[논문리뷰] SAM 2: Segment Anything in Images and Videos
ICLR 2025 (Oral). [Paper] [Page] [Github]
Nikhila Ravi, Valentin Gabeur, Yuan-Ting Hu, Ronghang Hu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr, Roman Rädle, Chloe Rolland, Laura Gustafson, Eric Mintun, Junting Pan, Kalyan Vasudev Alwala, Nicolas Carion, Chao-Yuan Wu, Ross Girshick, Piotr Dollár, Christoph Feichtenhofer
Meta FAIR
1 Aug 2024
Segment Anything의 후속 논문
Introduction
Segment Anything Model (SAM)은 이미지에서 promptable segmentation을 위한 foundation model이다. 그러나 이미지는 현실의 정적 스냅샷일 뿐이다. 보편적인 segmentation 시스템은 이미지와 동영상 모두에 적용 가능해야 한다.
동영상에서의 segmentation은 엔티티의 시공간적 범위를 결정하는 것을 목표로 하며, 이는 이미지에서의 segmentation을 넘어 고유한 과제를 제시한다.
- 엔티티는 움직임, 변형, 가려짐, 조명 변화 및 기타 요인으로 인해 모양이 크게 바뀔 수 있다.
- 동영상은 카메라 동작, blur, 낮은 해상도로 인해 종종 이미지보다 품질이 낮다.
- 많은 수의 프레임을 효율적으로 처리하는 것이 중요하다.
SAM은 이미지에서의 segmentation을 성공적으로 처리하지만, 기존 동영상 segmentation 모델과 데이터셋은 “segment anything in videos”에 필적할 만한 능력을 제공하지 못한다.
본 논문은 동영상 및 이미지 segmentation을 위한 통합 모델인 Segment Anything Model 2 (SAM 2)를 소개한다. 이미지는 프레임이 하나인 동영상으로 간주된다.
저자들은 동영상 도메인에 이미지 segmentation을 일반화하는 Promptable Visual Segmentation (PVS) task에 집중하였다. 이 task는 동영상의 모든 프레임에서 입력 포인트, 박스 또는 마스크를 사용하여 시공간 마스크인 masklet을 예측한다. Masklet이 예측되면 추가로 프레임에서 프롬프트를 제공받아 반복적으로 정제할 수 있다.
SAM 2는 object와 이전 상호작용에 대한 정보를 저장하는 메모리를 갖추고 있어 동영상 전체에 masklet 예측을 생성하고 이전에 관찰된 프레임의 object에 대한 저장된 메모리 컨텍스트를 기반으로 이를 효과적으로 수정할 수 있다. 스트리밍 아키텍처는 동영상 도메인에 대한 SAM의 자연스러운 일반화로, 한 번에 하나씩 동영상 프레임을 처리하고 타겟 object의 이전 메모리에 attention하는 memory attention module을 갖추고 있다. 이미지에 적용하면 메모리가 비어 있고 모델은 SAM처럼 작동한다.
저자들은 annotator와 함께 모델을 루프로 사용하여 새롭고 어려운 데이터에 상호 작용을 통해 주석을 달아 학습 데이터를 생성하는 데이터 엔진을 사용하였다. 대부분의 기존 동영상 segmentation 데이터셋과 달리, 이 데이터 엔진은 특정 카테고리의 object에 국한되지 않고, part와 subpart를 포함하여 유효한 경계가 있는 모든 object를 분할하기 위한 학습 데이터를 제공하는 것을 목표로 한다.
기존의 모델 지원 접근 방식과 비교할 때, SAM 2를 사용하는 데이터 엔진은 비슷한 품질에서 8.4배 더 빠르다. 최종 Segment Anything Video (SA-V) 데이터셋은 5.09만 개의 동영상에서 3,550만 개의 마스크로 구성되어 있으며, 기존 동영상 segmentation 데이터셋보다 53배 마스크가 더 많다. SA-V는 동영상 전체에서 가려지고 다시 나타나는 작은 object와 part로 인해 어렵다.
SAM 2는 동영상 분할 경험에 있어 단계적 변화를 제공한다. SAM 2는 이전 방법들보다 3배 적은 상호 작용을 사용하면서도 더 나은 분할 정확도를 달성할 수 있다. 또한 SAM 2는 여러 동영상 segmentation 벤치마크에서 이전 방법들보다 성능이 뛰어나고 이미지 segmentation 벤치마크에서 SAM보다 더 나은 성능을 제공하는 동시에 6배 더 빠르다. SAM 2는 수많은 zero-shot 벤치마크 (동영상 segmentation 17개, 이미지 segmentation 37개)를 통해 관찰된 것처럼 다양한 동영상 및 이미지 분포에서 효과적이다.
