[논문리뷰] Self-Rewarding Language Models
ICML 2024. [Paper]
Weizhe Yuan, Richard Yuanzhe Pang, Kyunghyun Cho, Xian Li, Sainbayar Sukhbaatar, Jing Xu, Jason Weston
Meta | NYU
18 Jan 2024
Introduction
인간 선호도 데이터를 사용하여 LLM을 정렬하면 사전 학습된 모델의 명령 수행 성능을 크게 개선할 수 있다. Reinforcement Learning from Human Feedback (RLHF)은 이러한 인간의 선호도에서 reward model을 학습한다. 그런 다음 reward model을 고정한 후 PPO와 같은 RL을 사용하여 LLM을 학습시킨다. 최근 Direct Preference Optimization (DPO)는 reward model을 전혀 학습하지 않고 인간의 선호도를 직접 사용하여 LLM을 학습하였다. 두 경우 모두 인간 선호도 데이터의 크기와 품질에 큰 영향을 받으며, RLHF의 경우 해당 데이터에서 학습된 고정된 reward model의 품질에도 영향을 미친다.
본 논문에서는 LLM 정렬 중에 고정되는 대신 지속적으로 업데이트되는 자체 개선 reward model을 학습시켜 이 문제를 피할 것을 제안하였다. 이러한 접근 방식의 핵심은 reward model과 언어 모델을 별도의 모델로 분리하는 대신 모든 능력을 보유한 에이전트를 개발하는 것이다.
본 논문은 Self-Rewarding Language Model을 제안하였다. 이 모델은 두 가지 기능을 가지고 있다.
- 주어진 프롬프트에 대한 응답을 생성하는 지시를 따르는 모델로 작용한다.
- 자체 훈련 세트에 추가할 새로운 지시를 따르는 예를 생성하고 평가한다.
시드 모델에서 시작하여 각 iteration에서 모델이 새로 만든 프롬프트에 대한 후보 응답을 생성하고 동일한 모델이 reward를 할당하는 self-instruction creation 프로세스가 있다. Reward 할당은 LLM-as-a-Judge 프롬프팅를 통해 구현되며, 이는 instruction following task로 볼 수도 있다. 선호도 데이터셋은 생성된 데이터에서 구축되고 모델의 다음 iteration은 DPO를 통해 학습된다.
시드 모델과 비교하여 Self-Rewarding LLM 정렬에서 instruction following 성능이 향상될 뿐만 아니라 reward 모델링 능력도 향상되었다. 즉, 반복적인 학습 중 모델은 주어진 iteration에서 이전 iteration보다 더 높은 품질의 선호도 데이터셋을 스스로에게 제공할 수 있다. 이 효과는 원래 인간이 작성한 시드 데이터만으로 학습할 수 있었던 reward model보다 우수한 reward model을 얻을 수 있는 흥미로운 가능성을 제공한다.
Self-Rewarding Language Models
본 논문은 사전 학습된 언어 모델과 소량의 인간이 주석을 단 시드 데이터에 대한 액세스를 가정한다. 그런 다음 두 가지 능력을 동시에 보유하는 것을 목표로 하는 모델을 구축한다.
- Instruction following: 사용자 요청을 설명하는 프롬프트가 주어지면, 고품질이고 도움이 되고 무해한 응답을 생성할 수 있는 능력
- Self-instruction creation: 새로운 instruction following 예제를 생성하고 평가하여 자체 학습 세트에 추가할 수 있는 능력
이러한 능력은 모델이 self-alignment를 수행할 수 있도록 사용된다. 즉, AI Feedback (AIF)을 사용하여 반복적으로 스스로 학습하는 데 사용된다.
Self-instruction creation은 후보 응답을 생성한 다음 모델 스스로가 그 품질을 판단하는 것으로 구성된다. 즉, 외부 모델에 대한 필요성을 대체하는 self-rewarding model 역할을 한다. 이는 LLM-as-a-Judge 메커니즘을 통해 구현된다. 즉, 응답 평가를 instruction following task로 공식화한다. 이 스스로 생성한 AIF 선호도 데이터는 학습 세트로 사용된다.
전반적인 self-alignment 절차는 반복적인 것으로, 일련의 이러한 모델을 구축하여 각각이 이전보다 개선되도록 하는 것을 목표로 한다. 중요한 점은 모델이 생성 능력을 개선하고 동일한 생성 메커니즘을 통해 self-rewarding model로 작용할 수 있기 때문에 reward model 자체가 이러한 반복을 통해 개선될 수 있으며, reward model이 고정된 표준 관행에서 벗어날 수 있다는 것이다. 이를 통해 모델의 자기 개선에 대한 잠재력의 한계를 높일 수 있다.
1. Initialization
학습 중에 두 가지 시드 세트를 함께 사용한다.
