[논문리뷰] Segment and Caption Anything
CVPR 2024. [Paper] [Page] [Github]
Xiaoke Huang, Jianfeng Wang, Yansong Tang, Zheng Zhang, Han Hu, Jiwen Lu, Lijuan Wang, Zicheng Liu
Tsinghua University | Microsoft
1 Dec 2023
Introduction
Segment Anything Model (SAM)은 마스크 데이터를 10억 개로 학습된 인터랙티브한 segmentation 시스템이다. 이러한 데이터 규모는 시각적 프롬프트에 따라 segmentation 시 더 강력한 일반화를 가능하게 한다. 그러나 데이터에는 semantic 레이블이 포함되어 있지 않으므로 모델은 semantic을 이해할 수 없다.
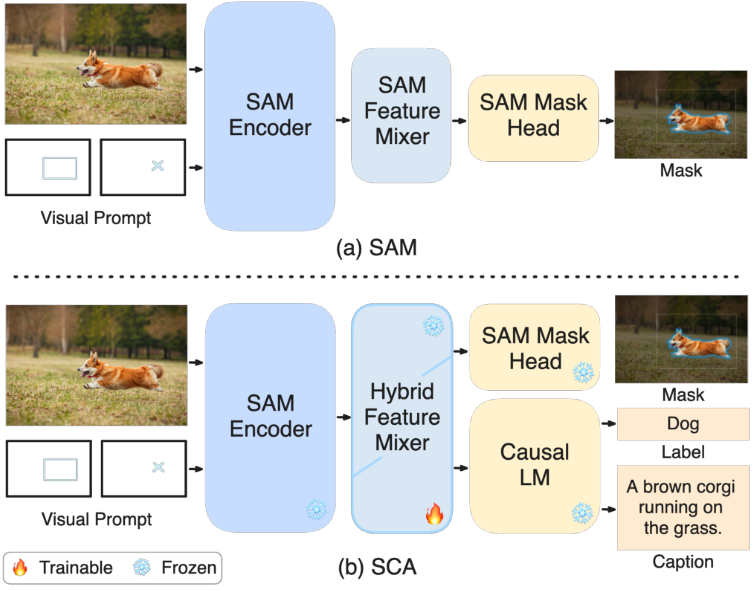
본 논문은 SAM에 영역 캡션 생성 능력을 효율적으로 장착할 수 있는 방법을 제안하였다. SAM feature mixture 위에 텍스트 feature mixture를 쌓는 가벼운 hybrid feature mixture를 도입하여 SAM과 인과적 언어 모델을 결합한다. Hybrid feature mixture는 self 및 cross-attention을 통해 다운스트림 캡션 예측을 위한 영역별 feature를 추출한다. 텍스트 feature mixer만 최적화하고 다른 네트워크 모듈, 즉 SAM 인코더, SAM feature mixer, 언어 모델은 그대로 둔다. 학습 중에 영역별 feature는 나중에 캡션 생성을 위해 언어 모델의 embedding space에 맞춰 조정된다. 학습 가능한 파라미터의 수가 적기 때문에 계산 비용과 메모리 사용량, 통신 대역폭이 적어 빠르고 확장 가능한(scaleable) 학습이 가능하다.
그러나 영역 캡셔닝 모델을 학습시키는 데 사용할 수 있는 데이터는 제한되어 있다. 예를 들어 Visual Genome(VG)에는 최대 10만 개의 이미지가 포함되어 있다. 이와 대조적으로 SAM은 1100만 개 이상의 이미지와 10억 개 이상의 마스크가 포함된 데이터셋을 사용했다. 따라서 공개적으로 사용 가능한 object detection (Objects365) 및 segmentation 데이터셋 (COCO-Panoptic)을 활용하기 위한 weak supervision 사전 학습 단계를 도입하였다. 텍스트 feature mixer는 VG의 영역 캡션 데이터에 대해 fine-tuning된다.