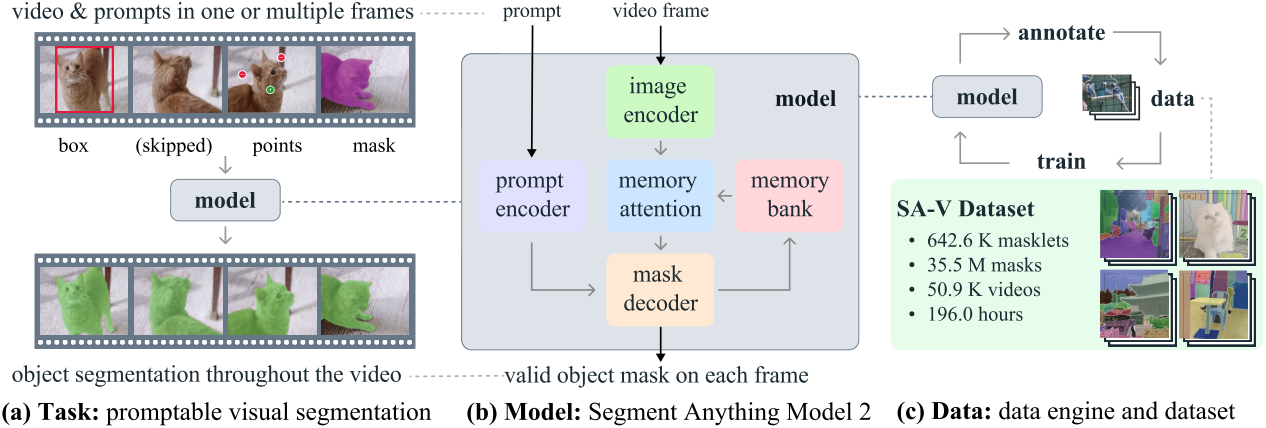
Task: promptable visual segmentation
PVS task는 동영상의 모든 프레임에서 모델에 프롬프트를 제공할 수 있다. 프롬프트는 positive/negative click, bounding box, 또는 마스크일 수 있으며, 분할할 object를 정의하거나 모델에서 예측한 object를 정제하는 데 사용할 수 있다. 대화형 경험을 제공하기 위해 특정 프레임에서 프롬프트를 수신하면 모델은 이 프레임에서 object의 유효한 segmentation mask로 즉시 응답해야 한다. 초기 (하나 또는 여러 개) 프롬프트 (동일한 프레임 또는 다른 프레임)를 수신한 후 모델은 이러한 프롬프트를 전파하여 모든 동영상 프레임에서 대상 object의 segmentation mask가 포함된 전체 동영상에서 object의 masklet을 얻어야 한다. 추가 프롬프트는 모든 프레임에서 모델에 제공하여 동영상 전체에서 세그먼트를 정제할 수 있다.
Model

SAM 2는 동영상 도메인에 대한 SAM의 일반화로 볼 수 있다. SAM 2는 동영상에서 분할할 object의 공간적 범위를 정의하기 위해 개별 프레임에서 포인트, bounding box, 마스크 프롬프트를 지원한다. 이미지 입력의 경우 SAM과 유사하게 동작한다. 프롬프팅 가능하고 가벼운 마스크 디코더는 현재 프레임에서 프레임 임베딩과 프롬프트(있는 경우)를 입력받고 프레임에 대한 segmentation mask를 출력한다. 마스크를 개선하기 위해 프레임에 프롬프트를 반복적으로 추가할 수 있다.
SAM과 달리 SAM 2 디코더에서 사용하는 프레임 임베딩은 이미지 인코더에서 직접 가져오지 않고 대신 과거 예측과 프롬프트 프레임의 메모리에 따라 달라진다. 프롬프트 프레임은 현재 프레임과 관련하여 미래 프레임에서 나올 수도 있다. 프레임의 메모리는 현재 예측을 기반으로 메모리 인코더에서 생성되어 후속 프레임에서 사용할 수 있도록 메모리 뱅크에 배치된다. Memory attention 연산은 이미지 인코더에서 프레임별 임베딩을 가져와 메모리 뱅크에 컨디셔닝되어 마스크 디코더로 전달되는 임베딩을 생성한다.
이미지 인코더
임의로 긴 동영상을 실시간으로 처리하기 위해 스트리밍 방식을 사용하여 동영상 프레임이 사용 가능해지면 사용한다. 이미지 인코더는 전체 상호작용에 대해 한 번만 실행되며, 그 역할은 각 프레임을 나타내는 토큰 (feature 임베딩)을 제공하는 것이다. MAE로 사전 학습된 Hiera 이미지 인코더를 사용하며, 계층적이기 때문에 디코딩 중에 멀티스케일 feature를 사용할 수 있다.
Memory attention
Memory attention의 역할은 과거 프레임의 feature와 예측, 그리고 새로운 프롬프트에 따라 현재 프레임의 feature를 컨디셔닝하는 것이다. $L$개의 transformer block을 쌓는데, 첫 번째 block은 현재 프레임의 이미지 인코딩을 입력으로 받는다. 각 block은 self-attention을 수행한 다음, 메모리 뱅크에 저장된 프레임과 object pointer의 메모리에 대한 cross-attention을 수행하고, 그 다음에는 MLP를 수행한다. Self-attention과 cross-attention에 바닐라 attention 연산을 사용한다.