Instruction following 시드 데이터
인간이 작성한 (명령 프롬프트, 응답) 형태의 일반적인 instruction following 예제로 구성된 시드 세트를 사용한다. 이 데이터를 사전 학습된 언어 모델을 supervised fine-tuning (SFT) 방식으로 학습시키는 데 사용하며, Instruction Fine-Tuning (IFT) 데이터라고 부른다.
LLM-as-a-Judge instruction following 시드 데이터
또한 (평가 명령 프롬프트, 평가 결과 응답) 형태의 예제로 구성된 시드 세트도 학습에 사용한다. IFT 데이터를 사용하는 모델은 이미 LLM-as-a-Judge를 학습할 수 있으므로 이 데이터는 꼭 필요한 것은 아니지만 이러한 학습 데이터가 향상된 성능을 제공할 수 있다.
이 데이터에서 입력 프롬프트는 모델에 특정 명령에 대한 주어진 응답의 품질을 평가하도록 요청한다. 제공된 평가 결과 응답은 chain-of-thought reasoning으로 구성되며, 그 뒤에 최종 점수 (5점 만점)가 이어진다. 저자들이 선택한 정확한 프롬프트 형식은 아래 그림에 나와 있으며, LLM에 품질의 다양한 측면을 포괄하는 5가지 기준 (관련성, 적용 범위, 유용성, 명확성, 전문성)을 사용하여 응답을 평가하도록 지시한다. 이 데이터를 Evaluation Fine-Tuning (EFT) 데이터라고 부른다.

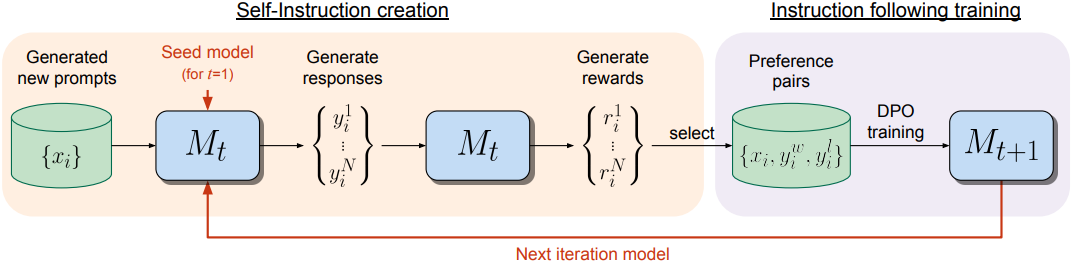
2. Self-Instruction Creation
학습시킨 모델을 사용하여, 모델이 자체 학습 세트를 스스로 수정하도록 만들 수 있다. 구체적으로, 다음 학습 iteration을 위해 추가 학습 데이터를 생성하며, 다음과 같은 단계로 구성된다.
- 새로운 프롬프트 생성: Self-Instruct와 Unnatural Instructions을 따라, few-shot 프롬프팅을 사용하여 원래 시드 IFT 데이터에서 프롬프트를 샘플링하고 새로운 프롬프트 $x_i$를 생성한다.
- 후보 응답 생성: 샘플링을 사용하여 모델에서 주어진 프롬프트 $x_i$에 대해 $N$개의 다양한 후보 응답 \(\{y_i^1, \ldots, y_i^N\}\)을 생성한다.
- 후보 응답 평가: 동일한 모델의 LLM-as-a-Judge 능력을 사용하여 점수 $r_i^n \in [0, 5]$로 후보 응답을 평가한다.
3. Instruction Following Training
앞서 설명한 대로, 학습은 처음에 IFT 및 EFT 시드 데이터로 수행된다. 그런 다음 AIF를 통해 추가 데이터로 보강된다.
AI Feedback Training
Self-instruction creation을 수행한 후, 추가적인 학습 예제로 시드 데이터를 보강할 수 있다. 이를 AI Feedback Training (AIFT) 데이터라고 한다.
이를 위해 선호도 쌍을 구성하며, (명령 프롬프트 $x_i$, 승리 응답 $y_i^w$, 패배 응답 $y_i^l$) 형태의 학습 데이터이다. 승리 및 패배 쌍을 구성하기 위해 $N$개의 평가된 후보 응답에서 가장 높은 점수와 가장 낮은 점수의 응답을 취하고 점수가 같으면 쌍을 버린다. 이러한 쌍은 DPO를 사용하여 학습에 사용할 수 있다.
4. Overall Self-Alignment Algorithm
반복적 학습
전반적인 절차는 일련의 모델 $M_1, \ldots, M_T$를 학습시키는데, 여기서 모델 $t$는 $t-1$번째 모델에 의해 생성된 증강된 학습 데이터를 사용한다. 따라서 모델 $M_t$를 사용하여 생성된 AIFT 데이터를 AIFT($M_t$)로 정의한다.
모델 시퀀스
모델과 각 모델이 사용하는 학습 데이터를 다음과 같이 정의한다.