Method
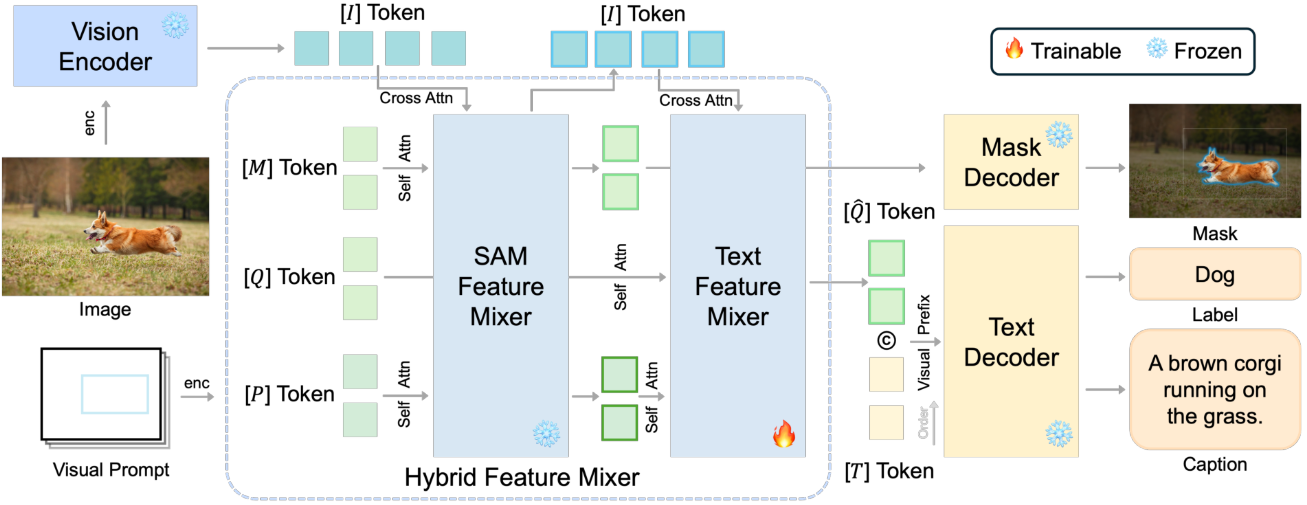
모델에는 ViT 기반 인코더, transformer 쿼리 기반 feature mixer, 다양한 출력을 위한 텍스트 디코더의 세 가지 구성 요소가 있다. ViT 기반 인코더와 소형 마스크 디코더 외에도 이미지 인코더에서 추출한 글로벌 이미지 feature와 사용자 프롬프트를 혼합하는 가벼운 쿼리 기반 feature mixer가 포함된다. 이 모듈은 200만 개의 파라미터로만 구성되므로 효율적이다. 모델 아키텍처는 위 그림과 같다.
저자들은 SAM의 이미지 인코더의 feature가 segmentation task를 넘어서는 풍부한 semantic feature를 포함하고 있다고 가정하였다. 이 가정을 기반으로 사전 학습된 SAM 모델 위에 모델을 구축하고 텍스트를 예측하기 위해 텍스트 디코더와 함께 추가 feature mixer를 쌓는다. Mixer의 레이어 수를 늘리는 것을 제외하고는 SAM의 mixer 디자인을 따른다.
이미지 인코더
SAM을 따라 ViT 스타일의 이미지 인코더가 채택되었다. 기본 로컬 window attention과 여러 개의 글로벌 attention이 있는 일반 ViT로 구성되어 동일한 feature 차원을 가진 feature map을 생성한다.
이미지 $\mathcal{I}$가 주어지면 인코더 $E_I$가 글로벌 이미지 feature $I$를 추출한다. 다음에 오는 feature mixer는 가능한 한 가벼워야 하므로 이미지 feature는 계산 효율성을 위해 256차원의 64$\times$64로 다운샘플링된다.
멀티스케일 feature를 생성하는 것과 비교하여 에서와 같이 마지막 레이어의 단일 수준의 시각적 feature만 활용하는 것은 아니다. 그러나 단일 수준 feature에는 지역 규모에 관계없이 나중에 캡션을 생성할 수 있는 충분한 정보가 포함되어 있다.