프롬프트 인코더 & 마스크 디코더
프롬프트 인코더는 SAM과 동일하며 positive/negative click, bounding box, 또는 마스크로 프롬프팅되어 주어진 프레임에서 object의 범위를 정의할 수 있다. 클릭(포인트)과 bounding box는 각 프롬프트 유형에 대한 학습된 임베딩과 합산된 위치 인코딩으로 표현되는 반면, 마스크는 convolutions들을 사용하여 임베딩되고 프레임 임베딩과 더해진다.

디코더 디자인은 대체로 SAM을 따르며, 프롬프트와 프레임 임베딩을 업데이트하는 양방향 transformer block을 쌓는다. SAM과 같이 여러 마스크가 있을 수 있는 모호한 프롬프트, 즉 단일 클릭의 경우, 여러 마스크를 예측한다. 모호성이 프레임 전체로 확장될 수 있는 동영상의 경우, 모델은 각 프레임에서 여러 마스크를 예측한다. 후속 프롬프트가 모호성을 해결하지 못하면, 모델은 현재 프레임에 대해 예측된 IoU가 가장 높은 마스크만 전파한다.
SAM과 달리 positive prompt가 주어지면 항상 분할할 유효한 object가 있는 반면, PVS task에서는 가려짐 등에 의해 일부 프레임에 유효한 object가 존재하지 않을 수 있다. 이 새로운 출력 모드를 설명하기 위해, 관심 object가 현재 프레임에 있는지 여부를 예측하는 head를 추가한다. SAM과의 또 다른 차이점은 계층적 이미지 인코더에서 skip connection을 사용하여 (memory attention을 우회) 마스크 디코딩을 위한 고해상도 정보를 통합한다는 것이다.
메모리 인코더
메모리 인코더는 convolutional module을 사용하여 출력 마스크를 다운샘플링하고 이미지 인코더의 컨디셔닝되지 않은 프레임 임베딩과 더한 다음, 가벼운 convolutional layer들을 통해 정보를 융합하여 메모리를 생성한다.
메모리 뱅크
메모리 뱅크는 최대 $N$개의 최근 프레임에 대한 메모리 FIFO 큐를 유지하여 동영상에서 타겟 object에 대한 과거 예측 정보를 유지하고, 최대 $M$개의 프롬프팅된 프레임에 대한 FIFO 큐에 프롬프트의 정보를 저장한다. 예를 들어, 초기 마스크가 유일한 프롬프트인 VOS task에서 메모리 뱅크는 최대 $N$개의 프롬프팅되지 않은 최근 프레임의 메모리와 함께 첫 번째 프레임의 메모리를 일관되게 유지한다. 두 메모리 세트 모두 공간적 feature map으로 저장된다.
추가로, 각 프레임의 마스크 디코더 출력 토큰을 기반으로 분할할 object의 high-level semantic 정보에 대한 가벼운 벡터로서 object pointer 목록을 저장한다. Memory attention은 메모리 feature와 object pointer에 모두 cross-attention한다. 시간적 위치 정보를 $N$개의 최근 프레임의 메모리에 임베딩하여 모델이 단기적인 object의 움직임을 표현할 수 있도록 하지만, 프롬프팅된 프레임의 메모리에는 임베딩하지 않는다. 프롬프팅된 프레임의 학습 신호가 더 sparse하고 프롬프팅된 프레임이 학습 중에 본 것과 매우 다른 시간에서 나올 수 있어 일반화하기가 더 어렵기 때문이다.
학습
모델은 이미지와 동영상 데이터에서 공동으로 학습되며, SAM과 유사하게 모델의 대화형 프롬프트를 시뮬레이션한다. 8개 프레임의 시퀀스를 샘플링하고 최대 2개 프레임을 무작위로 선택하여 프롬프팅한다. 이 때 확률적으로 수정을 위한 클릭을 입력받으며, 이는 학습 중에 GT masklet과 모델 예측을 사용하여 샘플링된다. 학습 목표는 GT masklet을 순차적으로, 그리고 상호 작용을 통해 예측하는 것이다. 모델에 대한 초기 프롬프트는 0.5의 확률로 GT 마스크, 0.25의 확률로 GT 마스크에서 샘플링된 positive click, 0.25의 확률로 bounding box 입력이 될 수 있다.
먼저, SAM을 학습할 때 사용한 SA-1B 데이터셋을 사용하여 정적 이미지에서 SAM 2를 사전 학습시킨다. SAM과 달리 IoU 예측을 보다 적극적으로 supervise하기 위해 L1 loss를 사용하고 IoU logit에 시그모이드를 적용하여 출력을 0과 1 사이의 범위로 제한하였다. 다중 마스크 예측 (첫 번째 클릭)의 경우, 마스크가 언제 나쁜지 더 잘 학습하도록 장려하기 위해 모든 마스크의 IoU 예측을 supervise하지만, segmentation loss가 가장 낮은 마스크의 logit만 supervise한다. SAM의 경우 반복적인 포인트 샘플링 중에 추가 프롬프트 없이 두 번의 iteration이 삽입되었지만, SAM 2에서는 이러한 iteration을 추가하지 않고 SAM의 8번의 수정 클릭 대신 7번의 수정 클릭을 사용한다.