- $M_0$: Fine-tuning하지 않은 사전 학습된 LLM
- $M_1$: $M_0$로 초기화한 후, SFT를 사용하여 IFT+EFT 시드 데이터로 fine-tuning한 LLM
- $M_2$: $M_1$로 초기화한 후, DPO를 사용하여 AIFT($M_1$) 데이터로 학습시킨 LLM
- $M_3$: $M_2$로 초기화한 후, DPO를 사용하여 AIFT($M_2$) 데이터로 학습시킨 LLM
이 반복적 학습은 Pairwise Cringe Optimization에서 사용된 Iterative DPO와 유사하지만, 해당 논문에서는 고정된 외부 reward model이 사용되었다.
Experiments
- Base model: Llama 2 70B
- IFT 시드 데이터: Open Assistant
1. Instruction Following Ability
다음은 instruction-following 성능을 비교한 그래프이다.

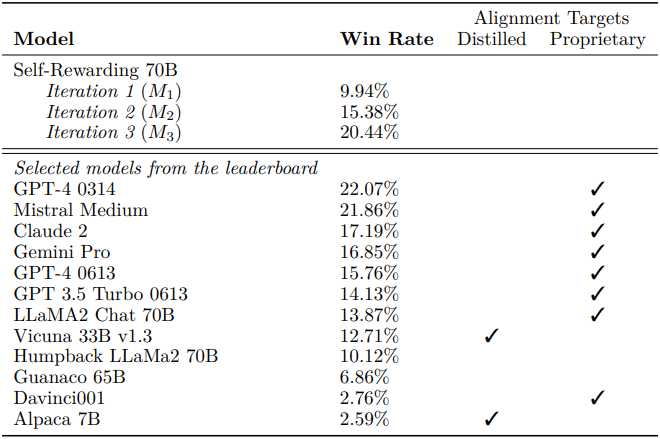
다음은 AlpacaEval 2.0 결과로, GPT-4 Turbo에 대한 승률을 비교한 표이다. (GPT-4가 평가)
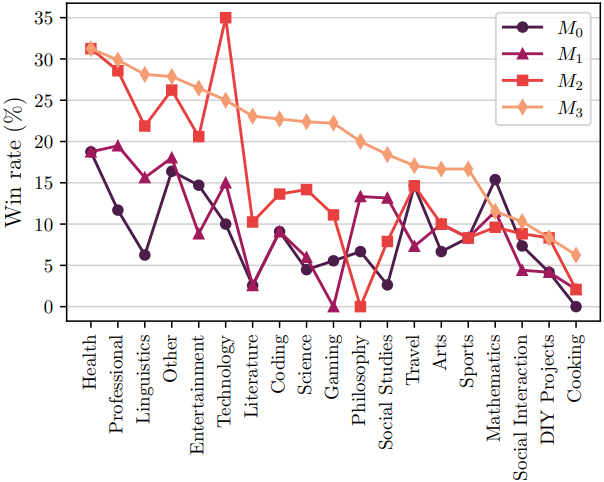
다음은 명령 카테고리에 따라 AlpacaEval 승률을 나타낸 그래프이다.
다음은 인간이 평가한 결과이다.
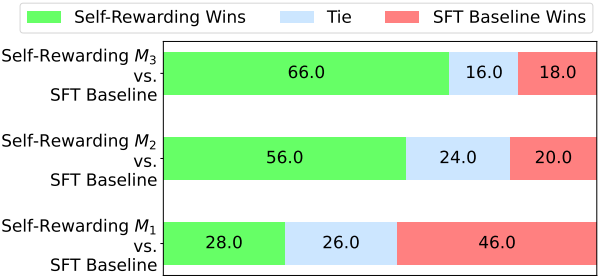
다음은 MT-Bench 결과이다. (10점 만점)
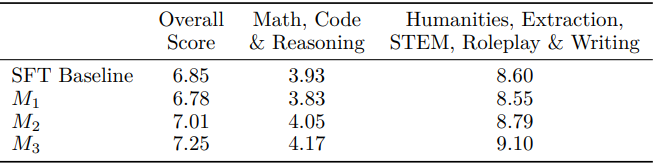
다음은 여러 NLP 벤치마크들에 대한 비교 결과이다.

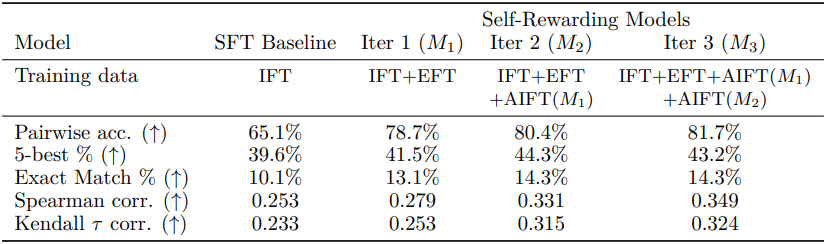
2. Reward Modeling Ability
다음은 다양한 metric으로 인간 선호도와의 정렬도를 평가한 표이다.