Regional feature mixer
글로벌 이미지 feature를 추출한 후에는 입력된 시각적 프롬프트에 해당하는 regional feature를 추가로 추출해야 한다. Region-of-interest (ROI) feature를 얻기 위해 각 attention block 전체에 regional feature를 융합하는 쿼리 토큰을 통합하여 attention 메커니즘을 활용한다. Attention block과 호환되는 토큰을 출력하는 특정 프롬프트 인코더를 사용하여 다양한 형식의 프롬프트를 인코딩할 수 있다. 또한 점진적인 feature 상호 작용 및 융합이 가능하다.
쿼리 기반 feature mixer는 attention block으로 구성되며, 입력으로 인코딩된 프롬프트 토큰, 글로벌 이미지 토큰, task 전용 쿼리 토큰이 들어간다. 여러 self-attention block과 cross-attention block을 통과한 후에는 쿼리 토큰의 정확한 위치에서 regional feature를 가져올 수 있다.
글로벌 이미지 토큰 $I$와 상자 $b$, 점 $p$, 마스크 $m$ 형태의 프롬프트 \(\mathcal{P}_{\{b,p,m\}}\)가 주어지면 먼저 프롬프트 인코더 $E_p$로 \(\mathcal{P}_{\{b,p,m\}}\)를 인코딩한다.
\[\begin{equation} E_p (\mathcal{P}_{\{b,p,m\}}) = P_{\{b,p,m\}} \end{equation}\]다음으로, 인코딩된 프롬프트 토큰, 텍스트 토큰 $Q$, 마스크 쿼리 토큰 $M$을 concatenate하고 글로벌 이미지 토큰 $I$와 함께 $N$개의 block이 있는 쿼리 기반 feature mixer $E_R$에 공급한다.
\[\begin{equation} E_R^j (P^{j-1}, Q^{j-1}, M^{j-1}, I^{j-1}) = \{\hat{P}\vphantom{P}^j, \hat{Q}\vphantom{Q}^j, \hat{M}\vphantom{M}^j, \hat{I}\vphantom{I}^j\}, \quad j = \{1, \ldots, N\} \end{equation}\]$N$번째 block 이후의 융합된 토큰 \(\{\hat{P}\vphantom{P}^N, \hat{Q}\vphantom{Q}^N, \hat{M}\vphantom{M}^N, \hat{I}\vphantom{I}^N\}\)을 최종 출력 \(\{\hat{P}, \hat{Q}, \hat{M}, \hat{I}\}\)으로 사용한다. 인코딩된 쿼리 토큰 $\hat{Q}$와 $\hat{M}$은 각각 캡션 및 segmentation을 위한 ROI 토큰으로 간주되며 다음 output head로 전달된다.
쿼리 기반 feature mixer $E_R$은 block을 쌓은 양방향 Transformer이다. 각 block은 sparse 토큰(즉, 프롬프트 토큰 $P$와 쿼리 토큰 $Q$의 concatenation)을 융합하는 하나의 self-attention layer와 글로벌 이미지 토큰 $I$를 주입하는 cross-attention layer로 구성된다. 인코딩 프로세스 중에 각 block에서 쿼리 토큰 $Q$는 글로발 이미지 토큰 $I$ 내부의 프롬프트 $P$에 기반한 task별 정보를 점진적으로 수집할 수 있다.
쿼리 토큰
SAM은 쿼리 기반 feature mixer를 핵심 구성 요소로 사용하지만 레이블과 같은 높은 수준의 semantic 출력 없이 마스크만 예측한다. SAM은 카테고리에 구애받지 않고 학습된 경우에도 실제로 좋은 semantic으로 마스크를 예측할 수 있다. 이는 SAM의 초기 학습 데이터에 semantic 라벨 없이 사물 위에 마스크를 그려져 있기 때문이다. 따라서 SAM 위에 추가 feature mixer $E_R^\textrm{Cap}$을 쌓아서 SAM의 쿼리 토큰을 활용한다.
SAM은 마스크 예측을 위한 feature를 혼합하기 위해 자체 쿼리 토큰 $M$을 보유했다. 2-layer feature mixer $E_R^\textrm{SAM}$을 사용하여 해당 feature를 인코딩한다. 텍스트 예측을 위해 새로운 쿼리 토큰 $Q$ 세트를 추가하고 $E_R^\textrm{SAM}$로 인코딩된 프롬프트 토큰과 이미지 토큰을 $E_R^\textrm{Cap}$에 넣어준다.