사전 학습 후, 새로 도입한 데이터셋인 SA-V (70%)와 내부 데이터셋 (14.8%), SA-1B (15.2%)을 혼합하여 SAM 2를 학습시킨다. 학습 중에 데이터 사용과 계산 리소스를 최적화하기 위해 동영상 데이터와 정적 이미지를 교대로 학습하는 전략을 채택하였다. 구체적으로, 각 iteration에서 이미지 또는 동영상 데이터셋에서 전체 batch를 샘플링하며, 샘플링 확률은 각 데이터 소스의 크기에 비례한다. 이 접근 방식은 PVS task와 Segment Anything task에 대한 균형 잡힌 노출과 각 데이터 소스에 대한 서로 다른 batch size를 허용하여 컴퓨팅 활용도를 극대화한다.
마스크 예측은 focal loss와 dice loss의 선형 결합을 사용하고, IoU 예측은 MAE loss, object prediction은 cross-entropy loss로 사용한다. 각 loss의 비율은 20:1:1이다. GT에 마스크가 포함되어 있지 않으면 어떤 마스크 출력도 supervise하지 않는다. 그러나 프레임에 마스크가 있어야 하는지를 예측하는 occlusion prediction head는 항상 supervise한다.
Data
저자들은 동영상에서 “segment anything”하는 모델을 만들기 위해 방대하고 다양한 동영상 segmentation 데이터셋을 수집하는 데이터 엔진을 구축했다. 인간 annotator와 함께 대화형 모델이 사용되었다. SAM과 유사하게, 주석이 달린 masklet에 semantic 제약을 부과하지 않고 전체 object와 part에 모두 집중하였다. 데이터 엔진은 세 phase를 거쳤으며, 각 phase는 annotator에게 제공된 모델 지원 수준에 따라 분류된다.
1. Data engine
Phase 1: SAM per frame
Phase 1에서는 이미지 기반 대화형 SAM을 사용하여 인간 주석을 지원했다. Annotator들은 SAM과 “브러시”, “지우개”와 같은 픽셀 단위의 수동 편집 도구를 사용하여 6 FPS로 동영상의 모든 프레임에서 대상 object의 마스크에 주석을 달도록 과제를 받았다. 마스크를 다른 프레임으로 시간적으로 전파하는 데 도움이 되는 추적 모델은 없다. 이는 per-frame 방법이고 모든 프레임에 처음부터 마스크 주석이 필요하기 때문에 프로세스가 느리며 프레임당 주석을 다는 평균 시간은 37.8초이다. 그러나 이를 통해 프레임별로 고품질의 주석이 생성된다.
Phase 1에서는 1,400개의 동영상에서 1.6만 개의 masklet이 수집되었다. 또한 이 접근 방식을 사용하여 SA-V의 validation set과 test set에 주석을 달아 평가 중에 SAM 2의 잠재적 편향을 완화한다.
Phase 2: SAM + SAM 2 Mask
Phase 2에서는 루프에 SAM 2를 추가했는데, SAM 2는 마스크만 프롬프트로 허용한다. 이 버전을 SAM 2 Mask라고 한다. Annotator가 Phase 1에서와 같이 SAM과 기타 도구를 사용하여 첫 번째 프레임에서 마스크를 만들면 SAM 2 Mask를 사용하여 주석이 달린 마스크를 다른 프레임으로 시간적으로 전파하여 전체 시공간 masklet을 얻는다. 이후의 모든 동영상 프레임에서 annotator들은 SAM과 기타 도구를 사용하여 처음부터 마스크를 만들어 SAM 2 Mask의 예측을 변경하고 다시 전파할 수 있으며 masklet이 정확해질 때까지 이 프로세스를 반복한다. SAM 2 Mask는 처음에 Phase 1 데이터와 공개 데이터셋에서 학습되었다. Phase 2에서 수집된 데이터를 사용하여 SAM 2 Mask를 두 번 다시 학습시키고 업데이트했다.
Phase 2에서는 6.35만 개의 masklet이 수집되었다. 주석을 다는 시간은 Phase 1에 비해 약 5.1배 빨라진 7.4초/프레임으로 감소했다. 주석을 다는 시간이 개선되었음에도 불구하고, 이 분리된 접근 방식은 이전 메모리 없이 처음부터 중간 프레임의 마스크에 주석을 달아야 한다.
Phase 3: SAM 2
Phase 3에서는 포인트와 마스크를 포함한 다양한 유형의 프롬프트를 허용하는 모든 기능을 갖춘 SAM 2를 활용한다. SAM 2는 시간 차원에 걸친 object의 메모리를 활용하여 마스크 예측을 생성한다. 즉, annotator는 중간 프레임에서 예측된 masklet을 편집하기 위해 SAM 2에 가끔씩 마스크 정제를 위한 클릭만 제공하면 되며, 처음부터 주석을 달 필요가 없다. Phase 3에서 수집된 주석을 사용하여 SAM 2를 5번 재학습시키고 업데이트했다.
