[논문리뷰] Self-Consistency Improves Chain of Thought Reasoning in Language Models
ICLR 2023. [Paper]
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, Denny Zhou
Google Research, Brain Team
18 Jan 2024
Introduction
언어 모델은 다양한 NLP task에서 놀라운 성공을 거두었지만, 추론을 입증하는 능력은 종종 한계로 여겨지며, 이는 모델의 크기를 늘리는 것만으로는 극복할 수 없다. 이러한 단점을 해결하기 위해 언어 모델이 사람의 추론 프로세스를 모방하는 일련의 짧은 문장을 생성하도록 유도하는 chain-of-thought (CoT) prompting이 제안되었다. CoT-prompting은 다양한 다단계 추론 task에서 모델 성능을 크게 향상시키는 것으로 관찰되었다.
본 논문에서는 CoT-prompting에서 사용되는 greedy decoding 전략을 대체하기 위해 self-consistency라는 새로운 디코딩 전략을 소개하는데, 이는 언어 모델의 추론 성능을 상당한 차이로 개선하였다. Self-consistency는 복잡한 추론 task가 일반적으로 정답에 도달하는 여러 추론 경로를 가진다는 직관을 활용하였다. 문제에 대해 의도적인 사고와 분석이 더 많이 필요할수록 답을 복구할 수 있는 추론 경로의 다양성이 커진다.
먼저 언어 모델을 CoT로 프롬프팅한 다음, 최적의 추론 경로를 greedy decoding하는 대신 sample-and-marginalize 디코딩을 사용한다.
- 언어 모델의 디코더에서 샘플링하여 다양한 추론 경로들을 생성한다.
- 각 추론 경로는 다른 최종 답으로 이어질 수 있으므로 샘플링된 추론 경로를 marginalizie out한다.
- 최종 답들에서 가장 일관된 답을 찾아 최적의 답으로 결정한다.
이러한 접근 방식은 여러 가지 다른 사고 방식이 같은 답으로 이어지면 최종 답이 옳다는 확신이 더 커지는 인간의 경험과 유사하다. Self-consistency는 greedy decoding을 괴롭히는 반복성과 로컬 최적성을 피하는 동시에 단일 샘플링의 확률성(stochasticity)을 완화한다.
Self-consistency는 완전히 unsupervised이고, 사전 학습된 언어 모델과 함께 즉시 사용할 수 있으며, 추가 인간 주석, 추가 학습, 보조 모델, fine-tuning이 필요없다. 또한 self-consistency는 여러 모델을 학습시키고 각 모델의 출력을 집계하는 일반적인 앙상블 접근 방식과 다르며 하나의 언어 모델 위에서 작동하는 “self-ensemble”처럼 작동한다.
저자들은 다양한 스케일 가진 4가지 언어 모델에 대한 광범위한 산술적 추론 및 상식적 추론 task에서 self-consistency를 평가하였다. Self-consistency는 4가지 언어 모델 모두에서 CoT-prompting보다 현저한 차이로 개선되었다. 특히 PaLM-540B 또는 GPT-3와 함께 사용할 때 GSM8K, SVAMP, AQuA, StrategyQA, ARCchallenge에서 새로운 SOTA를 달성하였다. 또한, self-consistency는 CoT를 추가하면 성능이 저하되는 NLP task에서도 성능을 높일 수 있음을 보여주었으며, 샘플링 전략 및 불완전한 프롬프트에 견고함을 보여주었다.
Self-Consistency over Diverse Reasoning Paths

인간의 두드러진 측면은 사람들이 각각 다르게 생각한다는 것이다. 의도적인 사고가 필요한 문제에서는 문제를 공격하는 여러 가지 방법이 있을 가능성이 있다고 가정하는 것은 당연하다. 본 논문은 언어 모델의 디코더에서 샘플링을 통해 언어 모델에서 이러한 프로세스를 시뮬레이션할 수 있다고 제안하였다.
예를 들어, 위 그림에서 볼 수 있듯이 모델은 모두 같은 정답에 도달하는 여러 가지 그럴듯한 응답을 생성할 수 있다 (출력 1과 3). 언어 모델은 완벽하지 않기 때문에 잘못된 추론 경로를 생성하거나 추론 단계 중 하나에서 실수를 할 수도 있지만, 이러한 경우 같은 답에 도달할 가능성이 적다. 즉, 저자들은 다양하더라도 올바른 추론 프로세스가 잘못된 프로세스보다 최종 답에 더 큰 동의를 갖는 경향이 있다고 가정하였다.
