중치와 consistency loss 가중치로 default로 $w_u = 4$, $w_c = 1$로 설정된다. $t$는 현재 학습 iteration이고 $T_1$은 SHM 모듈 내 첫 번째 단계 학습의 iteration이다.
Experiments
- 데이터셋: MS-COCO (COCO-Partial, COCO-Full), Pascal VOC
- 구현 디테일
- Deformable DETR과 DINO를 Semi-DETR 방법에 통합
- backbone: ImageNet에서 사전 학습된 ResNet을
- classification loss: Focal Loss
- regression loss: Smooth L1 Loss, GIoU loss
- object query 수: Deformable DETR은 300, DINO는 900
- 학습 디테일
- COCO-Partial
- iteration 수: 12만 ($T_1$ = 6만)
- batch size: 40 (8개의 GPU, GPU당 5개의 이미지)
- 레이블이 있는 데이터와 없는 데이터의 비율 = 1:4
- unsupervised loss 가중치: $\alpha = 4.0$
- COCO-Full
- iteration 수: 24만 ($T_1$ = 18만)
- batch size: 64 (8개의 GPU, GPU당 8개의 이미지)
- 레이블이 있는 데이터와 없는 데이터의 비율 = 1:1
- unsupervised loss 가중치: $\alpha = 2.0$
- Pascal VOC
- iteration 수: 6만 ($T_1$ = 4만)
- 나머지는 COCO-Partial과 동일
- 신뢰도 threshold: 0.4
- optimizer: Adam
- learning rate: 0.001 (decay 없음)
- EMA momentum: 0.999
- COCO-Partial
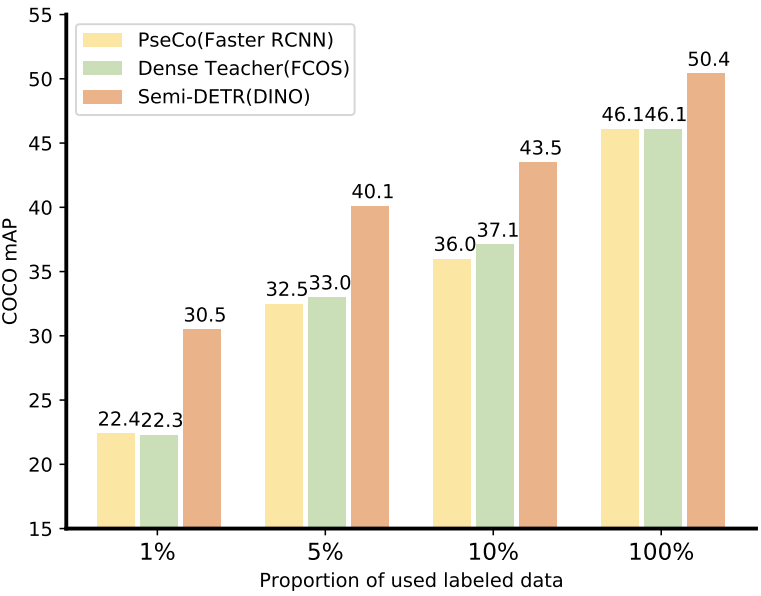
1. Comparison with SOTA methods
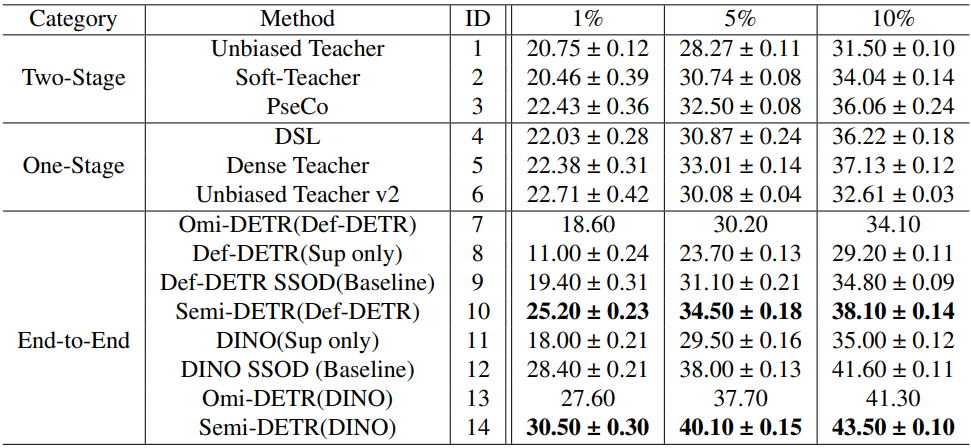
COCO-Partial benchmark
다음은 COCO-Partial에서 SOTA SSOD 방법들과 비교한 표이다.