Phase 3에서는 19.7만개의 masklet이 수집되었다. SAM 2를 루프에 넣으면 주석을 다는 시간이 4.5초/프레임으로 줄어들어 Phase 1보다 약 8.4배 빨라졌다.
품질 검증
주석에 대한 높은 품질을 유지하기 위해 품질 검증 단계를 도입한다. 별도의 annotator들이 각 주석이 달린 masklet의 품질을 “만족” (모든 프레임에서 대상 객체를 정확하고 일관되게 추적) 또는 “불만족” (대상 object가 명확한 경계로 잘 정의되었지만 masklet이 정확하거나 일관되지 않음)으로 검증하였다. 만족스럽지 않은 masklet들은 정제를 위해 주석 파이프라인으로 다시 보내졌다. 잘 정의되지 않은 object를 추적하는 masklet들은 모두 거부되었다.
자동 masklet 생성

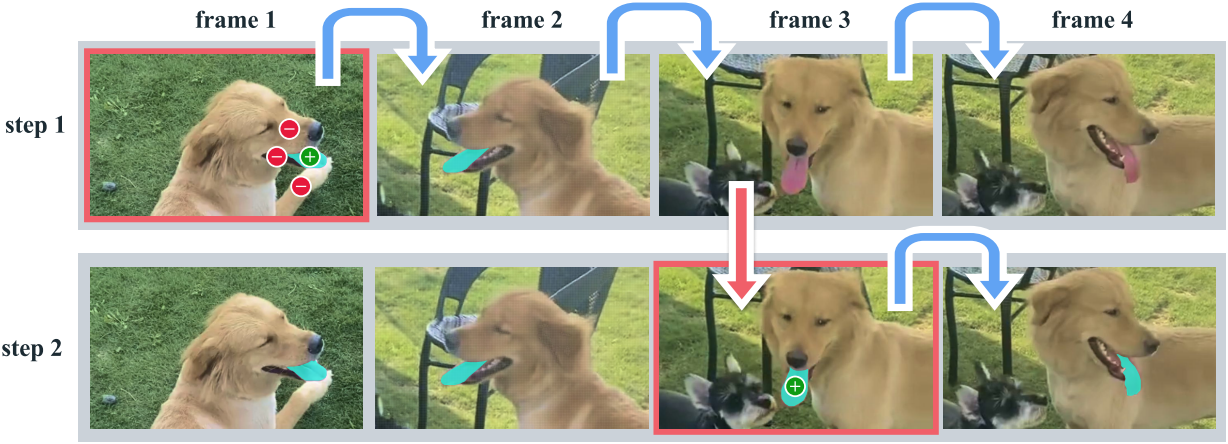
모델의 anything 기능을 활성화하려면 주석의 다양성을 보장하는 것이 중요하다. 인간 annotator는 일반적으로 눈에 띄는 object에 더 집중할 수 있으므로, 주석을 자동으로 생성된 masklet (“Auto”라고 함)으로 보강한다. 이는 주석의 다양성을 늘리고 모델의 failure case들을 식별하는 데 도움이 된다. 위의 예시는 (a) 수동 주석만 있을 때와 (b) Auto도 있을 때를 비교한 예시이다.
자동 masklet을 생성하기 위해 첫 번째 프레임에서 regular grid로 SAM 2를 프롬프팅하고 후보 masklet을 생성한다. 그런 다음 masklet 검증 단계로 보내 필터링한다. “만족”으로 검증된 자동 masklet은 SA-V 데이터셋에 추가된다. “불만족” (failure case)으로 식별된 masklet은 샘플링되어 Phase 3에서 수정하도록 annotator에게 제공된다. 이러한 자동 masklet은 크고 눈에 띄는 중앙의 object뿐만 아니라 배경에 있는 크기와 위치가 다양한 object도 포함한다.
분석

위 표는 각 데이터 엔진 phase의 프레임당 평균 주석을 다는 시간, masklet당 수동으로 편집한 프레임의 평균 백분율, 클릭한 프레임당 평균 클릭 수를 비교한 표이다. “Phase 1 Mask Alignment Score”는 Phase 1의 마스크와 비교했을 때 IoU가 0.75를 초과하는 마스크의 백분율이다.
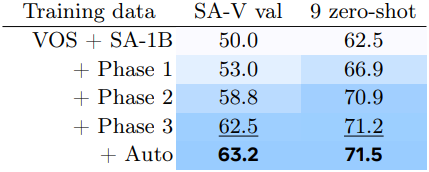
위 표는 iteration 수를 고정한 채 각 phase의 마지막에 사용 가능한 데이터로 학습된 SAM 2의 성능을 비교한 것이다. 따라서 추가 데이터의 영향만 측정한 것이다. 첫 번째 프레임에서 3번 클릭으로 프롬프팅할 때 $\mathcal{J \& F}$ 정확도 (높을수록 좋음)을 사용하여 자체 SA-V validation set괴 9개의 zero-shot 벤치마크에서 평가하였다. 각 phase의 데이터를 반복적으로 포함한 후 segmentation 성능의 일관된 개선이 나타났다.