Regional feature decoder
ROI feature를 얻은 후 이를 텍스트 디코더 \(D_\textrm{Cap}\)로 보내 영역 캡션을 생성할 수 있다. 텍스트 디코더는 예측된 이전 텍스트 토큰 \(\mathcal{T}_{1:k−1}\)을 기반으로 텍스트 토큰 $T_k$를 예측하는 Transformer 디코더이다.
\[\begin{equation} D_\textrm{Cap} (\mathcal{T}_{1:k-1}) = \mathcal{T}_k \end{equation}\]Regional feature에 대한 컨디셔닝을 위해 텍스트 토큰 $\mathcal{T}$ 앞에 feature 토큰 $Q$를 붙인다. Task 관련 컨텍스트를 활용하기 위해 최적화 가능한 task 토큰 집합 $\mathcal{T}$를 접두사로 추가한다. 다음과 같은 cross-entropy loss $L$을 최소화하여 모델을 최적화할 수 있다.
\[\begin{equation} L = \frac{1}{N_\mathcal{T} + 1} \sum_{k=1}^{N_\mathcal{T} + 1} \textrm{CE} (\mathcal{T}_k, p(\mathcal{T}_k \vert T, Q, \mathcal{T}_{0:k-1})) \end{equation}\]CE는 0.1의 강도의 label smoothing을 사용한 cross-entropy loss이다. \(\mathcal{T}_0\)는 문장 시작(BOS) 토큰, \(\mathcal{T}_{N_\mathcal{T} + 1}\)은 문장 끝(EOS) 토큰이다.
Experiments
- 데이터셋
- 사전 학습: Objects365, COCO-Panoptic (샘플링 비율 10:1)
- Fine-tuning: Visual Genome (VG)
- 구현 디테일
- 마스크 feature mixer, 마스크 디코더: 사전 학습된 SAM
- 텍스트 디코더: GPT2-large, OpenLLAMA-3B (학습 중 고정)
- Regional feature mixer: SAM의 2-layer mixer를 12 layer로 스케일링하여 사용
- 캡션 쿼리 토큰 $Q$의 길이: 8
- Task 토큰 $T$의 길이: 6
1. Comparison with Other Methods
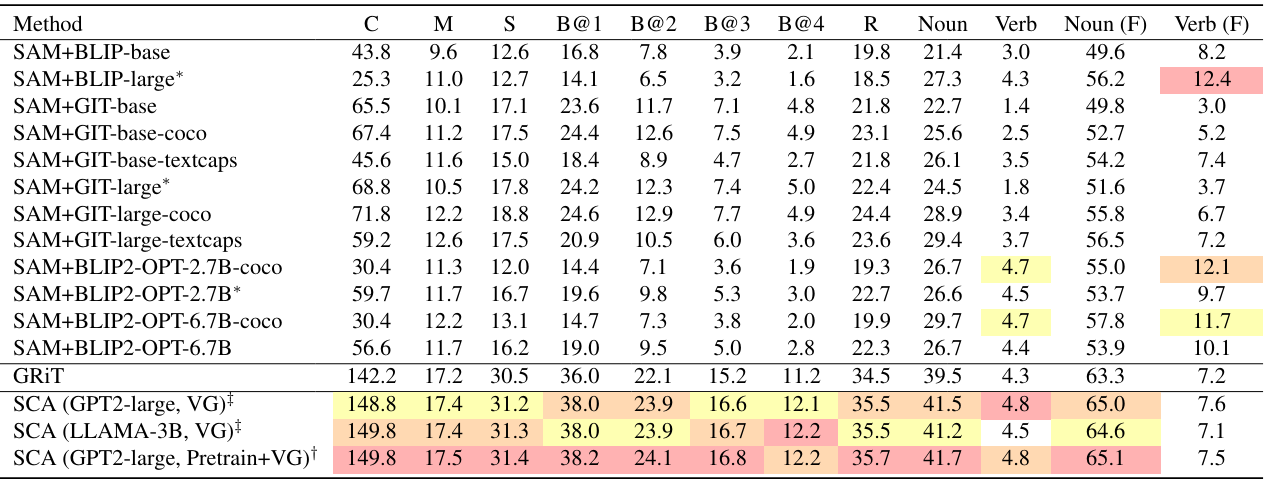
다음은 다른 방법들과 정량적으로 비교한 표이다. ‘VG’는 VG로 20만 step동안 학습시킨 모델이고, ‘Pretrain+VG’는 10만 step동안 사전 학습 후 10만 step동안 VG로 fine-tuning한 모델이다. (C: CIDEr-D, M: METEOR, S: SPICE, B: BLEU, R: ROUGE, (F): Fuzzy)
다음은 정성적인 결과이다.