본 논문은 self-consistency를 제안함으로써 이 직관을 활용하였다. 먼저, 언어 모델은 수동으로 작성된 chain-of-thought (CoT) 예시들로 프롬프팅된다. 그 후, 언어 모델의 디코더에서 일련의 후보 출력을 샘플링하여 다양한 추론 경로 후보들을 생성한다. Self-consistency는 temperature sampling, top-k sampling, nucleus sampling 등 대부분의 기존 샘플링 알고리즘과 호환된다. 마지막으로, 샘플링된 추론 경로를 marginalize out하여 생성된 답변들 중 가장 일관성 있는 답변을 선택하여 답변을 집계한다.
구체적으로, 생성된 답변들 \(\{a_i\}_{i=1}^m\)가 고정된 답변 집합 $\mathbb{A}$에서 나온다고 가정하자. 프롬프트와 질문이 주어졌을 때, self-consistency는 추가적인 latent variable $r_i$를 도입하는데, 이는 $i$번째 출력에서 추론 경로를 나타내는 토큰들의 시퀀스이다. 그런 다음 $(r_i, a_i)$으로 결합하며, 여기서 추론 경로 $r_i$는 선택 사항이고 최종 답변 $a_i$에 도달하기 위해 사용된다.
예를 들어, 위 그림의 출력 3을 보면, "She eats 3 for breakfast ... So she has 9 eggs * $2 = $18"은 $r_i$가 되고, 마지막 문장에서의 답변 "The answer is $18"의 18이 $a_i$로 파싱된다. 이러한 파싱 절차는 task에 따라 다르며, 산술적 추론의 경우 "The answer is" 이후에 나오는 첫번째 수를 파싱하게 된다.
모델의 디코더에서 다수의 $(r_i, a_i)$를 샘플링한 후, self-consistency는 $r_i$를 marginalize out하고 $a_i$에 대해 다수결을 취하여 가장 일관된 답변을 최종 답변 집합에서 선택한다.
\[\begin{equation} \underset{a}{\arg \max} \sum_{i=1}^m \unicode{x1D7D9} (a_i = a) \end{equation}\]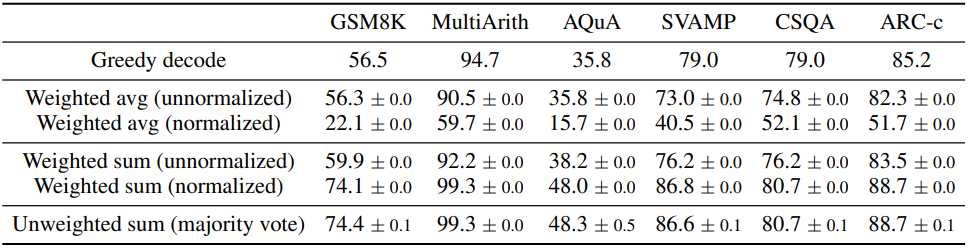
위 표는 다양한 답변 집계 전략을 사용하여 추론 task들에 대한 테스트 정확도를 비교한 것이다. 다수결 외에도, 각 $(r_i, a_i$)을 \(P (r_i, a_i \; \vert \; \textrm{prompt}, \textrm{question})\)으로 가중치를 부여해 답변을 집계할 수 있다. \(P (r_i, a_i \; \vert \; \textrm{prompt}, \textrm{question})\)를 계산할 때, 모델이 주어진 (프롬프트, 질문)에 대하여 $(r_i, a_i)$를 생성할 정규화되지 않은 확률을 취하거나, 다음과 같이 출력 길이에 따라 조건부 확률을 정규화할 수 있다.
표에서 ‘unweighted sum’, 즉 $a_i$에 대해 다수결을 직접 취하는 것이 ‘normalized weighted sum’을 사용한 것과 매우 유사한 정확도를 나타낸다. 저자들이 모델의 출력 확률을 자세히 분석한 결과, 각 $(r_i, a_i)$에 대한 정규화된 조건부 확률 \(P (r_i, a_i \; \vert \; \textrm{prompt}, \textrm{question})\)가 서로 매우 유사하다는 것을 발견했다. 이는 언어 모델이 올바른 답과 틀린 답을 잘 구분하지 못함을 의미한다.