2. SA-V dataset
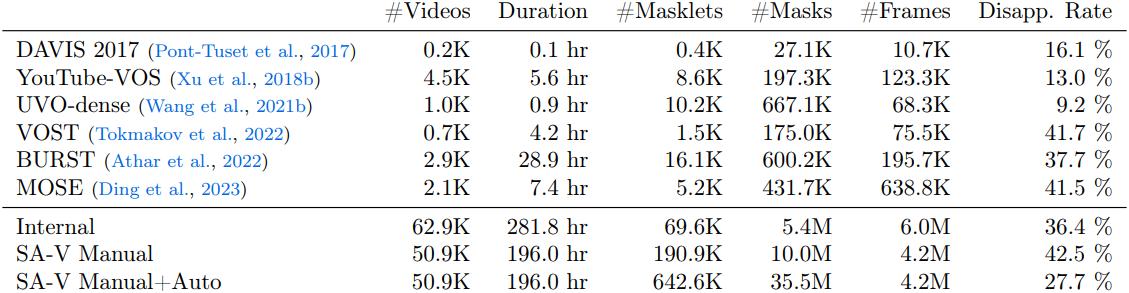
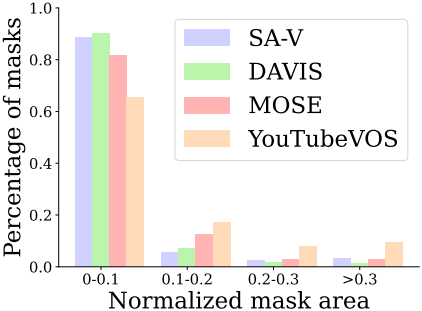
데이터 엔진으로 수집한 SA-V 데이터셋은 64.3만 개의 masklet이 있는 5.09만 개의 동영상으로 구성되어 있다. 위 표는 동영상, masklet, 마스크 수에 따라 SA-V와 일반적인 VOS 데이터셋을 비교한 표이다. 특히 주석이 달린 마스크의 수는 기존 VOS 데이터셋보다 53배 (Auto가 없는 경우 15배) 더 많다. Disappearance rate는 한 프레임에서 사라졌다가 다시 나타나는 masklet의 비율이다.
Videos
저자들은 크라우드워커가 촬영한 5.09만 개의 새로운 동영상 세트를 수집했다. 동영상은 54%가 실내 장면이고 46%가 실외 장면이며 평균 길이는 14초이다. 동영상은 다양한 환경을 특징으로 하며 다양한 일상 시나리오를 다룬다. 본 논문의 데이터셋은 기존 VOS 데이터셋보다 더 많은 동영상을 가지고 있으며, 다양한 참여자가 촬영했다.
Masklets

주석은 데이터 엔진을 사용하여 수집한 19.1만개의 수동 masklet 주석과 45.2만 개의 자동 masklet으로 구성되어 있다. SA-V 수동 주석의 disappearance rate는 42.5%로 기존 데이터셋 중에서 가장 경쟁력이 있다. 또한 SA-V 마스크의 88% 이상이 0.1 미만의 정규화된 마스크 영역을 갖는다.
SA-V training, validation and test splits
저자들은 동영상 촬영자와 그들의 지리적 위치를 기준으로 SA-V를 분할하여 유사한 object의 최소 중복을 보장하였다. SA-V validation과 test set을 만들기 위해 동영상을 선택할 때 어려운 시나리오에 집중하고 annotator에게 빠르게 움직이고 다른 object에 의한 복잡한 가려짐과 사라짐/재등장 패턴을 갖는 어려운 대상을 식별하도록 요청하였다. 이러한 대상들은 데이터 엔진 Phase 1을 사용하여 6 FPS로 주석이 달렸다.
SA-V validation set에는 293개의 masklet과 155개의 동영상이 있고 SA-V test set에는 278개의 masklet과 150개의 동영상이 있다.
Internal dataset
또한 내부적으로 사용 가능한 저작권이 있는 동영상 데이터를 사용하여 학습 데이터셋을 더욱 보강했다. 학습을 위한 내부 데이터셋은 Phase 2와 Phase 3에서 주석이 달린 6.29만 개의 동영상과 6.96만 개의 masklet으로 구성되었으며, 내부 테스트를 위한 데이터셋은 Phase 1에서 주석이 달린 96개 동영상과 189개 masklet으로 구성되어 있다.