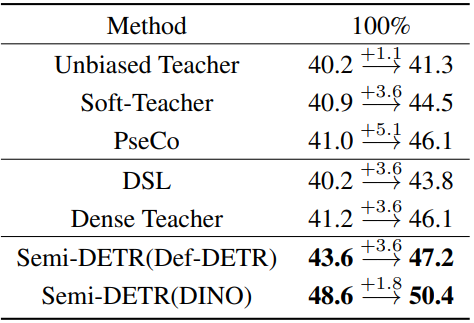
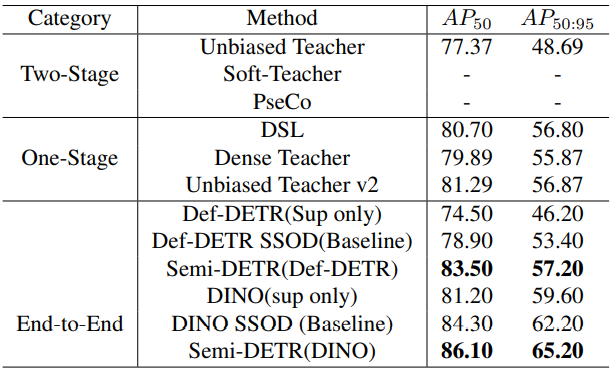
COCO-Full benchmark
다음은 COCO-Full에서 SOTA SSOD 방법들과 비교한 표이다.
Pascal VOC benchmark
다음은 Pascal VOC에서 SOTA SSOD 방법들과 비교한 표이다.
2. Ablation Study
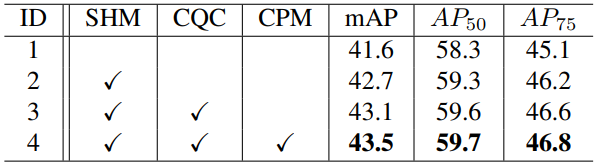
Component Effectiveness
다음은 Semi-DETR의 각 구성 요소에 대한 효과를 비교한 표이다. SHM은 Stage-wise Hybrid Matching, CQC는 Cross-view Query Consistency, CPM은 Cost-based Pseudo Label Mining을 의미한다.
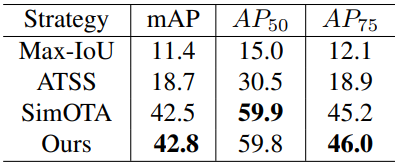
Variants of SHM
다음은 첫 번쨰 단계에서의 다양한 일대다 할당 방법들의 효과를 비교한 표이다.
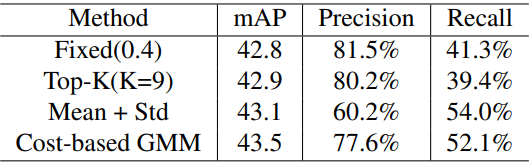
Effectiveness of CQC+CPM
다음은 cross-view consistency 학습을 위해 pseudo-label을 필터링하는 다양한 방법의 효과를 비교한 표이다.
Hyperparameters
다음은 pseudo-label threshold $\tau_s$에 따른 성능을 비교한 표이다.

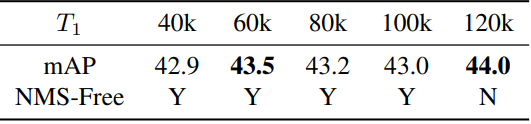
다음은 첫 번째 단계의 학습 iteration $T_1$에 따른 성능을 비교한 표이다.