추론 task는 일반적으로 고정된 답변을 가지기 때문에, 기존 연구들은 주로 greedy decoding 방식을 고려해왔다. 하지만 원하는 답변이 고정되어 있더라도, 추론 과정에서 다양성을 도입하는 것이 매우 유익할 수 있다. Self-consistency는 최종 답변이 고정된 답변 집합에서 나오는 문제에만 적용될 수 있지만, 원칙적으로는 여러 생성 결과 간의 일관성을 평가할 수 있는 좋은 기준이 정의될 경우 개방형 텍스트 생성 문제에도 확장될 수 있다.
Experiments
- 데이터셋
- 산술적 추론: Math Word Problem Repository (AddSub, MultiArith, ASDiv), AQUA-RAT, GSM8K, SVAMP
- 상식적 추론: CommonsenseQA, StrategyQA, AI2 Reasoning Challenge (ARC)
- 기호적 추론 (symbolic reasoning)
- last letter concatenation: 단어들의 끝 문자만 모아서 출력하는 task
- Coinflip: 동전의 초기 상태와 몇 번 뒤집어졌는지 정보를 준 뒤, 마지막 동전의 상태를 맞추는 task
- 샘플링 방식
- UL2-20B, LaMDA-137B
- temperature sampling: $T = 0.5$
- top-$k$ truncation: $k = 40$
- PaLM-540B
- temperature sampling: $T = 0.7$
- top-$k$ truncation: $k = 40$
- GPT-3
- temperature sampling: $T = 0.7$
- top-$k$ truncation: 사용 안 함
- UL2-20B, LaMDA-137B
1. Main results
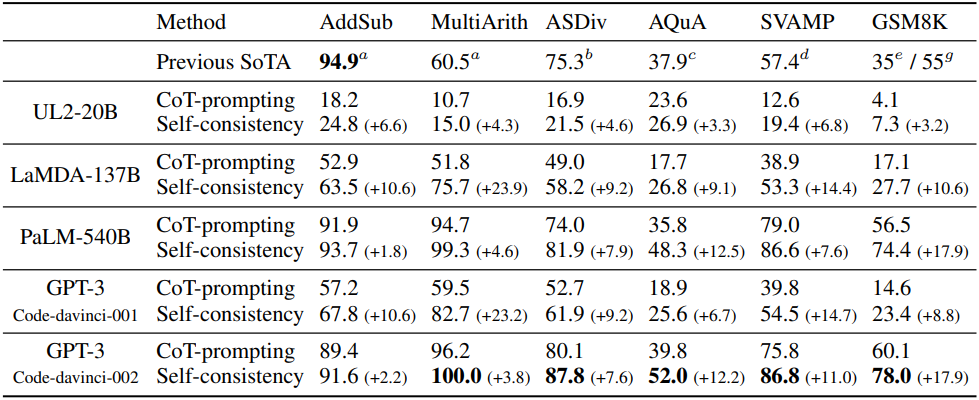
다음은 산술적 추론에 대하여 CoT-prompting과 self-consistency를 비교한 결과이다.
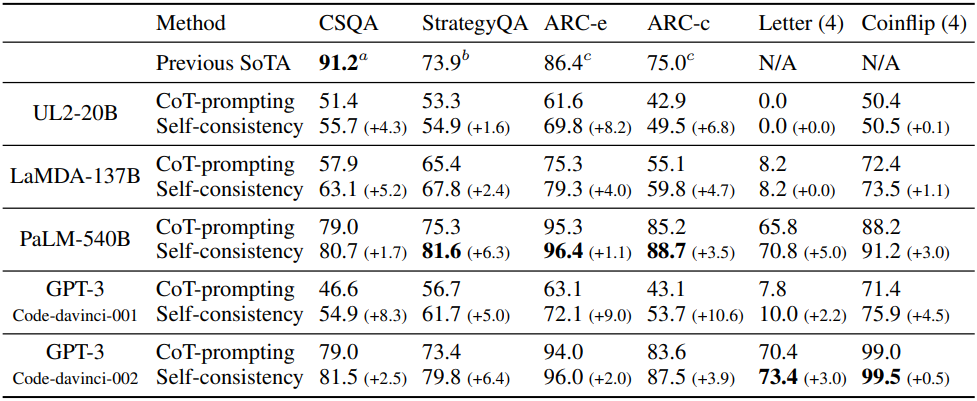
다음은 상식적 추론과 기호적 추론에 대하여 CoT-prompting과 self-consistency를 비교한 결과이다.
다음은 샘플링된 추론 경로 수에 따른 self-consistency의 정확도를 CoT-prompting과 비교한 그래프이다. (LaMDA-137B)

다음은 greedy decoding으로 인한 오류를 복구하는 데 self-consistency가 도움이 되는 예시이다.