Experiments

1. Zero-shot experiments
Video tasks
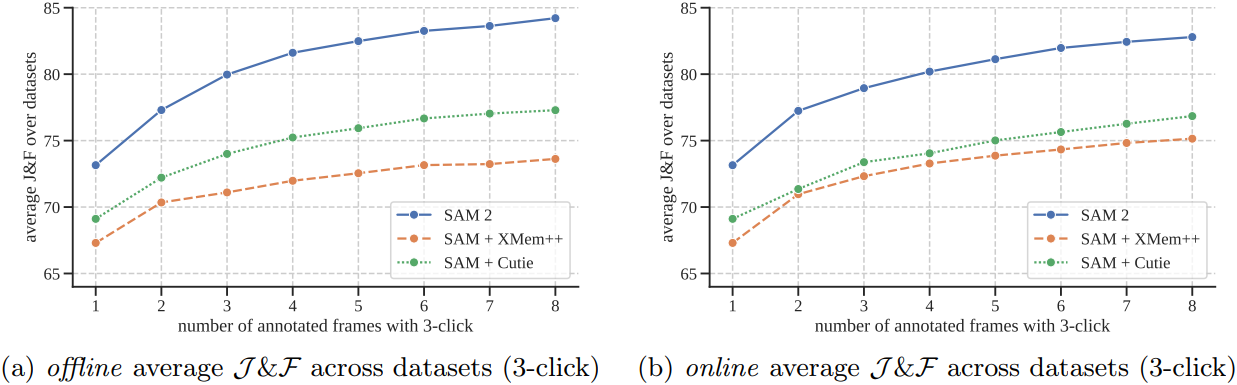
다음은 상호작용한 프레임 수에 따른 $\mathcal{J \& F}$ 정확도를 비교한 그래프이다. (9개 데이터셋의 평균 결과)
다음은 17개의 동영상 데이터셋에서 semi-supervised VOS에 대한 zero-shot 정확도를 비교한 표이다.

Image tasks
다음은 37개의 데이터셋에서 Segment Anything (SA) task에 대한 zero-shot 정확도를 비교한 표이다.

2. Comparison to SOTA in semi-supervised VOS
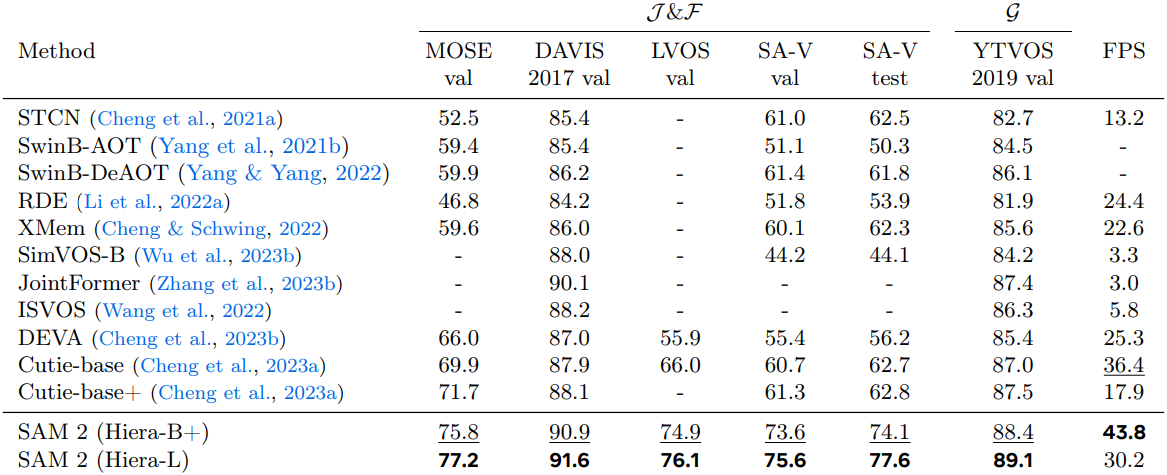
다음은 VOS 성능을 기존 방법들과 비교한 표이다.
3. Ablations
Data ablations
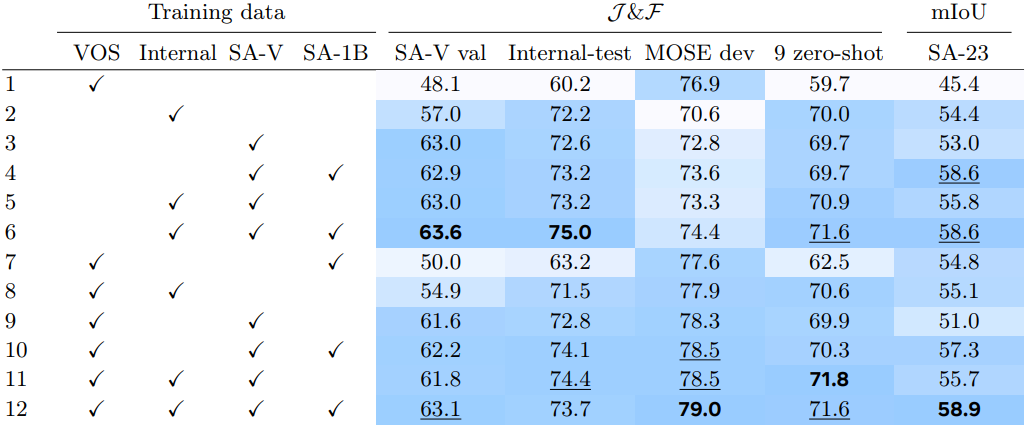
다음은 학습 데이터에 따른 성능을 비교한 표이다. 첫번째 프레임에서 3번의 클릭으로 프롬프팅할 때의 $\mathcal{J \& F}$ 정확도를 비교하였다.