- SAM + GIT-large
- SAM + BLIP-large
- SAM + BLIP2-OPT-2.7B
- GRIT
- SCA (GPT2-large+VG)
- SCA (LLAMA-3B+VG)
- SCA (GPT2-large+Pretrain+VG)
- ground truth
2. Ablation Study
다음은 weak supervision을 사용한 사전 학습에 대한 ablation 결과이다.

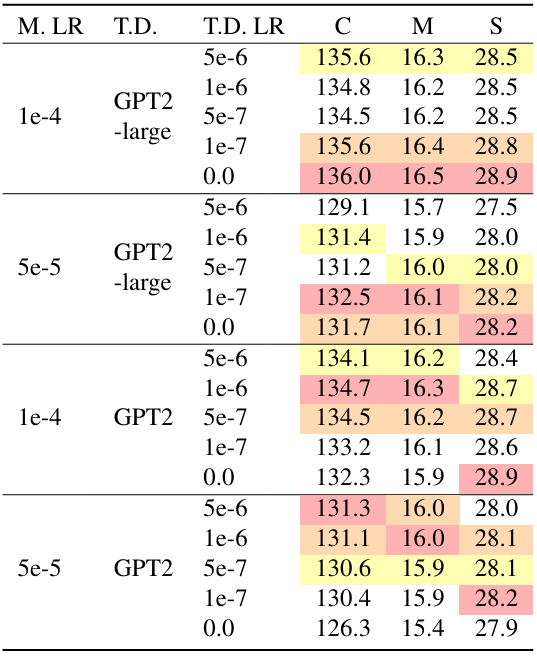
다음은 feature mixer(M)와 텍스트 디코더(TD)의 학습 세팅에 대한 ablation 결과이다.
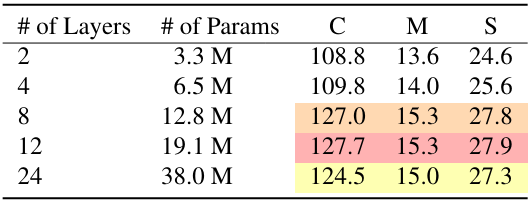
다음은 (왼쪽) feature mixer의 layer 수와 (오른쪽) feature mixer 디자인에 따른 성능을 비교한 표이다.
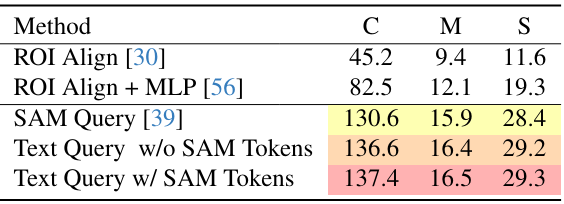
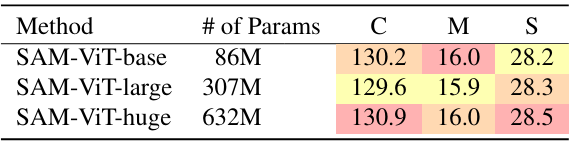
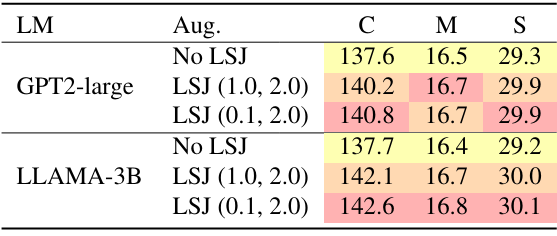
다음은 (왼쪽) 이미지 인코더의 크기와 (오른쪽) data augmentation 사용에 대한 ablation 결과이다.