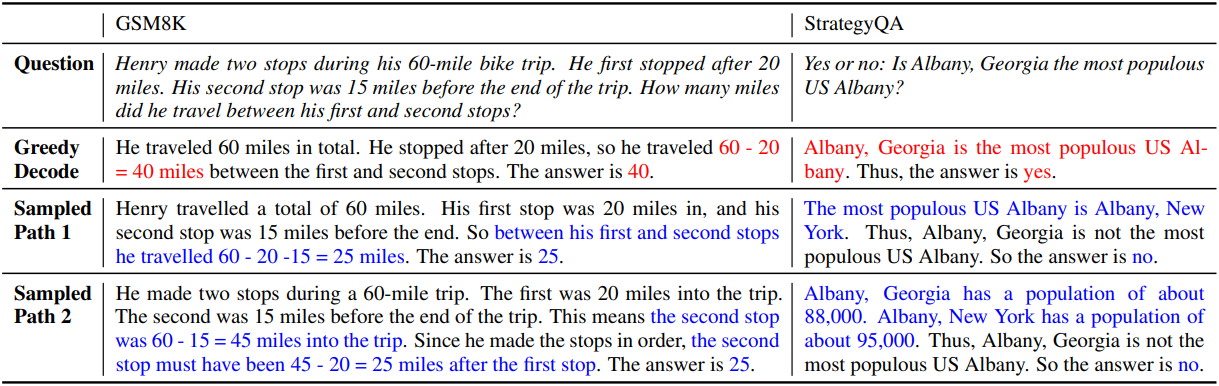
2. Self-consistency helps when chain-of-thought hurts performance
다음은 일반 NLP task에서 self-consistency를 일반 프롬프팅, CoT-prompting과 비교한 표이다.

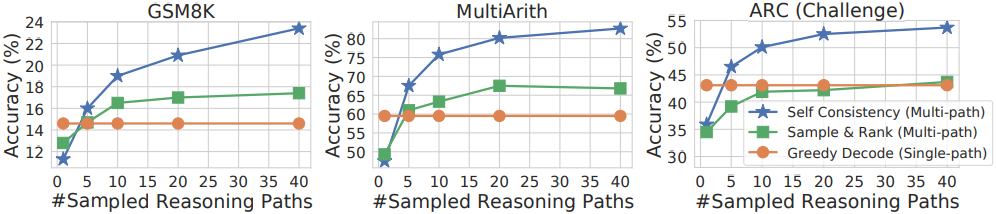
3. Compare to other existing approaches
생성 품질을 개선하기 위해 일반적으로 사용되는 접근 방식 중 하나는 sample-and-rank이다. Sample-and-rank는 여러 시퀀스가 디코더에서 샘플링된 다음 각 시퀀스의 로그 확률에 따라 순위가 매겨진다. 다음은 sample-and-rank와 self-consistency를 비교한 그래프이다. (GPT-3 code-davinci-001)
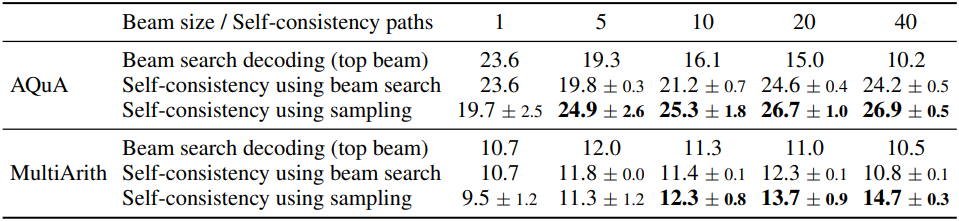
다음은 beam search decoding을 사용하는 self-consistency와 비교한 결과이다. (UL2-20B)
다음은 앙상블 기반 방법들과 비교한 결과이다. (LaMDA-137B)

4. Additional studies
다음은 (왼쪽) 샘플링 전략과 (오른쪽) 모델 크기에 따른 GSM8K 정확도를 비교한 그래프이다.

다음은 GSM8K에서 불완전한 프롬프트, 방정식 프롬프트, zero-shot CoT에 self-consistency를 적용한 결과이다.

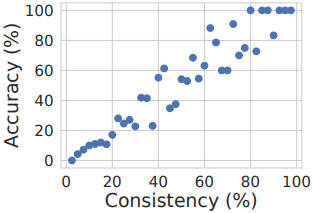
다음은 일관성 (최종 집계된 답변과 일치하는 답변의 비율)과 정확도 사이의 높은 상관관계를 보여주는 그래프이다.