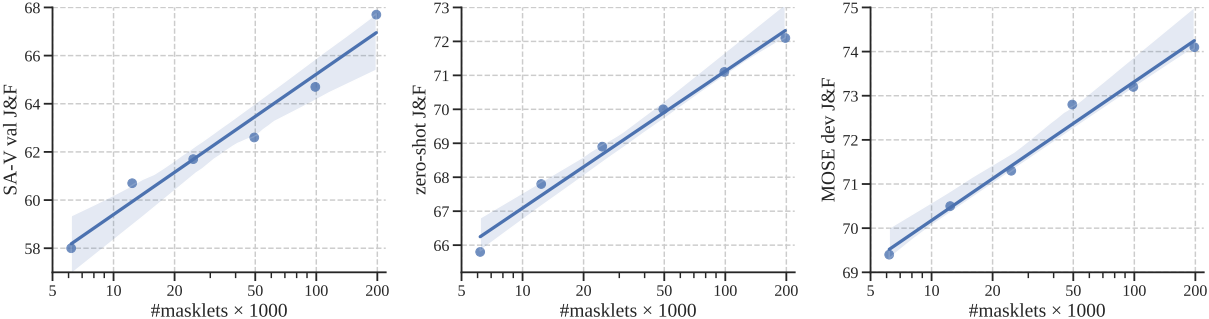
다음은 SA-V 데이터 양에 따른 성능을 (왼쪽) SA-V validation set, (중간) 9개의 zero-shot 데이터셋, (오른쪽) MOSE dev set에서 비교한 그래프이다.
다음은 필터링 전략에 대한 ablation 결과이다.

Model architecture ablations
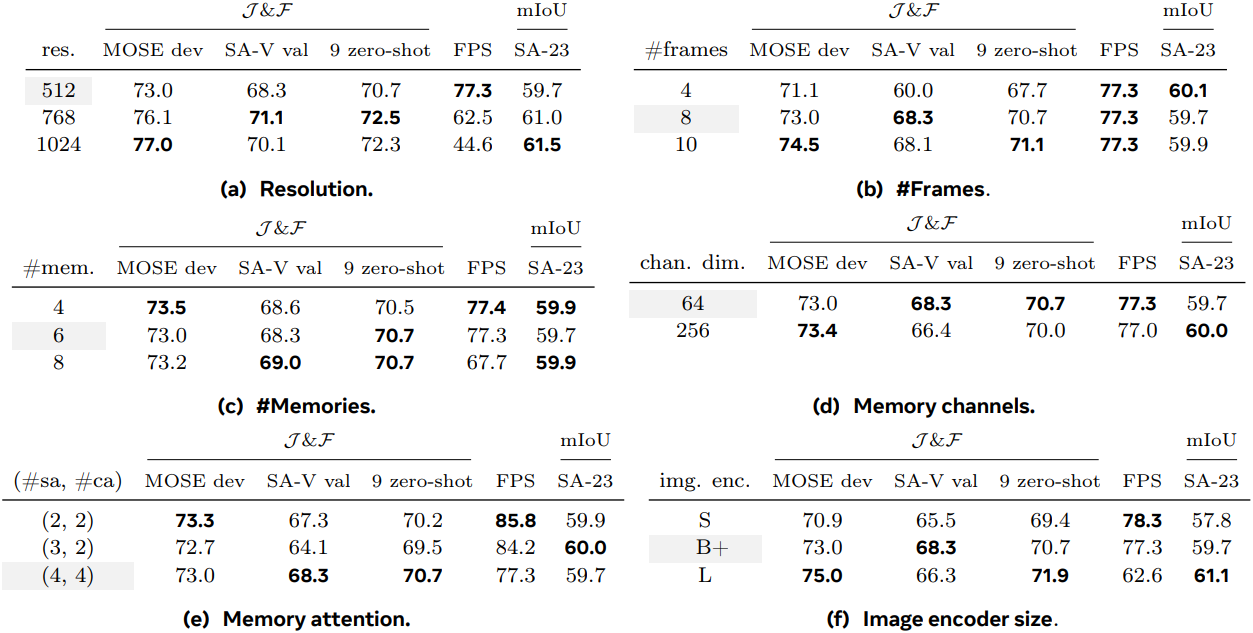
다음은 입력 해상도, 입력 프레임 수, 메모리 수, 메모리 채널 차원, memory attention 수, 이미지 인코더 크기에 대한 ablation 결과이다.
다음은 relative positional encoding에 대한 ablation 결과이다.

다음은 메모리 디자인에 대한 ablation 결과이다.

Limitations
- 혼잡한 장면, 긴 가려짐 후 또는 확장된 동영상에서 object를 추적하지 못하거나 혼동할 수 있다.
- 빠르게 움직이는 경우 매우 얇거나 미세한 디테일이 있는 object를 정확하게 추적하는 데 어려움을 겪는다.
- 비슷한 모양의 object가 근처에 있는 경우 어려움이 발생한다.
- 여러 object를 동시에 추적할 수 있지만 각 object를 개별적으로 처리하여 object 간 통신 없이 공유된 프레임당 임베딩만 활용한다.
- 데이터 엔진은 인간 annotator들에 의존하여 masklet 품질을 확인하고 수정이 필요한 프레임을 선택한다.